







这篇文章我们就来学习嵌入模型(Embedding Models)的核心概念及其在NLP中的应用。我们将从基础理论出发,了解什么是潜在嵌入、词嵌入以及句子嵌入,并区分解码器与编码器模型的不同架构。
文章目录
1 引入
在之前的内容中,我们已经涉足了大型文档处理领域,并学习了如何应用现有技术来处理大量相关内容。然而,我们仍然面临一些挑战,特别是在即时内容解析方面,现有技术难以完全解决。
因此,本文将焦点转移到一种不同的方法上:嵌入模型。我们将通过学习和应用嵌入模型,来攻克这些难题。
- 熟悉嵌入(
Embeddings),即词语、短语或文档的数值表示形式,并理解它们如何使深度学习模型能够处理语义。 - 学习如何将这些嵌入模型应用于大规模文档处理,以增强我们现有的文档摘要和知识提取方法。
2 嵌入模型基础回顾
潜在嵌入是深度学习网络中的中间层,它在输入和输出之间架起了一座桥梁。例如,一个用于分类MNIST数字的轻量级两层网络,其输入和输出可能分别是扁平化的图像和独热(one-hot)概率向量。在这种设置中,第一层产生的值就是图像的潜在嵌入。通过优化过程,这些嵌入会收敛成对最终层有用的表示形式。这使得它们成为富含语义的嵌入,虽然可能不易于人类直接解读,但其原始的向量属性仍然可以被有效利用。
2.1 词嵌入
词嵌入是单个词语的高维向量表示,它们构成了深度语言模型的骨干。这些嵌入是通过针对特定任务的端到端流程中的优化过程创建的。在实践中,来自语言模型v个词汇的词元(token)会从一个词元索引映射到一个d维的词元嵌入:
Token Index ∈ { 0 , 1 , ⋯ , v − 1 } → Token Embedding ∈ R d \text{Token Index} \in \{0, 1, \cdots, v-1\} \to \text{Token Embedding} \in \mathbb{R}^{d} Token Index∈{0,1,⋯,v−1}→Token Embedding∈Rd
对于一个包含n个词元的序列,这种映射会扩展到整个序列:
Token Sequence ∈ { 0 , 1 , ⋯ , v − 1 } v → Embedding Sequence ∈ R n × d \text{Token Sequence} \in \{0, 1, \cdots, v-1\}^{v} \to \text{Embedding Sequence} \in \mathbb{R}^{n\times d} Token Sequence∈{0,1,⋯,v−1}v→Embedding Sequence∈Rn×d
2.2 句子/文档嵌入
在处理句子或整个文档时,嵌入在捕捉上下文、意义以及元素间相互作用方面扮演着至关重要的角色。几乎所有的大型语言模型都利用类Transformer架构来生成这些句子/文档嵌入。Transformer架构使得网络能够在解决优化问题时,兼顾词元和整个序列的信息。
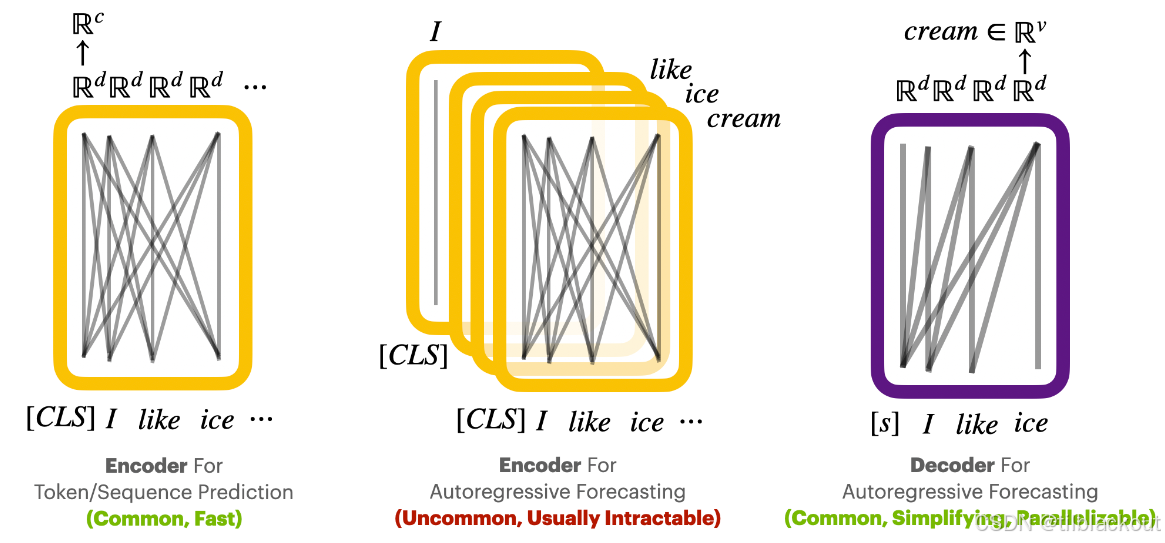
2.3 解码器模型
解码器模型通常用于聊天机器人和其他语言生成任务。它们首先接收一个词元序列作为输入,将这些词元嵌入到一个潜在序列中,并应用单向推理来聚焦于输出序列的特定部分。从这个聚焦的、语义密集的点开始,模型预测序列中的下一个词元:
[ Next-Token Generation ]
\text{[ Next-Token Generation ]}
[ Next-Token Generation ]
Embedding Sequence
∈
R
n
×
d
→
Latent Sequence
∈
R
n
×
d
\text{Embedding Sequence} \in \mathbb{R}^{n\times d} \to \text{Latent Sequence} \in \mathbb{R}^{n\times d}
Embedding Sequence∈Rn×d→Latent Sequence∈Rn×d
(
Latent Sequence
)
[
last entry
]
∈
R
d
→
Token Prediction
∈
R
v
(\text{Latent Sequence})[\text{last entry}] \in \mathbb{R}^{d} \to \text{Token Prediction} \in \mathbb{R}^{v}
