







 探讨了在深度学习中如何有效调整模型参数,包括warmup预热策略、熊猫与鱼子酱机制,以及AutoDL在超参数优化上的应用,如随机搜索、贝叶斯优化、遗传算法等,重点介绍了百度PaddleHub的AutoDL如何利用哈密尔顿动力系统提升搜索效率。
探讨了在深度学习中如何有效调整模型参数,包括warmup预热策略、熊猫与鱼子酱机制,以及AutoDL在超参数优化上的应用,如随机搜索、贝叶斯优化、遗传算法等,重点介绍了百度PaddleHub的AutoDL如何利用哈密尔顿动力系统提升搜索效率。

16.55 工业检测上 实力分割 和语义分割的应用场景。
19.18 X 是计算量,Y是 表示模型的精度,还有个维度,圈圈的大小,圈圈越大,表示它的内存开销越大,
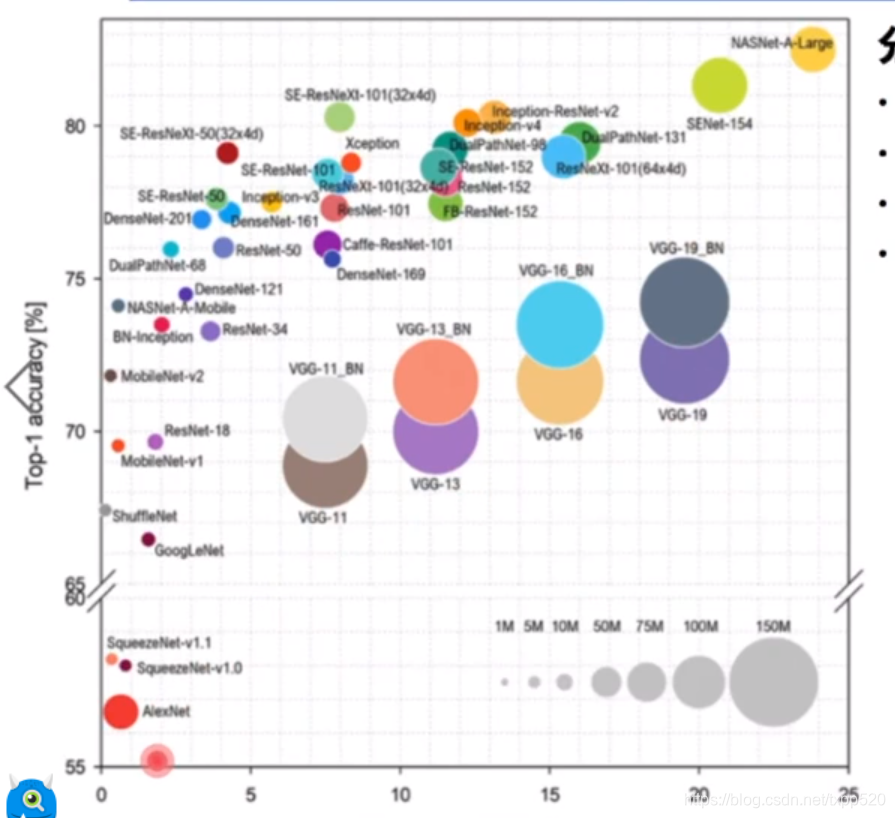
精度最高的是这种 基于 automl 做的模型,19.48
35.55

