







到目前为止,我们已经使用FashionMNIST数据集训练了一个模型来生成服装图像。然而,用户还无法指定要生成哪一类图像。在本篇文章中,我们将逐步构建一个 条件扩散模型(Conditional Diffusion Model),不仅能够生成时尚图像,还允许你指定类别,比如T恤、裙子、鞋子等。我们还会使用一种称为Classifier-Free Guidance的技巧来显著提升生成质量。
文章目录
1 准备工作
在我们开始之前,先加载所需的库和数据集信息。
# 导入 glob 模块用于文件路径匹配
import glob
# 导入 PyTorch
import torch
# 导入函数式 API
import torch.nn.functional as F
# 导入优化器 Adam
from torch.optim import Adam
# 导入图像预处理方法
import torchvision.transforms as transforms
# 可视化工具
# 导入绘图库
import matplotlib.pyplot as plt
# 导入 PIL 图像处理库
from PIL import Image
# 导入图像保存和网格制作工具
from torchvision.utils import save_image, make_grid
# 导入自定义库
from utils import other_utils
from utils import ddpm_utils
from utils import UNet_utils
# 设置设备为 GPU(如果可用)或 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 图像尺寸
IMG_SIZE = 16
# 图像通道数(灰度图为 1)
IMG_CH = 1
# 每批训练样本数量
BATCH_SIZE = 128
# 类别数
N_CLASSES = 10
# 加载经过变换的数据集
data, dataloader = other_utils.load_transformed_fashionMNIST(IMG_SIZE, BATCH_SIZE)
对于FashionMNIST数据集来说,它的DataLoader每个batch返回的是一个元组(images, labels)。假设batch size为4,则:
batch[0] = 图像 = torch.Size([4, 1, 28, 28]) # 每个样本是 28x28 的灰度图
batch[1] = 标签 = tensor([0, 5, 2, 9]) # 这 4 张图的类别标签
我们就可以利用这个标签来嵌入类别信息。
2 U-Net模型添加类别嵌入
2.1 模型修改
我们之前的β时间调度策略保持不变。
# 行数
nrows = 10
# 列数
ncols = 15
# 总扩散步数
T = nrows * ncols
# β 起始值
B_start = 0.0001
# β 结束值
B_end = 0.02
# 构建线性 β 调度表
B = torch.linspace(B_start, B_end, T).to(device)
# 实例化 DDPM 类
ddpm = ddpm_utils.DDPM(B, device)
这一次,我们的UNet有了一些变化。我们添加了新的组件,并将其架构独立放在了UNet_utils.py文件中。
完整文件如下:
import math
import torch
import torch.nn as nn
from einops.layers.torch import Rearrange
class GELUConvBlock(nn.Module):
def __init__(self, in_ch, out_ch, group_size):
super().__init__()
layers = [
nn.Conv2d(in_ch, out_ch, 3, 1, 1),
nn.GroupNorm(group_size, out_ch),
nn.GELU(),
]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class RearrangePoolBlock(nn.Module):
def __init__(self, in_chs, group_size):
super().__init__()
self.rearrange = Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2)
self.conv = GELUConvBlock(4 * in_chs, in_chs, group_size)
def forward(self, x):
x = self.rearrange(x)
return self.conv(x)
class DownBlock(nn.Module):
def __init__(self, in_chs, out_chs, group_size):
super(DownBlock, self).__init__()
layers = [
GELUConvBlock(in_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
RearrangePoolBlock(out_chs, group_size),
]
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UpBlock(nn.Module):
def __init__(self, in_chs, out_chs, group_size):
super(UpBlock, self).__init__()
layers = [
nn.ConvTranspose2d(2 * in_chs, out_chs, 2, 2),
