







SVA机制
假设现在有一个用户进程分配了一块内存空间,并让PCIE设备把数据写到这块内存中。在有 IOMMU 的情况下,这个过程可以用下图来表示:
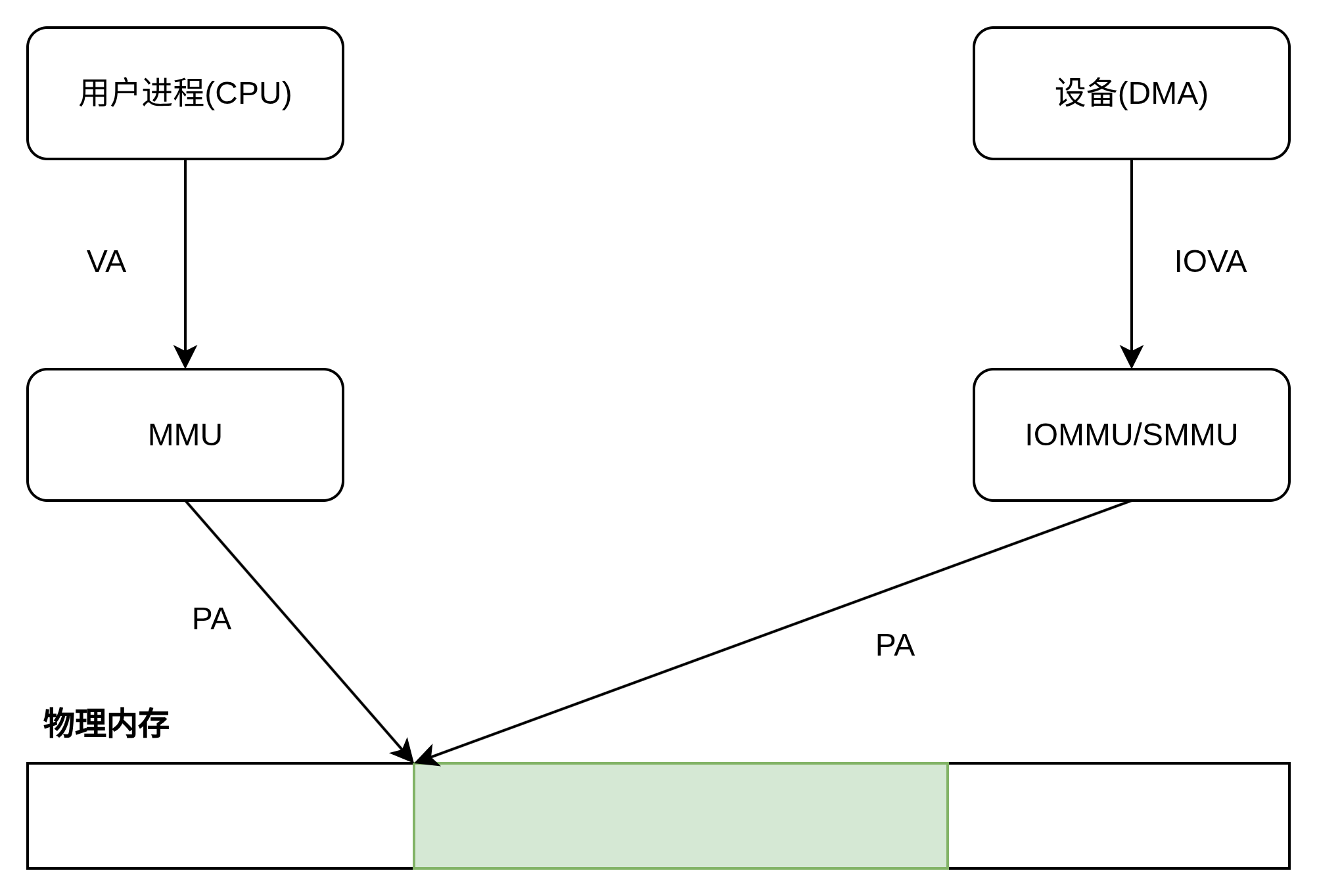
首先用户进程分配一块内存空间,用户进程看到的是 VA, 该 VA 对应到 PA,然后 IOMMU 将此 PA 映射到IOVA,设备看到的是 IOVA。那问题来了:
- 问题1:用户进程分配内存时,操作系统给进程分一个 VA,此时不一定会把 VA 映射到真正的内存空间上,可能要等到真正用内存的时候才会映射上去,也就是说用户进程拿到一个 VA,此时根本就没有对应的 PA,那谁也没法把这个根本不存在 PA 映射到 IOVA 上。
- 问题2:在用户进程的生命周期中,操作系统是可以改变 VA 和 PA 的映射关系的,比如迁移页面、交换到SWAP。这边设备还在 DMA 操作原来的 PA 呢,那边操作系统吧唧一下这个 PA 的内存切去做别的事情了。这不就乱套了吗?