(Latent Sequence)[last entry]∈Rd→Token Prediction∈Rv
这个过程会持续进行,将词元预测从一个向量具体化为一个已实现的词元,并逐步构建一个预测序列,直到满足终止条件,例如达到长度限制或遇到停止词元。
[ Autoregressive Generation ]
\text{[ Autoregressive Generation ]}
[ Autoregressive Generation ]
(
Original + Predicted Embedding Sequence
)
∈
R
(
n
+
1
)
×
e
→
Token Prediction
∈
R
v
(\text{Original + Predicted Embedding Sequence}) \in \mathbb{R}^{(n+1)\times e} \to \text{Token Prediction} \in \mathbb{R}^{v}
(Original + Predicted Embedding Sequence)∈R(n+1)×e→Token Prediction∈Rv
⋮
\vdots
⋮
(
Original + Predicted Embedding Sequence
)
∈
R
(
n
+
m
)
×
e
→
Token Prediction
∈
R
v
(\text{Original + Predicted Embedding Sequence}) \in \mathbb{R}^{(n+m)\times e} \to \text{Token Prediction} \in \mathbb{R}^{v}
(Original + Predicted Embedding Sequence)∈R(n+m)×e→Token Prediction∈Rv
2.4 编码器模型
与解码器模型相比,编码器模型使用双向架构,这使它们适用于不同类型的任务。它们在诸如词元或序列预测之类的任务中特别有效。设c为类别或回归值的数量:
[ Per-Token Prediction ]
\text{[ Per-Token Prediction ]}
[ Per-Token Prediction ]
Embedding Sequence
∈
R
n
×
d
→
Latent Sequence
∈
R
n
×
d
→
Per-Token Predictions
∈
R
n
×
c
\text{Embedding Sequence} \in \mathbb{R}^{n\times d} \to \text{Latent Sequence} \in \mathbb{R}^{n\times d} \to \text{Per-Token Predictions} \in \mathbb{R}^{n\times c}
Embedding Sequence∈Rn×d→Latent Sequence∈Rn×d→Per-Token Predictions∈Rn×c
[ Full-Sequence Prediction ]
\text{[ Full-Sequence Prediction ]}
[ Full-Sequence Prediction ]
Embedding Sequence
∈
R
n
×
d
→
Latent Sequence
∈
R
n
×
d
\text{Embedding Sequence} \in \mathbb{R}^{n\times d} \to \text{Latent Sequence} \in \mathbb{R}^{n\times d}
Embedding Sequence∈Rn×d→Latent Sequence∈Rn×d
(
Latent Sequence
)
[
0th entry
]
∈
R
d
→
Sequence Prediction
∈
R
c
(\text{Latent Sequence})[\text{0th entry}] \in \mathbb{R}^{d} \to \text{Sequence Prediction} \in \mathbb{R}^{c}
(Latent Sequence)[0th entry]∈Rd→Sequence Prediction∈Rc
