







在这一篇文章中,我们将探讨如何将大型文档,如PDF或YouTube视频,融入到我们的大语言模型(LLM)上下文中。我们将学习如何使用文档加载器和分块技术来处理因上下文空间有限而带来的问题。通过逐步对文档块进行重新情境化、强制转换和整合,我们将构建一个能够与大型文档进行有效对话和推理的系统。
1 与文档对话
传统的聊天模型需要大量时间在海量的公共数据上重新训练。如果能让LLM直接从输入的PDF甚至视频中进行推理,通过充分的提示工程和模型已有的指令遵循能力,你可以强制模型仅基于你提供的材料来做出响应。
更进一步,你的LLM甚至可以与你的文档进行互动,在必要时自动修改内容。这为自动化内容优化和合成操作开辟了新的道路。
假设你有一些文本文档(PDF、博客等),并希望提出与这些文档内容相关的问题。你可以尝试的一种方法是,将文档的表示形式全部喂给一个聊天模型!从文档的角度来看,这被称为文档填充(document stuffing)。
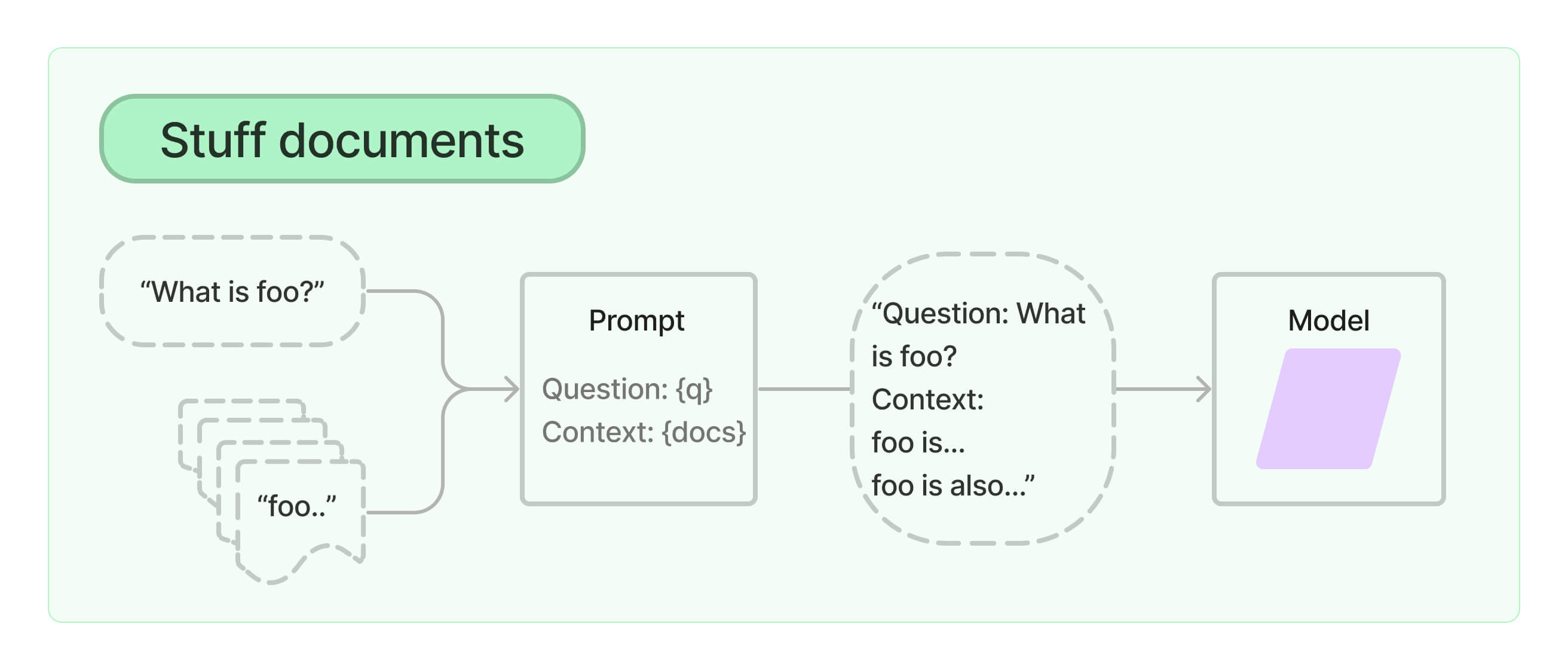 如果你的模型足够强大,文档篇幅也不长,这种方法很可能奏效。但我们不能奢望它在处理整个文档时都能有同样出色的表现。这是因为,受限于训练方式,很多现代LLM在处理长上下文时依然存在显著的瓶颈。虽然如今大型模型在性能上的衰减不再那么剧烈,但即便你使用的是最基础的原始模型,在面对大量信息时,其指令遵循能力也很可能会迅速下降。
如果你的模型足够强大,文档篇幅也不长,这种方法很可能奏效。但我们不能奢望它在处理整个文档时都能有同样出色的表现。这是因为,受限于训练方式,很多现代LLM在处理长上下文时依然存在显著的瓶颈。虽然如今大型模型在性能上的衰减不再那么剧烈,但即便你使用的是最基础的原始模型,在面对大量信息时,其指令遵循能力也很可能会迅速下降。
在文档推理中你需要解决的关键问题是:
- 我们如何将文档分割成可以进行推理的小块?
- 随着文档大小和数量的增加,我们如何有效地找到和考虑这些小块?
所以这篇文章将探讨几种解决这些问题的方法,同时扩展我们之前的运行链技能,用于更渐进的推理公式,并将介绍一些新技术,以妥善解决大规模检索问题。
文档加载框架领域有许多强大的选择,其中两个主要角色将在整个课程中出现:
- LangChain:提供了一个简单的框架,通过通用的分块策略和与嵌入框架/服务的强大结合,将LLM连接到你自己的数据源。这个框架最初是围绕其对LLM功能的强大通用支持而发展的,这表明了它在链抽象和代理协调方面的现有优势。
- LlamaIndex:是一个用于LLM应用程序的数据框架,用于摄取、构建和访问私有或领域特定的数据。它后来扩展到包括类似于LangChain的通用LLM功能,但截至目前,它在处理LLM组件的文档方面仍然最强,因为其最初的抽象是围绕这个问题展开的。
建议更多地了解LlamaIndex和LangChain各自的优势,并选择最适合你的那一个。由于LlamaIndex可以与LangChain一起使用,这两个框架的独特功能可以毫无问题地结合利用。为简单起见,我们将继续使用LangChain。
2 加载文档
LangChain提供了多种文档加载器,以方便从不同来源和位置(本地存储、私有s3存储桶、公共网站、消息API等)摄取各种文档格式(HTML、PDF、代码)。这些加载器查询你的数据源并返回一个Document对象,该对象包含内容和元数据,通常是纯文本或其他人类可读的格式。已经有大量的文档加载器被构建并可供使用,LangChain官方提供的选项列在这里。
在我们的例子中,使用以下LangChain加载器之一加载我们选择的研究论文:
UnstructuredFileLoader:通用的文件加载器,适用于任意文件;对你的文档结构不做过多假设,通常足够使用。ArxivLoader:一个更专业的文件加载器,可以直接与Arxiv接口通信。它会对你的数据做出更多假设,以产生更好的解析和自动填充元数据(当你处理多个文档/格式时非常有用)。
在下面的代码示例中,将默认使用ArxivLoader来加载MRKL或ReAct的出版论文,因为你在后续的聊天模型研究中很可能会遇到它们。
%%time
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import ArxivLoader