解决上述问题最直接的方法是强行让 VA 先跟 PA 映射好,并且把这个关系给 pin 住(即不允许操作系统中途改变这个关系)。这个方法很直接,但对用户进程使用内存的方案限制比较大。
于是有了让设备侧发起缺页的诉求。如果 VA 没有映射到 PA 上,那 IOVA 也先不映射到 PA 上,设备访问 IOVA 时,SMMU 发现没有对应的 PA ,此时再发起缺页补页的请求。但是 SMMU 和 MMU 各有各的页表,如果分别各补各的页,那怎么保证最后 VA 和 IOVA 都是映射到一个 PA 上的呢?世界破破烂烂,总有人缝缝补补,为了解决PA映射一致性的问题,于是又有了让 SMMU 和 MMU 共页表的诉求。SMMU 和 MMU 共用页表,这个釜底抽薪的设计,不仅保持了PA映射的一致,同时也确保了 IOVA == VA,设备和CPU之间共用指针。这样只要补页,那 SMMU 和 MMU 都同时补上了,如果页面迁移了,那 SMMU 和 MMU 的页表都会修改,因为本来就是一个页表嘛。
于是 SVA 就被发明出来了(ARM 叫它 SVA,intel 叫它 SVM,SVA 和 SVM 指的是同一个特性)。
SVM实现的关键在IOMMU, 由于当前市面上基本找不到支持SVM的服务器/个人PC,所以我们用QEMU模拟的INTEL-IOMMU搭建一个测试环境,学习和验证SVM/SVA机制。
主机和虚拟机环境
主机os:
- OS: Ubuntu 24.04.3 LTS x86_64
- Kernel: 6.14.0-37-generic
- CPU: Intel i7-8565U (8) @ 4.600GHz
- GPU: NVIDIA GeForce MX250
- GPU: Intel WhiskeyLake-U GT2 [UHD Graphics 620]
虚拟机os:
验证环境使用的虚拟机OS 和HOST OS版本完全相同,由于SVA机制是比较新的特性,需要较新的LINUX KERNEL和QEMU版本。
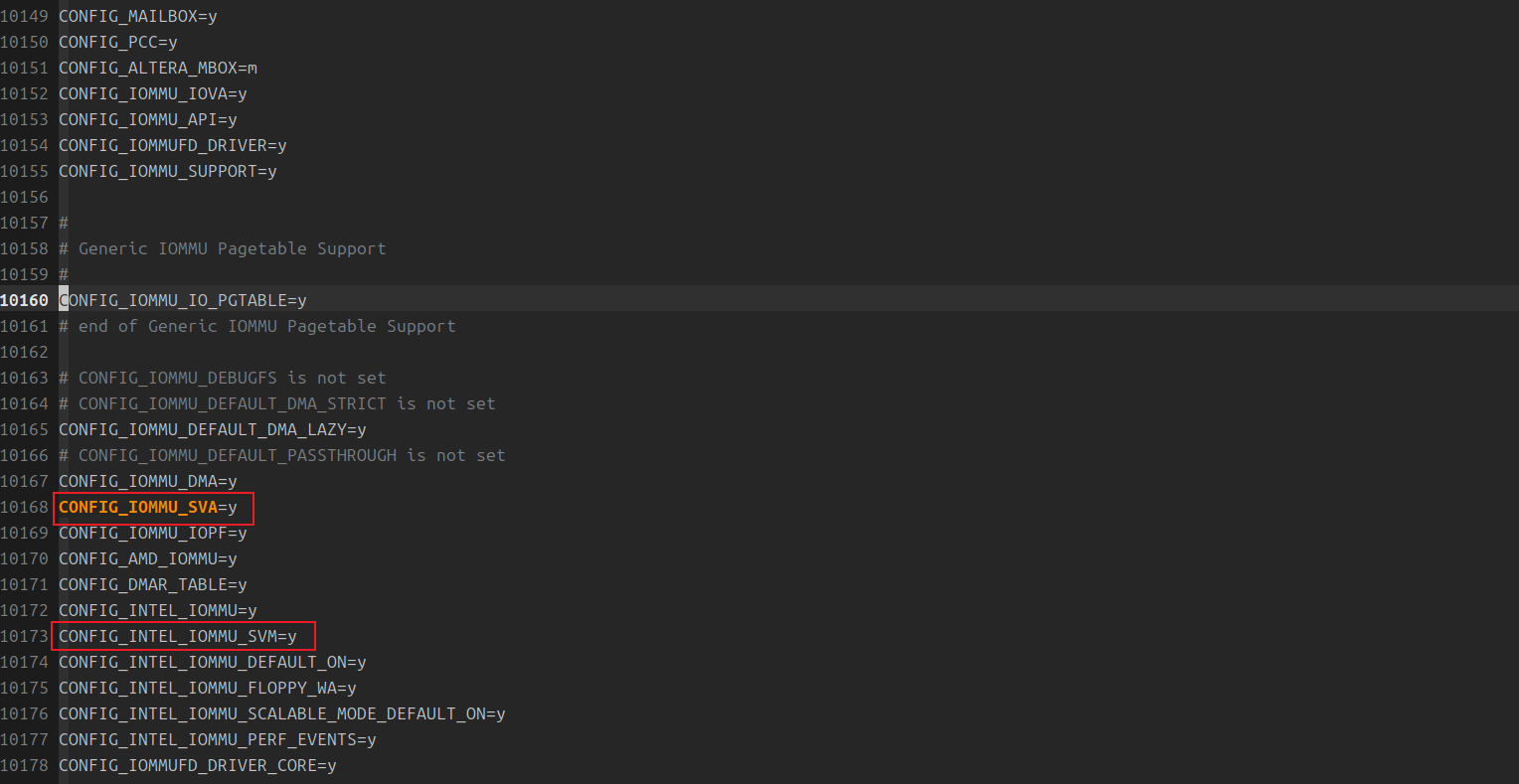
确认虚拟机OS内核启用了SVA
测试运行在VM中,需要VM OS KERNEL支持SVA 和IOMMU配置,由于HOST 和VM安装的是同一个版本的OS,所以在HOST检查相关配置CONFIG_IOMMU_SVA等是否开启,经过验证,ubuntu-24.04.3默认开启了对SVA的支持:
QEMU版本(运行于HOST):
此版本是WIP for SVM的版本,还未合入QEMU mainline,基于qemu主线10.1.x开发,算是很新的了,其中实现了一个支持SVM的模拟 PCIE Device,使用此仓库的svm_v3分支.
