







 本文介绍了一个经典的动态规划问题——数塔问题,并提供了两种不同的实现方式,通过自底向上的递推公式解决了如何从数塔顶部走到底部,使得路径上的数字之和最大的问题。
本文介绍了一个经典的动态规划问题——数塔问题,并提供了两种不同的实现方式,通过自底向上的递推公式解决了如何从数塔顶部走到底部,使得路径上的数字之和最大的问题。
数塔
Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 20737 Accepted Submission(s): 12462
Problem Description
在讲述DP算法的时候,一个经典的例子就是数塔问题,它是这样描述的:
有如下所示的数塔,要求从顶层走到底层,若每一步只能走到相邻的结点,则经过的结点的数字之和最大是多少?
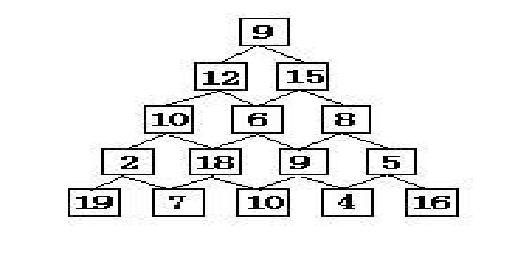
已经告诉你了,这是个DP的题目,你能AC吗?
有如下所示的数塔,要求从顶层走到底层,若每一步只能走到相邻的结点,则经过的结点的数字之和最大是多少?
已经告诉你了,这是个DP的题目,你能AC吗?
Input
输入数据首先包括一个整数C,表示测试实例的个数,每个测试实例的第一行是一个整数N(1 <= N <= 100),表示数塔的高度,接下来用N行数字表示数塔,其中第i行有个i个整数,且所有的整数均在区间[0,99]内。
Output
对于每个测试实例,输出可能得到的最大和,每个实例的输出占一行。
Sample Input
1 5 7 3 8 8 1 0 2 7 4 4 4 5 2 6 5
Sample Output
30
Source
最近一直研究图论,研究MST(最小生成树)算法,需要学习并查集,而并查集又是树结构,所以又去复习树去了,而最初的目的我只是想学习dp而已,我学完图的2种经典邻接结构时我认为我已经能做出数塔问题了(当初卡在数塔的结构问题上),好长时间没刷题了,今天花了几分钟完成它。
这道题我用自底向上递推 公式: vexs(i, j) = vexs(i, j) + Max{vexs(i+1, j), vexs(i+1, j+1)}
/******************************
*
* acm: hdu-2084
*
* title: 数塔
*
* time : 2014.6.5
*
*******************************/
//经典dp
#include <stdio.h>
#include <stdlib.h>
#define MAXVEX 101
typedef int VertexType;
VertexType vexs[MAXVEX][MAXVEX];
//dp方程,得到最优指标
//vexs(i, j) = vexs(i, j) + Max{vexs(i+1, j), vexs(i+1, j+1)}
void Max(int i, int j)
{
if (vexs[i+1][j] > vexs[i+1][j+1])
{
vexs[i][j] += vexs[i+1][j];
}
else
{
vexs[i][j] += vexs[i+1][j+1];
}
}
int main()
{
int C;
int N;
int i;
int j;
int k = 0;
scanf("%d", &C);
while (k < C)
{
scanf("%d", &N); //数塔的行数
for (i = 0; i < N; i++)
{
for (j = 0; j <= i; j++)
{
scanf("%d", &vexs[i][j]);
}
}
for (i = N-2; i >= 0; i--) //行序号
{
for (j = 0; j <= i; j++) //列序号
{
Max(i, j);
}
}
printf("%d\n", vexs[0][0]);
k++;
}
return 0;
}
规划规格(一样的),上面的程序用坐标当做参数,下面程序用数值代表参数。
公式:DP(i,j) = DP(i,j)+max{DP(i+1,j) , DP(i+1,j+1)}, 最终得到DP(0,0)为止
/******************************
*
* acm: hdu-2084
*
* title: 数塔
*
* time : 2014.6.5
*
*******************************/
//经典dp
#include <stdio.h>
#include <stdlib.h>
#define MAXVEX 101
typedef int VertexType;
VertexType vexs[MAXVEX][MAXVEX];
//dp方程,得到最优指标
//DP(i,j) = DP(i,j)+max{DP(i+1,j) , DP(i+1,j+1)}
int DP(int x, int y) //得到max最大点
{
return x > y ? x : y;
}
int main()
{
int C;
int N;
int i;
int j;
int k = 0;
scanf("%d", &C);
while (k < C)
{
scanf("%d", &N); //数塔的行数
for (i = 0; i < N; i++)
{
for (j = 0; j <= i; j++)
{
scanf("%d", &vexs[i][j]);
}
}
for (i = N-2; i >= 0; i--) //行序号
{
for (j = 0; j <= i; j++) //列序号
{
vexs[i][j] += DP(vexs[i+1][j], vexs[i+1][j+1]);
}
}
printf("%d\n", vexs[0][0]);
k++;
}
return 0;
}

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









