







 本文介绍了在PyTorch环境下搭建YOLOv5推理和训练环境的步骤,包括环境配置、模型下载、模型转换、ONNX导出与优化、模型验证等。针对可能出现的错误,提供了解决方法,并展示了不同模型在batch=2时的处理。此外,文章还讨论了模型输出结构调整以适应NPU后处理需求。
本文介绍了在PyTorch环境下搭建YOLOv5推理和训练环境的步骤,包括环境配置、模型下载、模型转换、ONNX导出与优化、模型验证等。针对可能出现的错误,提供了解决方法,并展示了不同模型在batch=2时的处理。此外,文章还讨论了模型输出结构调整以适应NPU后处理需求。
关于之前pytorch框架下yolov3推理和训练环境搭建可以参考,本文所使用的环境和这篇记录一致。
pytorch yolov3 推理和训练环境搭建_papaofdoudou的博客-优快云博客_yolov3环境搭建
下载代码框架环境:
git clone https://github.com/ultralytics/yolov5 安装依赖:
安装依赖:
pip install -r requirements.txt
下载YOLOV5模型文件:
下载链接 :Releases · ultralytics/yolov5 · GitHub以下模型均可用:

拷贝模型文件到yolov5顶层目录,之后执行命令:
python detect.py --source data/images --weights yolov5s.pt --conf 0.25输出如下,一开始会去下载字库,猜测是用来画标签用:

根据LOG,推理结果在runs/detect/exp目录:



yolov5s6.pt模型推理
python detect.py --source data/images --weights yolov5s6.pt --conf 0.25

排错:
如果遇到下面的错误,说明PROTOBUF版本不对,需要重新安装。

安装命令:
pip install protobuf==3.20.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
之后就可以了。
python代码推理:
由于我们已经将YOLOV5的pytorch训练框架下载过来,接下来我们就可以编写代码来完成推理了,代码如下所示:
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l, yolov5x, custom
# Images
img = './data/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
results.show()执行命令python inf.py 推理完成后:

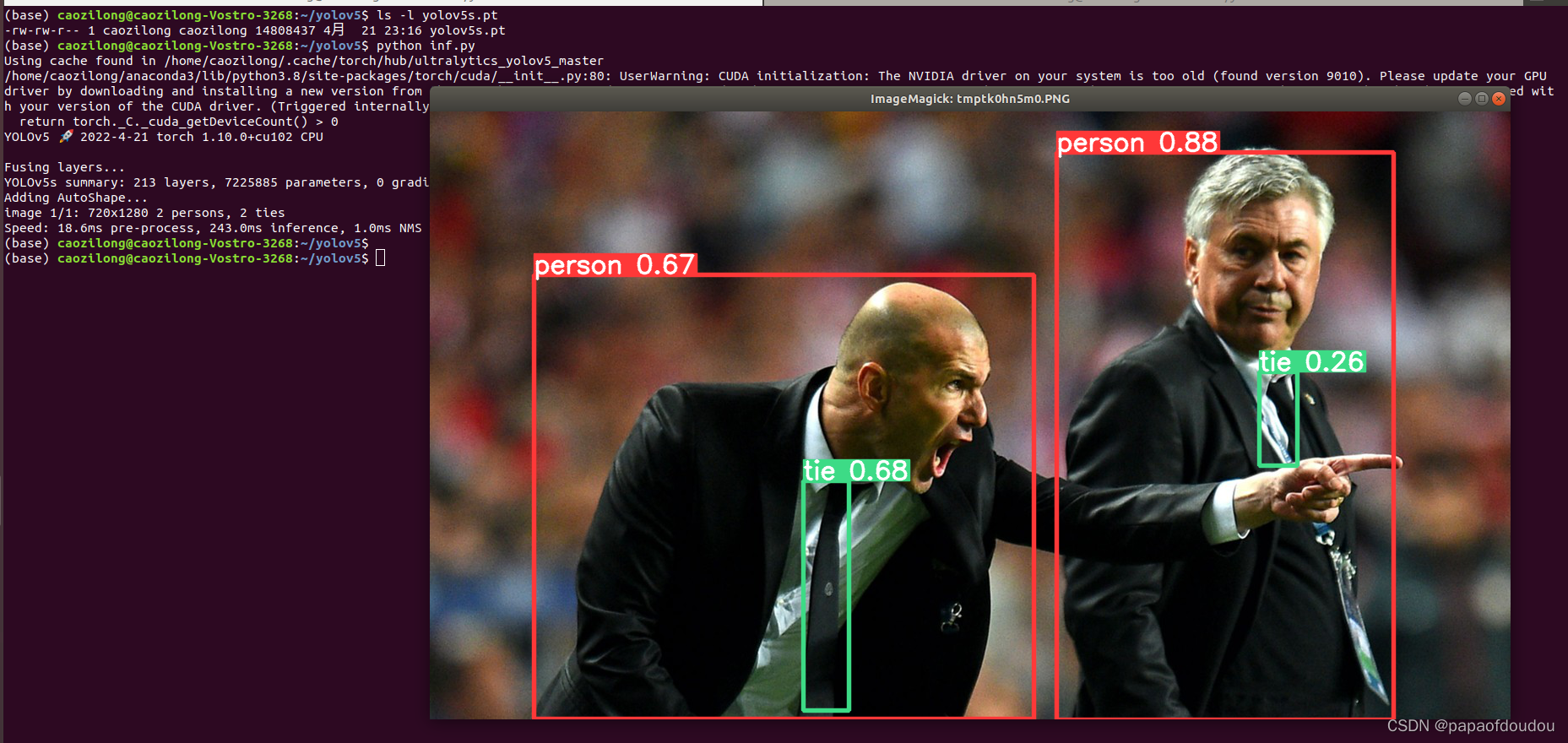
YOLOV5X.pt
python detect.py --source data/images --weights yolov5x.pt --conf 0.25
yolov5x.pt



导出ONNX模型数据
导出ONNX模型,还需要依赖两个python安装包:
pip install onnx==1.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnxruntime==1.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple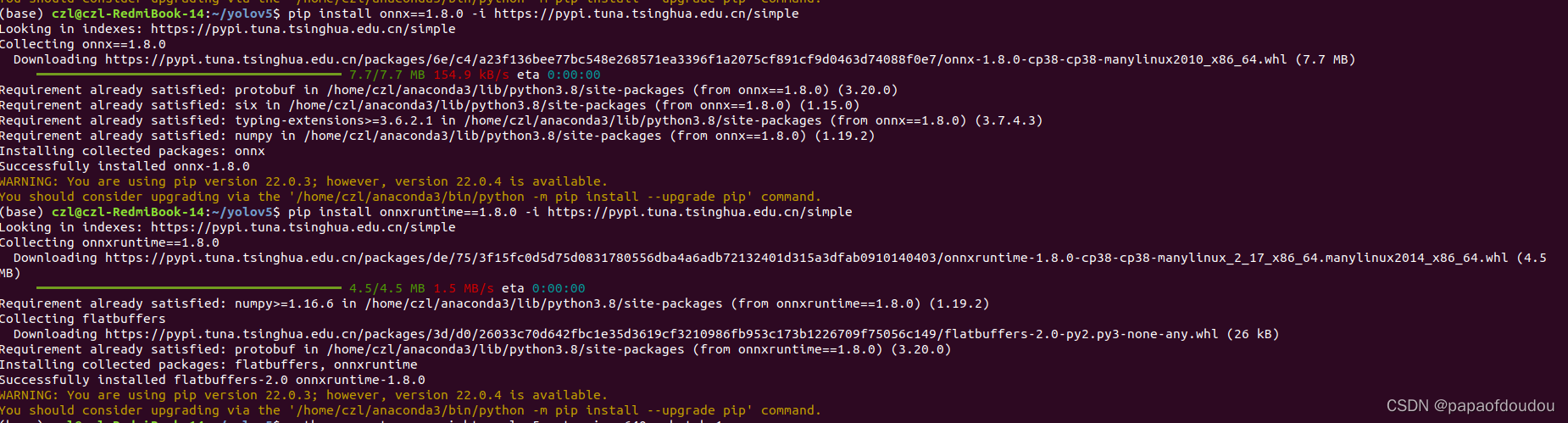
导出模型:
由于原始模型为动态模型,输入输出是没固定的,所以这里需要指定输入图的大小,我们指定为640像素。
python export.py --weights yolov5s.pt --img 640 --batch 1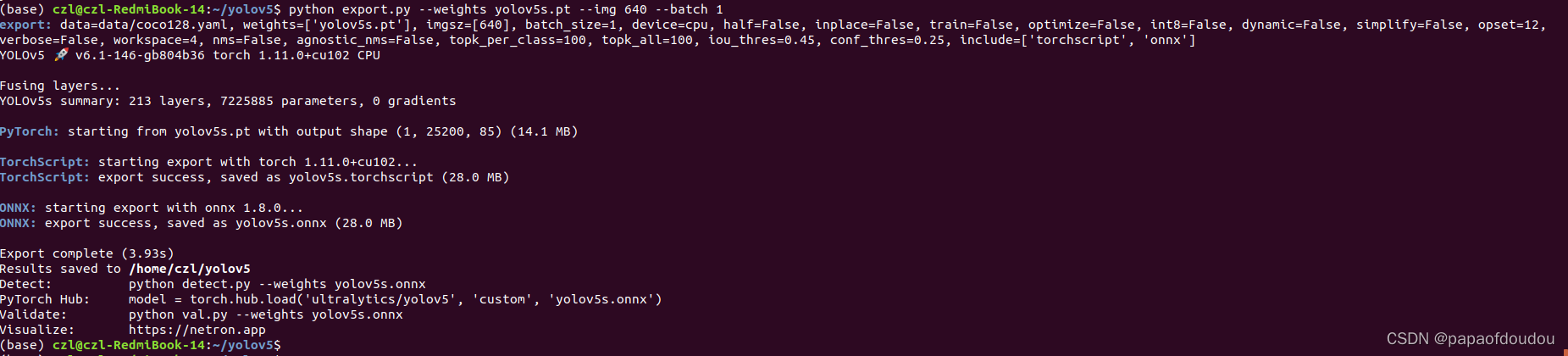