## 加载文件
## Unstructured File Loader: 适用于任意文件的“可能足够好”的加载器
# documents = UnstructuredFileLoader("llama2_paper.pdf").load()
## 更专业的加载器,不适用于所有情况,但API简单且通常效果更好
documents = ArxivLoader(query="2404.16130").load() ## GraphRAG
# documents = ArxivLoader(query="2404.03622").load() ## Visualization-of-Thought
# documents = ArxivLoader(query="2404.19756").load() ## KAN: Kolmogorov-Arnold Networks
# documents = ArxivLoader(query="2404.07143").load() ## Infini-Attention
# documents = ArxivLoader(query="2210.03629").load() ## ReAct
从我们的导入中我们可以看到,这个连接器为我们提供了两个不同的组件的访问权限:
page_content是文档的实际主体,以某种人类可解释的格式呈现。metadata是关于文档的相关信息,由连接器通过其数据源提供。
下面,我们可以查看文档主体的长度以了解其内部内容:
## 打印部分内容示例
print("Number of Documents Retrieved:", len(documents))
print(f"Sample of Document 1 Content (Total Length: {len(documents[0].page_content)}):")
print(documents[0].page_content[:1000])
输出如下:
Number of Documents Retrieved: 1
Sample of Document 1 Content (Total Length: 89593):
From Local to Global: A GraphRAG Approach to
Query-Focused Summarization
Darren Edge1†
Ha Trinh1†
Newman Cheng2
Joshua Bradley2
Alex Chao3
Apurva Mody3
Steven Truitt2
Dasha Metropolitansky1
Robert Osazuwa Ness1
Jonathan Larson1
1Microsoft Research
2Microsoft Strategic Missions and Technologies
3Microsoft Office of the CTO
{daedge,trinhha,newmancheng,joshbradley,achao,moapurva,
steventruitt,dasham,robertness,jolarso}@microsoft.com
†These authors contributed equally to this work
Abstract
The use of retrieval-augmented generation (RAG) to retrieve relevant informa-
tion from an external knowledge source enables large language models (LLMs)
to answer questions over private and/or previously unseen document collections.
However, RAG fails on global questions directed at an entire text corpus, such
as “What are the main themes in the dataset?”, since this is inherently a query-