GELUConvBlock(out_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
]
self.model = nn.Sequential(*layers)
def forward(self, x, skip):
x = torch.cat((x, skip), 1)
x = self.model(x)
return x
class SinusoidalPositionEmbedBlock(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, time):
device = time.device
half_dim = self.dim // 2
embeddings = math.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
embeddings = time[:, None] * embeddings[None, :]
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
class EmbedBlock(nn.Module):
def __init__(self, input_dim, emb_dim):
super(EmbedBlock, self).__init__()
self.input_dim = input_dim
layers = [
nn.Linear(input_dim, emb_dim),
nn.GELU(),
nn.Linear(emb_dim, emb_dim),
nn.Unflatten(1, (emb_dim, 1, 1)),
]
self.model = nn.Sequential(*layers)
def forward(self, x):
x = x.view(-1, self.input_dim)
return self.model(x)
class ResidualConvBlock(nn.Module):
def __init__(self, in_chs, out_chs, group_size):
super().__init__()
self.conv1 = GELUConvBlock(in_chs, out_chs, group_size)
self.conv2 = GELUConvBlock(out_chs, out_chs, group_size)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
out = x1 + x2
return out
class UNet(nn.Module):
def __init__(
self, T, img_ch, img_size, down_chs=(64, 64, 128), t_embed_dim=8, c_embed_dim=10
):
super().__init__()
self.T = T
up_chs = down_chs[::-1] # Reverse of the down channels
latent_image_size = img_size // 4 # 2 ** (len(down_chs) - 1)
small_group_size = 8
big_group_size = 32
# Inital convolution
self.down0 = ResidualConvBlock(img_ch, down_chs[0], small_group_size)
# Downsample
self.down1 = DownBlock(down_chs[0], down_chs[1], big_group_size)
self.down2 = DownBlock(down_chs[1], down_chs[2], big_group_size)
self.to_vec = nn.Sequential(nn.Flatten(), nn.GELU())
# Embeddings
self.dense_emb = nn.Sequential(
nn.Linear(down_chs[2] * latent_image_size**2, down_chs[1]),
nn.ReLU(),
nn.Linear(down_chs[1], down_chs[1]),
nn.ReLU(),
nn.Linear(down_chs[1], down_chs[2] * latent_image_size**2),
nn.ReLU(),
)
self.sinusoidaltime = SinusoidalPositionEmbedBlock(t_embed_dim)
self.t_emb1 = EmbedBlock(t_embed_dim, up_chs[0])
self.t_emb2 = EmbedBlock(t_embed_dim, up_chs[1])
self.c_embed1 = EmbedBlock(c_embed_dim, up_chs[0])
self.c_embed2 = EmbedBlock(c_embed_dim, up_chs[1])
# Upsample
self.up0 = nn.Sequential(
nn.Unflatten(1, (up_chs[0], latent_image_size, latent_image_size)),
GELUConvBlock(up_chs[0], up_chs[0], big_group_size),
)
self.up1 = UpBlock(up_chs[0], up_chs[1], big_group_size)
self.up2 = UpBlock(up_chs[1], up_chs[2], big_group_size)