3 实战:使用NVIDIA嵌入模型
在本文中,我们将使用一个具有两条路径的嵌入模型:一条是为较短格式的查询(query)设计的路径,另一条是为较长格式的段落(passage)设计的路径。通过这样做,我们将学习如何正确地理解其输出,并利用它来补充我们现有的LLM工具集。
3.1 选择模型
在可用的模型中,你应该能找到一个适合区分人类可读段落的嵌入模型。在确定了感兴趣的端点后,创建一个连接到它的NVIDIAEmbeddings实例,并查看它提供了哪些方法。
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
# 筛选出ID中包含 "embed" 的可用模型
[m for m in NVIDIAEmbeddings.get_available_models() if "embed" in m.id]
根据输出,我们选择:
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
# NVIDIAEmbeddings.get_available_models() # 获取所有可用模型
# embedder = NVIDIAEmbeddings(model="nvidia/nv-embedqa-mistral-7b-v2")
# embedder = NVIDIAEmbeddings(model="nvidia/nv-embedqa-e5-v5")
# embedder = NVIDIAEmbeddings(model="nvidia/embed-qa-4")
# embedder = NVIDIAEmbeddings(model="snowflake/arctic-embed-l")
embedder = NVIDIAEmbeddings(model="nvidia/nv-embed-v1")
# ChatNVIDIA.get_available_models() # 获取所有可用的聊天模型
instruct_llm = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1")
3.2 查询嵌入和文档嵌入
在使用LangChain的Embeddings接口与我们的NVIDIAEmbeddings模型时,我们关注于嵌入查询(queries)和文档(documents)的双重路径。这种区分在数据如何被处理和应用于基于检索的应用中起着关键作用。
查询嵌入 (Query Embedding)
- 目的: 设计用于嵌入较短形式或问题类型的内容,例如一个简单的陈述或一个问题。
- 方法: 使用
embed_query对每个查询进行单独嵌入。 - 在检索中的角色: 充当密钥生成器,以在文档检索框架中启用搜索(查询过程)。
- 使用模式: 根据需要动态嵌入,以便与预处理的文档嵌入集合进行比较。
文档嵌入 (Document Embedding)
- 目的: 专为较长形式或回答类型的内容量身定制,包括文档块或段落。
- 方法: 使用
embed_documents对文档进行批量处理。 - 在检索中的角色: 充当值生成器,为检索系统创建可搜索的内容。
- 使用模式: 通常作为一个预处理步骤被批量嵌入,创建一个文档嵌入的存储库以供未来查询。
尽管它们在应用上有所不同,但这两个过程共享一个核心功能:它们都将文本内容处理成富含语义的向量化表示。选择embed_query还是embed_documents取决于内容的性质以及在检索系统中的预期用途。
例子
让我们来看一组示例查询和文档,并理解这些过程在实践中的作用。这些例子经过精心挑选,为了评估我们的嵌入模型在一般文本推理方面的能力。
# 示例查询和文档
queries = [
"What's the weather like in Rocky Mountains?", # 洛基山脉的天气怎么样?
"What kinds of food is Italy known for?", # 意大利以哪些食物闻名?
"What's my name? I bet you don't remember...", # 我叫什么名字?我打赌你不记得了...
"What's the point of life anyways?", # 人生的意义到底是什么?