git clone https://gitee.com/tugouxp/svm-pasid-qemu.git
模拟PCIe设备驱动和用户态测试用例(运行于VM)
git clone https://gitee.com/tugouxp/qemu-in-guest-svm-demo.git
测试用例项目下的QEMU目录是一个submodule,指向了本测试使用QEMU版本,也就是上面提供的QEMU仓库中的版本。

主机上编译QEMU
下载支持PASID/SVM的仓库代码
git clone https://gitee.com/tugouxp/svm-pasid-qemu.git安装配置&编译依赖包
sudo apt install python3-sphinx-rtd-theme libp11-kit-dev libcurl4-openssl-dev libjson-c-dev libcurl4-doc libidn-dev libkrb5-dev libldap2-dev librtmp-dev libssh2-1-dev p11-kit-doc libusb-dev libgcrypt20-dev libbz2-dev libssh-dev lz4 liblzfse-dev libgtk2.0-dev acpica-tools libnfs-dev python3-dev gvncviewer qemu-utils libslirp-dev切换到svm_v3分支,配置QEMU:
./configure --target-list=x86_64-softmmu,x86_64-linux-user,arm-softmmu,arm-linux-user,aarch64-softmmu,aarch64-linux-user --enable-kvm --enable-debug-tcg --enable-debug-info --enable-debug --disable-strip --enable-sdl --enable-vnc --enable-virtfs --enable-fdt --extra-cflags="-O0 -g" --prefix=/home/czl/Workspace/native/install --enable-slirp --enable-virtfs --enable-vhost-net --enable-vhost-user --enable-vhost-kernel --enable-libnfs --enable-cap-ng --enable-linux-aio然后执行 make && sudo make install编译安装:

安装虚拟机
使用如下命令安装虚拟机,安装ubuntu-24.04.3。
$ qemu-img create -f qcow2 test-vm-1.qcow2 60G
$ qemu-system-x86_64 -machine -q35 -m 4096 -enable-kvm test-vm-1.qcow2 -cdrom ./ubuntu-24.04.3-desktop-amd64.iso启动虚拟机
/home/czl/Workspace/svm-qemu/install/bin/qemu-system-x86_64 -cpu host,+mtrr,+ssse3,sse4.1,+sse4.2,+pdpe1gb,+pse36,+pae,+lm,+nx -m 4096 -smp 4 --enable-kvm -drive file=./test-vm-1.qcow2,if=virtio -machine q35,kernel-irqchip=split -device svm -device intel-iommu,intremap=on,caching-mode=on,aw-bits=48,x-scalable-mode=on,x-flts=on,svm=true,device-iotlb=true,x-pasid-mode=true,dma-translation=true参数说明:
1. -cpu host, +pdpe1gb,+pse36,+pae,+lm,+nx: qemu 支持多种CPU类型,用如下命令可以得到当前QEMU支持的CPU类型。
/home/czl/Workspace/svm-qemu/install/bin/qemu-system-x86_64 -cpu ?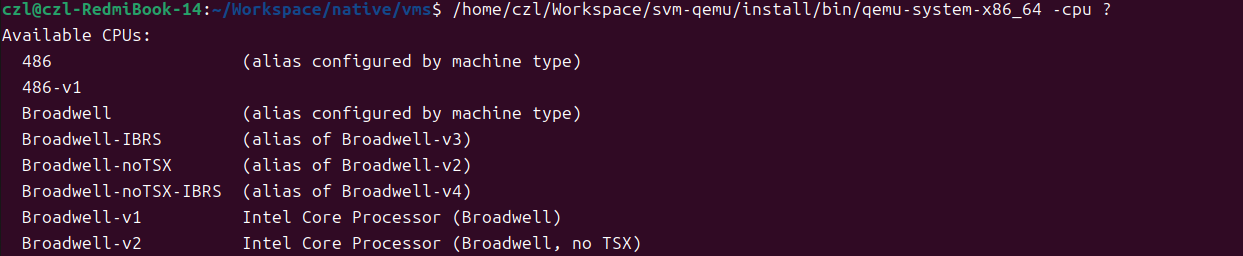
其中-cpu host是说,让VM中的CPU和HOST CPU支持同样的FEATURE

特别是FEATURE pdpe1gb,它表示系统支持1G巨页,因为我们的VM中测试用例需要用到1G巨页,所以必须把pdpe1gb特性传递给VM CPU。
2. -device svm -device intel-iommu,intremap=on,caching-mode=on,aw-bits=48,x-scalable-mode=on,x-flts=on,svm=true,device-iotlb=true,x-pasid-mode=true,dma-translation=true
-device svm表示将QEMU实现的支持PASID和SVM的PCIE模拟设备透给虚拟机,加入此参数后,虚拟机中会出现对应的PCIE设备。
-device intel-iommu ....:表示使虚拟机支持INTEL IOMMU模拟设备,这样虚拟机中也就有了IOMMU,这个IOMMU非硬件的,而是QEMU 模拟的intel-iommu设备。
启动虚拟机后,查看对巨页的支持能力,如下图所示,显示是支持的:
sudo cat /proc/cpuinfo |grep pdpe1gb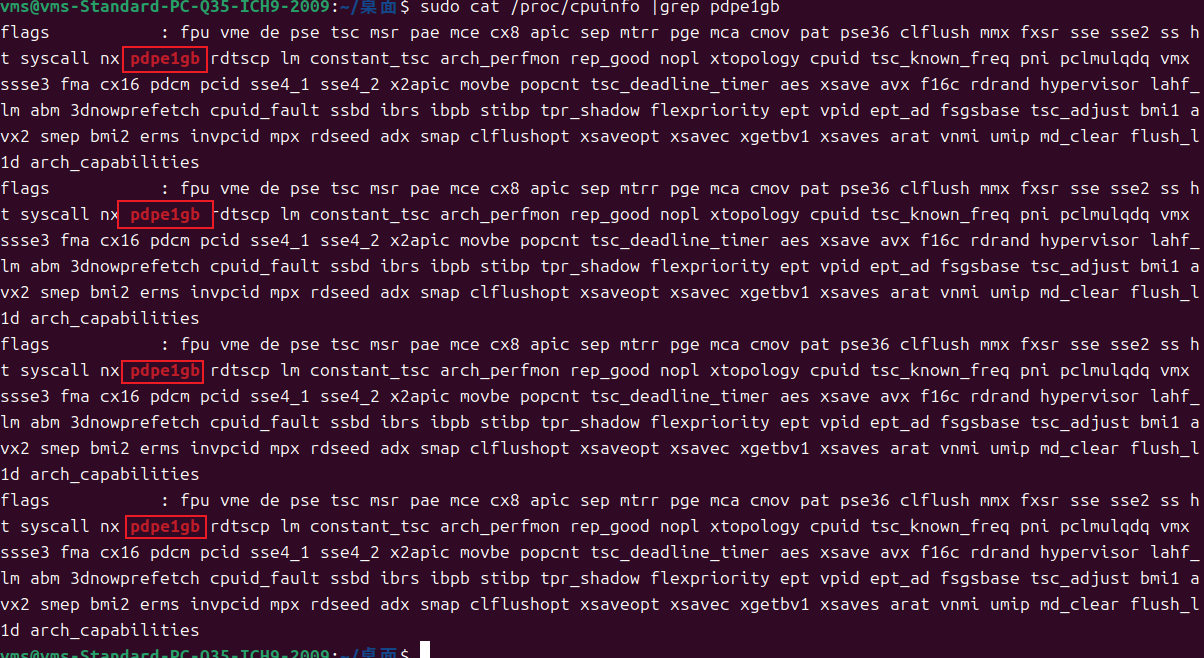
配置VM内IOMMU和1G巨页支持
修改虚拟机/etc/default/grub文件,在GRUB_CMDLINE_LINUX_DEFAULT添加如下配置,之后执行sudo update-grub更新配置:
pci=realloc=on intel_iommu=on,sm_on default_hugepagesz=1G hugepagesz=1G hugepag之后重启虚拟机,查验IOMMU和巨页配置是否OK:

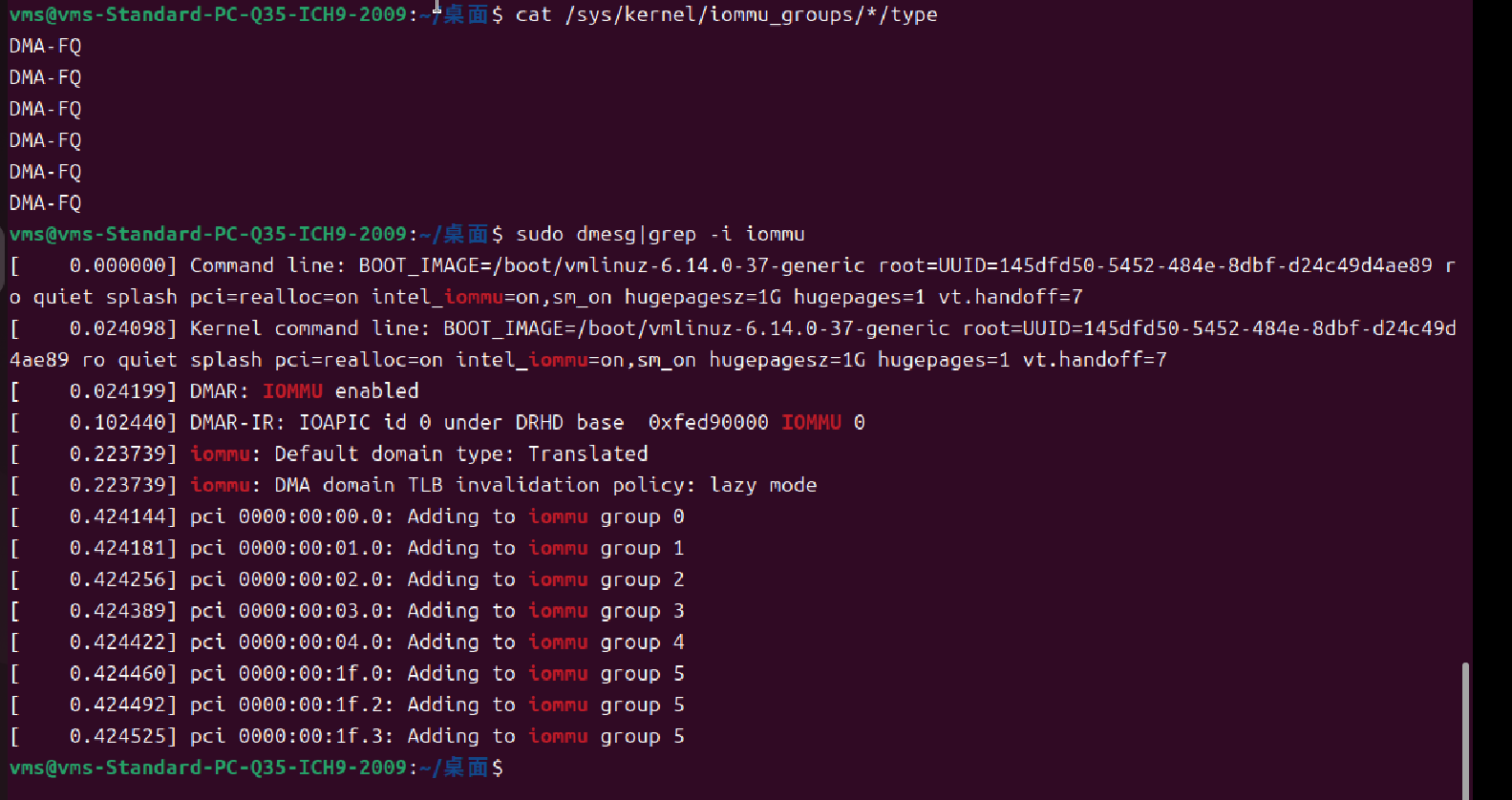
1G 巨页支持:

确认SVM PCIE模拟设备存在
可以看到,VM内模拟PCIE设备BDF为00:03.0.其VENDOR ID,DEVICE ID和QEMU中模拟设定的完全一致,也可VM内SVM设备的驱动给定的匹配设备信息完全一致。
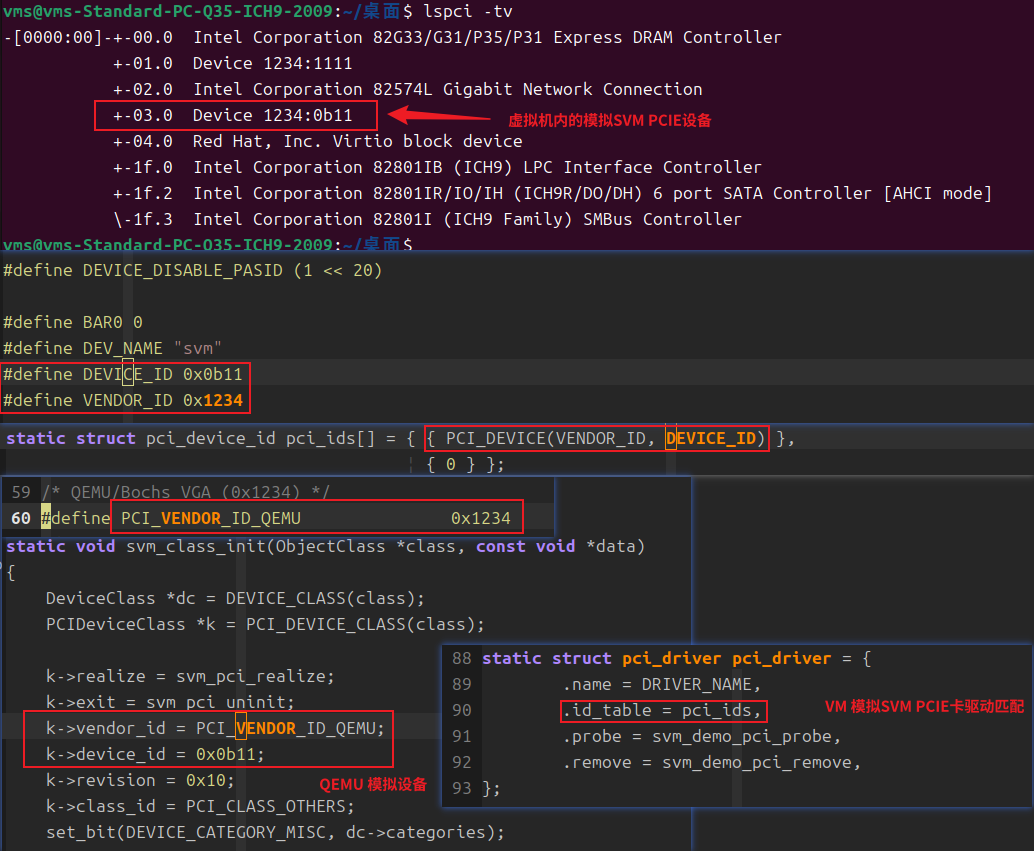
模拟PCIE设备的支持信息,可以看到,SVM 模拟PCIE设备是一个"Root Complex Intergrated Endpoint", 说明模拟设备是继承到了RC中的终端设备,此类型的设备在LINUX内核中用PCI_EXP_TYPE_RC_END表示,说明它是直接连接在RC内部的,不是通过PCIE插槽插上区的,而是物理上集成在 CPU 的 Root Complex 内部的端点设备。它的上游就是Root Complex本身,没有中间的PCIE BUS和switch.因为走的是片内互连,而非外部PCIe总线,所以访问延迟会比较低。 这种设备是SVM/SVA 特性的首批支持者和主要使用者。因为将集成GPU或加速器的地址空间与CPU进程统一管理,能带来巨大的性能提升和编程简化。
由于是内部集成设备,通常无法进行物理隔离的透传(例如VFIO passthrough),因为它与CPU/内存控制器共享硅片和电源域。另外,QEMU模拟了1M的MMIO,用于VM中的驱动配置PCIE,MMIO位置在BAR0.
