







主要内容参考: 为什么现在的LLM都是Decoder only的架构?
当前的LLM(如GPT、LLaMA、PaLM等)普遍采用Decoder-only架构,主要原因可归结为性能优势、训练效率和工程生态三方面的综合考量。
首先,我们来回顾下几种主要主要的架构:
- 以BERT为代表的
encoder-only - 以T5为代表的
encoder-decoder - 以GPT为代表的
decoder-only
encoder-only模型 和 decoder-only模型 比较
首先淘汰掉BERT这种encoder-only模型,因为它使用 Masked Language Model (MLM) 进行预训练,不擅长做生成任务。BERT这种encoder-only模型在做NLU(Natural Language Understanding,自然语言理解) 任务一般也需要有监督的下游数据微调;
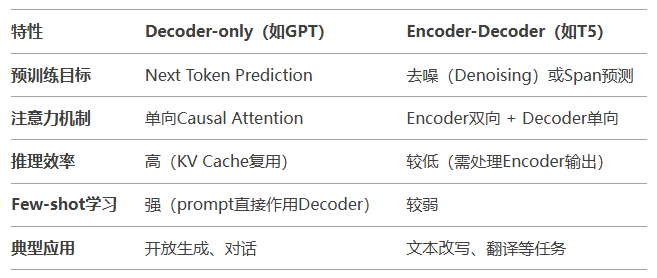
相比之下,decoder-only的模型使用NTP (Next Token Prediction) 进行预训练,兼顾了理解和生成,在各种下游任务上的 zero-shot 和 few-shot 泛化性能都很好。
encoder-decoder模型 和 decoder-only模型 比较
这里,我们重点讨论:为什么引入了一部分双向 attention 的 encoder-decoder模型没有被大部分大模型工作所采用?毕竟它们也能兼顾理解和生成,泛化性能也不错。
具体原因可以归结为以下几点:
-
根据过去的研究经验,decoder-only 模型的泛化性能更好。ICML 22的《What language model architecture and pretraining objective works best for zero-shot generalization?》。在最大5B参数量、170B token数据量的规模下做了一系列实验,发现用next token prediction训练的decoder-only模型在各种下游任务上zero-shot泛化性能最好;另外,许多工作表明decoder-only模型的few-shot(也就是上下文学习,in-context learning)泛化能力更强。
-
各位大佬所阐述decoder-only泛化性能更好的潜在原因:
- @苏剑林 苏神强调的注意力满秩问题:双向attention的注意力矩阵容易退化为低秩状态,而causal attention的注意力矩阵是下三角矩阵,必然是满秩的,建模能力更强;
具体可以参考苏神的博客:- 为什么现在的LLM都是Decoder-only的架构?By 苏剑林
-
@VIII 大佬强调的预测性任务难度问题:纯粹的decoder-only架构+next token prediction训练中,每个位置所能接触的信息比其他架构少,要预测下一个token难度更高,当模型足够大、数据足够多时,decoder-only模型学习通用表征的上限更高;
-
@minimum 大佬强调,上下文学习为decoder-only架构带来的更好的few-shot性能:prompt和demonstration的信息可以视为对模型参数的隐式微调[2],decoder-only的架构相比encoder-decoder在in-context learning上会更有优势,因为prompt可以更加直接地作用于decoder每一层的参数,微调的信号更强;
-
多位大佬强调了一个容易被忽视的属性:causal attention(decoder-only的单向attention)具有隐式的位置编码功能,打破了transformer的位置不变性,而带有双向attention的模型,如果不显式添加位置编码,双向attention允许部分token对换而不改变语义表示,因此对语序的区分能力天生较弱。
-
工业界效率优势
KV-Cache复用:Decoder-only架构支持持续复用KV-Cache,特别适合多轮对话场景。因为每个token的表示仅依赖其之前的输入,而encoder-decoder和PrefixLM架构难以高效实现这一点。 -
行业生态与路径依赖
-
OpenAI的开拓作用:作为先行者,OpenAI基于decoder-only架构探索出成熟的训练方法和Scaling Law,后来者因时间和算力成本倾向于沿用该架构。
-
工程生态优势:Decoder-only架构已形成先发优势,主流工具(如Megatron+和flash attention+)对causal attention的优化支持更完善。
关键优势总结
- 泛化能力更强
(1)Next Token Prediction的预训练目标
-
任务难度更高:Decoder-only模型通过 自回归(AR) 逐词预测下一个token,每个位置仅能依赖历史信息(无法“偷看”未来),迫使模型学习更强的上下文建模能力。
-
Zero-shot/Few-shot表现更好:论文What Language Model Architecture and Pretraining Objective Works Best for Zero-Shot Generalization? 通过实验证明,在相同参数量和数据规模下,Decoder-only架构在零样本(zero-shot)任务上的泛化性能显著优于Encoder-Decoder(如T5)或纯Encoder架构(如BERT)。
(2)Causal Attention的建模优势
-
注意力矩阵满秩:双向Attention(如BERT)的注意力矩阵可能退化为低秩,而Decoder-only的单向 Causal Attention(下三角矩阵)天然满秩,建模能力更强(参考苏剑林的理论分析)。
-
隐式位置编码:Causal Attention本身具有位置敏感性(因掩码强制关注历史token),无需显式位置编码即可区分语序,而双向Attention需依赖额外位置编码。
- 训练与推理效率更高
(1)KV Cache复用
-
自回归生成友好:Decoder-only模型在推理时可通过KV Cache缓存历史token的Key/Value,仅计算当前token的注意力,大幅提升长文本生成效率。
-
Encoder-Decoder的瓶颈:类似T5的架构需同时处理输入(Encoder)和生成(Decoder),KV Cache复用更复杂,内存占用更高。
(2)计算资源优化
-
单一致的计算图:Decoder-only架构仅需维护单向注意力,而Encoder-Decoder需处理双向和单向两种模式,增加实现复杂度。
-
工程工具支持:主流框架(如Megatron、FlashAttention)对Decoder-only的Causal Attention优化更成熟(如FlashAttention-2的显存优化)。
- 上下文学习(In-Context Learning)优势
- Few-shot能力更强:
- Decoder-only模型(如GPT-3)通过prompt工程可直接利用上下文示例(demonstrations)进行隐式微调,而Encoder-Decoder架构对prompt的响应较弱(因Encoder和Decoder的参数分离)。
- 论文Why Can GPT Learn In-Context? 指出,Decoder-only的注意力机制能更直接地将prompt信息传递到每一层。
- 行业路径依赖
-
OpenAI的示范效应:GPT系列的成功验证了Decoder-only架构的可行性,后续研究者倾向于沿用成熟方案,避免重复试错。
-
生态工具链完善:从训练框架(Megatron-DeepSpeed)到推理优化(vLLM、TensorRT-LLM),均针对Decoder-only架构深度优化。
- 与Encoder-Decoder架构的对比

















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