可以看到,生成了yolov5s.onnx模型文件,我们看其结构:
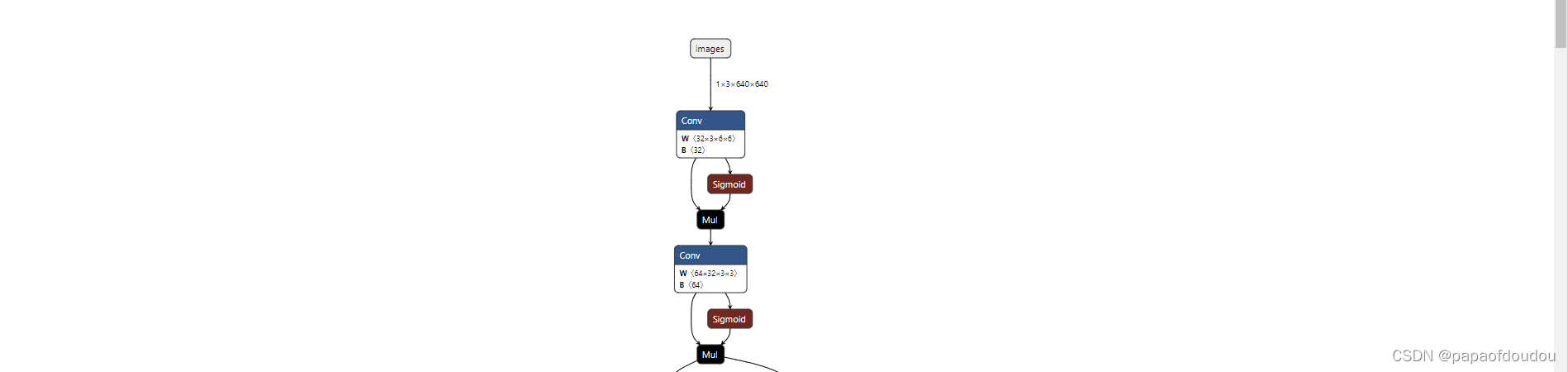
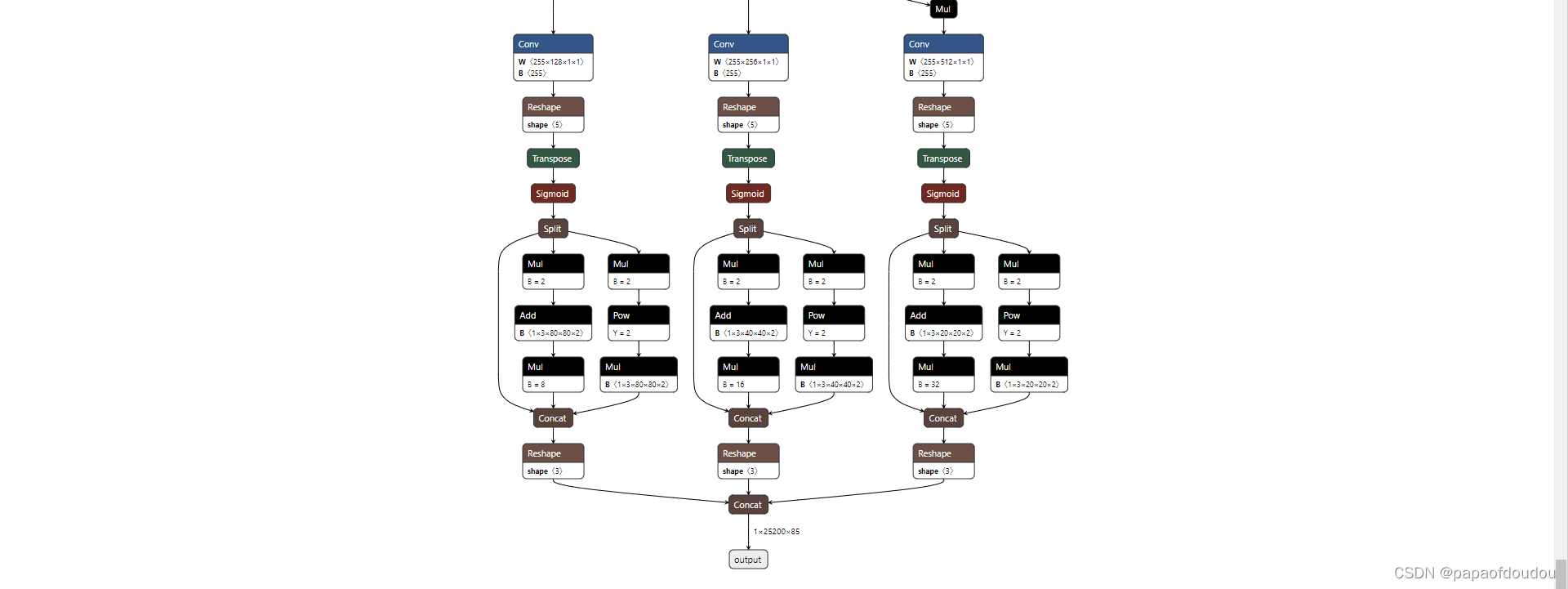
修改导图尺寸:
python export.py --weights yolov5s.pt --img 320 --batch 1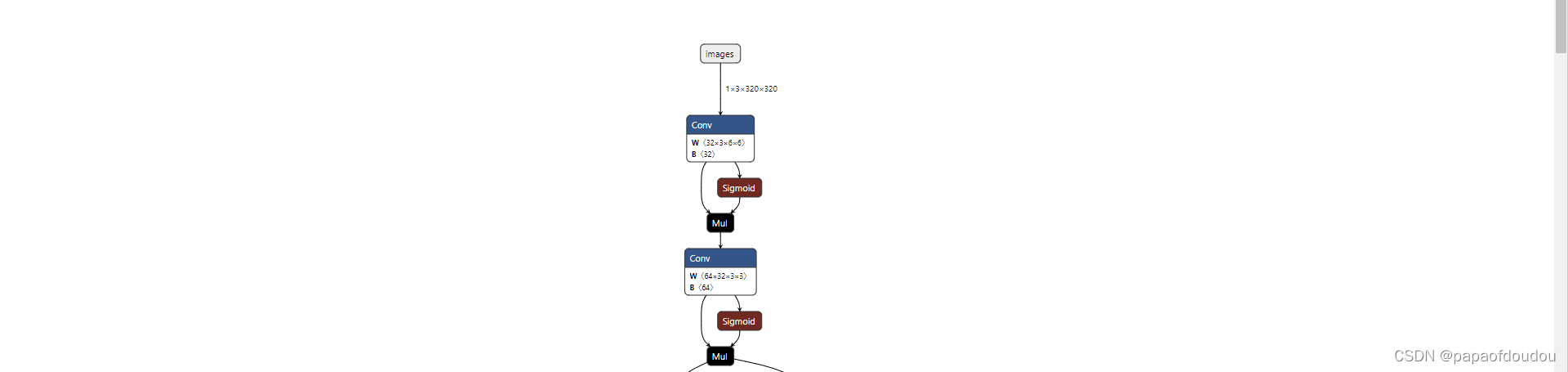
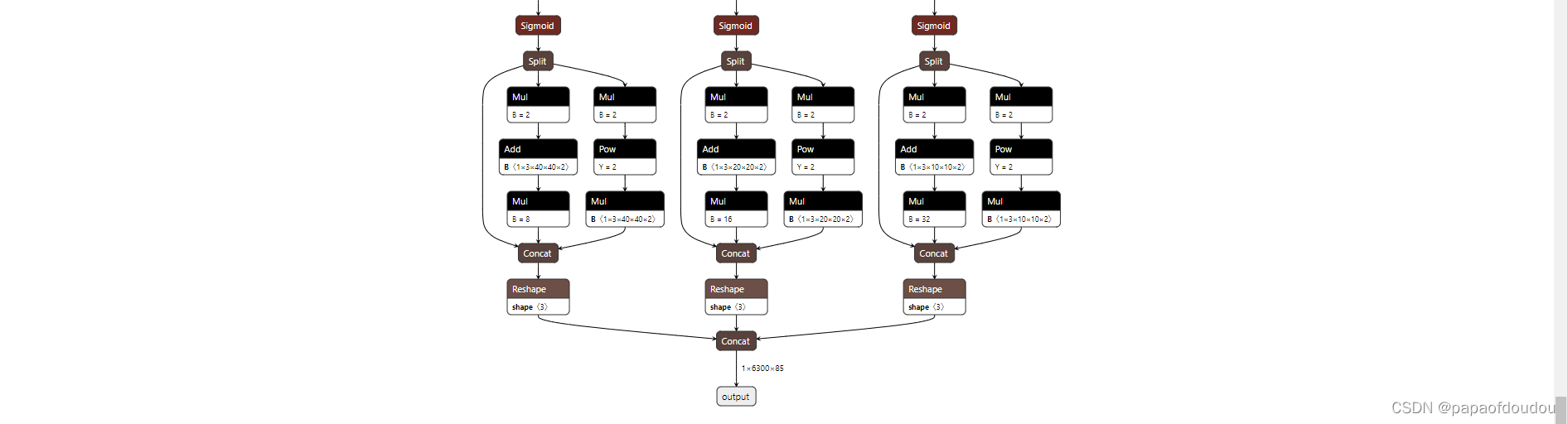
yolov5s6模型转换
python export.py --weights yolov5s6.pt --img 640 --batch 1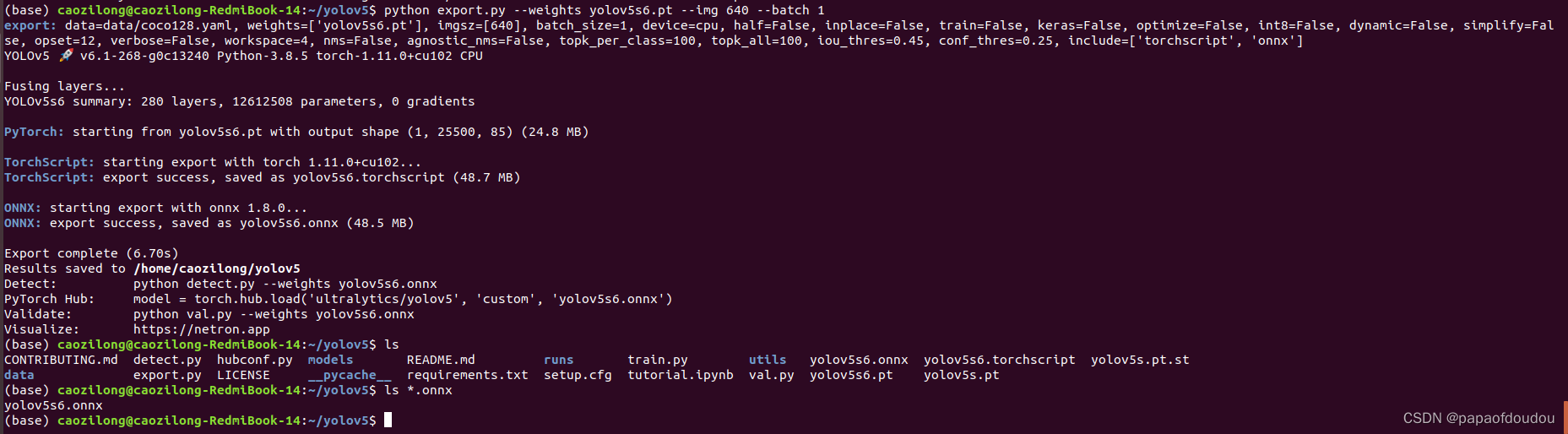
yolov5x6大模型转换
python export.py --weights yolov5x6.pt --img 320 --batch 1
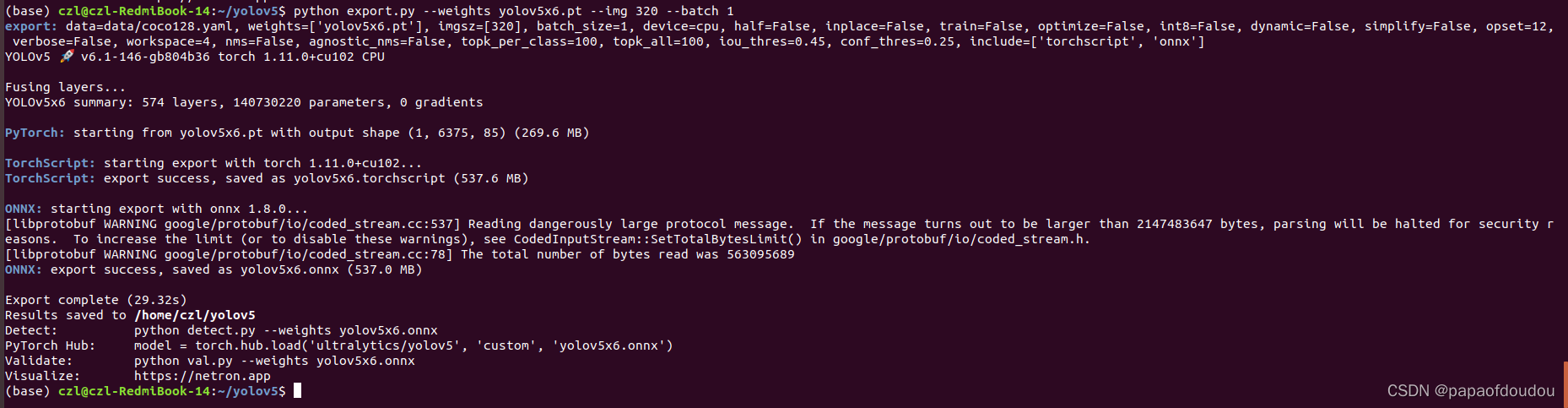