# Match output channels and one last concatenation
self.out = nn.Sequential(
nn.Conv2d(2 * up_chs[-1], up_chs[-1], 3, 1, 1),
nn.GroupNorm(small_group_size, up_chs[-1]),
nn.ReLU(),
nn.Conv2d(up_chs[-1], img_ch, 3, 1, 1),
)
def forward(self, x, t, c, c_mask):
down0 = self.down0(x)
down1 = self.down1(down0)
down2 = self.down2(down1)
latent_vec = self.to_vec(down2)
latent_vec = self.dense_emb(latent_vec)
t = t.float() / self.T # Convert from [0, T] to [0, 1]
t = self.sinusoidaltime(t)
t_emb1 = self.t_emb1(t)
t_emb2 = self.t_emb2(t)
c = c * c_mask
c_emb1 = self.c_embed1(c)
c_emb2 = self.c_embed2(c)
up0 = self.up0(latent_vec)
up1 = self.up1(c_emb1 * up0 + t_emb1, down2)
up2 = self.up2(c_emb2 * up1 + t_emb2, down1)
return self.out(torch.cat((up2, down0), 1))
def get_context_mask(c, drop_prob, num_classes):
c_hot = F.one_hot(c.to(torch.int64), num_classes=num_classes).to(device)
c_mask = torch.bernoulli(torch.ones_like(c_hot).float() - drop_prob).to(device)
return c_hot, c_mask
在__init__函数中,我们新增了一个参数c_embed_dim。类似于时间步t,我们可以为类别创建嵌入向量。
# 正弦位置编码用于时间步嵌入
self.sinusoidaltime = SinusoidalPositionEmbedBlock(t_embed_dim)
# 时间步嵌入的第 1 层
self.t_emb1 = EmbedBlock(t_embed_dim, up_chs[0])
# 时间步嵌入的第 2 层
self.t_emb2 = EmbedBlock(t_embed_dim, up_chs[1])
# 类别嵌入的第 1 层(新增)
self.c_embed1 = EmbedBlock(c_embed_dim, up_chs[0]) # New
# 类别嵌入的第 2 层(新增)
self.c_embed2 = EmbedBlock(c_embed_dim, up_chs[1]) # New
接着,在forward函数中,我们新增了两个参数:c和c_mask。
c是表示类别的向量。它可以是独热编码或嵌入向量。告诉模型你想生成哪一类图像的信息。c_mask用于随机将c中的值设为 0。这有助于模型学习在没有类别条件时的平均输出表现(类似于之前的模型)。即控制是否使用该类别。
c是one-hot编码的类别向量,比如[0, 1, 0, 0]表示第 2 类。c_mask是一个同样形状的掩码向量,元素为0或1。使用伯努利分布随机生成,比如[1, 0, 1, 1]。c = c * c_mask会把c中某些维度 强制设为0,即屏蔽掉部分类别信息。如果模型只在有完整类别信息的时候训练,它可能学不会如何在不知道类别时该怎么办。而加了
c_mask,模型就要学会在 类别信息缺失的情况下,也能做出合理输出。在你之前没加入类别嵌入的时候,模型本来就是 纯无条件的,完全靠图像噪声和时间步来恢复图像。
现在你加入类别嵌入后,模型变成了条件模型。为了保留无条件的能力,就用这个随机屏蔽的技巧让模型两种模式都学到。
# 将类别向量乘以掩码,模拟部分丢失
c = c * c_mask
# 计算第一个类别嵌入层的输出
c_emb1 = self.c_embed1(c)
# 计算第二个类别嵌入层的输出
c_emb2 = self.c_embed2(c)
我们可以通过多种方式将嵌入的类别信息引入模型中。一种流行方法是缩放和偏移(scale-and-shift)。我们可以将类别嵌入与潜在图像相乘,然后加上时间嵌入t_emb。缩放和偏移类似于方差和均值的作用。
# 上采样第一层
up0 = self.up0(latent_vec)
# 上采样第二层,将类别嵌入与特征相乘后再加时间嵌入
up1 = self.up1(c_emb1 * up0 + t_emb1, down2) # Changed
# 上采样第三层,同样合并类别嵌入和时间嵌入
up2 = self.up2(c_emb2 * up1 + t_emb2, down1) # Changed
# 返回最终输出
return self.out(torch.cat((up2, down0), 1))
上面代码把
c_emb1和c_emb2嵌入向量融合到模型的特征图中。比如c_emb1 * up0 + t_emb1中的参数:up0是图像的 latent 特征;c_emb1是类别嵌入(理解为调色板);t_emb1是时间步嵌入(扩散调度引导)。用类别嵌入去 缩放图像特征,再加上时间信息相当于告诉模型:“你现在正在生成一个裙子,在扩散第 35 步”。这个指令是通过向量调制的方式影响图像特征的,让模型按照这个类别去调图像的细节。
为什么放在 UpBlock 中?
