







目录
requests-html
Requsts库的作者Kenneth Reitz 又开发了requests-html 用于做爬虫。requests-html 是基于现有的框架 PyQuery、Requests、lxml、beautifulsoup4等库进行了二次封装,作者将Requests设计的简单强大的优点带到了该项目中。
官方文档:
http://html.python-requests.org/
GiHub项目地址:
https://github.com/kennethreitz/requests-html
安装:
pip install requests-html
基本使用
- 获取网页
下面的代码获取了体彩页面,返回的对象r是requests.Reponse类型,更确切的说是继承自前者的requests_html.HTMLResponse类型。这里其实和requests库的使用方法差不多,获取到的响应对象其实其实也没啥用,这里的关键就在于r.html这个属性,它会返回requests_html.HTML这个类型,它是整个requests_html库中最核心的一个类,负责对HTML进行解析。我们学习requests_html这个库,其实也就是学习这个HTML类的使用方法。
from requests_html import HTMLSession
url = "http://www.lottery.gov.cn/historykj/history_92.jspx?page=false&_ltype=dlt&termNum=0&startTerm=07001&endTerm="
session = HTMLSession()
r = session.get(url)
# 查看页面内容
print(r.html.html)- 获取链接
links和absolute_links两个属性分别返回HTML对象所包含的所有链接和绝对链接(均不包含锚点)。
# 获取链接
print(r.html.links)
print(r.html.absolute_links)- 获取元素
request-html支持CSS选择器和XPATH选择器两种语法来选取HTML元素。
CSS选择器语法,它需要使用HTML的find函数。
def find(self, selector: str = "*", *, containing: _Containing = None, clean: bool = False, first: bool = False, _encoding: str = None) -> _Find:
"""Given a CSS Selector, returns a list of
:class:`Element <Element>` objects or a single one.
:param selector: CSS Selector to use.
:param clean: Whether or not to sanitize the found HTML of ``<script>`` and ``<style>`` tags.
:param containing: If specified, only return elements that contain the provided text.
:param first: Whether or not to return just the first result.
:param _encoding: The encoding format.该函数有5个参数,作用如下:
- selector,要用的CSS选择器;
- clean,布尔值,如果为真会忽略HTML中style和script标签造成的影响(原文是sanitize,大概这么理解);
- containing,如果设置该属性,会返回包含该属性文本的标签;
- first,布尔值,如果为真会返回第一个元素,否则会返回满足条件的元素列表;
- _encoding,编码格式。
下面是几个简单的例子:
# 首页菜单文本
print(r.html.find('div#menu', first=True).text)
# 首页菜单元素
print(r.html.find('div#menu a'))
# 糗事百科段子内容
print(list(map(lambda x: x.text, r.html.find('div.content span'))))
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
def xpath(self, selector: str, *, clean: bool = False, first: bool = False, _encoding: str = None) -> _XPath:
"""Given an XPath selector, returns a list of
:class:`Element <Element>` objects or a single one.
:param selector: XPath Selector to use.
:param clean: Whether or not to sanitize the found HTML of ``<script>`` and ``<style>`` tags.
:param first: Whether or not to return just the first result.
