



在刷官方Tutorial的时候发现了一个用法self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size)),看了官方教程里面的解释也是云里雾里,于是在栈溢网看到了一篇解释,并做了几个实验才算完全理解了这个函数。首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
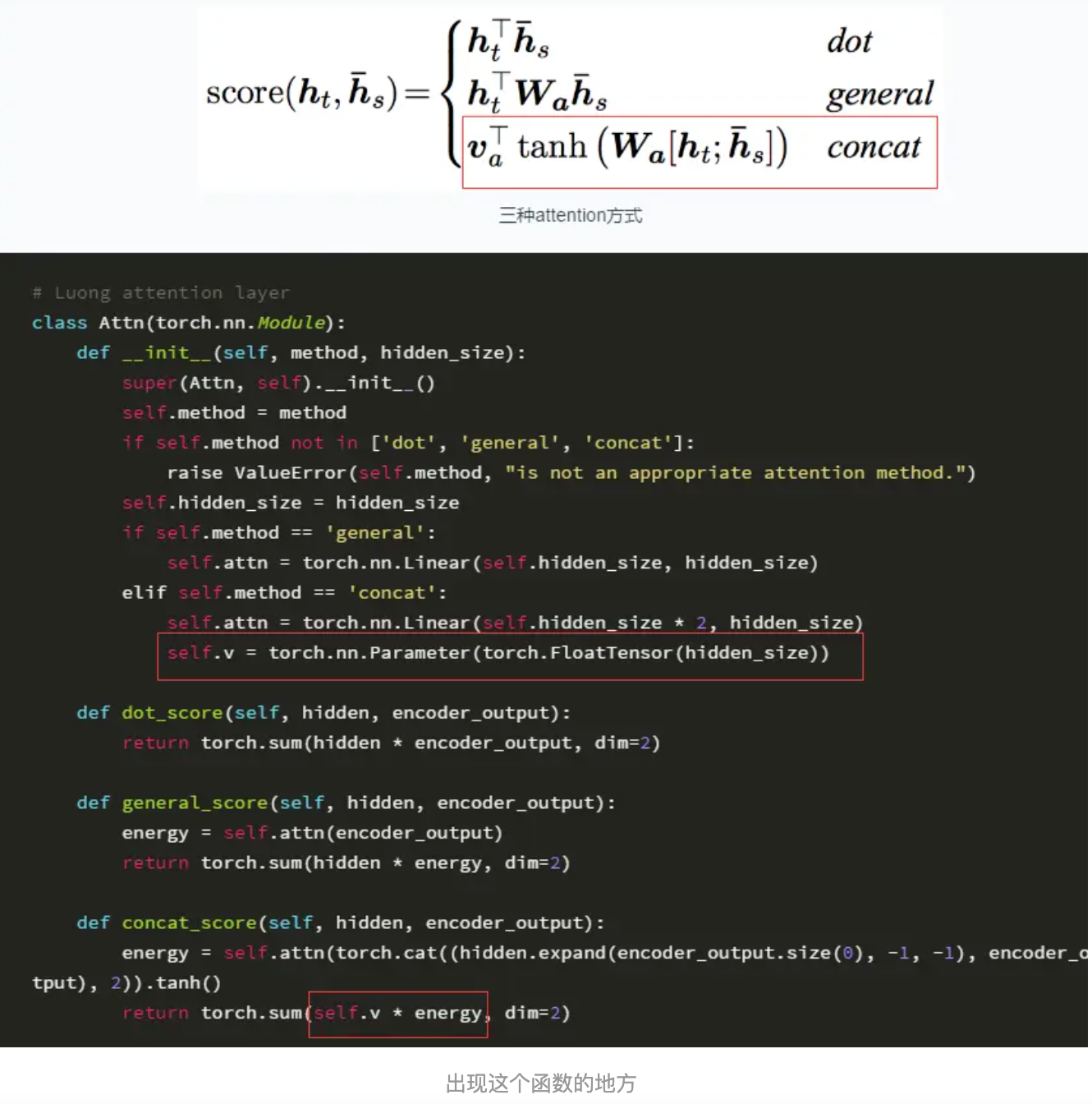
在concat注意力机制中,权值V是不断学习的所以要是parameter类型。
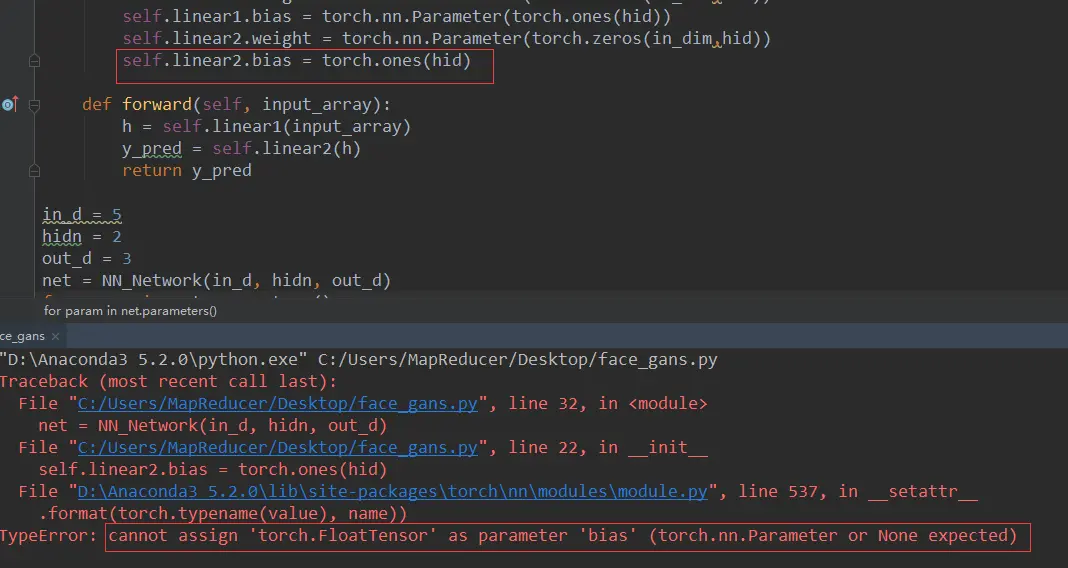