- DownBlock 是提取图像特征,我们不希望提前引入类别干扰图像理解。
- UpBlock 是生成阶段,模型已经理解了图像,这时我们告诉它:“现在,请生成裙子”,就刚刚好。
我们使用get_context_mask函数将标签转换为模型可以处理的格式。因为标签是整数,我们可以用 F.one_hot 转换成编码向量。
为了随机将one-hot编码中的值设置为0,我们使用伯努利分布。这类似于加权硬币投掷,正面出现概率为
p
p
p,反面为
1
−
p
1-p
1−p。这里,drop_prob表示反面的概率。
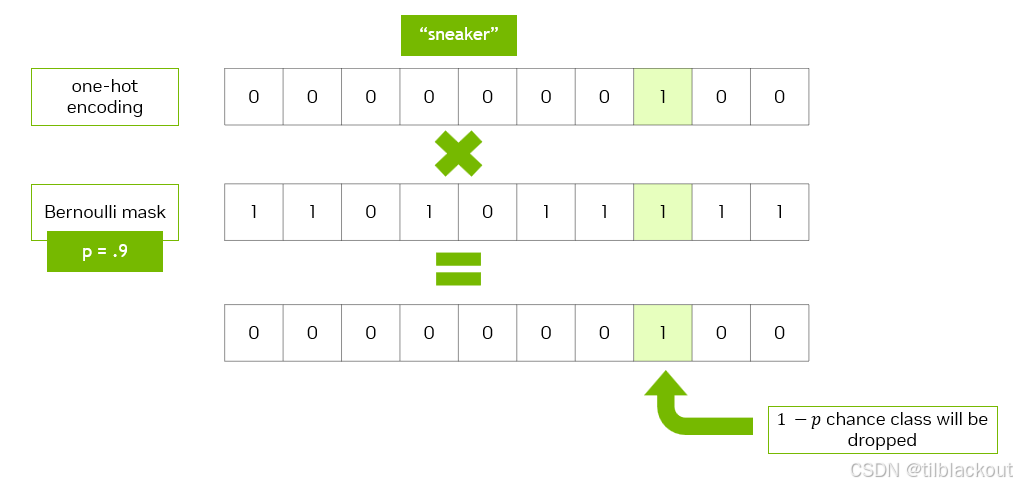
代码如下:
# 获取上下文掩码
def get_context_mask(c, drop_prob):
# 将类别转换为独热编码
c_hot = F.one_hot(c.to(torch.int64), num_classes=N_CLASSES).to(device)
# 使用伯努利分布构造掩码,随机将某些位设为 0
c_mask = torch.bernoulli(torch.ones_like(c_hot).float() - drop_prob).to(device)
# 返回类别编码与掩码
return c_hot, c_mask
以上就是我们需要对UNet做出的全部更改,以使其能够学习类别条件信息。
2.2 模型训练
现在构建一个这个新结构的实例:
# 实例化条件 UNet 模型
model = UNet_utils.UNet(
T, IMG_CH, IMG_SIZE, down_chs=(64, 64, 128), t_embed_dim=8, c_embed_dim=N_CLASSES
)
# 打印模型参数数量
print("Num params: ", sum(p.numel() for p in model.parameters())) # 输出2002561
# 使用 torch.compile 提升性能
model = torch.compile(model.to(device))
为了知道模型当前试图生成什么类别,我们保留了一个类别名称列表。这个顺序与数据集中的标签一致。例如,当标签为3时表示dress。
# 类别名称列表(与标签顺序一致)
class_names = [
"Top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
训练步骤与上次非常相似。我们会在每次预览时循环显示不同类别,以观察模型在各类别上的学习表现。
# 定义优化器
optimizer = Adam(model.parameters(), lr=0.001)
# 训练轮数
epochs = 3
# 当前预览的类别
preview_c = 0
# 设置模型为训练模式
model.train()
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
# 设置类别丢弃概率
c_drop_prob = 0.1
# 清空梯度
optimizer.zero_grad()
# 随机选择时间步
t = torch.randint(0, T, (BATCH_SIZE,), device=device).float()
# 获取图像
x = batch[0].to(device)
# 获取类别嵌入及其掩码(新增)
c_hot, c_mask = get_context_mask(batch[1], c_drop_prob)
# 计算损失
loss = ddpm.get_loss(model, x, t, c_hot, c_mask)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 每轮每 100 步打印一次损失
if epoch % 1 == 0 and step % 100 == 0:
class_name = class_names[preview_c]
print(f"Epoch {epoch} | Step {step:03d} | Loss: {loss.item()} | C: {class_name}")
# 预览时不丢弃上下文
c_drop_prob = 0
c_hot, c_mask = get_context_mask(torch.Tensor([preview_c]), c_drop_prob)
# 采样并显示图像
ddpm.sample_images(model, IMG_CH, IMG_SIZE, ncols, c_hot, c_mask)
# 循环切换预览类别
preview_c = (preview_c + 1) % N_CLASSES
训练的部分输出如下:

