







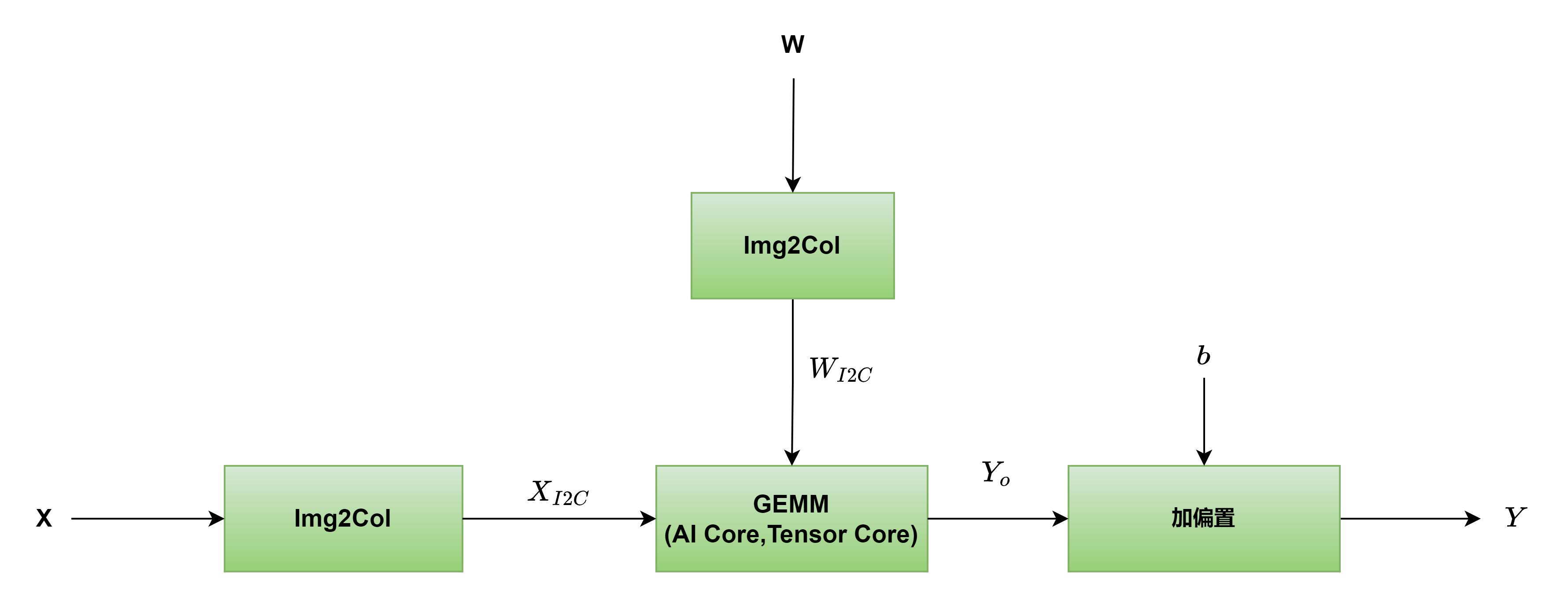
卷积转GEMM
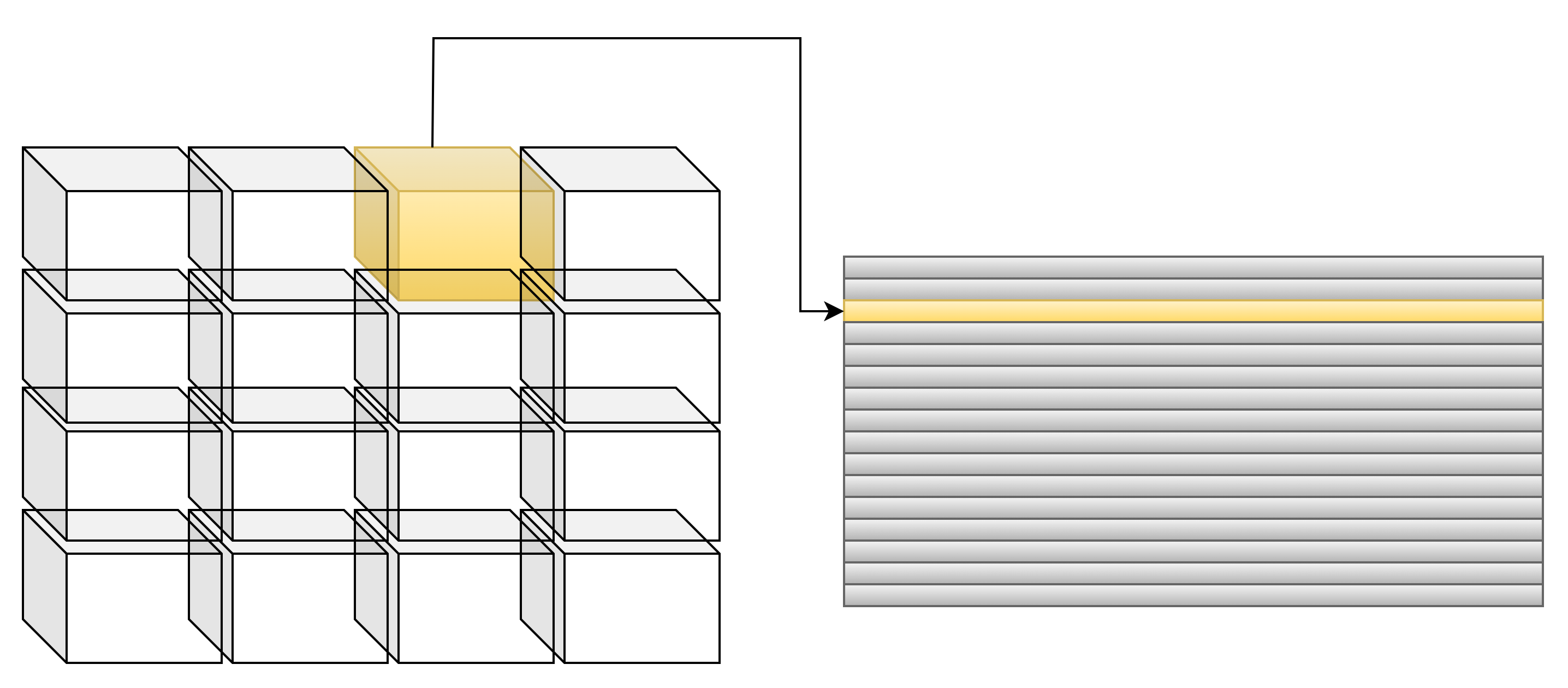

神经网络90%以上的计算单元都是由卷积和全链接构成的,所以说,一个具有tensor core矩阵乘法单元的加速卡,已经足以加速绝大部分CNN类型的网络了。
 本文探讨了在神经网络中,利用具备Tensorcore的加速卡如何显著提升卷积和全链接运算效率,表明这种硬件加速对于主流CNN模型的性能优化至关重要。
本文探讨了在神经网络中,利用具备Tensorcore的加速卡如何显著提升卷积和全链接运算效率,表明这种硬件加速对于主流CNN模型的性能优化至关重要。
卷积转GEMM
神经网络90%以上的计算单元都是由卷积和全链接构成的,所以说,一个具有tensor core矩阵乘法单元的加速卡,已经足以加速绝大部分CNN类型的网络了。
您可能感兴趣的与本文相关的镜像

Wan2.2-I2V-A14B
Wan2.2是由通义万相开源高效文本到视频生成模型,是有50亿参数的轻量级视频生成模型,专为快速内容创作优化。支持480P视频生成,具备优秀的时序连贯性和运动推理能力
 960
339
4538
1861
2156
960
339
4538
1861
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






























