







一、引言
RAG(检索增强生成)通过结合检索与生成技术,依赖其高效检索算法、多模态融合能力及系统级优化,解决了基础大模型在企业内部应用的局限性。
例如,通过RAG技术对接企业内部知识库,支持知识动态更新与实时交互,显著降低了大模型的幻觉风险,无需微调训练模型,低成本适配企业垂直领域的应用场景,在数据安全与可控性方面,可加入权限控制逻辑,确保敏感信息仅在授权范围内使用,同时通过引用标注实现可追溯性。
RAG 是将附加文档存储为嵌入向量,将传入的查询计算向量与这些向量进行匹配,并将最相似的信息与查询一起提供给LLM的过程。在此过程中分块策略是RAG系统的核心环节,不同的分块质量、不同的分块策略,直接影响知识检索效率与LLM生成质量。
回顾一下RAG的基本工作流程:
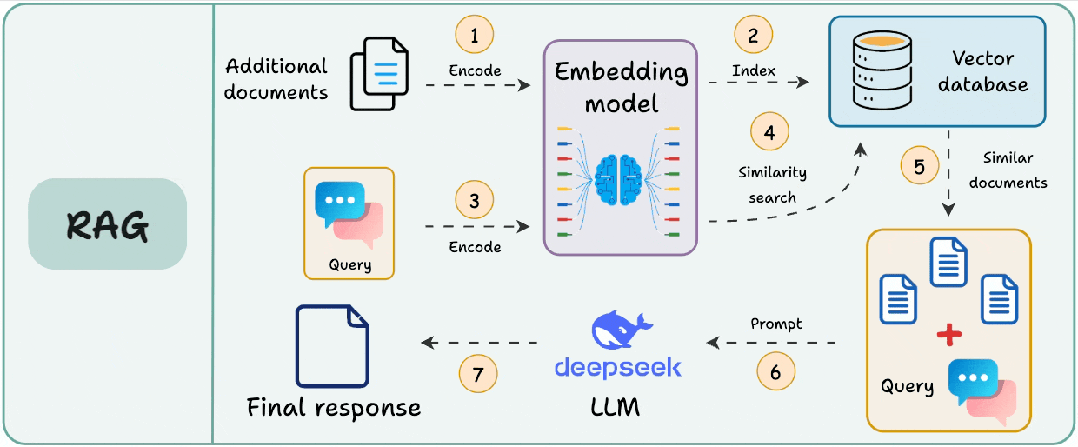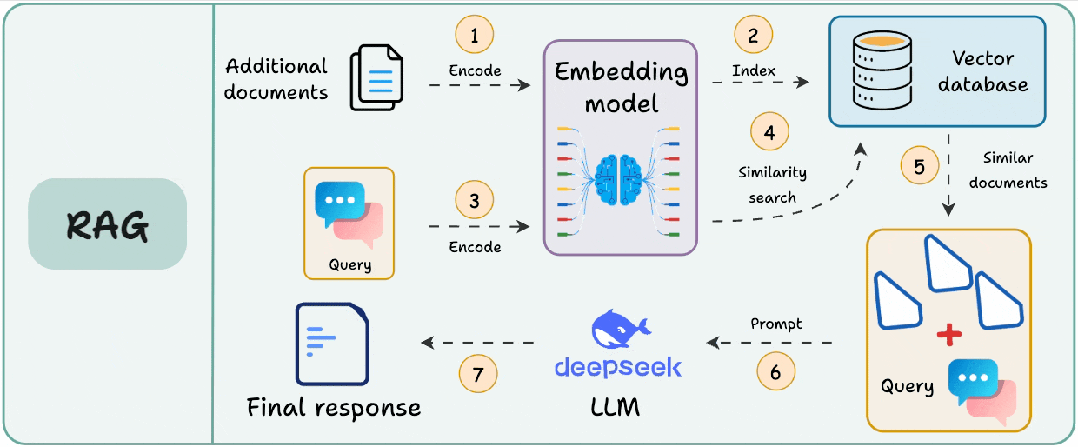