focused summarization (QFS) task, rather than an explicit retrieval task. Prior
QFS methods, meanwhile, do not scal
相比之下,元数据的大小将更为保守,以至于可以作为你喜欢的聊天模型的有效上下文组件:
pprint(documents[0].metadata)
输出:
{
'Published': '2025-02-19',
'Title': 'From Local to Global: A Graph RAG Approach to Query-Focused Summarization',
'Authors': 'Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha
Metropolitansky, Robert Osazuwa Ness, Jonathan Larson',
'Summary': 'The use of retrieval-augmented generation (RAG) to retrieve relevant\ninformation from an external
knowledge source enables large language models\n(LLMs) to answer questions over private and/or previously unseen
document\ncollections. However, RAG fails on global questions directed at an entire text\ncorpus, such as "What are
the main themes in the dataset?", since this is\ninherently a query-focused summarization (QFS) task, rather than
an explicit\nretrieval task. Prior QFS methods, meanwhile, do not scale to the quantities of\ntext indexed by
typical RAG systems. To combine the strengths of these\ncontrasting methods, we propose GraphRAG, a graph-based
approach to question\nanswering over private text corpora that scales with both the generality of\nuser questions
and the quantity of source text. Our approach uses an LLM to\nbuild a graph index in two stages: first, to derive
an entity knowledge graph\nfrom the source documents, then to pregenerate community summaries for all\ngroups of
closely related entities. Given a question, each community summary is\nused to generate a partial response, before
all partial responses are again\nsummarized in a final response to the user. For a class of global
sensemaking\nquestions over datasets in the 1 million token range, we show that GraphRAG\nleads to substantial
improvements over a conventional RAG baseline for both the\ncomprehensiveness and diversity of generated answers.'