"The point of life is to have fun :D" # 人生的意义在于享受乐趣 :D
]
documents = [
"Komchatka's weather is cold, with long, severe winters.", # 勘察加半岛天气寒冷,冬季漫长而严酷。
"Italy is famous for pasta, pizza, gelato, and espresso.", # 意大利以意面、披萨、冰淇淋和浓缩咖啡而闻名。
"I can't recall personal names, only provide information.", # 我记不住个人姓名,只能提供信息。
"Life's purpose varies, often seen as personal fulfillment.", # 人生的目的各不相同,通常被看作是个人价值的实现。
"Enjoying life's moments is indeed a wonderful approach.", # 享受生活的瞬间确实是一种美妙的方式。
]
我们可以通过查询或文档路径对这些段落进行编码。由于它们的预期用途不同,方法签名也不同,因此两种选项的语法会略有差异。
%%time
# 嵌入查询
q_embeddings = [embedder.embed_query(query) for query in queries]
# 嵌入文档
d_embeddings = embedder.embed_documents(documents)
有了嵌入之后,我们可以对结果进行简单的相似度检查,看看在检索任务中哪些文档会作为合理的答案被触发。准备好条目后,运行以下代码块以可视化交叉相似度矩阵。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
def plot_cross_similarity_matrix(emb1, emb2):
# 计算 embeddings1 和 embeddings2 之间的相似度矩阵
cross_similarity_matrix = cosine_similarity(np.array(emb1), np.array(emb2))
# 绘制交叉相似度矩阵
plt.imshow(cross_similarity_matrix, cmap='Greens', interpolation='nearest')
plt.colorbar()
plt.gca().invert_yaxis()
plt.title("Cross-Similarity Matrix")
plt.grid(True)
plt.figure(figsize=(8, 6))
plot_cross_similarity_matrix(q_embeddings, d_embeddings)
plt.xlabel("Query Embeddings")
plt.ylabel("Document Embeddings")
plt.show()
# queries = [
# "What's the weather like in the Rocky Mountains?",
# "What kinds of food is Italy known for?",
# "What's my name? I bet you don't remember...",
# "What's the point of life anyways?",
# "The point of life is to have fun :D"]
# documents = [
# "Komchatka's weather is cold, with long, severe winters.",
# "Italy is famous for pasta, pizza, gelato, and espresso.",
# "I can't recall personal names, only provide information.",
# "Life's purpose varies, often seen as personal fulfillment.",
# "Enjoying life's moments is indeed a wonderful approach."]
输出如下:
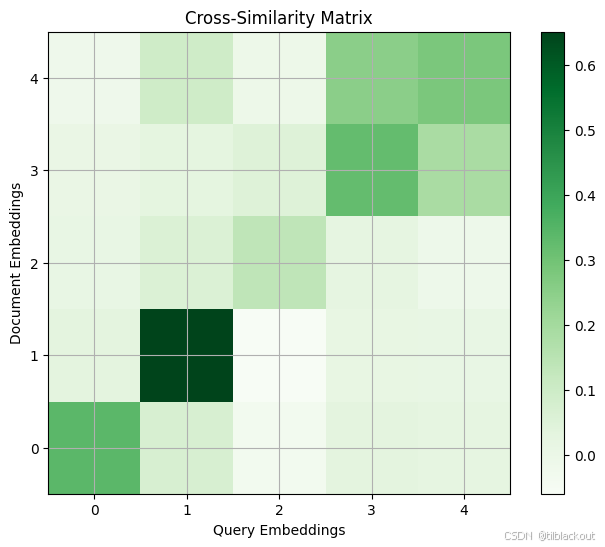
4 更真实的合成例子
观察可以发现,那些可被视为良好输入/输出对的条目,在嵌入上的相似度相对较高。值得一提的是,根据编码器模型的收敛情况,查询路径和文档路径可能会有显著差异,也可能没有。
plt.figure(figsize=(8, 6))
plot_cross_similarity_matrix(
q_embeddings,
[embedder.embed_query(doc) for doc in documents]
)
plt.xlabel("Query Embeddings (of queries)")