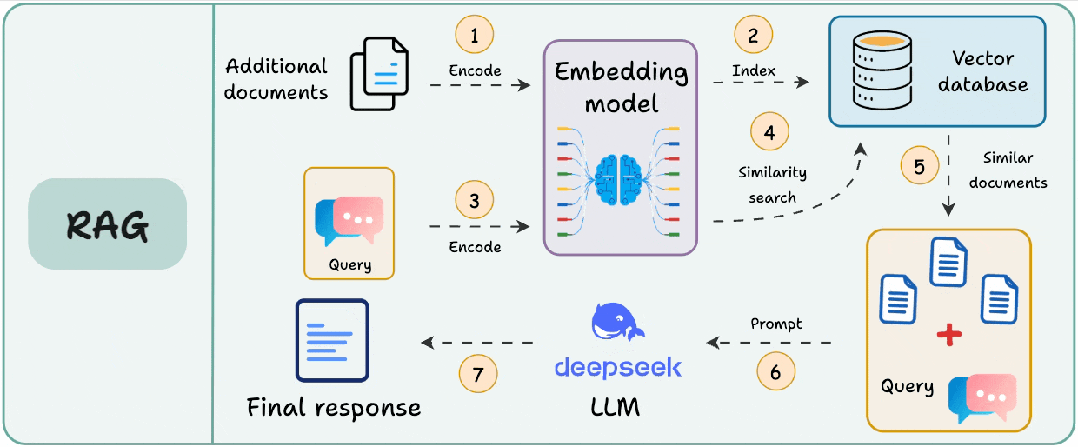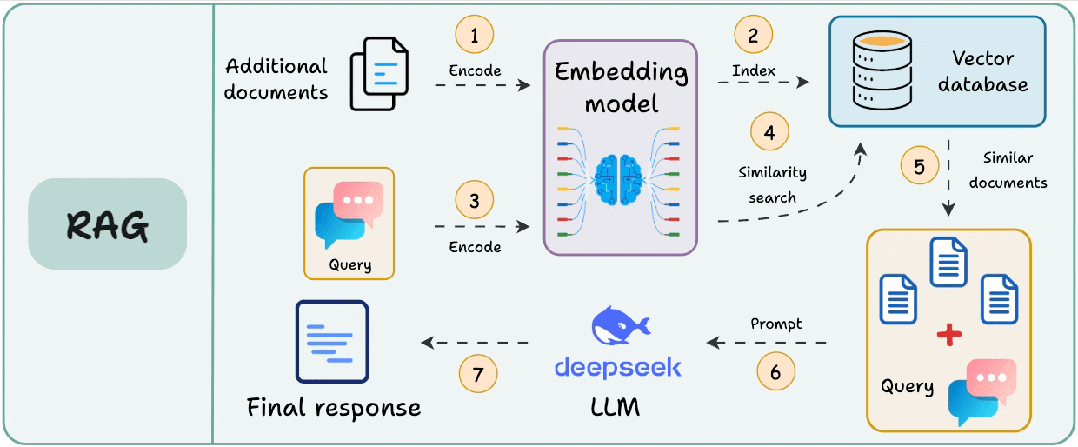
有时候文档可能很大,或者结构很复杂,在步骤①中需要对文档进行分块处理,将大文档分成较小单位/可管理的部分,以确保文本适合嵌入模型的输入大小。
如果采用了不恰当的分块策略,可能导致我们最终应用RAG的效果达不到预期,面临答案可信度不足、关键信息漏检、复杂文档提取瓶颈等问题。 这些问题直接影响RAG系统的可靠性和实用性。
二、RAG分块应用中普遍存在的问题
1. 准确性:答案可信度不足
-
幻觉问题
即使检索到相关文档,大模型仍可能脱离文档内容编造答案(尤其在文档信息模糊或矛盾时)。例如如:用户问“某基金近3年收益率”,模型可能捏造数据而非引用检索到的报告。 -
检索噪声干扰