}
但有一些关键特性如果不深入研究全文就无法实现:
- 元数据不是一定存在的:在
arxiv的例子中,论文的摘要、标题、作者和日期是提交的必要组成部分,所以能够查询它们并不奇怪。但对于任意一个PDF或网页,情况就不一定如此了。 - 无法深入了解文档内容 :摘要并没有提供一个直接的路径来与主体内容进行任何程度的交互。
- 无法同时对多个文档进行推理:当你需要同时与5个文档交互时,你会发现你的上下文窗口将被信息淹没。
3 转换文档
文档加载后,如果我们打算将它们作为上下文传递给我们的LLM,通常需要对它们进行转换。一种转换方法是分块(chunking),它将大块内容分解成更小的片段。这项技术很有价值,因为它有助于优化从向量数据库返回的内容的相关性。
LangChain提供了多种文档转换器,我们将使用RecursiveCharacterTextSplitter,它允许我们根据自然断点的偏好来分割我们的文档。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1200,
chunk_overlap=100,
separators=["\n\n", "\n", ".", ";", ",", " ", ""],
)
## 一些不错的自定义预处理
# documents[0].page_content = documents[0].page_content.replace(". .", "")
docs_split = text_splitter.split_documents(documents)
# def include_doc(doc):
# ## 一些块会被无用的数字数据所累,所以我们将其过滤掉
# string = doc.page_content
# if len([l for l in string if l.isalpha()]) < (len(string)//2):
# return False
# return True
# docs_split = [doc for doc in docs_split if include_doc(doc)]
print(len(docs_split)) # 输出83
我们可以查看不同的内容块:
for i in (0, 1, 2, 15, -1):
pprint(f"[Document {i}]")
print(docs_split[i].page_content)
pprint("="*64)
这种分块方法虽然简单,但它让我们快速为应用程序实现了基础功能。我们努力控制每个chunk的大小,目的是让模型能更有效地利用这些上下文信息。但我们将如何对所有这些片段进行推理呢?
当为任意文档集扩展和优化此方法时,一些潜在选项包括:
- 识别逻辑断点或采用合成技术: 我们可以手动、自动或借助LLM来识别文档中的自然分割点,或者合成新的信息块。
- 优化信息块内容: 目标是构建信息丰富、内容独特且相关的块,同时避免冗余,以最大限度地提升数据库的效用。
- 根据文档特性定制分块: 针对不同类型的文档,调整分块策略,确保每个块在上下文上都是相关且连贯的。
- 在块中嵌入关键信息: 在每个块中加入核心概念、关键词或元数据片段,以提高数据库的搜索效率和相关性。
- 持续评估与调整: 定期评估分块策略的有效性,并随时准备进行调整,以在块的大小和内容的丰富度之间找到最佳平衡。
- 考虑层次结构系统: 可以引入(隐式生成或显式指定的)层次结构来改进信息检索的尝试。可参考:LlamaIndex索引指南中的树结构。
4 优化摘要
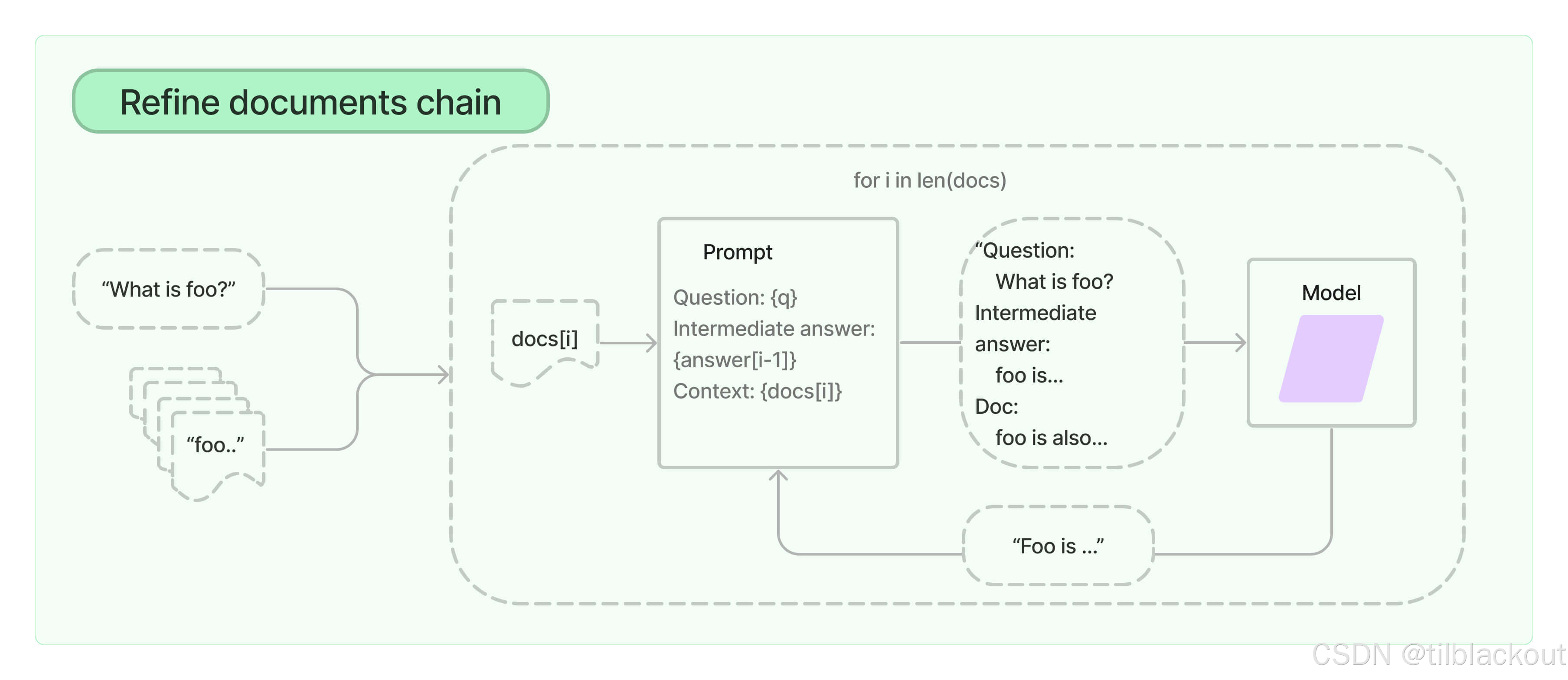
为了自动对大型文档进行推理,一个可能的想法是使用LLM来创建一个密集的摘要或知识库。类似于我们在上一篇文章中通过json填充来维护对话的运行历史,对整个文档保持一个运行历史是否存在任何问题?