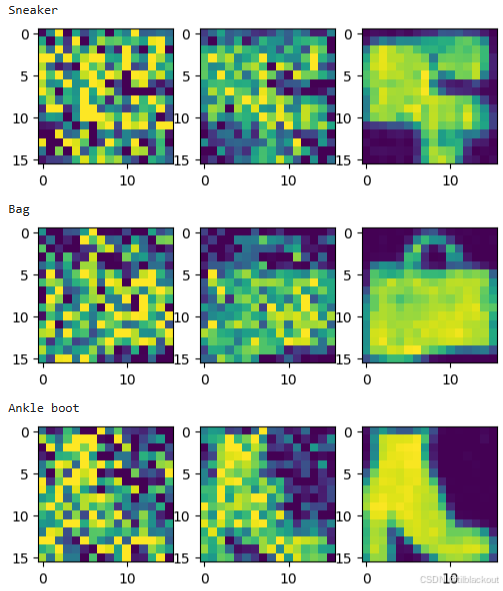
现在我们看看模型表现如何:
# 显示最终每类生成图像
plt.figure(figsize=(8,8))
ncols = 3
# 设置类别掩码丢弃概率(可调)
c_drop_prob = 0
for c in range(10):
print(class_names[c])
c_hot, c_mask = get_context_mask(torch.Tensor([c]), c_drop_prob)
ddpm.sample_images(model, IMG_CH, IMG_SIZE, ncols, c_hot, c_mask, axis_on=True)
部分输出如下:
3 条件反向扩散(Conditioning Reverse Diffusion)
刚刚效果还不错,但也还没到完美的程度。有些类别之间仍然存在干扰。例如,下面这只鞋子好像挂着一只衬衫袖子。
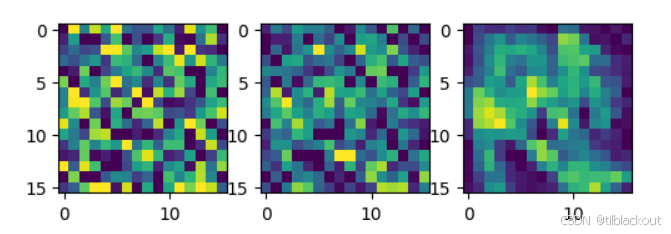
Classifier-Free Guidance是一种提高生成质量和控制能力的技巧。在训练时,模型有时候带标签训练(条件的),有时候不带(无条件);在生成图像时,它会同时预测两个版本:有条件预测(知道类别)和无条件预测(不知道类别)。我们可以通过提高类别的权重来解决这个问题。策略如下:
- 在反向扩散的每个时间步中,我们将对图像进行两次去噪:
- 第一次提取的噪声图像保留类别信息(记作
e_t_keep_c) - 第二次提取的噪声图像丢弃类别信息(记作
e_t_drop_c)
- 第一次提取的噪声图像保留类别信息(记作
- 我们将使用以下公式从类别噪声中减去平均噪声:
e_t = (1 + w) * e_t_keep_c - w * e_t_drop_c- 其中
w是我们设定的超参数(weight)
- 然后我们将使用这个新的
e_t噪声,通过reverse_q执行扩散操作。 - 从
t = T到0重复上述步骤。
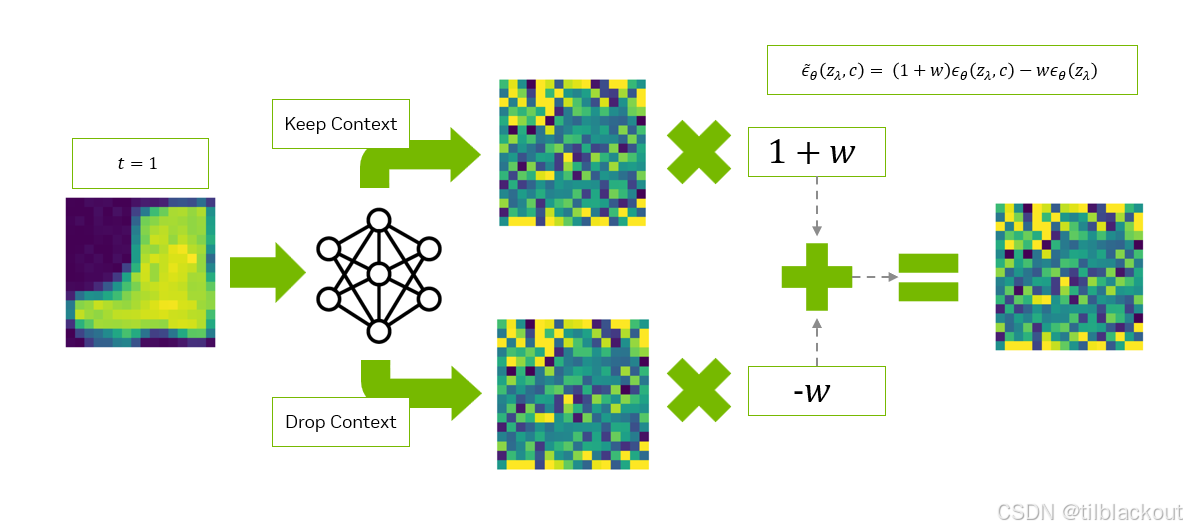
我们已经在下面的sample_w函数中实现了这些步骤。该函数接收一个噪声权重列表w_tests,以便我们比较不同权重对扩散效果的影响。
# 使用装饰器关闭梯度计算(用于推理阶段)
@torch.no_grad()
def sample_w(
model, input_size, T, c, w_tests=[-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0], store_freq=10
):
# 为每个类别和每个权重准备样本网格
n_samples = len(w_tests) * len(c)
# 为每个类别生成一个 w 值(broadcast 兼容)
w = torch.tensor(w_tests).float().repeat_interleave(len(c))
w = w[:, None, None, None].to(device) # 扩展维度,便于广播
# 初始化 x_t 为标准高斯噪声
x_t = torch.randn(n_samples, *input_size).to(device)
# 每个 w 对应一个类别
c = c.repeat(len(w_tests), 1)
# 扩大 batch 两倍(用于保留/丢弃类别)
c = c.repeat(2, 1)
# 在测试阶段不丢弃上下文
c_mask = torch.ones_like(c).to(device)
c_mask[n_samples:] = 0.0 # 后一半 batch 设置为 0(drop category)
# 存储用于生成动画的每一步图像
x_t_store = []
for i in range(0, T)[::-1]:
# 为每个样本复制时间步 t
t = torch.tensor([i]).to(device)
t = t.repeat(n_samples, 1, 1, 1)
# 扩大 batch 两倍(匹配 c)
x_t = x_t.repeat(2, 1, 1, 1)
t = t.repeat(2, 1, 1, 1)
# 使用模型预测噪声 e_t
e_t = model(x_t, t, c, c_mask)
# 提取保留类别信息的 e_t
e_t_keep_c = e_t[:n_samples]
# 提取丢弃类别信息的 e_t
e_t_drop_c = e_t[n_samples:]
# 计算加权噪声结果
e_t = (1 + w) * e_t_keep_c - w * e_t_drop_c
# 从批次中去除重复项
x_t = x_t[:n_samples]
