



OpenAI 发布了三款全新的 AI 模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。这些新模型在多个方面超越了其前任——GPT-4o 系列,尤其在编程、指令执行和长文本理解上取得了显著进展。新一代的 GPT-4.1 系列不仅提供了更强的性能,还对成本和延迟进行了优化,进一步推动了 AI 技术在实际应用中的普及与落地。
GPT-4.1 系列在多个领域的性能提升,意味着它已成为更加适合真实世界任务的工具,尤其是在以下几个关键领域:
编程能力:GPT-4.1 在 SWE-bench Verified 基准测试中的得分达到了 54.6%,相比 GPT-4o 提升了 21.4%,超过 GPT-4.5 则提高了 26.6%。这一成绩使其成为目前编程领域的领先 AI 模型,特别适用于需要高精度代码生成和错误修正的场景。
指令执行能力:在 Scale 的 MultiChallenge 基准测试中,GPT-4.1 的得分为 38.3%,较 GPT-4o 提高了 10.5%。这一改进意味着 GPT-4.1 在理解和执行复杂指令上的能力得到了显著增强,能够更好地处理多样化的任务需求。
长文本理解:GPT-4.1 在 Video-MME 基准测试中表现出色,在“长无字幕”类别中取得了 72.0% 的得分,较 GPT-4o 提高了 6.7%。这一进步表明,GPT-4.1 在理解长文本内容方面具有更高的精确度,特别是在需要理解多重上下文信息的任务中表现尤为突出。

根据不同的应用场景,GPT-4.1 系列还推出了适用于不同任务需求的变种模型,进一步提升了 AI 在低延迟、高性能任务中的表现:
GPT-4.1 mini:GPT-4.1 mini 相比 GPT-4o 在多个基准测试中表现优异,同时将延迟减少了近 50%, 成本降低了 83%。它不仅保持了和 GPT-4o 相当的智能水平,还提供了更低的响应时间和更高的性价比,特别适合需要快速响应的任务,如实时数据处理和低延迟计算任务。
GPT-4.1 nano:作为最小的模型,GPT-4.1 nano 是专为低延迟和低成本需求设计的 AI 模型。它在 MMLU 上得分 80.1%,在 GPQA 上得分 50.3%,在 Aider polyglot coding 上得分 9.8%,这些成绩均优于GPT-4o mini。GPT-4.1 nano适用于分类、自动补全等任务,尤其是在计算资源有限的环境中,它依然能够提供卓越的性能。
GPT-4.1 系列的升级不仅在各类基准测试中表现卓越,更在实际应用中展现了强大的潜力。尤其是在智能代理系统的领域,GPT-4.1 的改进使其成为一个理想选择。智能代理可以独立执行任务,如从大文档中提取信息、处理客户请求、自动化软件工程等,这些功能的提升得益于 GPT-4.1 在指令理解和长文本处理上的强大能力。
开发者可以通过 Responses API 等工具,构建更加高效和可靠的代理系统,使其在复杂环境中也能独立完成任务,降低了人力干预的需求,并提高了工作效率。
随着 GPT-4.1 系列的发布,GPT-4.5 Preview 将在 2025 年 7 月 14 日正式停用。GPT-4.5 曾作为一款研究预览版,探索大规模计算模型的潜力,但随着 GPT-4.1 的推出,它在性能、成本和延迟方面的优势使得 GPT-4.5 不再适合持续使用。GPT-4.5 在创作、写作质量、幽默感等方面的创新,将继续融入到未来的 API 模型中,以确保这些独特的特点不被遗失。
GPT-4.1 系列不仅提供了强大的性能优势,还通过优化延迟和降低成本,显著提升了 AI 模型的适用性。随着 GPT-4.1 系列的全面应用,开发者将能在多种任务场景中获得更高效、更智能的解决方案。
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 能够处理最多 100 万个 tokens 的上下文——相比于之前的 GPT-4o 模型的 128,000 个 tokens,提升了很多。100 万个 tokens 相当于超过 8 份完整的 React 代码库,因此长上下文特别适合处理大型代码库或大量长文档。
目前 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 已向所有开发人员推出。
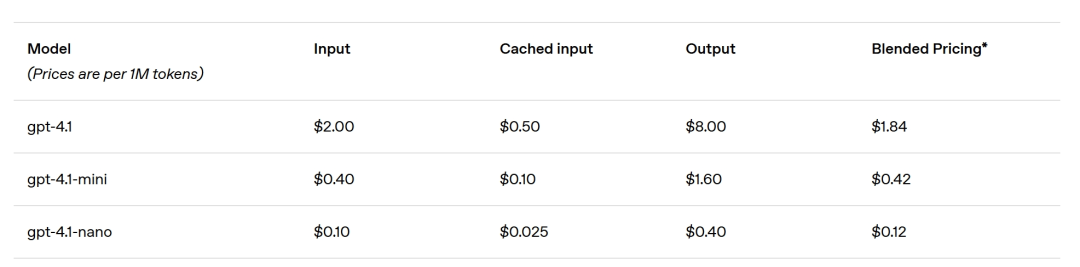
GPT-4.1 输入/输出费用为每百万 token 2 美元和 8 美元,较 GPT-4o 便宜 26%。提示词缓存折扣提高至 75%,长上下文无额外费用。
大模型从理论到应用开发
必读这三本!

《大模型技术30讲》
塞巴斯蒂安·拉施卡|著
叶文滔 | 译
GitHub 项目 LLMs-from-scratch(star数44k)作者、大模型独角兽公司 Lightning AI 工程师倾力打造,全书采用独特的一问一答式风格,探讨了当今机器学习和人工智能领域中最重要的 30 个问题,旨在帮助读者了解最新的技术进展。
内容共分为五个部分:神经网络与深度学习、计算机视觉、自然语言处理、生产与部署、预测性能与模型评测。每一章都围绕一个问题展开,不仅针对问题做出了相应的解释,并配有若干图表,还给出了练习供读者检验自身是否已理解所学内容。

《从零构建大模型》
塞巴斯蒂安·拉施卡|著
覃立波,冯骁骋,刘乾 | 译
全网疯传的大模型教程,由畅销书作家塞巴斯蒂安•拉施卡撰写,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。
在本书中,读者将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。还有惊喜彩蛋 DeepSeek,作者深入解析构建与优化推理模型的方法和策略。

《大模型应用开发极简入门:基于GPT-4和ChatGPT(第2版)》
奥利维耶·卡埃朗,[法] 玛丽–艾丽斯·布莱特 | 著
何文斯 | 译
深受读者喜爱的大模型应用开发图书升级版,作者为初学者提供了一份清晰、全面的“最小可用知识”,带领你快速了解 GPT-4 和 ChatGPT 的工作原理及优势,并在此基础上使用流行的 Python 编程语言构建大模型应用。
升级版在旧版的基础上进行了全面更新,融入了大模型应用开发的最新进展,比如 RAG、GPT-4 新特性的应用解析等。随书赠 DeepSeek × Dify 应用开发案例,书中还提供了大量简单易学的示例,帮你理解相关概念并将其应用在自己的项目中。


















 1
1

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









