



定义
- CVLM:使用Contrastive Learning的大语言模型
- GVLM:使用Generative loss的大语言模型
CVLM表现得更像Bags of words,忽略了顺序和语义信息
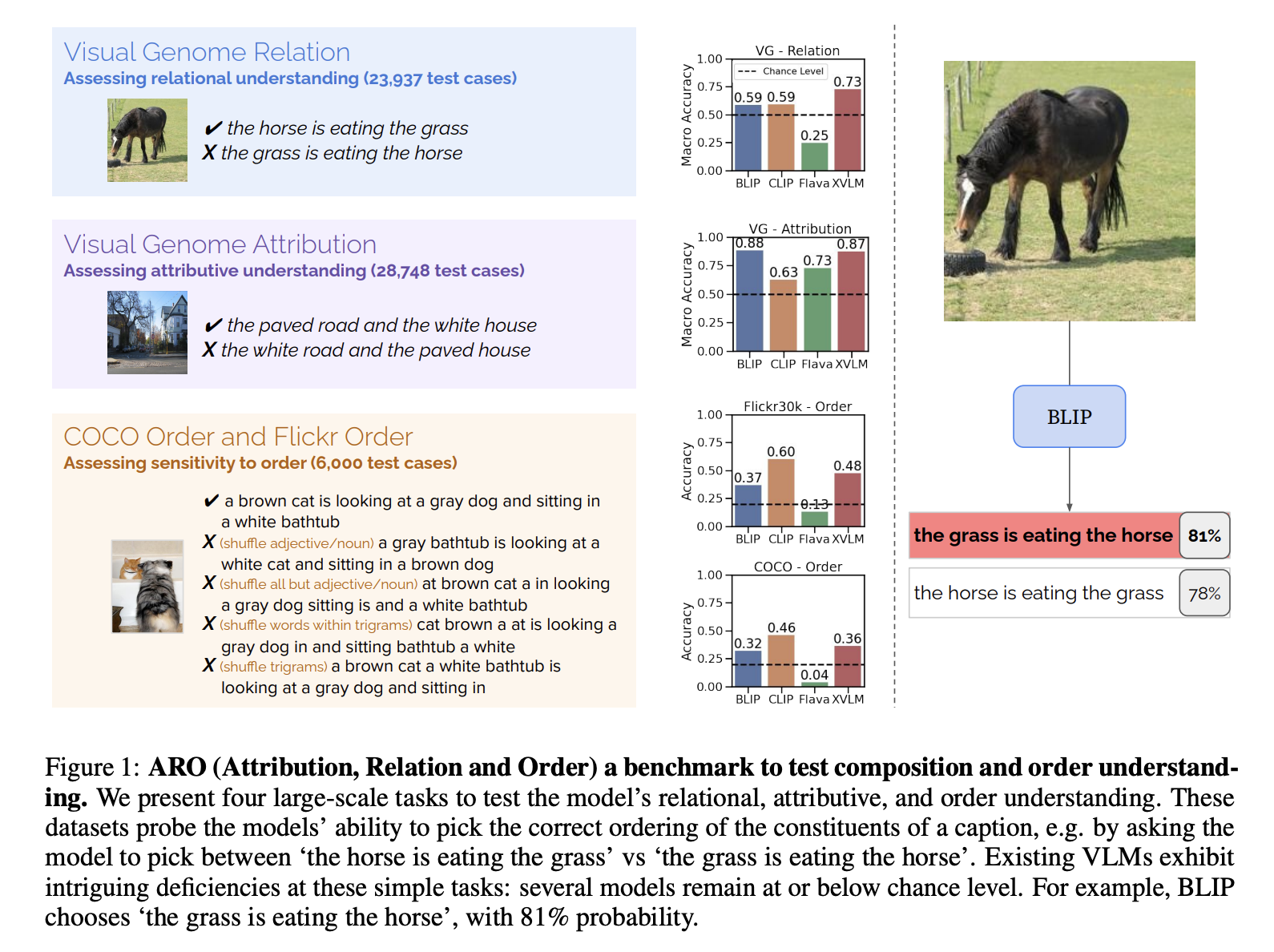
上图来自于论文WHEN AND WHY VISION-LANGUAGE MODELS BEHAVE LIKE BAGS-OF-WORDS, AND WHAT TO DO
ABOUT IT? 文中给的一种比较简单的修复方法是hard negative sample
GVLM更偏向于语法纠错而不是语义理解(这个领域叫做compositional learning)

上图来自于An Examination of the Compositionality of Large Generative Vision-Language Models,GVLM里定义了VisualGPTScore,发现一些幻觉的例子
Capca(来自于Image Captioners Are Scalable Vision Learners Too)
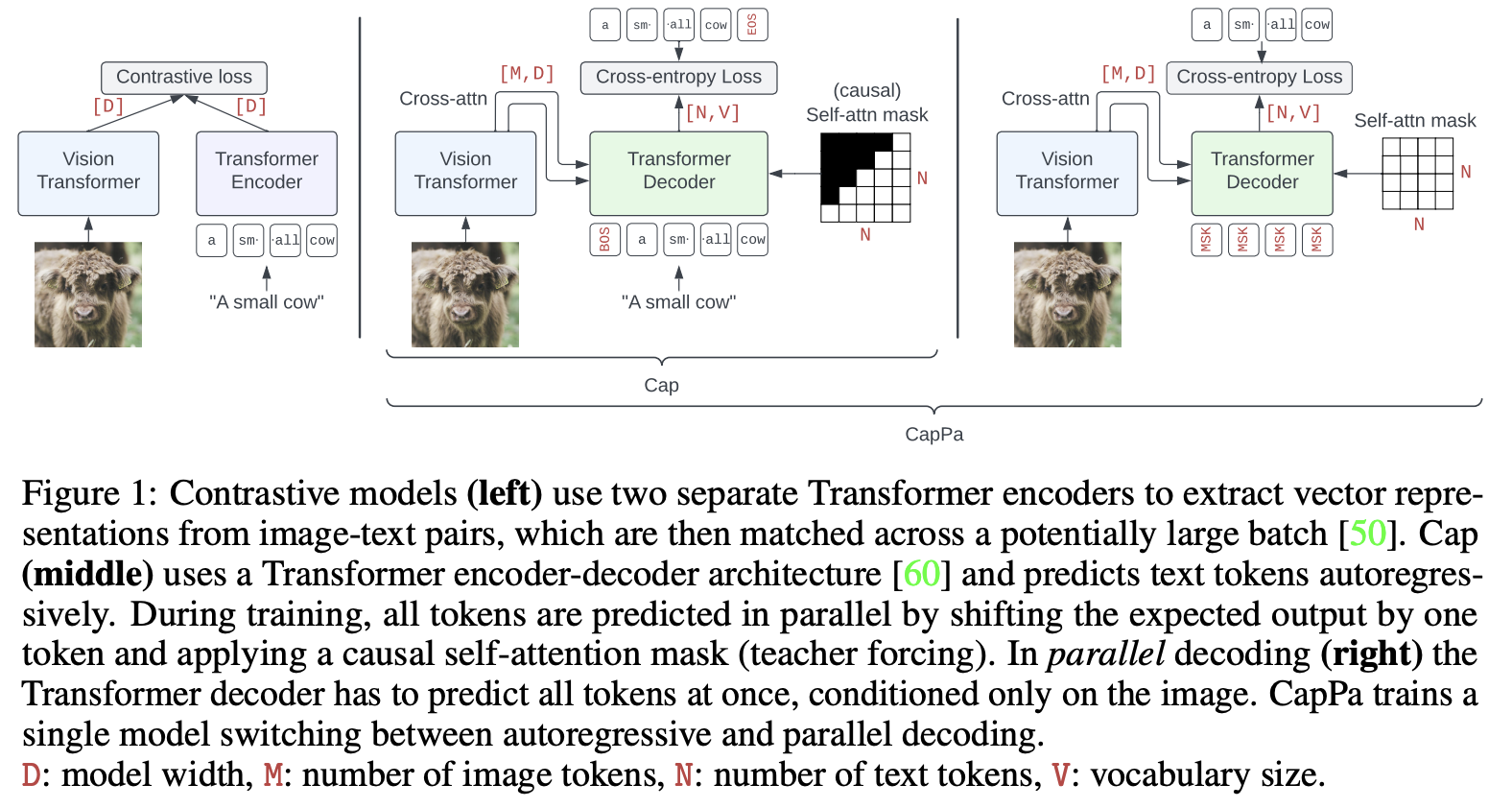