38.30 训练的预热。
在做 迁移学习的时候, 预训练的数据和你 现在的业务场景数据分布是不一样的,所以,怎么样调参更好呢?
经验上是 warmup,38.40 warmup的时间控制在 10%
41.45 AutoDL Finetune 两种机制 熊猫 和鱼子酱 机制
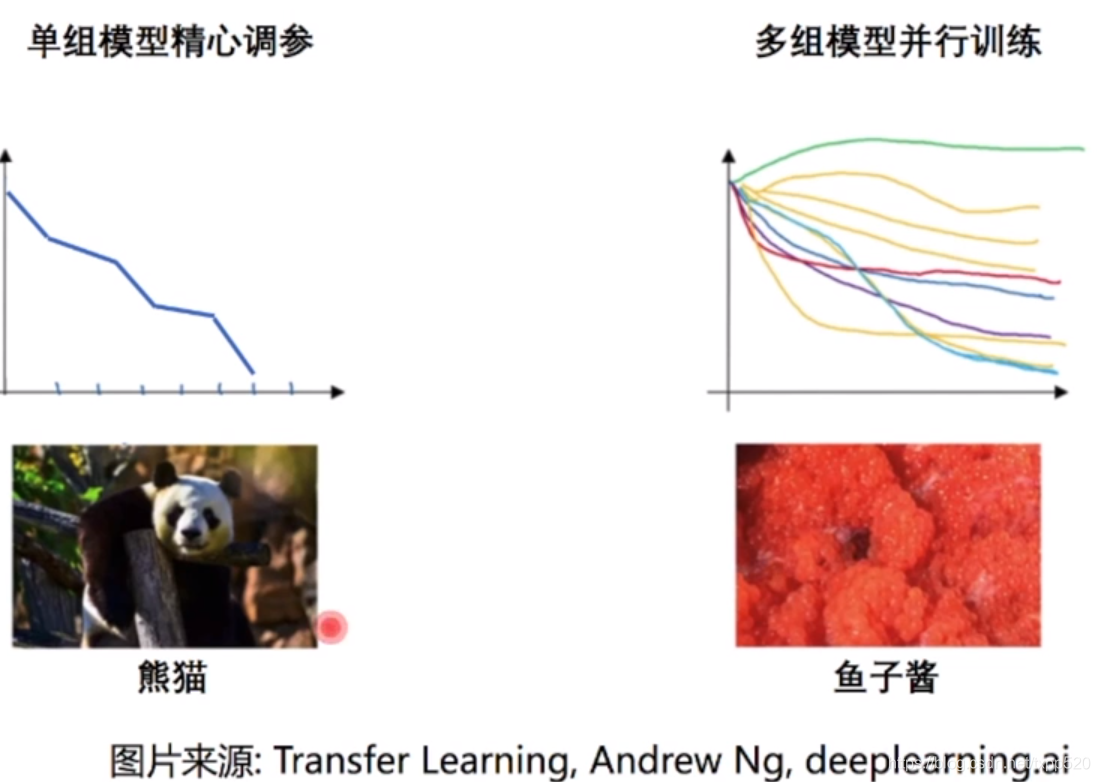
42.05 熊猫模型:我们有个模型,非常重要,非常大,我们每天调一点点。它的loss 一天比一天降低一点,这是一个人工的过程。前提是 调参者是个专家。知道自己的方向是对的,就能训练出来一个好的模型。X轴是 时间,y 是 loss
42.43 鱼子酱模式:随便搞个十几组超参,机器资源足够,让他们并行训练,跑着跑着肯定有几组参数会效果非常好。
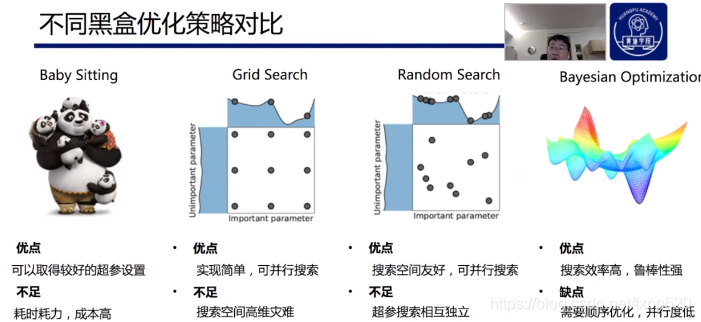
42.55 引出一个 黑盒优化的问题。怎么用更少的训练次数,找到最好的参数。
432.47 ,,两种 超参的 优化模式。
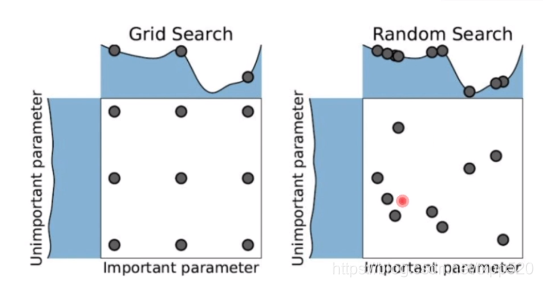
44.13 random search 能找到更好的超参的原因。
45.12 还有更好的做法是 贝叶斯优化。
还有一类算法 48.15 遗传算法和 粒子群算法
49.30
50.38 Google 提出来一种 PBT 的概念。 各种并行的参数之间 会 通讯,好的参数会告诉周围的
52.05 百度 paddlehub的 autodl 提出来一种 借鉴了 Google Docs 这种 PBT的思想,但是在随机扰动的策略那里 52.20 那里 用一种 哈密尔顿动力系统的数学方法,使得在搜索的过程当中有更大概率 调出 局部最优。在bert的一些语义任务做了一些 认证52.33 。通过这种 自动搜索参数的方法,取得比人工调参更好的效果。
这种自动搜索参数的方法在上面场景下好用?53.00
你有一个很好的与训练模型,你的数据量不是特别大,数据量大会导致我尝试一下要5,6天,是不合适的,
机器资源足够,我就可以 finetune。
autodl 还有一种 网络结构的搜索,53.22
占GPU资源更多,搜索量更大,因此超参的搜索 可行,有四五张卡,七八张卡,进行 超参的 autodl 搜索的比较合适的。

第四次科技革命,是预训练模型的革命。
54.30 传统算法比 现在算法差的对比。
55.45 autodl 现在还需要一些专家技巧,但是未来的门槛肯定会越来越低。因为后面专家们会摸索到一条更好的路了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