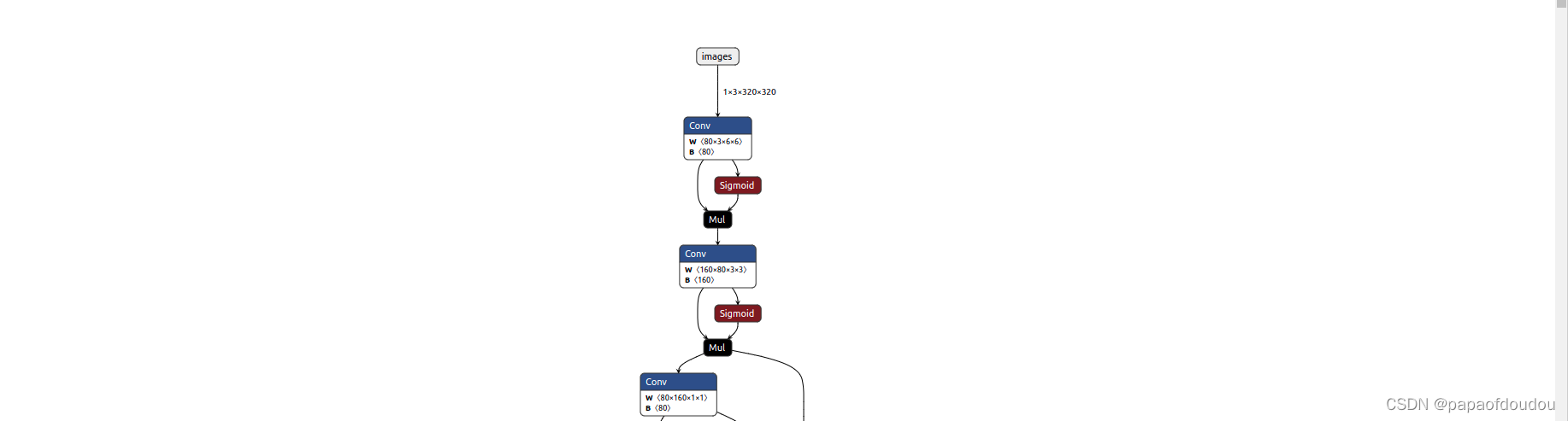
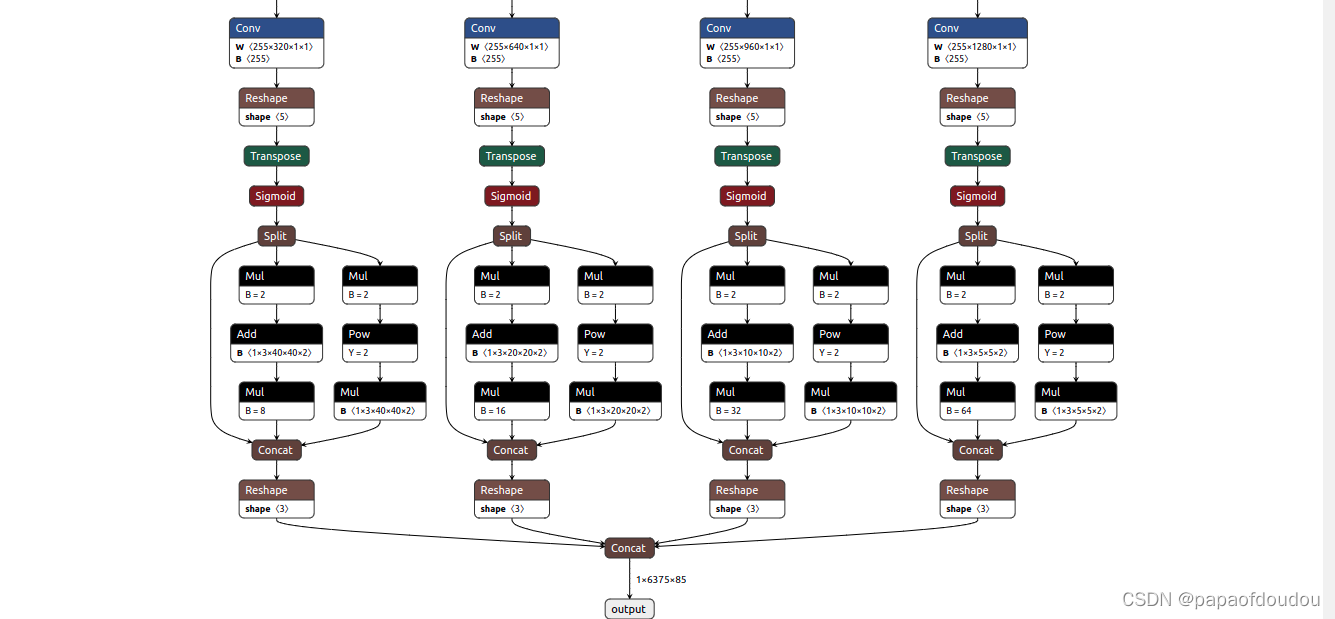
batch = 2的时候
python export.py --weights yolov5x6.pt --img 320 --batch 2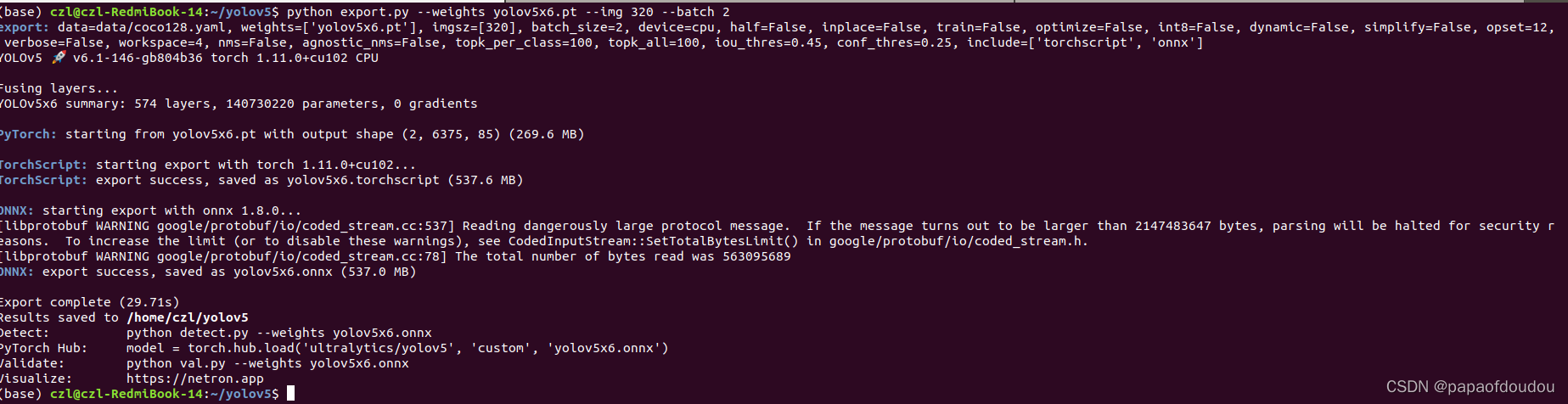
此时,网络一次吃两张图,同时也输出两张图的结果:
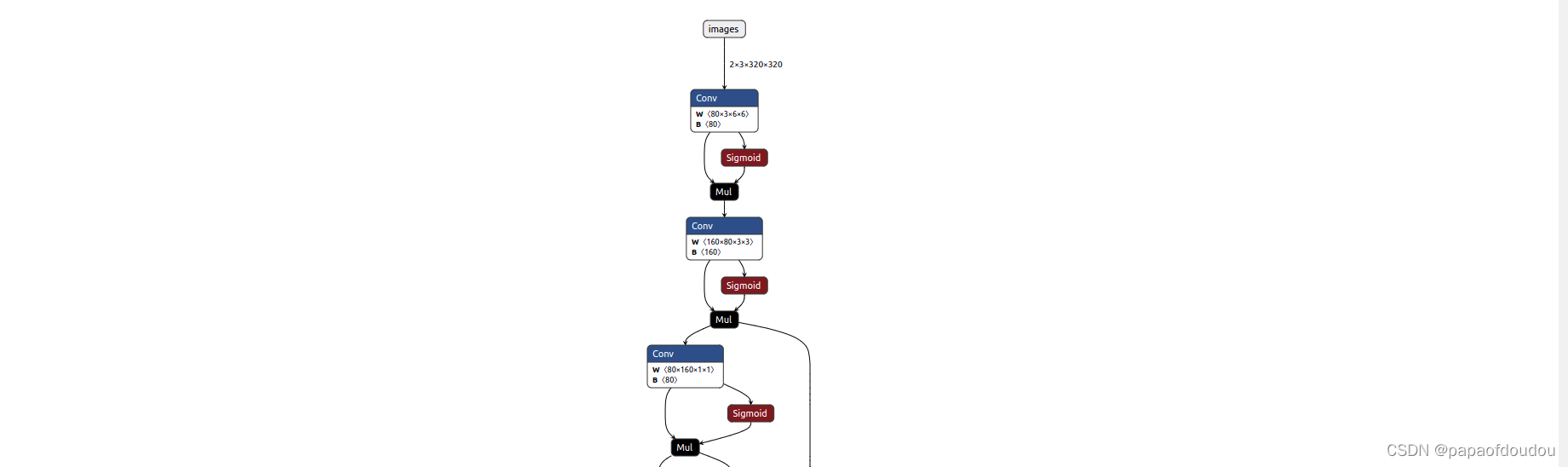
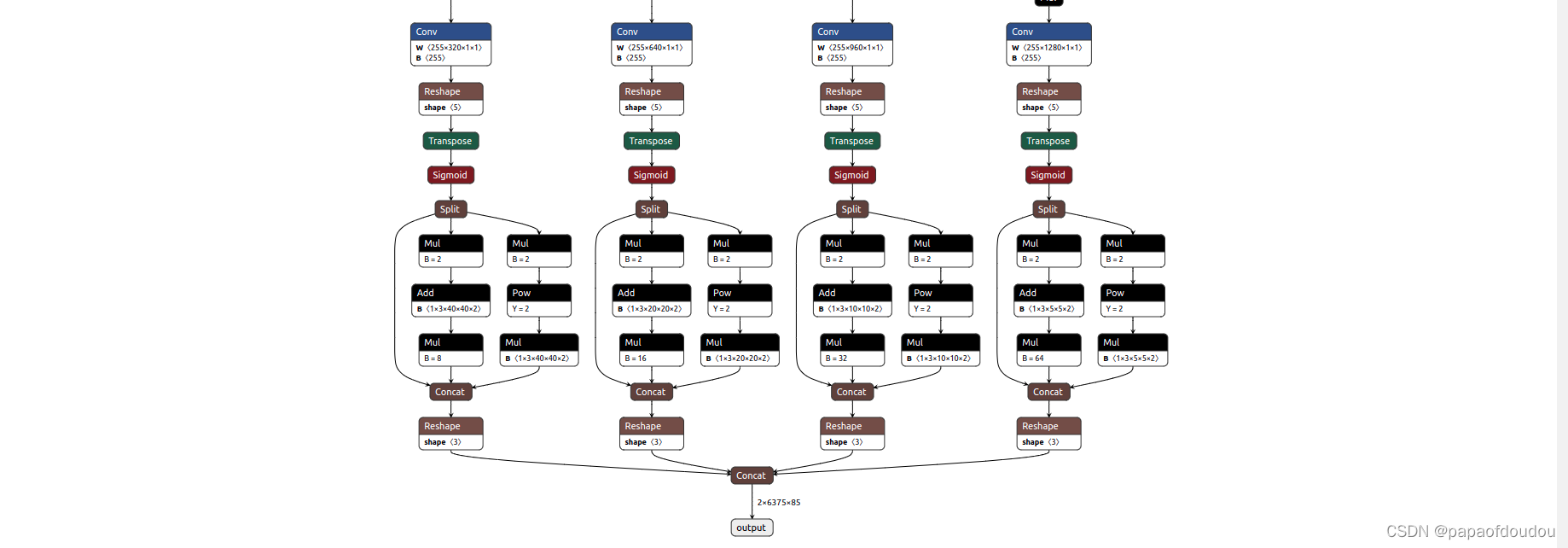
训练:
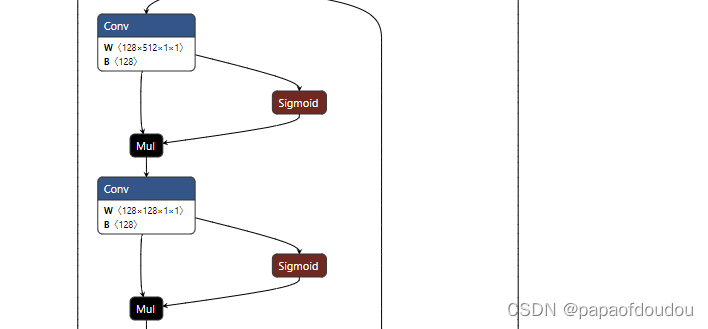
python train.py --data coco.yaml --cfg yolov5n.yaml --weights '' --batch-size 128YOLOV5s中很多类似的结构,开始我还以为是卷积后求sigmoid之后和原卷积输出矩阵做矩阵乘法,后面看了libonnx的代码,才发现不是,矩阵对应元素做乘法。