t = t[:n_samples]
# 执行一次反向扩散步骤
x_t = ddpm.reverse_q(x_t, t, e_t)
# 保存用于动画的每一步图像
if i % store_freq == 0 or i == T or i < 10:
x_t_store.append(x_t)
# 将所有时间步图像堆叠为一个 tensor
x_t_store = torch.stack(x_t_store)
# 返回最终图像与动画帧序列
return x_t, x_t_store
这里我们用下面代码扩大batch两倍(用于保留/丢弃类别),然后喂给模型的是2倍batch:前一半保留类别信息,后一半类别掩码为0。所以e_t = model(x_t, t, c, c_mask)就得到了两倍的噪声预测。
# 扩大 batch 两倍(用于保留/丢弃类别)
c = c.repeat(2, 1)
c_mask[n_samples:] = 0.0 # 后一半不带类别
现在是时候看它的实际效果了,运行下面的代码来生成一组服装图像,并使用make_grid将它们排列为网格:
# 创建 10 个类别标签
c = torch.arange(N_CLASSES).to(device)
# 设置丢弃概率为 0,保留所有类别信息
c_drop_prob = 0
# 获取 one-hot 编码和掩码
c_hot, c_mask = get_context_mask(c, c_drop_prob)
# 输入图像的尺寸定义
input_size = (IMG_CH, IMG_SIZE, IMG_SIZE)
# 执行带加权反向扩散的采样
x_0, x_t_store = sample_w(model, input_size, T, c_hot)
# 将每个时间步的图像转为网格格式
grids = [other_utils.to_image(make_grid(x_t.cpu(), nrow=N_CLASSES)) for x_t in x_t_store]
# 保存为动画 GIF
other_utils.save_animation(grids, "04_images/fashionMNIST.gif")
结果如下:

每一行表示w值的变化范围:从 [-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0] 依次增加。前两行是负权重,意味着模型更强调图像的平均表现而不是类别信息。这时生成的图像有时会完全不同于原本指定的类别。而最后几行则能更一致地生成符合标签的图像。
4 TF Flowers数据集
现在我们已经掌握了FashionMNIST数据集,现在是时候迎接更大挑战了:彩色图像。我们将使用经过修改的TF Flowers数据集来完成这项挑战。

这些图像已经过轻微修改以适用于图像生成任务。例如,下面这张照片已经被裁剪以突出显示花朵本身。

由于引入了颜色这一额外维度,模型训练时间将大大延长。为了加快速度,我们可以将图像预加载到GPU上。如果我们在加载前先对其进行resize,就可以减少其占用空间。
- 这种技巧适用于较小的数据集,如果数据集过大则可能不可行(超过GPU显存)。
我们首先要定义一些数据集变量:
- 图像宽度与高度:
IMG_SIZE - 图像通道数:
IMG_CH - 批大小:
BATCH_SIZE - 生成图像的尺寸:
INPUT_SIZE
# 图像尺寸设置为 32x32 像素
IMG_SIZE = 32
# 通道数为 3(彩色图像)
IMG_CH = 3
# 每个批次包含的图像数量
BATCH_SIZE = 128
# 输入图像的维度(通道,高度,宽度)
INPUT_SIZE = (IMG_CH, IMG_SIZE, IMG_SIZE)
为了将图像存储到 GPU 中,我们会设置一个只在初始化数据集时运行一次的pre_transforms列表。之后,每次从数据集中提取图像时,将对每个批次应用random_transforms。Resize会将图像缩放到指定尺寸。
接着,我们可以使用RandomCrop使图像变为正方形,并通过随机增强扩充数据集。
# 导入 torchvision 和必要模块
import torchvision
from torch.utils.data import Dataset, DataLoader
# 初始化预处理操作:调整尺寸、转换为张量、归一化至 [-1, 1]
pre_transforms = transforms.Compose([
transforms.Resize(IMG_SIZE), # 缩放图像至指定尺寸
transforms.ToTensor(), # 将图像转换为张量,缩放到 [0,1]
transforms.Lambda(lambda t: (t * 2) - 1) # 线性变换至 [-1,1]