:param _encoding: The encoding format.它有4个参数如下:
- selector,要用的XPATH选择器;
- clean,布尔值,如果为真会忽略HTML中style和script标签造成的影响(原文是sanitize,大概这么理解);
- first,布尔值,如果为真会返回第一个元素,否则会返回满足条件的元素列表;
- _encoding,编码格式。
XPath 常用规则:

XPath 的常用匹配规则示例如下:
//title[@lang='eng']表示选择所有名称为 title,同时属性 lang 的值为 'eng' 的节点,后面会通过 Python 的 lxml 库,利用 XPath 进行 HTML 的解析。
print(r.html.xpath("//div[@id='menu']", first=True).text)
print(r.html.xpath("//div[@id='menu']/a"))
print(r.html.xpath("//div[@class='content']/span/text()"))
- xlsxwriter
xlsxwriter模块主要用来生成excel表格,插入数据、插入图标等表格操作。
示例
talk is cheap,show me the code
- 开奖结果爬虫demo
打开网页,按F12可以查看html网页源码
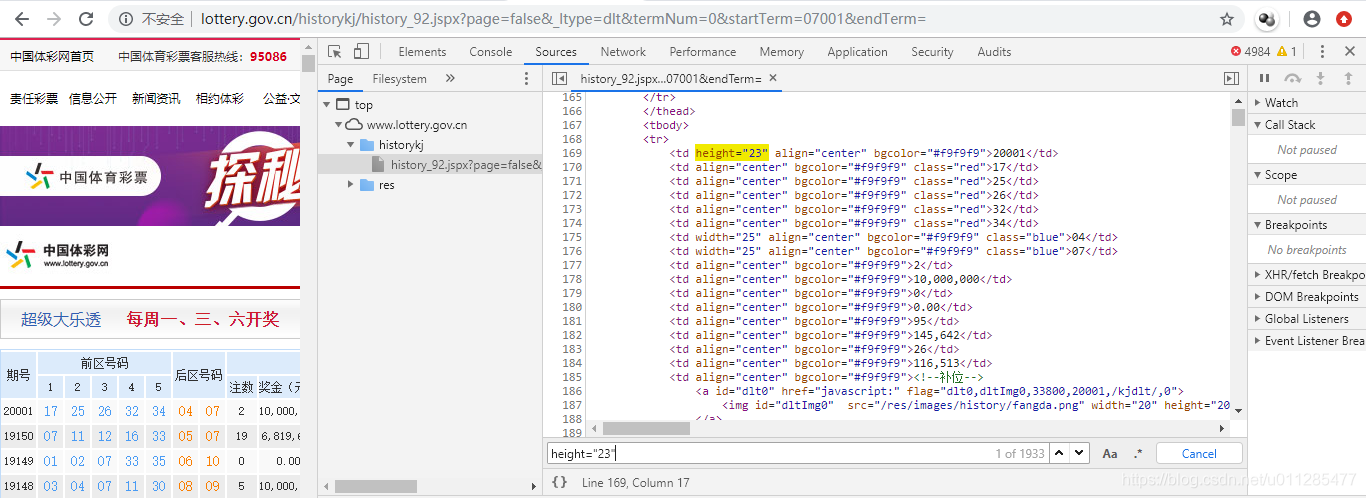
下面是一个简单的python爬虫代码,以爬取彩票开奖结果为例,保存到excel文件中。
import xlsxwriter
from requests_html import HTMLSession
def main():
url = "http://www.lottery.gov.cn/historykj/history_92.jspx?page=false&_ltype=dlt&termNum=0&startTerm=07001&endTerm="
session = HTMLSession()
r = session.get(url)
# 获取期号
numbers = r.html.xpath('//td[@height="23"]/text()')
# 获取红球号码
reds = r.html.xpath('//td[@class="red"]/text()')
# 获取蓝球号码
blues = r.html.xpath('//td[@class="blue"]/text()')
# 新建excel表
workbook = xlsxwriter.Workbook("daletou.xlsx")
# 新建sheet
worksheet = workbook.add_worksheet()
header = ("期号", "红-1", "红-2", "红-3", "红-4", "红-5", "蓝-1", "蓝-2")
worksheet.write_row(0, 0, header)
for i, number in enumerate(numbers):
red = reds[5 * i : 5 * i + 5]
blue = blues[2 * i : 2 * i + 2]