我们将实现一个简单但有用的Runnable,它使用一个while循环和运行状态链的公式来总结一组文档块。这个过程通常被称为文档精炼(document refinement),与我们之前以对话为中心大同小异;唯一的区别是现在我们处理的是一个大型文档而不是一个不断增加的聊天历史。
DocumentSummaryBase
就像上一篇文章中的KnowledgeBase类一样,我们可以创建一个DocumentSummaryBase结构,旨在提炼文档的核心内容。下面的结构将使用running_summary字段来向模型查询最终的摘要,同时试图利用main_ideas和loose_ends字段作为约束条件,以防止运行中的摘要变化过快。这需要我们通过提示工程来执行,因此也提供了summary_prompt,展示了这些信息将如何被使用。我们可以根据选择的模型随意修改,使其能正常工作。
from langchain_core.runnables import RunnableLambda
from langchain_core.runnables.passthrough import RunnableAssign
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.output_parsers import PydanticOutputParser
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from pydantic import BaseModel, Field
from typing import List
from IPython.display import clear_output
class DocumentSummaryBase(BaseModel):
running_summary: str = Field("", description="Running description of the document. Do not override; only update!")
main_ideas: List[str] = Field([], description="Most important information from the document (max 3)")
loose_ends: List[str] = Field([], description="Open questions that would be good to incorporate into summary, but that are yet unknown (max 3)")
summary_prompt = ChatPromptTemplate.from_template(
"You are generating a running summary of the document. Make it readable by a technical user."
" After this, the old knowledge base will be replaced by the new one. Make sure a reader can still understand everything."
" Keep it short, but as dense and useful as possible! The information should flow from chunk to (loose ends or main ideas) to running_summary."
" The updated knowledge base keep all of the information from running_summary here: {info_base}."