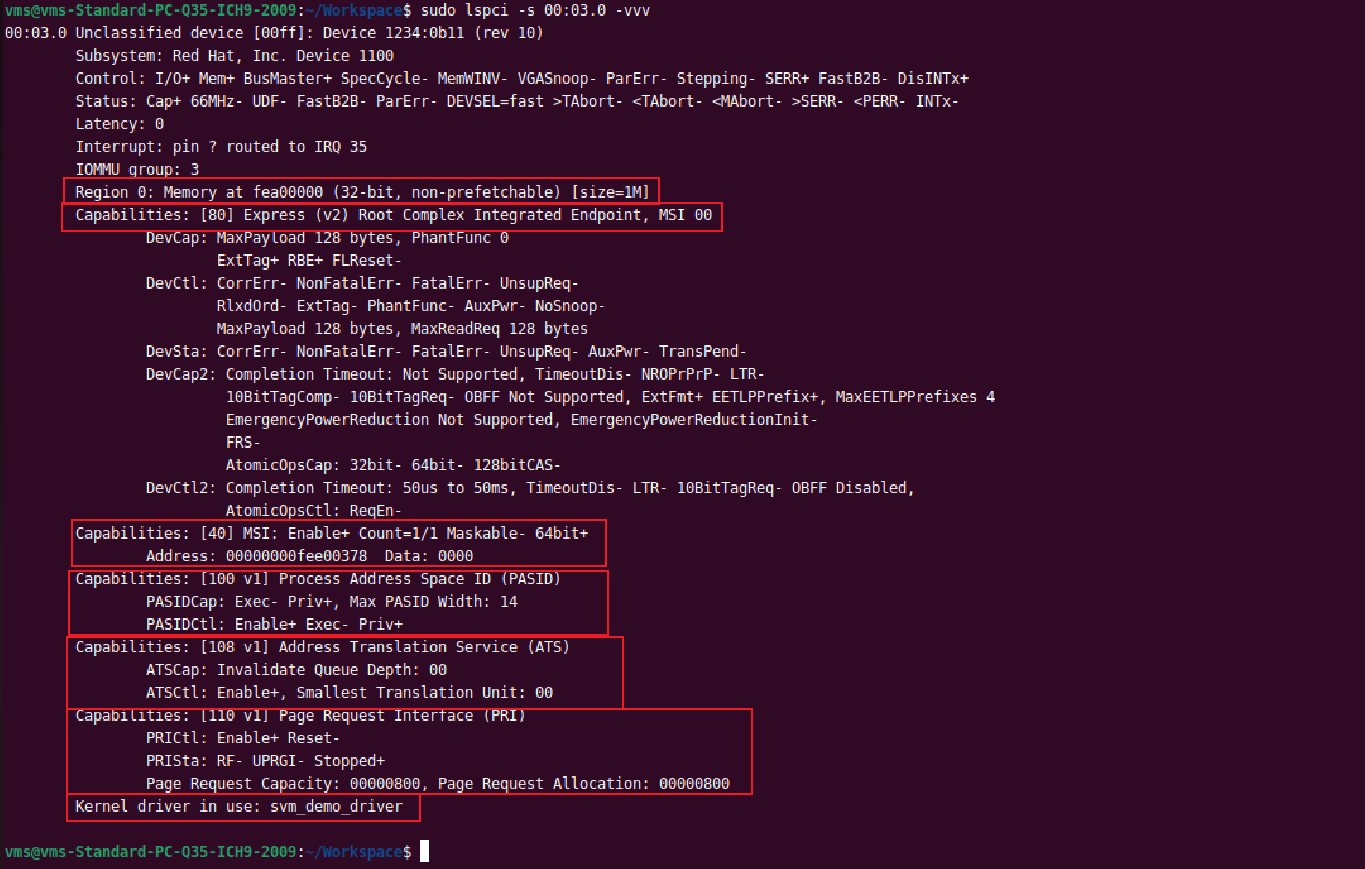
可以看到,安装好驱动svm_demo_driver.ko后,支持SVM价值最重要的PASID 支持能力已经被ENABLE了。驱动安装成功后,SVM设备将以字符设备节点的形式提供功能:

运行VM中的测试用例
下载测试代码:
git clone https://gitee.com/tugouxp/qemu-in-guest-svm-demo.git编译:
VM中运行测试:
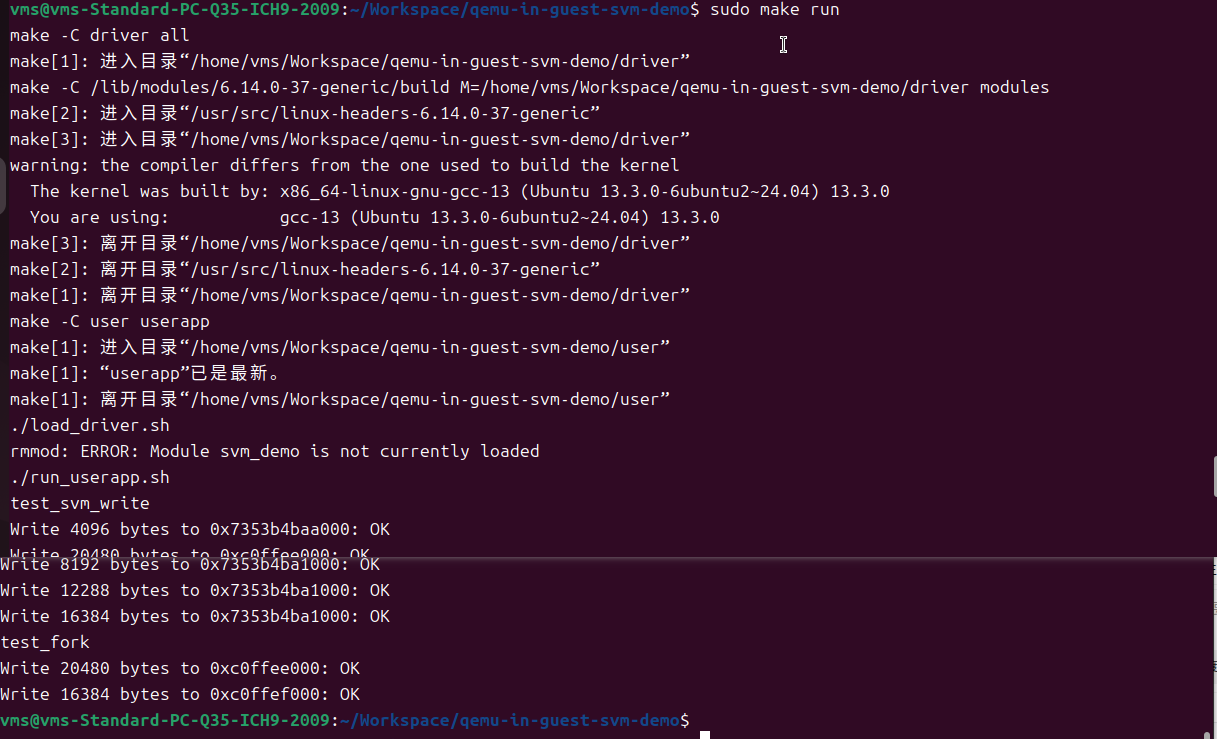
HOST OS中QEMU模拟LOG:
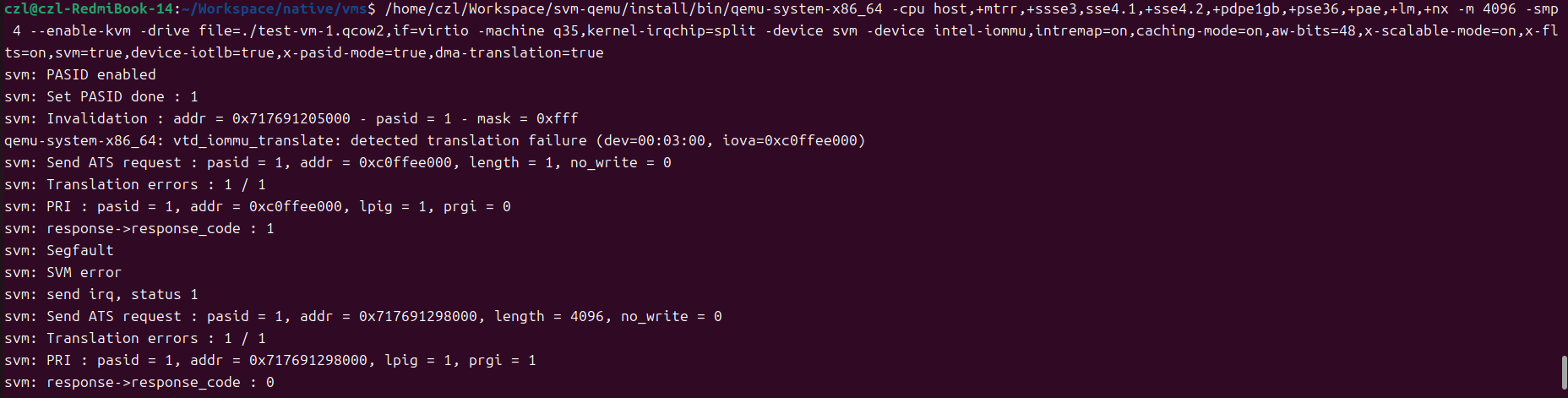