ONNX推理
用生成的ONNX模型做推理,程序如下:

代码:
import cv2
import numpy as np
import onnxruntime as rt
height, width = 640, 640
img0 = cv2.imread('./data/images/bus.jpg')
img = cv2.resize(img0, (height, width)) # 尺寸变换
img = img / 255.
img = img[:, :, ::-1].transpose((2, 0, 1)) # HWC转CHW
data = np.expand_dims(img, axis=0) # 扩展维度至[1,3,640,640]
sess = rt.InferenceSession('yolov5s.onnx')
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run([label_name], {input_name: data.astype(np.float32)})[0]
pred = np.squeeze(pred_onx)
print(pred)
print(pred.shape)
另外,除了自己导出模型,还可以直接从如下地址下载ONNX格式的模型:
https://github.com/ultralytics/yolov5/releases
onnxsim模型优化
原始的ONNX模型参数过多,不利于查看,ONNXSIM工具可以简化模型,让NETRON显示更加自然。
如下图所示,原始网络的输入输出TENSOR的形状并没有体现出来:
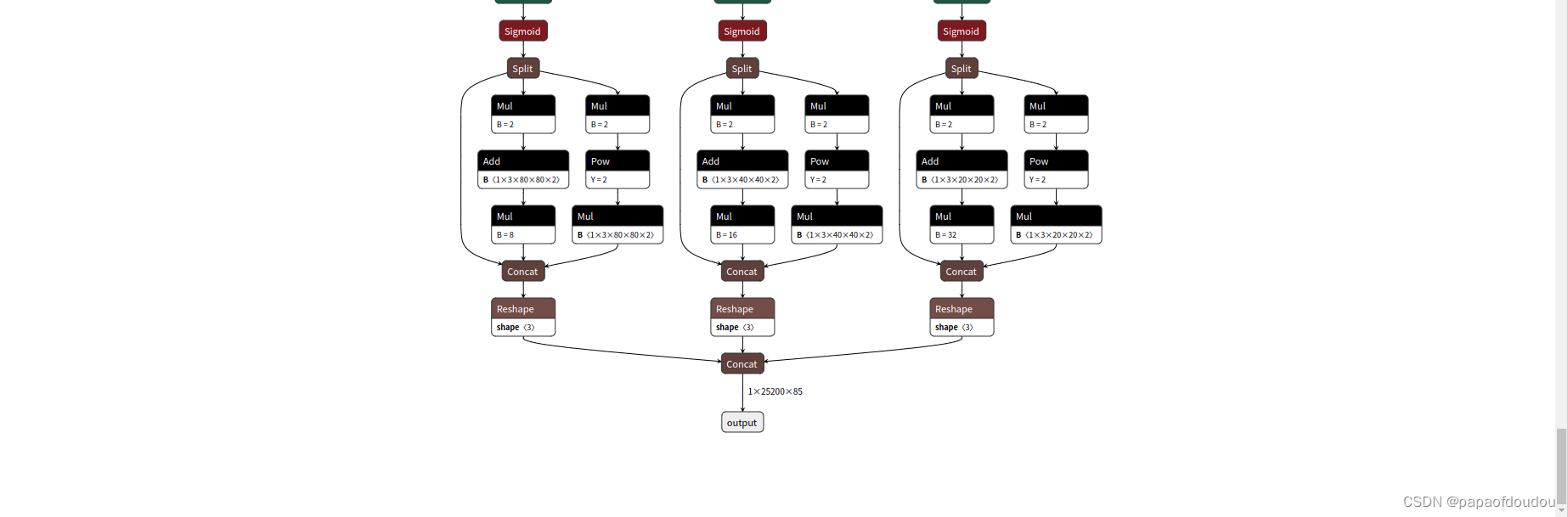
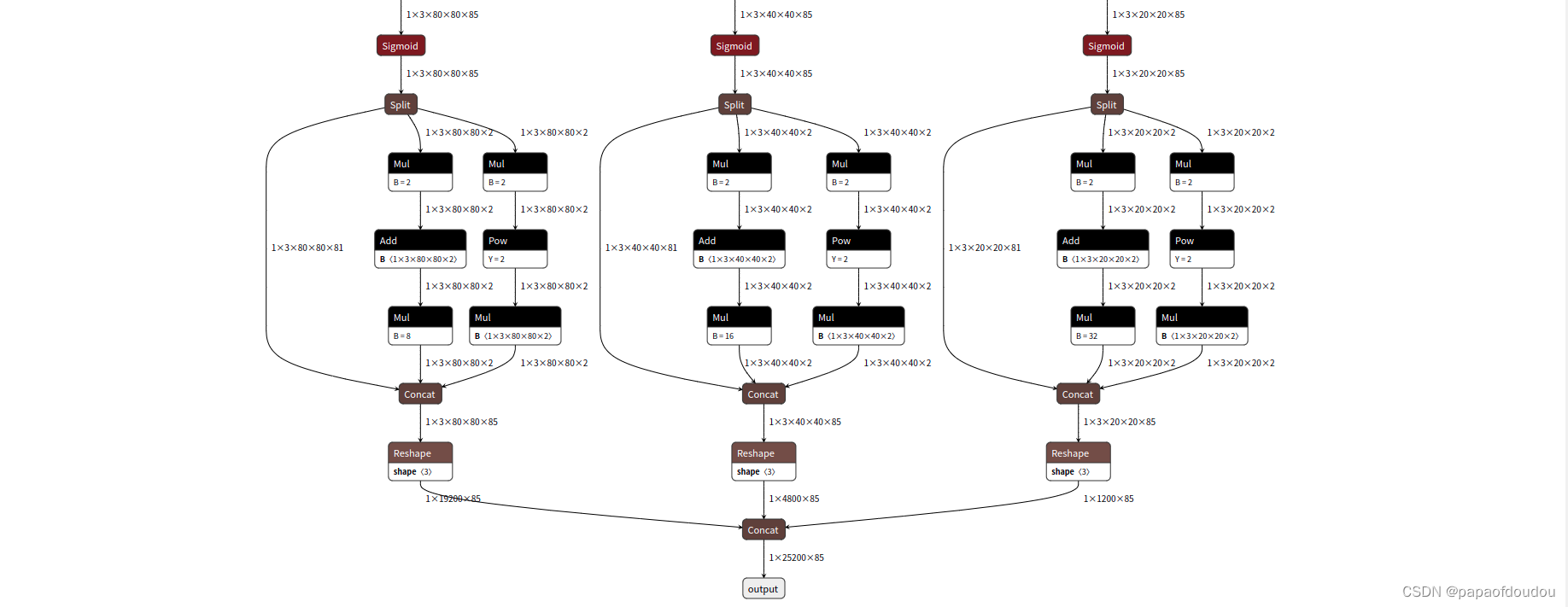
而通过ONNXSIM处理后,网络的对应层便成为了如下的样子,每层的输入输出形状都体现出来了。
安装ONNSIM:
pip install onnx-simplifier
执行优化命令
onnxsim ./yolov5s.onnx ./yolov5s-sim.onnx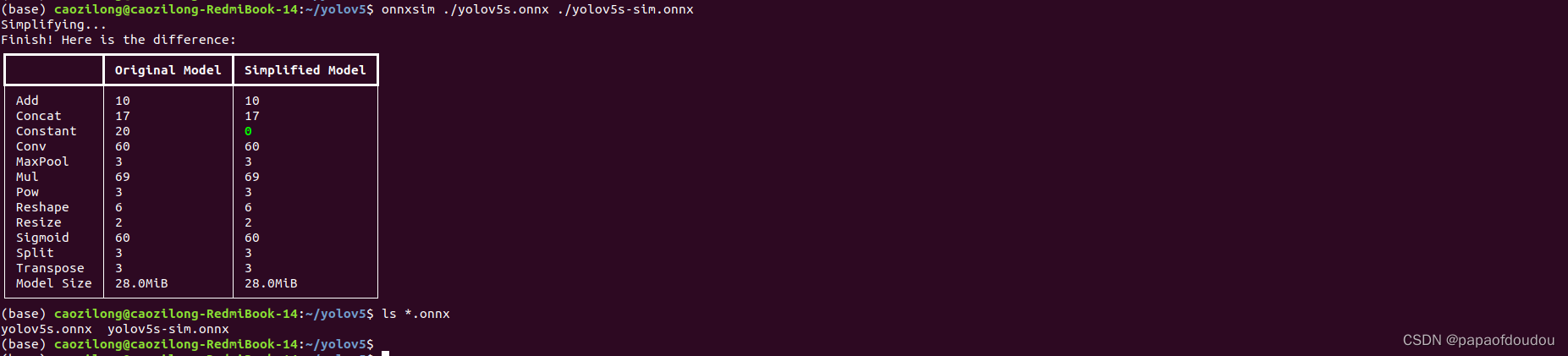
生成的yolov5s-sim.onnx通过netron查看,即可得到上面图示中的优化结果。
调整输出
YOLOV5S默认的输出如下,结构上三路分支在最终的输出点合并为一路输出,导龙入海,引火归原,但是这些层并不适合NPU做后处理,原因是中间有很多超越函数的操作。一般做法是从输出头那边引出输出节点,而不是将三路输出汇总为一路输出。
做法有三种,需要修改代码才能实现,核心是修改下面的行return语句,我们分别验证一下:

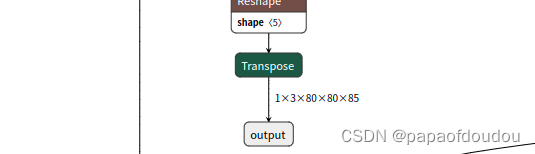
修改1:
修改后,网络变成了1输入三输出的结构:

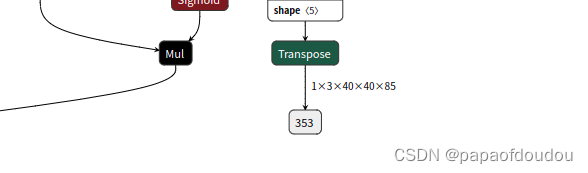
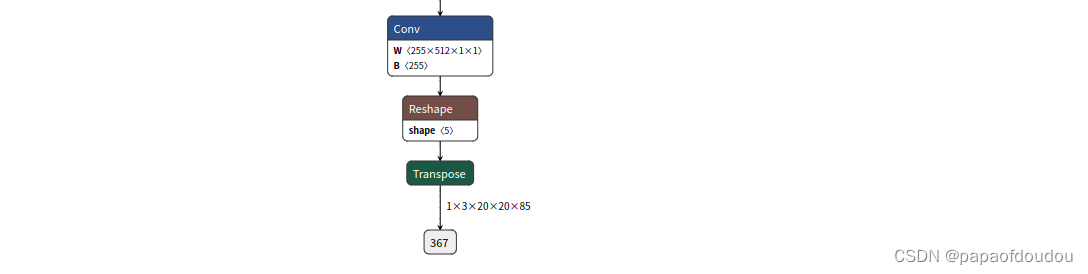 修改2:
修改2:
这是默认情况下的输出:


修改3:
这种情况下,有4个输出,将前面两种情况的输出全部在一个网络里面输出,便是这种情况。

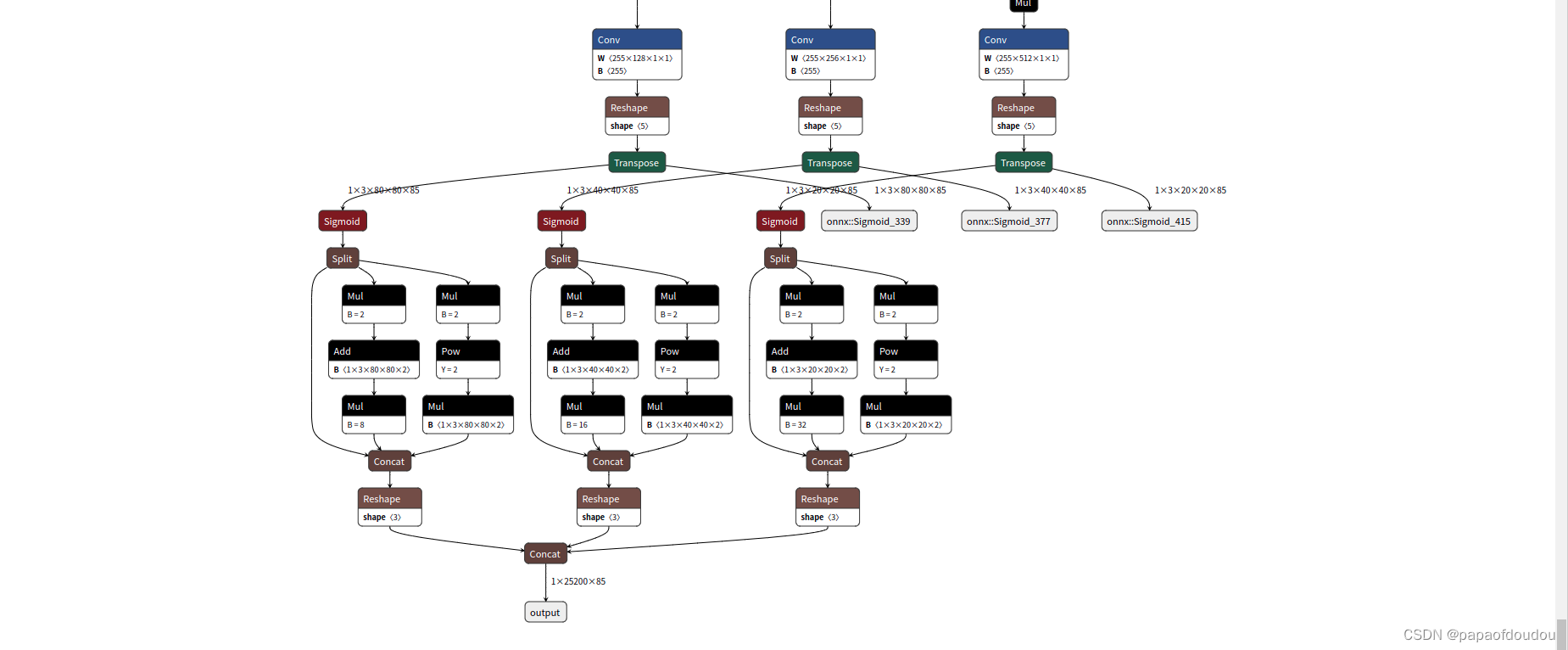
ONNXSIM处理后:
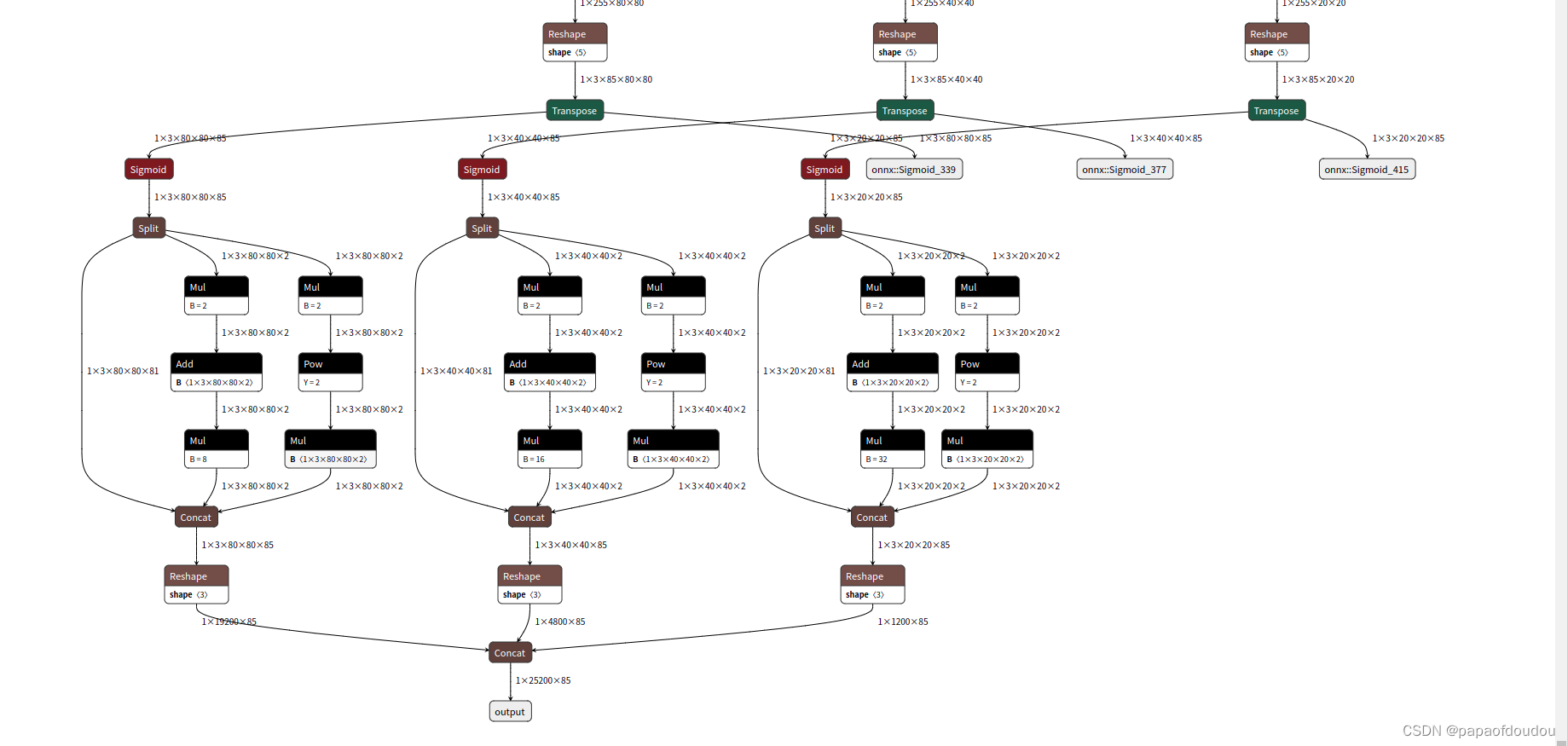
validate 验证模型
python val.py --weights yolov5s.onnx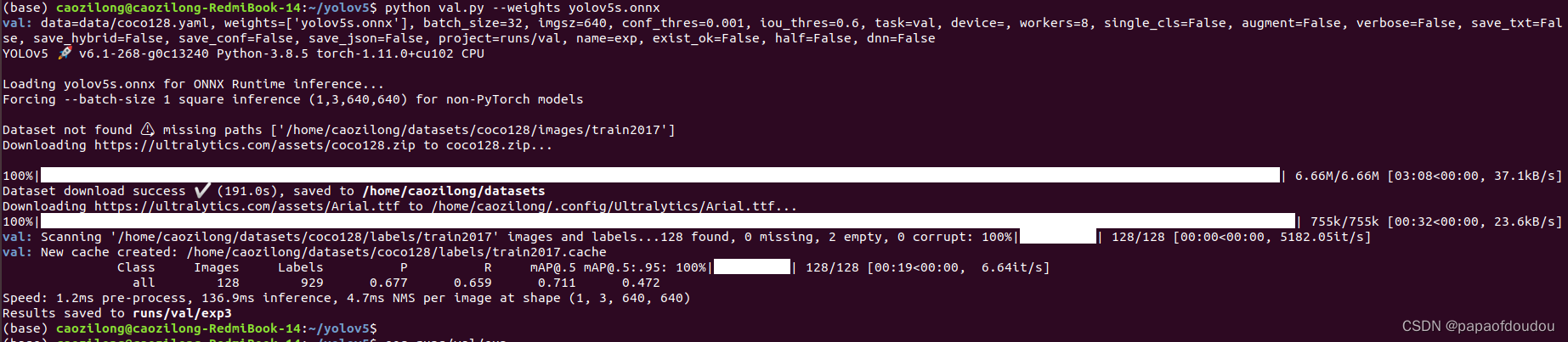