"\n\n{format_instructions}. Follow the format precisely, including quotations and commas"
"\n\nWithout losing any of the info, update the knowledge base with the following: {input}"
)
我们将沿用上一篇文章中的RExtract函数:
def RExtract(pydantic_class, llm, prompt):
'''
可运行的提取模块
返回一个通过槽位填充提取填充的知识字典
'''
parser = PydanticOutputParser(pydantic_object=pydantic_class)
instruct_merge = RunnableAssign({'format_instructions' : lambda x: parser.get_format_instructions()})
def preparse(string):
if '{' not in string: string = '{' + string
if '}' not in string: string = string + '}'
string = (string
.replace("\\_", "_")
.replace("\n", " ")
.replace("\]", "]")
.replace("\[", "[")
)
# print(string) ## 用于诊断的好方法
return string
return instruct_merge | prompt | llm | preparse | parser
以下代码在一个for循环中调用运行状态链来迭代你的文档。唯一需要修改的应该是parse_chain 的实现,它应该通过一个正确配置的、RExtract链来传递状态。在此之后,系统应该能较好地维护文档的运行摘要(尽管可能需要根据所用模型对提示进行一些调整)。
latest_summary = ""
def RSummarizer(knowledge, llm, prompt, verbose=False):
def summarize_docs(docs):
parse_chain = RunnableAssign({'info_base' : RExtract(knowledge.__class__, llm, prompt)})
#state = {}
state = {'info_base' : knowledge}
global latest_summary ## 如果你的循环崩溃了,你可以检查最新的摘要
for i, doc in enumerate(docs):
state['input'] = doc.page_content
state = parse_chain.invoke(state)
assert 'info_base' in state
if verbose:
print(f"Considered {i+1} documents")
pprint(state['info_base'])
latest_summary = state['info_base']
clear_output(wait=True)
return state['info_base']
return RunnableLambda(summarize_docs)
# instruct_model = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1").bind(max_tokens=4096)
instruct_model = ChatNVIDIA(model="mistralai/mixtral-8x22b-instruct-v0.1").bind(max_tokens=4096)
instruct_llm = instruct_model | StrOutputParser()
## 取前10个文档块并累积一个DocumentSummaryBase
summarizer = RSummarizer(DocumentSummaryBase(), instruct_llm, summary_prompt, verbose=True)
summary = summarizer.invoke(docs_split[:20])
summary代表了对这些文档块整体的、最终的摘要,输出如下:
DocumentSummaryBase(
running_summary="GraphRAG is a graph-based approach for global sensemaking tasks, outperforming traditional RAG
and QFS methods on large text corpora. It constructs an entity knowledge graph using a Language Learning Model
(LLM) and generates hierarchical community summaries. The approach employs a LLM-as-a-judge technique, partitions
thematically via Leiden community detection, and uses query-focused summarization to generate a 'global answer'.
Community summaries are generated by adding various element summaries to a community summary template, with
lower-level summaries used to generate higher-level community summaries. GraphRAG is useful for understanding the
global structure and semantics of a dataset, and can handle query-less sensemaking. For a given community level,
the global answer to any user query is generated using the community summaries. Higher-level communities are
handled by ranking sub-communities based on element summary tokens and iteratively substituting sub-community
summaries for element summaries until they fit within the context window.",
main_ideas=[
'GraphRAG is a graph-based approach for global sensemaking tasks covering large text corpora.',
'GraphRAG constructs an entity knowledge graph and generates community summaries using a novel
LLM-as-a-judge technique.',
'GraphRAG employs Leiden community detection for hierarchical, recursive partitioning of Communities,
enabling divide-and-conquer global summarization.',
'GraphRAG generates a global answer using query-focused summarization over relevant community summaries.'
],
loose_ends=[
'What is the performance of GraphRAG under various datasets and novel scenarios?',
'What are the detailed implementation and computational requirements of GraphRAG?',
'How does LLM-as-a-judge handle context window constraints within the GraphRAG framework?',
'How are statistics derived from LLM-extracted claims used for GraphRAG validation?',
'How does GraphRAG use rule-matching, statistical pattern recognition, clustering, and embeddings for
knowledge graph extraction?',
'How does the scale of the dataset affect the performance of hierarchical partitioning using Leiden
community detection?',
'How are community summaries generated by adding various element summaries to a community summary
template?',
'What is the optimal balance of summary detail and scope for general sensemaking questions across different
hierarchical community levels?'