相似度搜索返回的文档片段可能包含无关信息,导致模型生成答案时被误导。例如:检索到10篇文档,其中3篇主题相关但含错误数据,模型可能融合错误信息。 -
细粒度理解缺失
模型难以精准理解数字、日期、专业术语的上下文含义,导致关键信息误用。例如:将“预计2025年增长10%”误解为历史数据。
2. 召回率:关键信息漏检
-
语义匹配局限
传统向量搜索依赖语义相似度,但用户问题与文档表述差异大时漏检(如术语vs口语)。例如:用户问“钱放货币基金安全吗?”可能漏检标题为“货币市场基金信用风险分析”的文档。 -
长尾知识覆盖不足
低频、冷门知识因嵌入表示不充分,在向量空间中难以被检索到。例如:某小众金融衍生品的风险说明文档未被召回。 -
多跳推理失效
需组合多个文档片段才能回答的问题(如因果链),单次检索难以关联分散的知识点。例如:“美联储加息如何影响A股消费板块?”需先检索加息机制,再关联A股消费板块。
3. 复杂文档解析:信息提取瓶颈
-
非结构化数据处理
- 表格/图表:文本分块会破坏表格结构,导致行列关系丢失(如财报中的利润表)。
- 公式/代码:数学公式或程序代码被错误分段,语义完整性受损。
- 扫描件/图片:OCR识别错误率高,尤其对手写体或模糊文档。
-
上下文割裂问题
固定长度分块(如512字符)可能切断关键上下文:
分块1结尾:“…风险因素包括:”
分块2开头:“利率波动、信用违约…” → 模型无法关联分块1的提示语。 -
文档逻辑结构丢失
标准分块策略忽略章节、段落、标题的层级关系,影响知识图谱构建。例如:将“附录”中的备注误认为正文结论。
三、RAG实现的核心瓶颈分块技术
在构建高可用RAG系统时,其标准工作流包含三个关键阶段:
- 知识库构建:将文档分割为语义块 → 生成向量嵌入 → 存储至向量数据库
- 实时检索:将用户查询向量化 → 检索Top-K相关文本块
- 生成响应:将检索结果与查询拼接 → 输入LLM生成最终答案