通过做下面的实验发现,linear里面的weight和bias就是parameter类型,且不能够使用tensor类型替换,还有linear里面的weight甚至可能通过指定一个不同于初始化时候的形状进行模型的更改。
做的实验
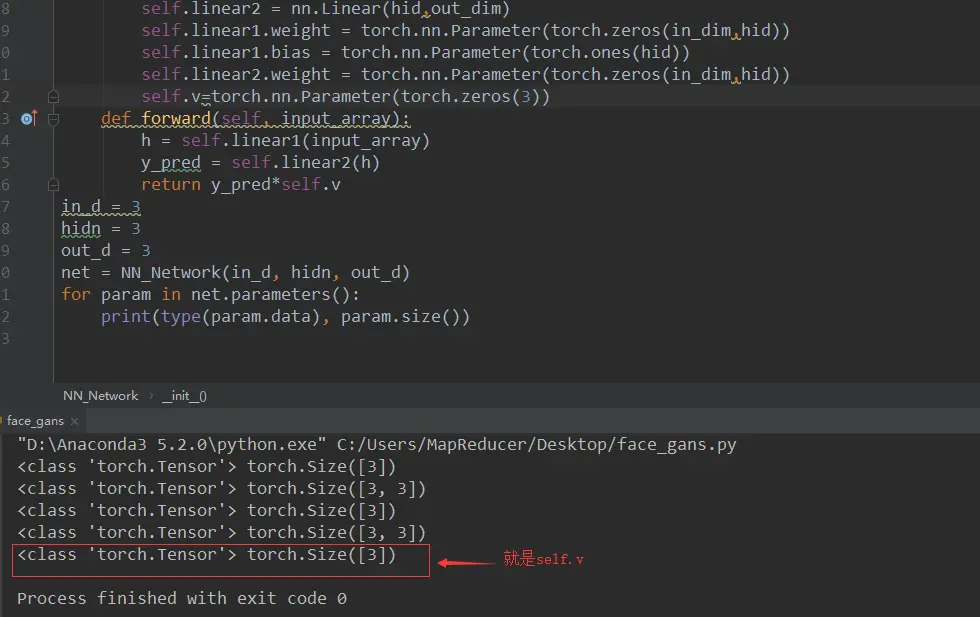
self.v被绑定到模型中了,所以可以在训练的时候优化
与torch.tensor([1,2,3],requires_grad=True)的区别,这个只是将参数变成可训练的,并没有绑定在module的parameter列表中。
作者:VanJordan
链接:https://www.jianshu.com/p/d8b77cc02410
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









