







SQL Layer 模块详解
摘要
本文将对 SQLdepth 模型中的关键模块进行详细解释,包括 Self Query Layer (SQL) 的工作原理、深度 bin 中心的计算方法以及如何确定深度范围的最小值和最大值。SQLdepth 是一种用于单目深度估计的自监督学习方法,通过构建 self-cost volume 来捕捉场景的内在几何结构,从而实现高效的深度估计。
1. Self Query Layer (SQL) 工作原理
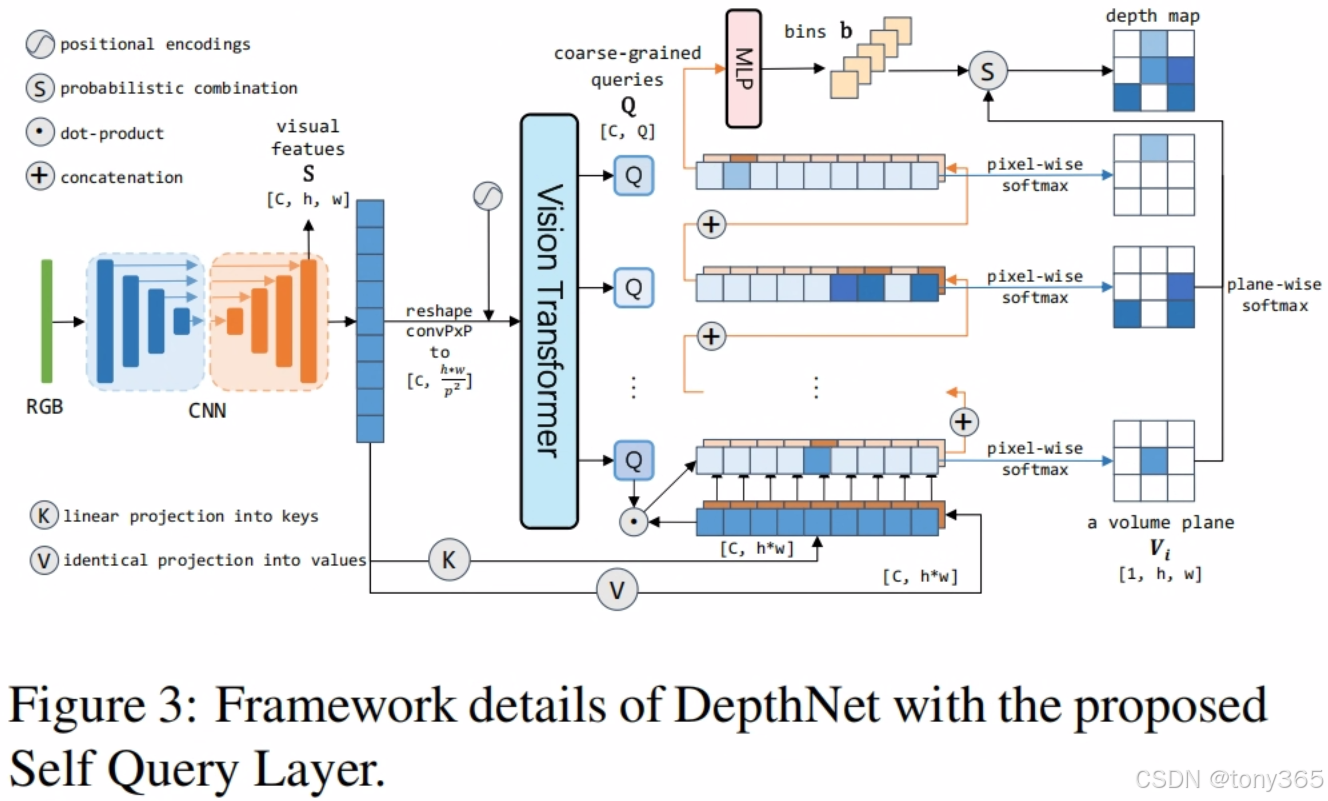
这个示意图个人感觉不是很清晰,代码中的Q是整合在一起的这里是分开的,所以感觉没有特别清晰。
总的来说sql模块 分解为2个模块一个是 概率,一个是bin
具体来说,概率:最终得到 n,q,h,w 表示的是每个像素位置在 q个深度的概率
bin: n,q表示的是q个深度,比如 0.01m, 0.1m, 3m,5m等q个深度值
那么加权之后可以得到每个像素的depth.