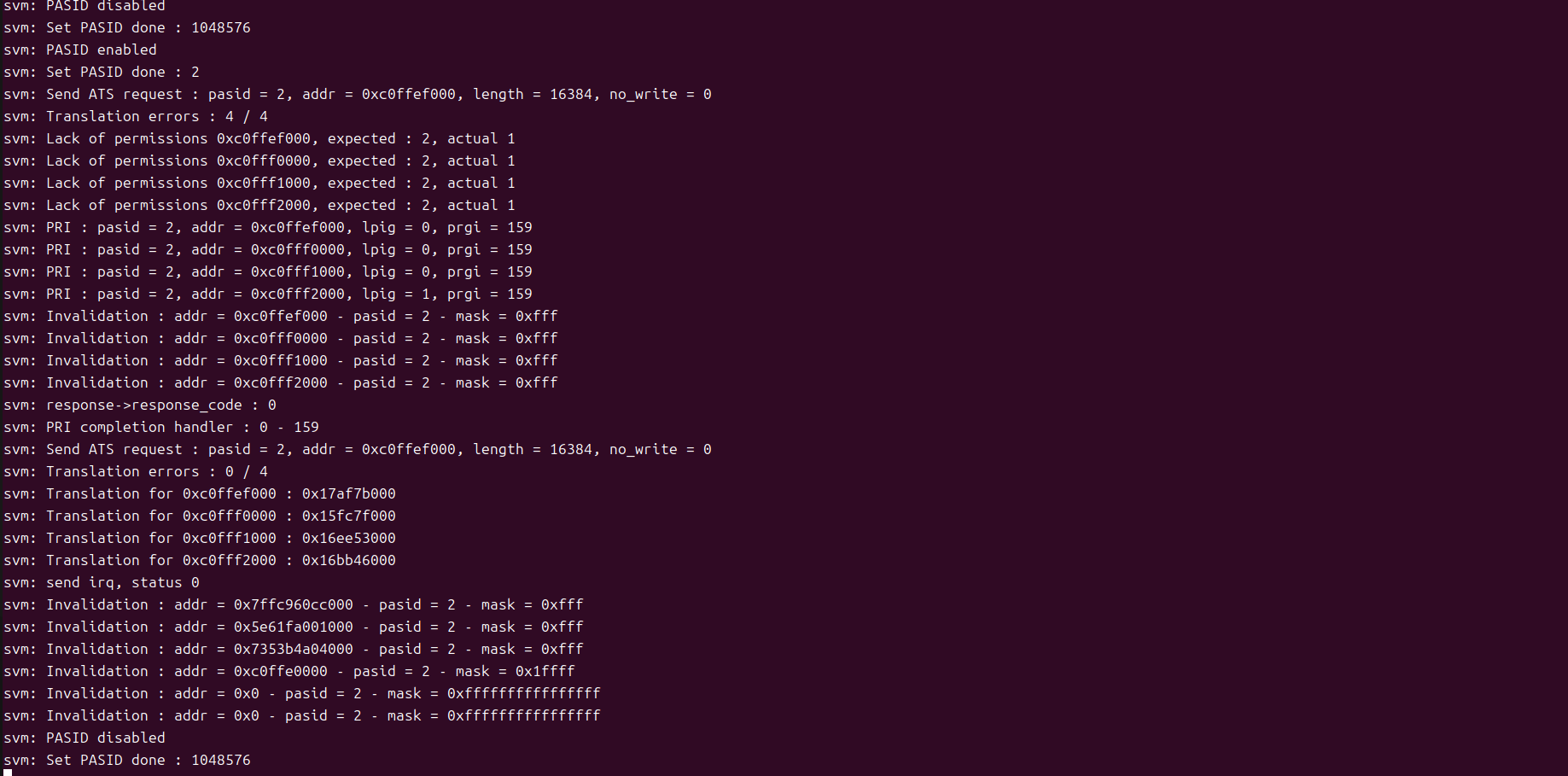
至此,我们构建了一个完美的学习目标——在QEMU模拟的Intel IOMMU环境中探索SVM,在没有硬件平台的情况下,这个环境是非常不错的学习IOMMU/SVM机制的平台。
QEMU intel-iommu WIP 和QEMU主线的关系
本实验使用的是社区WIP开发的成果,当前还并没合入主线,根据分析仓库提交日至来看,WIP相关提交是基于主线36076d24f0开发的,TAG大概是v10.1.0-1713-g36076d24f0附近,说明开发工作是最近开始的,并且距离主线还不太远,只有11个提交记录(下图蓝色框住的部分)。
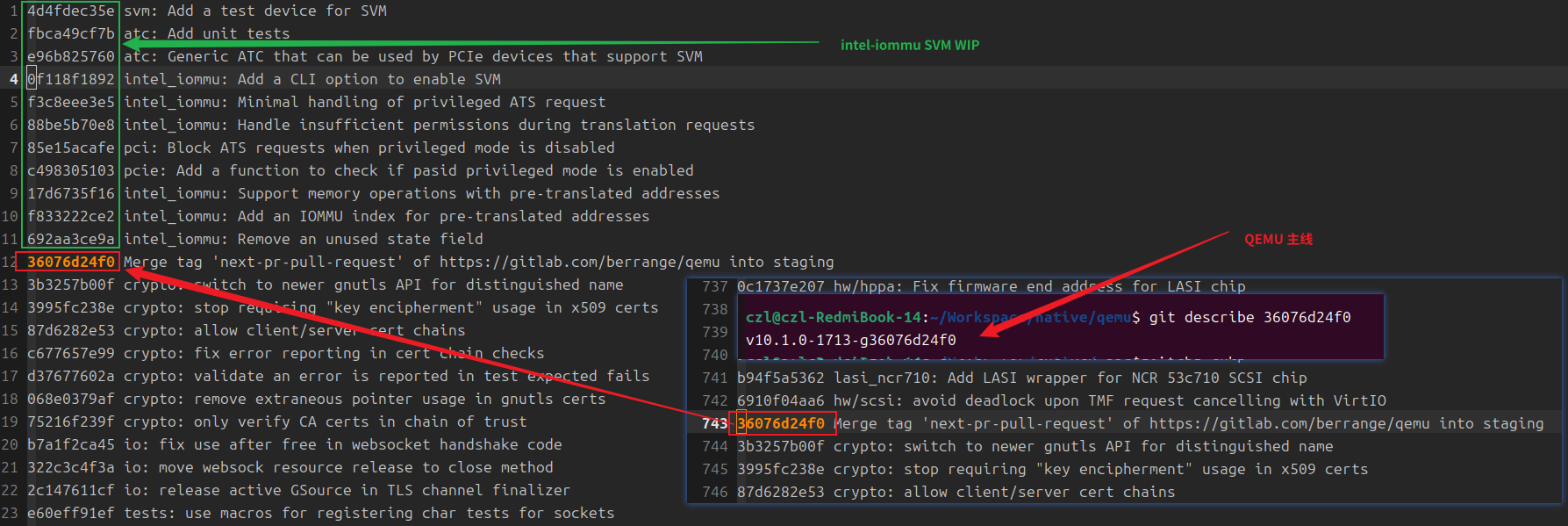