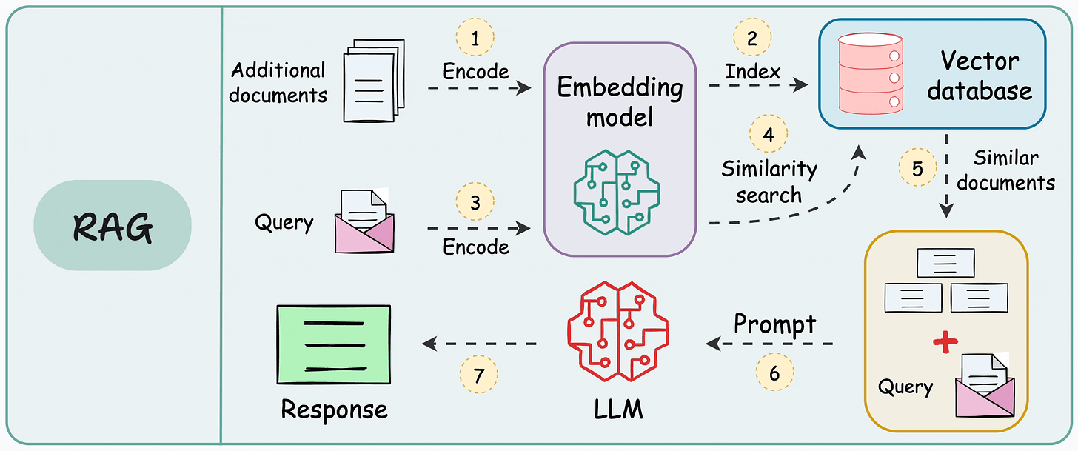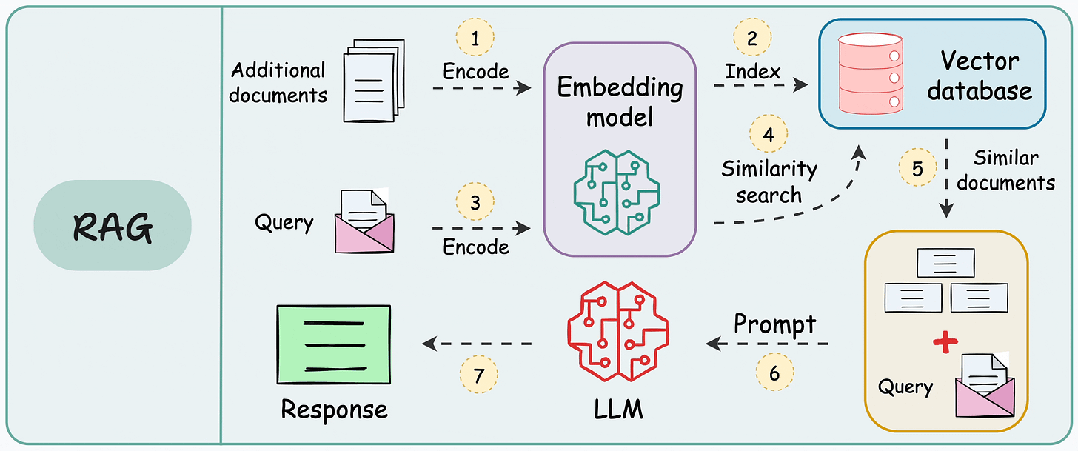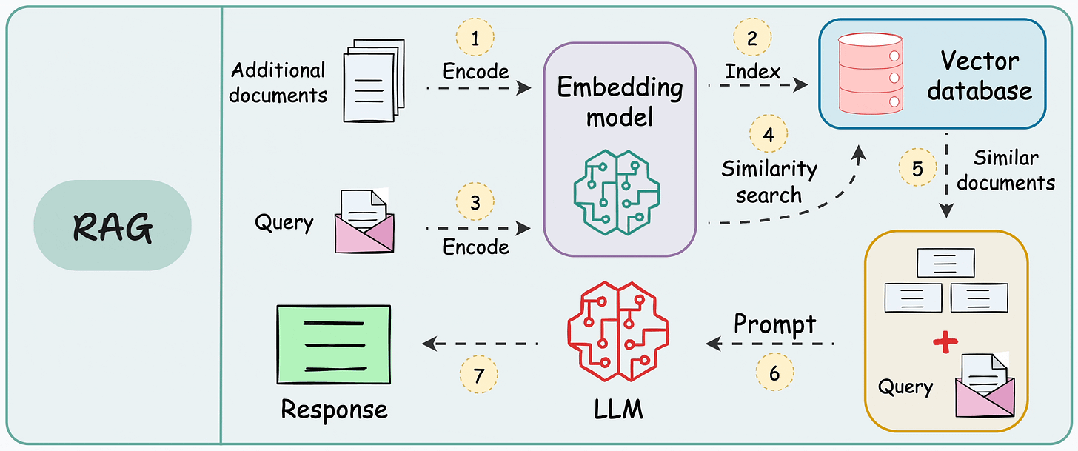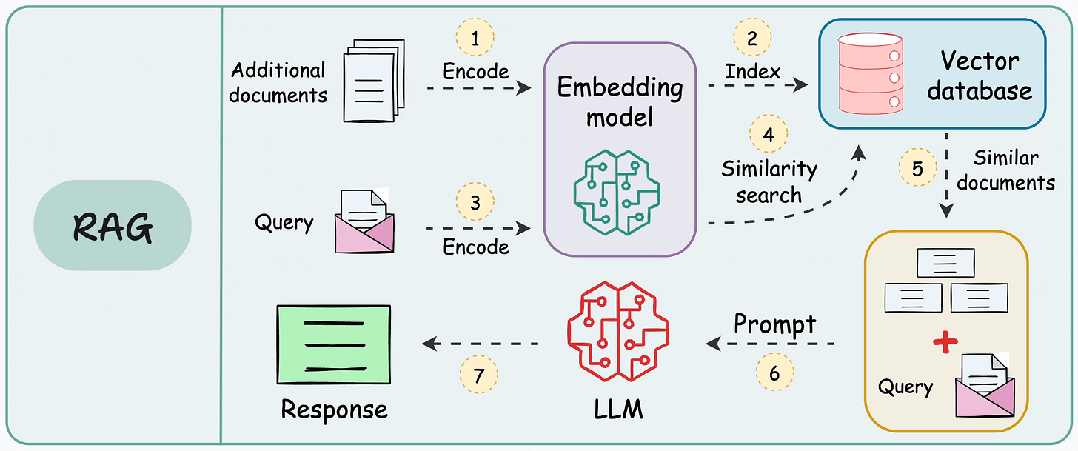
由于附加文档可能非常大,因此步骤 1 还涉及分块,其中将大文档分成较小/易于管理的部分。
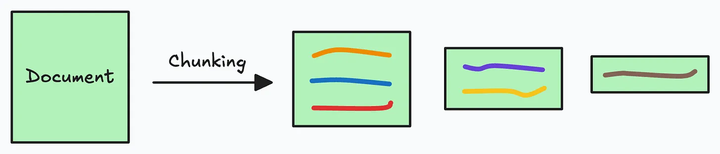
此外,它提高了检索步骤的效率和准确性,这直接影响生成的响应的质量。接下来,我们就深入探讨RAG 的几大分块策略
四、深度剖析五种分块策略
最常见的RAG分块策略包括:固定大小分块、语义分块、递归分块、基于文档结构的分块、基于LLM的分块。
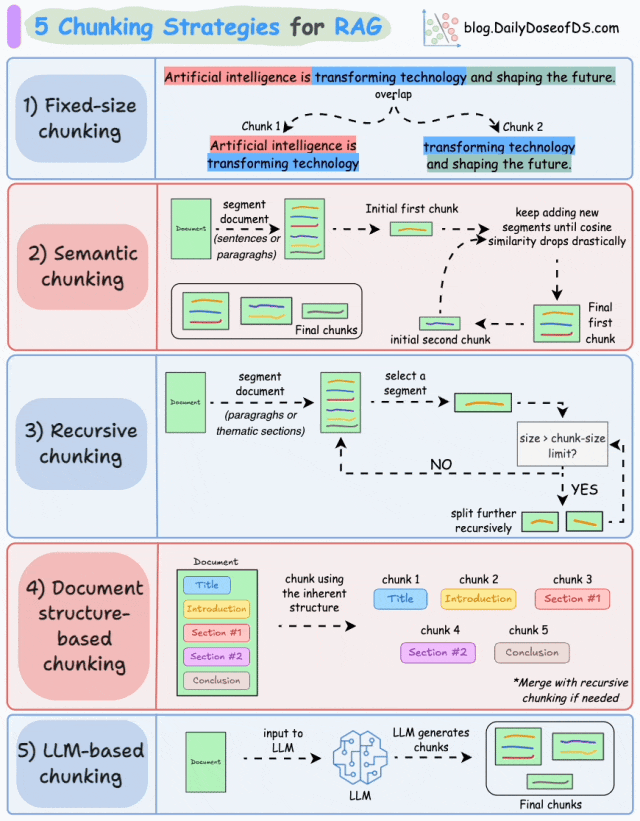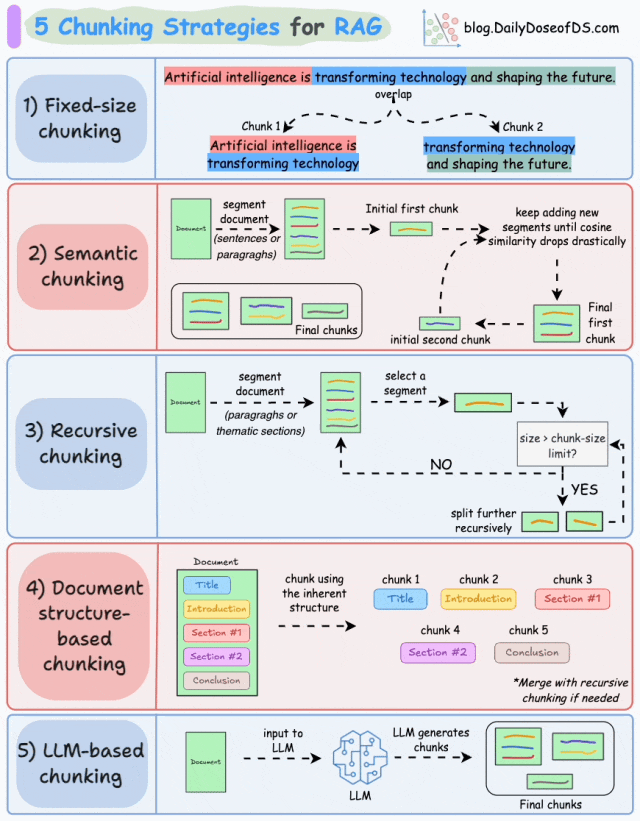