这个改进是用把image caption一个个token输出变成了parallel decoding,这种相比GVLM一个token一个token输出方式只condition了输入的图片而不是之前的文本tokens,一定程度缓解了幻觉的问题
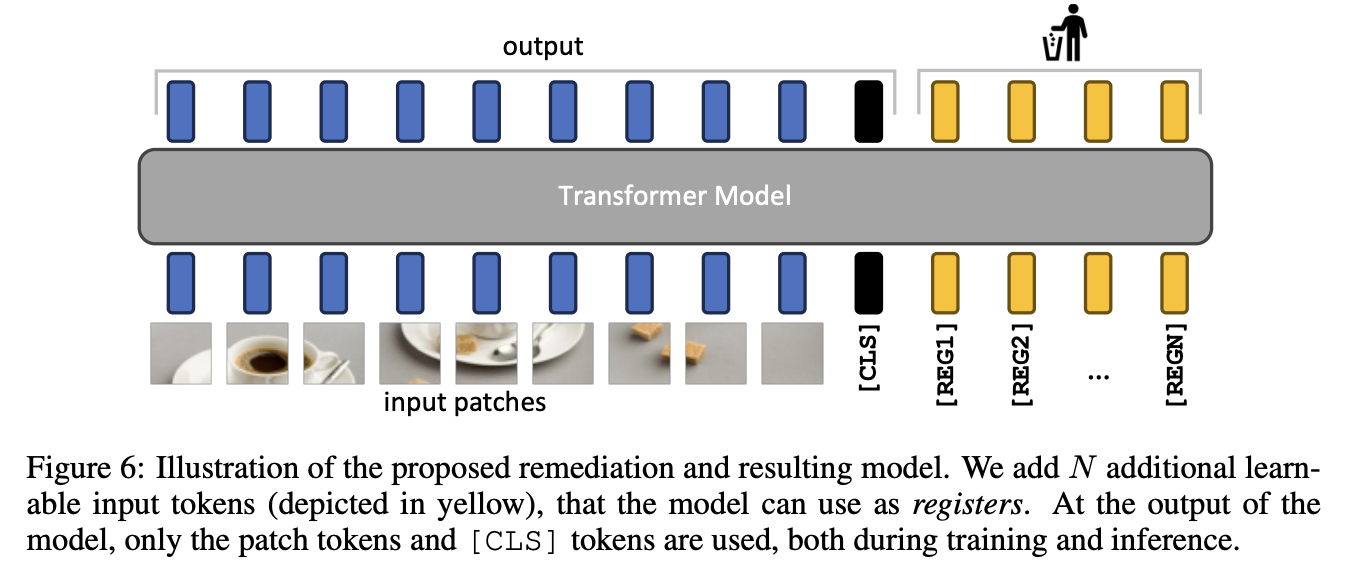
Visual Registers
来自于VISION TRANSFORMERS NEED REGISTERS这篇论文,其实就是加一些类似CLS的额外token来吸收幻觉:
CLIP的缺点(来自Deepseek的总结)
OpenAI的CLIP模型尽管在多模态任务中表现卓越,但仍存在以下主要缺点:
1. 数据质量与偏见问题
- 训练数据噪声:CLIP依赖互联网爬取的4亿图像-文本对,可能存在不准确描述或噪声,导致模型学习到错误的映射关系(例如将“狗”错误关联到无关背景)。
- 社会偏见:未经清洗的数据可能携带性别、种族等社会偏见,例如某些职业与特定性别的错误关联。
- 数据利用效率低:训练时需重复使用大规模数据(4亿样本经过32个epoch,相当于128亿次训练),计算资源消耗巨大。
2. 泛化能力受限
- 分布外(OOD)数据表现差:对与训练数据差异大的场景(如手写数字MNIST)泛化能力显著下降,准确率仅为88%,远低于传统分类器。
- 依赖背景假相关性:模型易受训练数据中背景与对象的虚假关联影响。例如,北极熊在雪地背景中准确率高达97.62%,但在草地背景中骤降至70.91%。
- 复杂任务表现不佳:在需要抽象推理或逻辑的任务(如计数、异常检测)中表现较差,难以理解“异常”等复杂概念。
3. 零样本与少样本学习的局限性
- Zero-Shot依赖文本提示:分类结果受文本模板设计影响,需人工优化提示词(Prompt Engineering)以提升效果,灵活性受限。
- Few-Shot性能反降:在提供少量样本时,模型表现可能不如Zero-Shot,与人类学习模式差异显著。
4. 生成能力不足
- 无法直接生成描述:CLIP仅支持图像与文本的对比匹配,无法直接生成图像标题,需结合生成式模型(如GPT)实现该功能。
总结与改进方向
CLIP的局限性主要集中在数据质量、泛化能力、计算效率及任务适应性上。未来研究可通过以下方向改进:
- 数据清洗与增强:减少噪声和偏见,引入合成数据或自监督学习提升数据效率。
- 混合训练目标:结合对比学习与生成式目标,增强复杂任务处理能力。
- 轻量化部署:优化模型架构(如剪枝、量化)或采用硬件加速技术提升推理速度。
如需更详细的技术分析或具体应用案例,可参考相关研究论文或开源项目实现。

















 3226
3226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