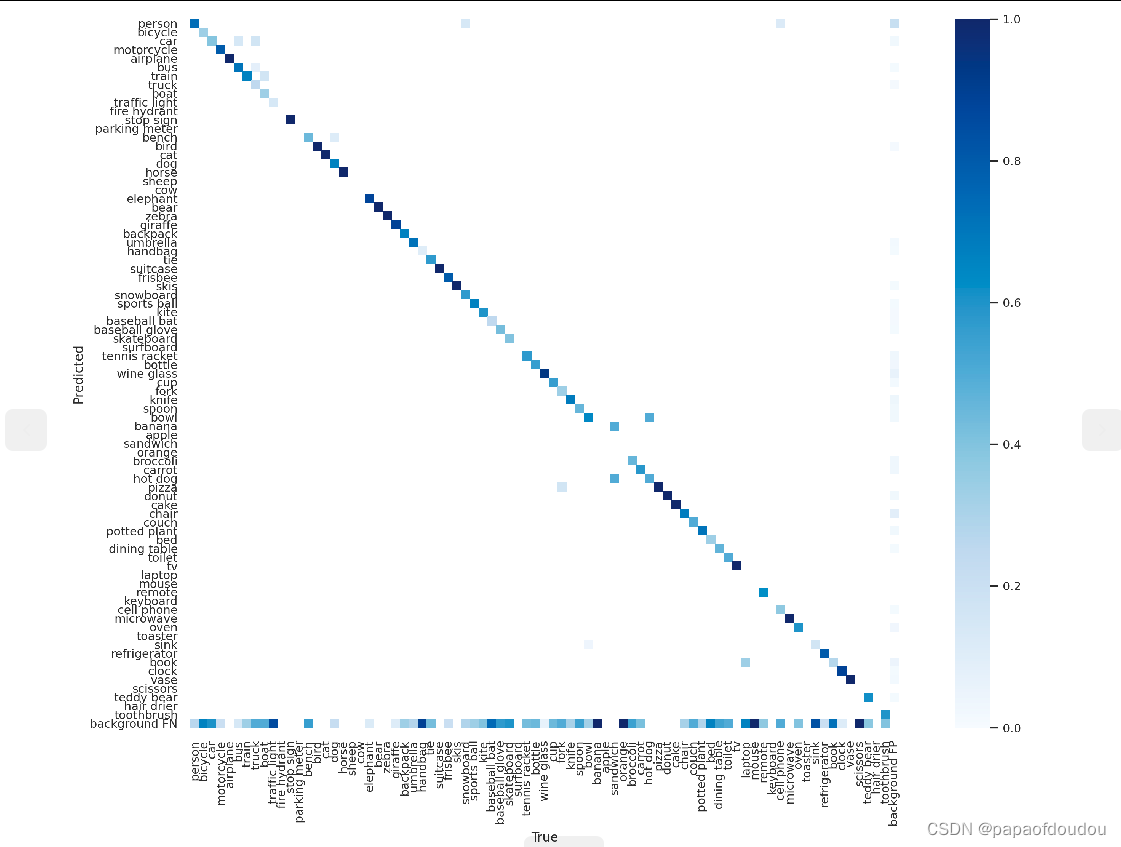
confusion matrix(混淆矩阵):
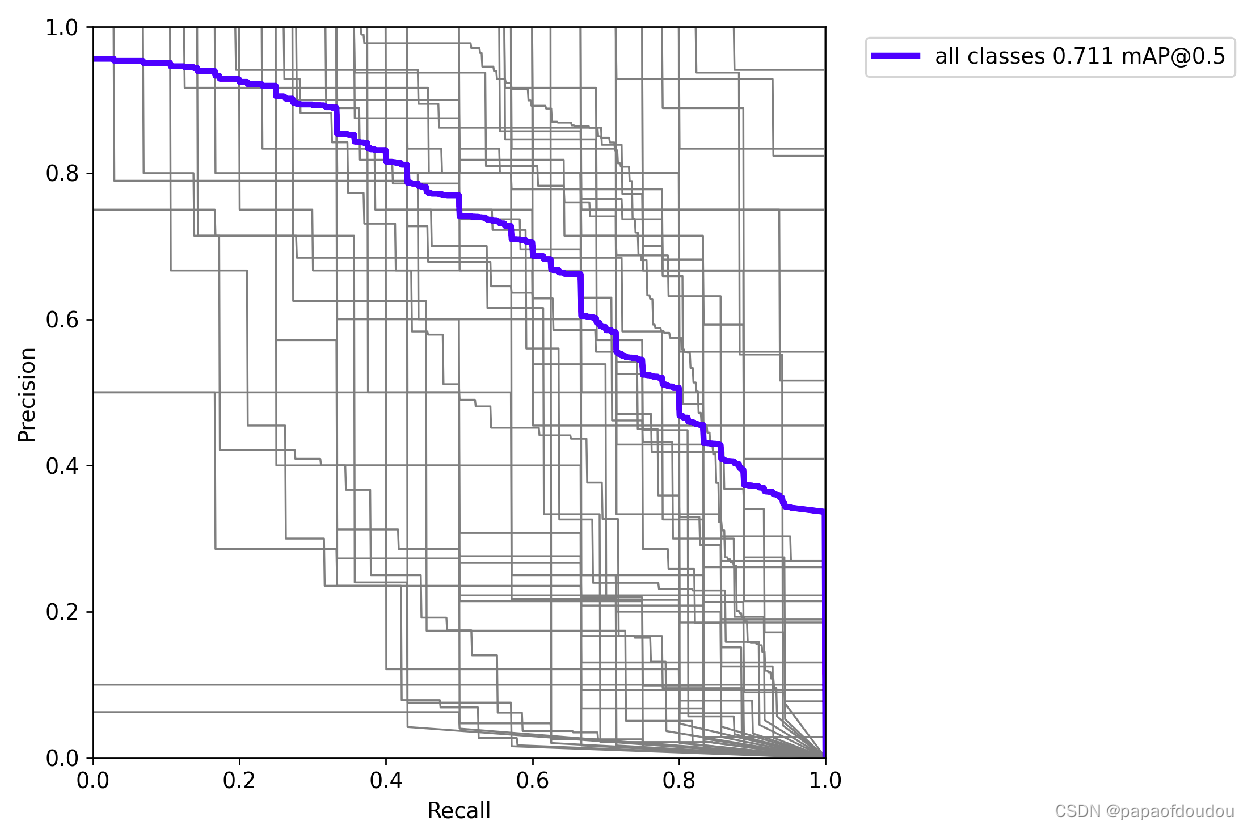
PR曲线:
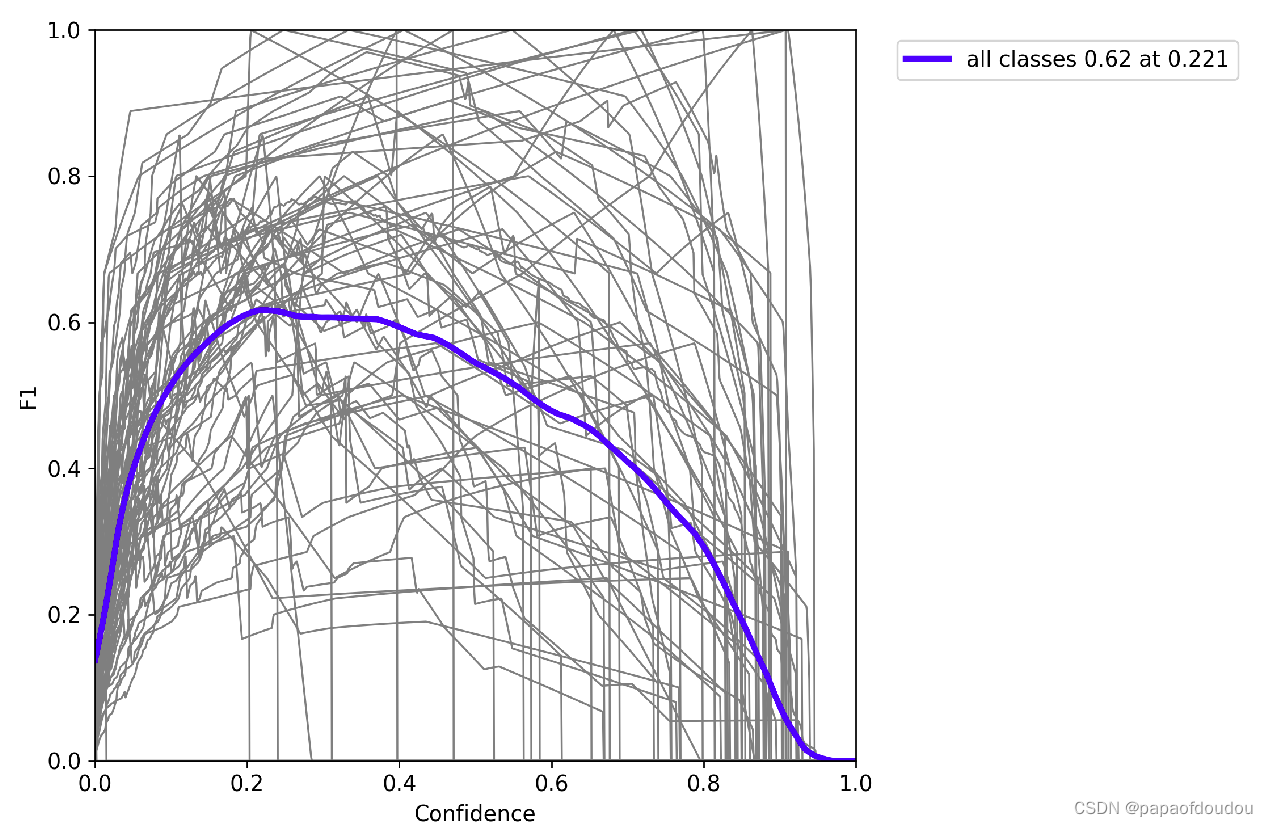
F1曲线
P_cureve:
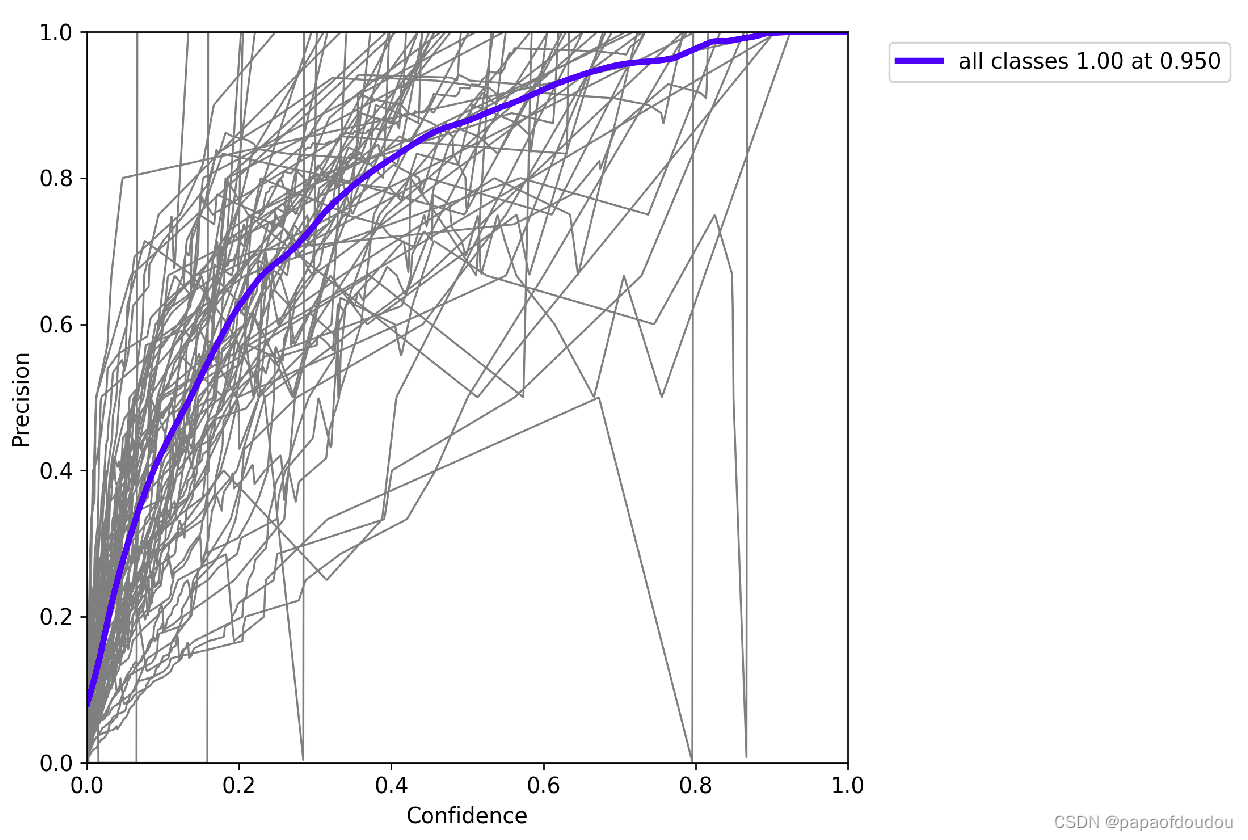
R_curve:
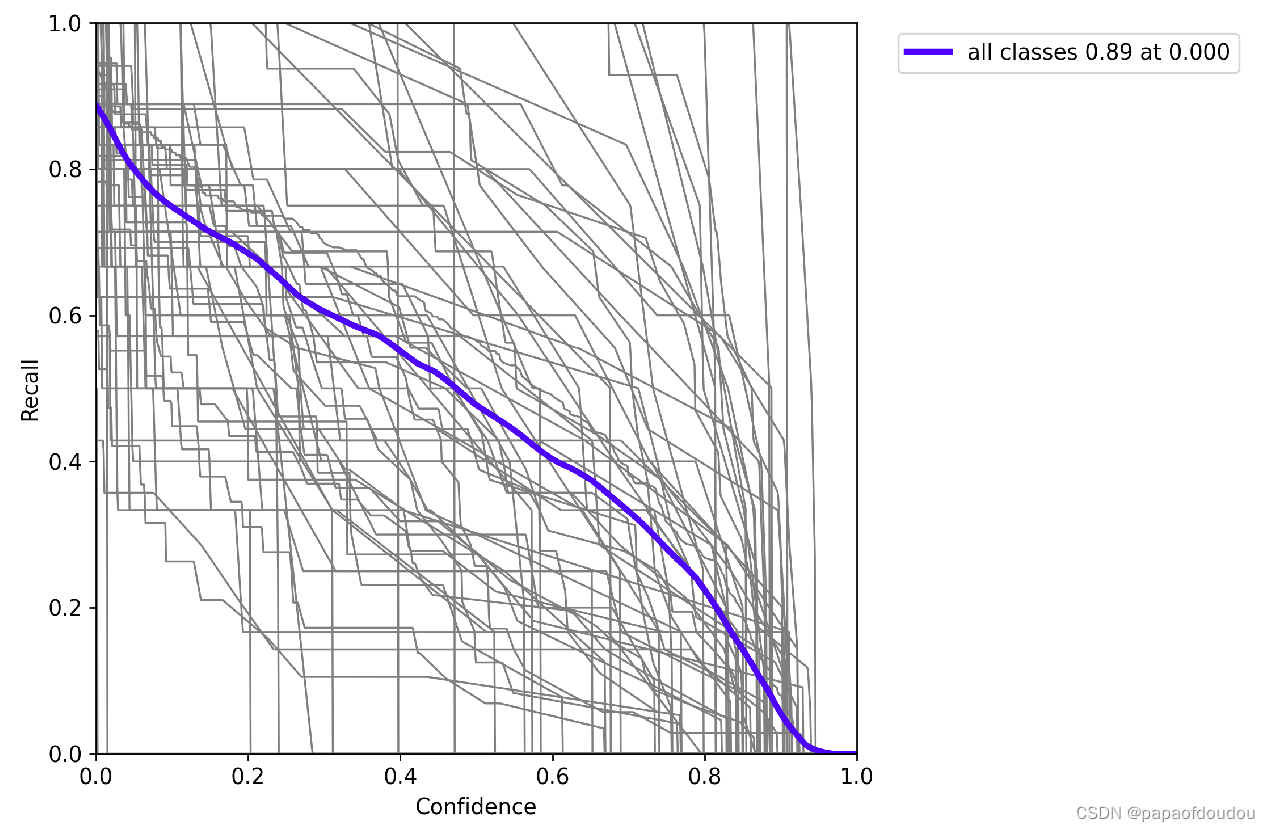
picture:

参考资料:
https://github.com/ultralytics/yolov5/issues/251
https://github.com/ppogg/YOLOv5-Lite https://github.com/ppogg/YOLOv5-Lite
https://github.com/ppogg/YOLOv5-Lite



















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