plt.ylabel("Query Embeddings (of documents)")
plt.show()
输出:
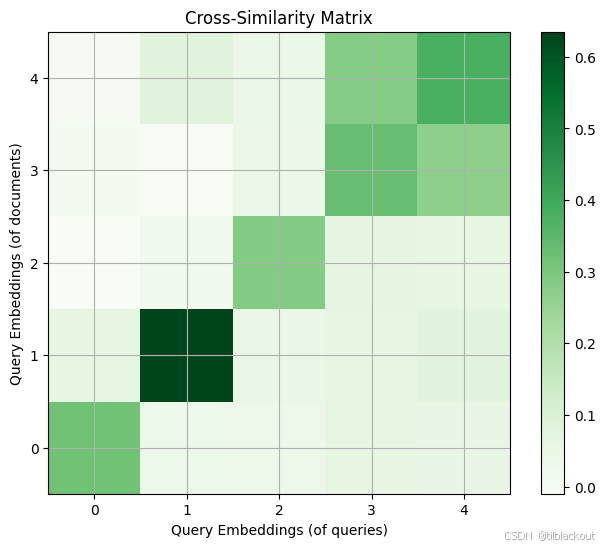
通常来说,拥有一个双编码器的真正效用在于,即使输入的格式开始发生巨大变化,第二个编码器也可以通过训练来与第一个编码器保持一致。为了更好地说明这一点,我们可以将我们的文档扩充为更长的版本,然后再次尝试同样的实验。
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
expound_prompt = ChatPromptTemplate.from_template(
"Generate part of a longer story that could reasonably answer all"
" of these questions somewhere in its contents: {questions}\n"
" Make sure the passage only answers the following concretely: {q1}."
" Give it some weird formatting, and try not to answer the others."
" Do not include any commentary like 'Here is your response'"
)
expound_chain = (
{'q1' : itemgetter(0), 'questions' : itemgetter(1)}
| expound_prompt
| instruct_llm
| StrOutputParser()
)
longer_docs = []
for i, q in enumerate(queries):
longer_doc = ""
longer_doc = expound_chain.invoke([q, queries])
pprint(f"\n\n[Query {i+1}]")
print(q)
pprint(f"\n\n[Document {i+1}]")
print(longer_doc)
pprint("-"*64)
longer_docs += [longer_doc]
部分输出如下:
当你对长格式文档满意后,我们可以运行下面的代码来比较嵌入效果。结果可能相似,但至少存在某种数学上优化的关系,这可能有助于在更大规模上改善检索结果。这个结果也会因双编码器模型的不同而有所差异。
总的来说,一个好的做法是默认使用专为特定用途设计的编码器(例如,用文档编码器处理文档),而当你假设要比较的内容在形式和模态上相似时,则倾向于使用相同的编码器。需要明确的是,我们测试的模型在这两种选项之间的偏差非常小,但这仍然是一个需要考虑的因素。
## 在编写本文时,我们的嵌入模型最多支持2048个词元...
longer_docs_cut = [doc[:2048] for doc in longer_docs]
q_long_embs = [embedder._embed([doc], model_type='query')[0] for doc in longer_docs_cut]
d_long_embs = [embedder._embed([doc], model_type='passage')[0] for doc in longer_docs_cut]
## 对于任何特定示例,差异可能非常小。
## 我们将相似度矩阵的5次方以试图发现差异。
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plot_cross_similarity_matrix(q_embeddings, q_long_embs)
plt.xlabel("Query Embeddings (of queries)")
plt.ylabel("Query Embeddings (of long documents)")
plt.subplot(1, 2, 2)
plot_cross_similarity_matrix(q_embeddings, d_long_embs)
plt.xlabel("Query Embeddings (of queries)")
plt.ylabel("Document Embeddings (of long documents)")
plt.show()
注意: 要查看两个差异巨大的双编码器组件,可以考虑研究一下 对比语言-图像预训练模型(CLIP)。这对双编码器在一个更宽的模态鸿沟上协同工作,连接的是图像和文本模态,而不是查询和文档模态。
5 总结
通过阅读本文,你应该已经熟悉了语义嵌入模型的价值主张,并理解了我们如何使用它来在数据集中搜索相关信息…


















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