])
# 定义随机增强操作:随机裁剪、水平翻转
random_transforms = transforms.Compose([
transforms.RandomCrop(IMG_SIZE), # 随机裁剪为指定尺寸
transforms.RandomHorizontalFlip(), # 随机水平翻转图像
])
接下来我们来编写读取图像文件的函数。我们直接根据图像所在的父目录来判断其类别。我们总共有三个类别,定义在下面的DATA_LABELS中。

从左到右依次是:daisy(雏菊)、 sunflower(向日葵)、和rose(玫瑰)。我们可以使用glob函数来程序化地获取每张花朵图像的路径。
# 数据目录路径
DATA_DIR = "data/cropped_flowers/"
# 数据标签列表
DATA_LABELS = ["daisy", "sunflowers", "roses"]
# 类别数量
N_CLASSES = len(DATA_LABELS)
# 获取第一个类别的图像路径示例
data_paths = glob.glob(DATA_DIR + DATA_LABELS[0] + '/*.jpg', recursive=True)
data_paths[:5] # 显示前5个路径
输出如下:

我们可以使用 PyTorch 的Dataset工具来构建自定义数据集。__init__在类实例化时运行一次。__getitem__在获取每个样本时调用,返回图像和标签,并应用随机增强。
# 自定义数据集类
class MyDataset(Dataset):
def __init__(self):
self.imgs = [] # 存储预处理后的图像
self.labels = [] # 存储图像对应的标签
for l_idx, label in enumerate(DATA_LABELS): # 遍历每个类别
data_paths = glob.glob(DATA_DIR + label + '/*.jpg', recursive=True)
for path in data_paths:
img = Image.open(path) # 打开图像文件
self.imgs.append(pre_transforms(img).to(device)) # 应用预处理并转到GPU
self.labels.append(l_idx) # 存储标签索引
def __getitem__(self, idx):
img = random_transforms(self.imgs[idx]) # 应用随机增强
label = self.labels[idx] # 获取标签
return img, label # 返回图像和标签
def __len__(self):
return len(self.imgs) # 返回数据集长度
# 创建数据集实例
train_data = MyDataset()
# 创建数据加载器
dataloader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
现在初始化我们的U-Net。结构与之前相同,但 T和down_chs更大。
T:因为彩色图像的细节更丰富、结构更复杂,需要更细致的去噪过程来逐步还原真实图像。down_chs:彩色图像具有更高的维度(3通道 + 更多纹理/色彩),所以需要更强的编码/解码能力,即更宽的网络。
# 时间步数
T = 400
# 噪声调度起始和终止值
B_start = 0.0001
B_end = 0.02
# 创建线性噪声调度表
B = torch.linspace(B_start, B_end, T).to(device)
# 初始化 DDPM 模型
ddpm = ddpm_utils.DDPM(B, device)
# 初始化 U-Net 模型
model_flowers = UNet_utils.UNet(
T, IMG_CH, IMG_SIZE, down_chs=(256, 256, 512), t_embed_dim=8, c_embed_dim=N_CLASSES
)
print("Num params: ", sum(p.numel() for p in model_flowers.parameters())) # 输出44509443
# 编译模型以加速运行
model_flowers = torch.compile(model_flowers.to(device))
下面定义一个采样函数,用于在训练过程中生成图像。
# 采样函数,生成花朵图像
def sample_flowers(n_classes):