分析改动文件,发现这11笔提交主要包含两个方面的改动,1。增加支持SVM PASID的模拟PCIE设备实现svm.c。2.对intel-iommu支持SVM机制的改动,包括PASID, ATC等等模块。
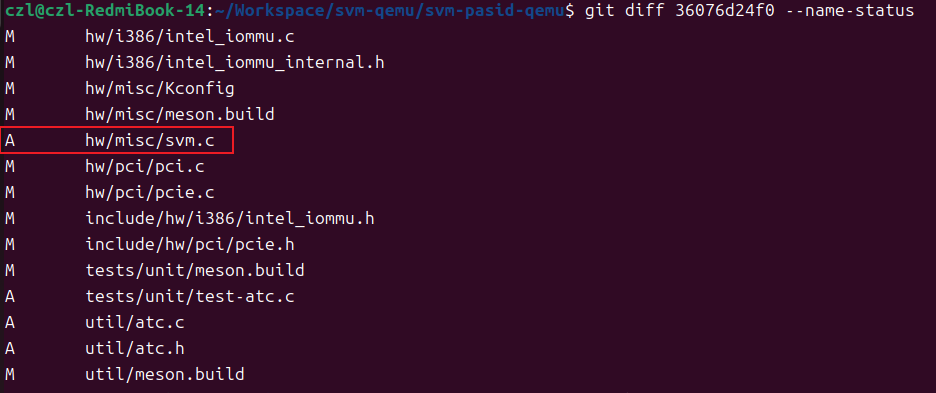
实现分析
SVI PCIE设备 MMIO
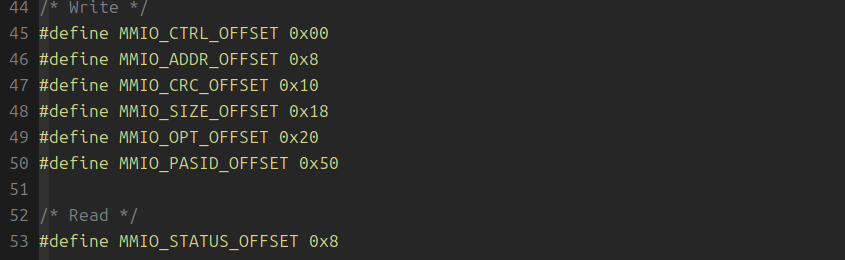
BAR0是MMIO空间,其配置寄存器如下,其中偏移0x8的MMIO寄存器在读/写时硬件处理语义不同。
测试用例分析:
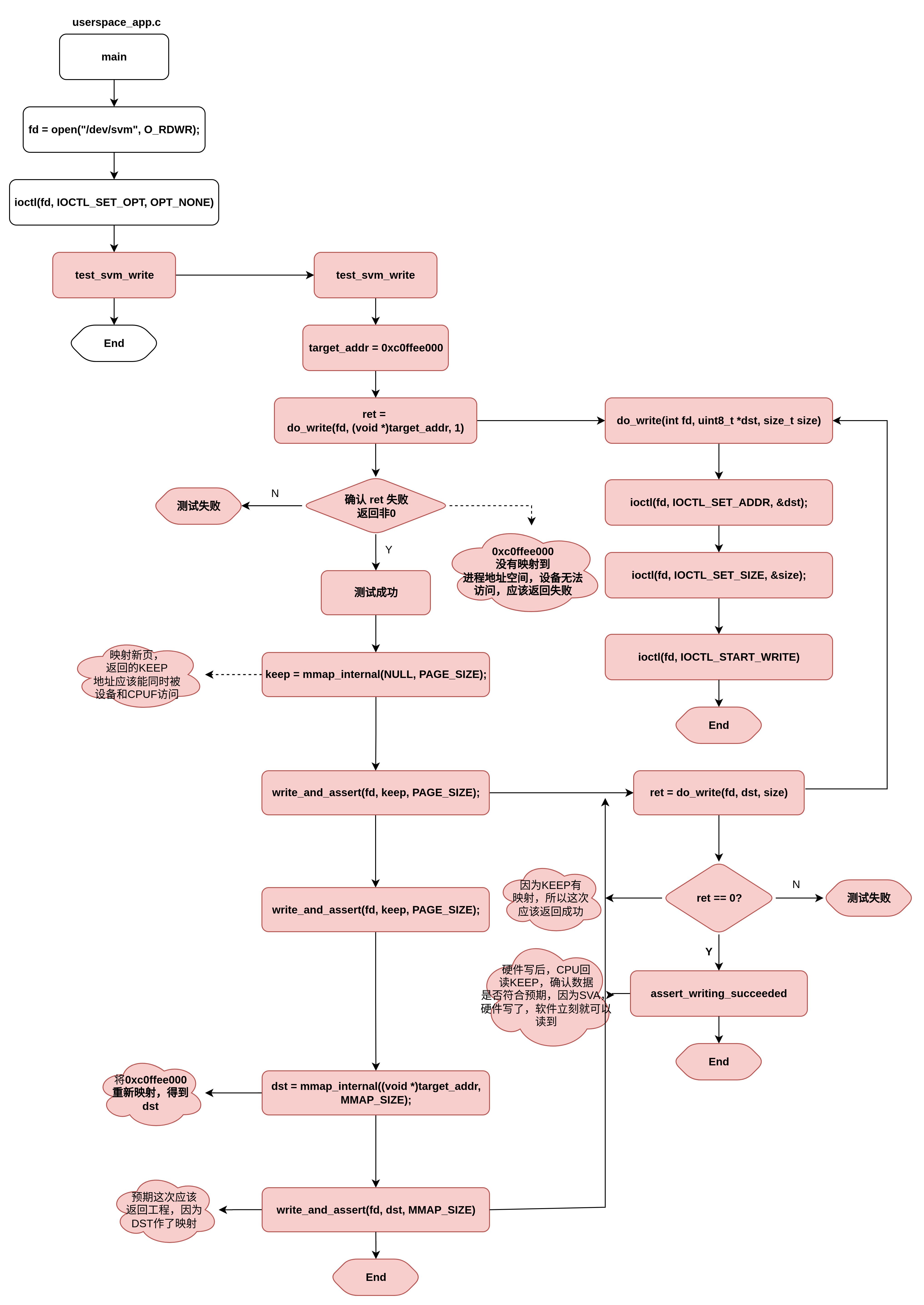
VM测试用例文件userspace_app.c,测试逻辑如下,首先给出一个没有映射到进程地址空间的地址0xc0ffee000给SVM PCIE设备访问,因为地址还没有映射到进程地址空间,所以测试预期应该返回错误。之后,随即映射一块匿名空间,给到设备区访问写入数据,然后给CPU读回来,由于此地址已经映射给进程地址空间,SVA机制下设备和CPU共享地址空间,所以可以立刻回读数据确认是否正确,预期能够读到正确的数据。最后,在将第一步测试的非法地址映射到进程地址,空间返回一个DST地址(由于没有设置FIXED MAP,返回的DST地址可能不等于0xc0ffee000)之后在用DST做同样的验证。由于这次地址经过映射,预期验证应该返回成功。



















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