1.1 构建 self-cost volume
Self Query Layer 的核心在于构建一个 self-cost volume,用于存储像素和物体之间的相对距离信息。具体步骤如下:
-
提取即时视觉表示:
使用卷积层从输入图像中提取特征图S,形状为[batch_size, embedding_dim, height, width]。 -
生成粗粒度查询:
Q在一定程度上表示的是物体语义。
通过卷积操作和 Transformer 提取粗粒度查询Q,形状为[batch_size, Q, embedding_dim]。 -
计算相对距离:
使用点积计算每个查询与特征图中每个像素的相对距离,构建 self-cost volumeV,形状为[batch_size, Q, height, width]。
这里计算出每个像素与Q个物体的距离。
1.2 深度 bin 估计
深度 bin 用于估计连续深度。SQL 层通过以下步骤估计深度 bin:
-
应用像素级 softmax求概率
对 self-cost volume 的每个平面应用像素级 softmax,得到概率图p,形状为[batch_size, Q, height, width]。 -
特征聚合:求bin
使用概率图对特征图进行加权求和,得到聚合特征,形状为[batch_size, Q, embedding_dim]。
再经过MLP得到[batch_size, Q]
1.3 概率组合
将概率分布与深度 bin 中心相乘并求和,得到最终的深度图 depth,形状为 [batch_size, 1, height, width]。
2. 深度 bin 中心计算
2.1 公式解释
深度 bin 中心的计算公式如下:
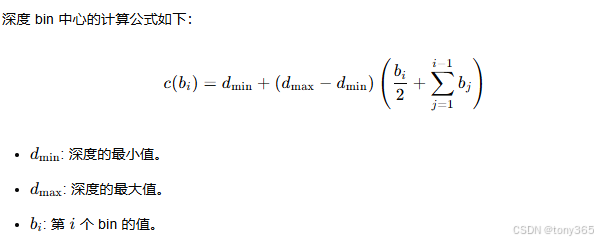
2.2 PyTorch代码实现
def calculate_bin_centers(bins, dmin, dmax):
# 计算深度 bin 的中心
n, d = bins.size()
bin_centers = dmin + (dmax - dmin) * (bins / 2 + torch.cumsum(bins, dim=1))
return bin_centers.view(n, d, 1, 1)
2.3 代码注释
-
输入:
bins: 深度 bin 的值,形状为[batch_size, num_bins]。dmin: 深度的最小值。dmax: 深度的最大值。
-
输出:
bin_centers: 深度 bin 的中心,形状为[batch_size, num_bins, 1, 1]。
3. 确定深度范围的最小值和最大值
3.1 数据集统计
根据训练数据集的统计信息来确定 dmin 和 dmax:
# 假设你有一个训练集的深度图列表 train_depth_maps
dmin = float('inf')
dmax = -float('inf')
for depth_map in train_depth_maps:
current_min = depth_map.min()
current_max = depth_map.max()
if current_min < dmin:
dmin = current_min
if current_max > dmax:
dmax = current_max
print(f"dmin: {dmin}, dmax: {dmax}")
3.2 手动设置
根据先验知识手动设置 dmin 和 dmax:
dmin = 0.001 # 假设最小深度为 1 毫米
dmax = 10.0 # 假设最大深度为 10 米
3.3 动态计算
使用一个小型的 Transformer 模块(mini-ViT)来预测深度范围:
class DepthRangePredictor(nn.Module):
def __init__(self, in_channels, embedding_dim, num_heads, num_layers):
super(DepthRangePredictor, self).__init__()
self.embedding_dim = embedding_dim
self.num_heads = num_heads
self.num_layers = num_layers
# 用于提取特征的卷积层
self.conv = nn.Conv2d(in_channels, embedding_dim, kernel_size=3, stride=1, padding=1)
# Transformer 编码器
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(embedding_dim, num_heads, dim_feedforward=1024),
num_layers=num_layers
)
# 用于预测深度范围的MLP
self.mlp = nn.Sequential(
nn.Linear(embedding_dim, 128),
nn.ReLU(),
nn.Linear(128, 2) # 输出dmin和dmax
)
def forward(self, x):
# 提取特征
features = self.conv(x) # 输入x的形状为 [batch_size, in_channels, height, width]
# features的形状为 [batch_size, embedding_dim, height, width]
# 重塑特征以适配Transformer
n, c, h, w = features.size()
features = features.view(n, c, -1).permute(2, 0, 1) # 调整维度为 [h*w, batch_size, embedding_dim]
# Transformer编码
encoded_features = self.transformer(features) # 输出形状为 [h*w, batch_size, embedding_dim]
# 取第一个编码特征进行预测
encoded_feature = encoded_features[0, :, :] # 形状为 [batch_size, embedding_dim]
# 预测深度范围
depth_range = self.mlp(encoded_feature) # 输出形状为 [batch_size, 2]
# 确保dmin < dmax
dmin = depth_range[:, 0]
dmax = depth_range[:, 1]
dmax = torch.max(dmax, dmin + 1e-6) # 确保dmax >= dmin
return dmin, dmax
3.4 使用预训练模型
如果使用的是预训练模型,dmin 和 dmax 可能已经包含在模型的参数中。例如,AdaBins 模型在训练时已经学习了深度范围的参数,可以直接使用。
3.5 自适应 bin 宽度
在 AdaBins 方法中,bin 宽度是自适应的,可以根据每个图像的内容进行调整。这种方法通过一个小型的 Transformer 模块(mini-ViT)来预测 bin 宽度向量 b,并使用这些宽度来计算深度 bin 的中心。
def calculate_bin_centers(b, dmin, dmax):
# 计算深度 bin 的中心
n, d = b.size()
bin_centers = dmin + (dmax - dmin) * (b / 2 + torch.cumsum(b, dim=1))
return bin_centers.view(n, d, 1, 1)
4. 总结
通过本文的详细解释,我们了解了 SQLdepth 模型中的 Self Query Layer (SQL) 的工作原理、深度 bin 中心的计算方法以及如何确定深度范围的最小值和最大值。这些模块共同作用,使得 SQLdepth 能够有效地从单目图像中估计深度,捕捉场景的细粒度几何结构。

















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