# 将数据插入到表格中,第i+1行,第1列,内容为number
worksheet.write(i + 1, 0, number)
red = list(map(int, red))
blue = list(map(int, blue))
worksheet.write_row(i + 1, 1, red)
worksheet.write_row(i + 1, 6, blue)
workbook.close()
session.close()
if __name__ == "__main__":
main()- 爬取表情包demo
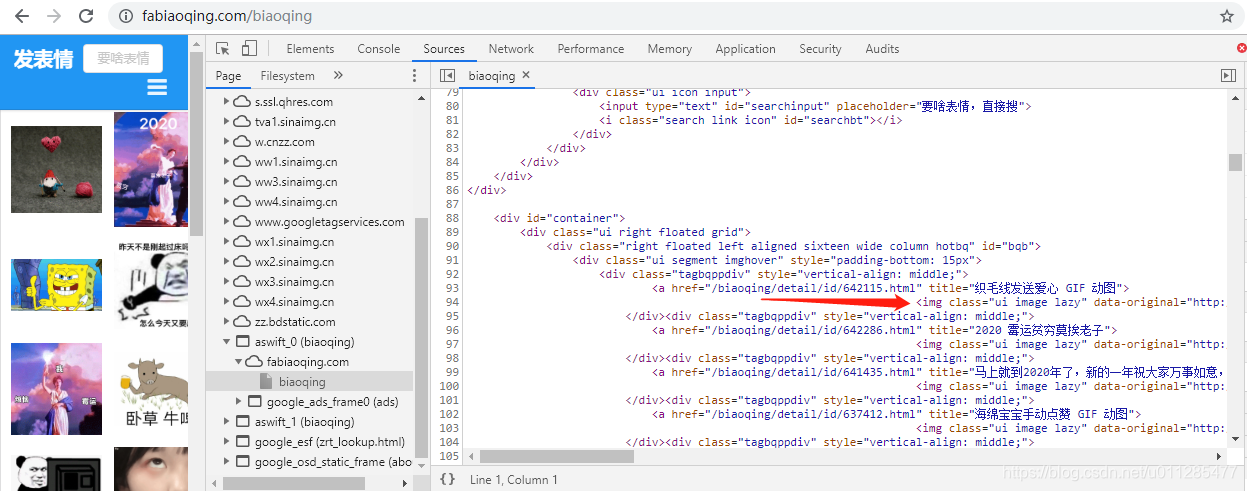
import requests
import os
from requests_html import HTMLSession
# 文件保存目录
path= 'C:/workspace/data/'
# 保存为.jpg格式
def save(respone,name):
with open(path + name + '.jpg','wb') as f:
f.write(respone)
# 保存为.gif格式
def savegif(respone,name):
with open(path + name + '.gif', 'wb') as f:
f.write(respone)
def main():
# 爬取表情包图片
url = "https://fabiaoqing.com/biaoqing"
session = HTMLSession()
r = session.get(url)
# 打印网页内容 或者 按F12在浏览器上查看
# print(r.html.html)
# 直接定位到img标签,具体分析,获取相应的数据
# print(r.html.find('img'))
result = r.html.xpath('//div[@class="tagbqppdiv"]/a/img')
# 下载图片
for idx in range(len(result)):
try:
temp_result = result[idx].attrs
image_name = temp_result['title']
img_url = temp_result['data-original']
print('第%d个,url:%s'%(idx+1,img_url))
connet = requests.get(img_url,timeout=15)
# 判断文件格式
if (img_url[-3:] == 'jpg'):
save(connet.content, image_name)
else:
savegif(connet.content, image_name)
except Exception as e:
print(e)
if __name__ == "__main__":
main()结果:
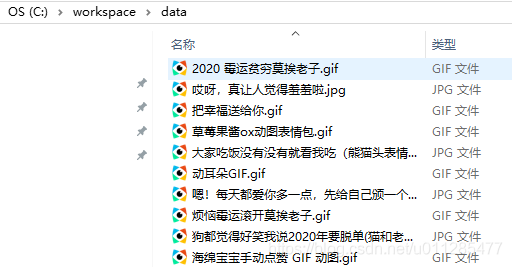
【参考】
[1] https://www.cnblogs.com/fnng/p/8948015.html

















 2903
2903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