c_test = torch.arange(n_classes).to(device) # 创建类别张量
c_hot_test, c_mask_test = get_context_mask(c_test, 0) # 生成类别掩码
x_gen, x_gen_store = sample_w(model_flowers, INPUT_SIZE, T, c_hot_test) # 调用采样函数
return x_gen, x_gen_store
下面是我们的训练循环,我们把它封装函数形式。
# 模型训练函数
def train_flowers(dataloader, epochs=100, n_classes=N_CLASSES, c_drop_prob=0.1, save_dir = "04_images/"):
lrate = 1e-4 # 学习率
optimizer = torch.optim.Adam(model_flowers.parameters(), lr=lrate) # 优化器
c = torch.arange(n_classes).to(device)
c_hot_test, c_mask_test = get_context_mask(c, 0)
model_flowers.train() # 设置模型为训练模式
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
t = torch.randint(0, T, (BATCH_SIZE,), device=device).float() # 随机时间步
x = batch[0].to(device) # 输入图像
c_hot, c_mask = get_context_mask(batch[1], c_drop_prob) # 生成上下文
loss = ddpm.get_loss(model_flowers, x, t, c_hot, c_mask) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
print(f"Epoch {epoch} | Step {step:03d} | Loss: {loss.item()}") # 打印训练信息
if epoch % 5 == 0 or epoch == int(epochs - 1): # 每5轮或最后一轮保存图像
x_gen, x_gen_store = sample_flowers(n_classes)
grid = make_grid(x_gen.cpu(), nrow=n_classes)
save_image(grid, save_dir + f"image_ep{epoch:02}.png")
print("saved images in " + save_dir + f" for episode {epoch}")
现在让我们看看扩散模型如何处理彩色图像。模型在第50轮已可生成可识别的图像,在第100轮效果最佳。
# 启动训练
train_flowers(dataloader)
第100轮的图像如下:

由于扩散模型具有随机性,一些生成的图像可能比其他图像效果更好。可以多次采样直到得到满意结果。之后我们还可以将其制作成动画。
# 评估并生成图像
model.eval()
x_gen, x_gen_store = sample_flowers(N_CLASSES)
grid = make_grid(x_gen.cpu(), nrow=N_CLASSES)
other_utils.show_tensor_image([grid])
plt.show()
输出:

# 保存为 GIF 动画
grids = [other_utils.to_image(make_grid(x_gen.cpu(), nrow=N_CLASSES)) for x_gen in x_gen_store]
other_utils.save_animation(grids, "images/flowers.gif")
输出:

训练十几分钟就能生成这些图像,还是相当不错的!
5 总结
本篇文章介绍了如何基于FashionMNIST和TF Flowers构建一个支持类别控制的条件扩散模型。通过在U-Net中引入类别嵌入和伯努利掩码,实现了无监督与有监督的统一训练,同时利用Classifier-Free Guidance提升图像生成质量和类别一致性。最终,模型成功在彩色图像上生成了清晰、多样的类别特定图像,为后续文本生成图像打下基础。
在下一篇文章中,我们将构建完整的文本生成图像(text-to-image)流程来进一步提升生成效果…


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