]
)
latest_summary是一个在处理过程中不断更新的变量,下面的print显示的是处理完最后一个文档块时的摘要状态。
pprint(latest_summary)
输出如下:
DocumentSummaryBase(
running_summary="GraphRAG enhances traditional RAG methods by integrating QFS techniques, addressing RAG's
limitations. It scales with question generality and source text quantity. GraphRAG employs a two-stage LLM process
for hierarchical community summaries and graph-based community detection for thematic data partitioning. Recursive
summaries span the community hierarchy, and adaptive benchmarking is proposed for RAG evaluation using LLMs. Our
work evaluates RAG-generated answers to global sensemaking questions and compares models using LLM-as-a-judge.
Documents are split into chunks for LLM extraction, with chunk size influencing recall. LLM extracts entities and
relationships with short descriptions for persona generation and sensemaking queries. Notably, NeoChip, a
previously private semiconductor firm specializing in low-power processors for wearables and IoT devices, was
acquired by Quantum Systems in 2016. The LLM extracts the entities NeoChip and Quantum Systems, along with their
relationship, for domain-specific application.",
main_ideas=[
'GraphRAG incorporates RAG and QFS methods to address RAG’s limitations',
'GraphRAG scales with both question generality and source text quantity',
'GraphRAG utilizes a graph-based approach for community detection and thematic partitioning of data',
'NeoChip is a semiconductor firm specializing in low-power processors for wearables and IoT devices, which
was acquired by Quantum Systems in 2016'
],
loose_ends=[
'How does the two-stage process of GraphRAG compare to traditional RAG methods?',
'What are the specific performance improvements of GraphRAG over RAG?',
'How does LLM-as-a-judge technique contribute to answering global sensemaking questions?',
'How does the acquisition of NeoChip by Quantum Systems impact their respective market positions?'
]
)
5 综合数据处理
我们已经展示了一种可行的方法来提取简洁、有意义的摘要,现在让我们深入探讨这种方法的重要性以及它带来的复杂性。
优化的通用性
值得注意的是,这种渐进式摘要技术仅仅是一个入门级的链,它对初始数据和期望的输出格式做出了很少的假设。同样的技术可以被广泛扩展,以生成具有已知元数据、主动假设和下游目标的综合性优化结果。
考虑以下潜在应用:
- 数据聚合: 构建能够将来自文档块的原始数据,转化为连贯、有用摘要的结构。
- 分类和子主题分析: 创建系统,将从数据块中提取的见解归类到预定义的类别中,并能跟踪每个类别内新兴的子主题。
- 整合为密集信息块: 优化这些结构,将见解提炼成紧凑的片段,并辅以直接引用以进行更深入的分析。
这些应用暗示着创建一个领域特定的知识图谱,该图谱可以被对话式聊天模型访问和遍历。现在已经存在一些实用的工具可以自动生成这些图谱,例如通过 LangChain知识图谱。虽然你可能需要开发相应的层次结构和工具来构建及遍历此类结构,但当你能为自己的用例正确优化一个完善的知识图谱时,这无疑是一个可行的选择。
- 如果你对依赖于更大型系统和向量相似性的高级知识图谱构建技术感兴趣,可以参考这篇文章:LangChain x Neo4j文章。
应对大规模数据处理的挑战
虽然我们的方法开启了激动人心的可能性,但它并非没有挑战,尤其是在处理大量数据时:
- 通用预处理的局限性: 尽管摘要生成相对直接,但开发在各种上下文中普遍有效的层次结构仍具挑战性。
- 粒度和导航成本: 在层次结构中实现详细的粒度可能会消耗大量资源。这需要复杂的整合或广泛的分支来维持每次交互中可管理的上下文大小。
- 对精确指令执行的依赖: 使用我们当前的工具来导航这样的层次结构,将严重依赖于通过强大提示工程驱动的、具备指令调优能力的模型。推理延迟和参数预测错误的风险可能很大,因此让LLM来完成这项任务可能会是一个挑战。
6 总结
这篇文章的目标是介绍围绕大型文档处理用于聊天模型的问题和技术,包括文档加载、结构化分块、内容转换、摘要提炼和状态维护等步骤,旨在将大文档转化为模型可用的、结构化的信息块,从而支持后续的问答、总结和信息整合等任务。


















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