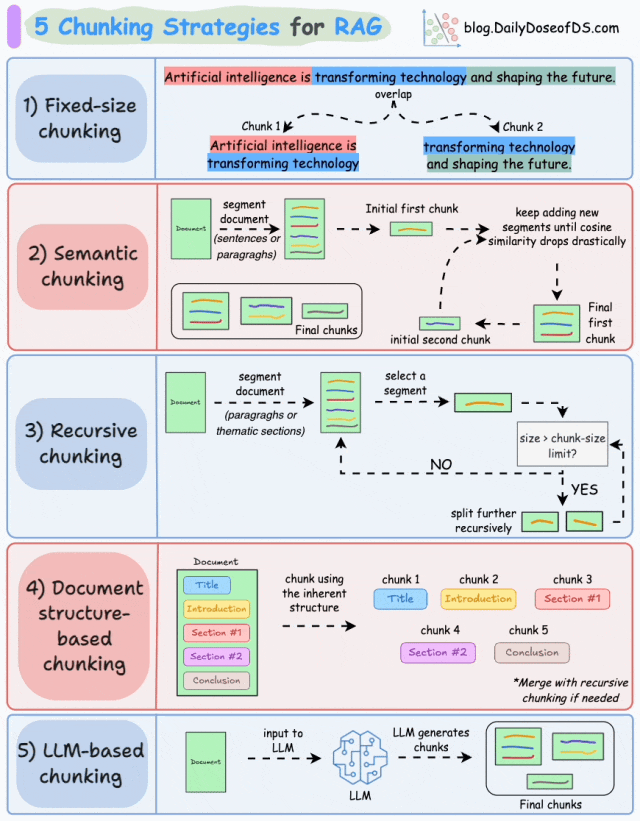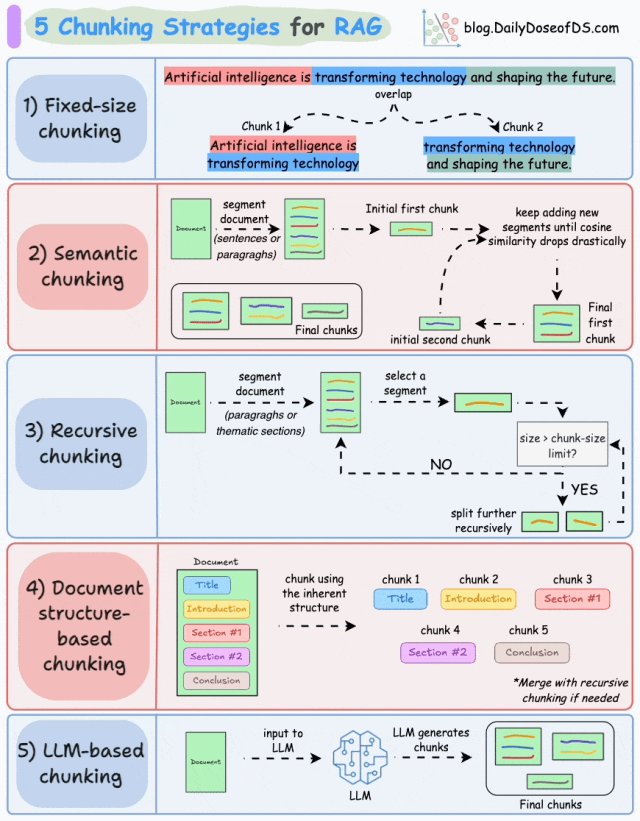
策略1:固定尺寸分块(Fixed-size Chunking)
基本原理:将文本按固定长度(如字符数、单词数或token数)切分,每个块大小一致,可能通过重叠保留上下文连贯性。例如,将文档每256个字符切分为一个块,重叠20个字符以减少边界信息丢失。
实现步骤:
- 预设参数:定义块大小(如256 token)和重叠比例(如20 token)。
- 切分文本:按固定长度分割文本,允许相邻块部分重叠。
- 生成块列表:输出所有块作为独立单元。
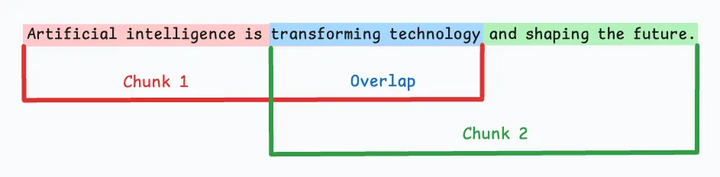
如图,由于直接分割会破坏语义流,因此建议在两个连续的块之间保持一些重叠(上图蓝色部分)。这很容易实现。而且,由于所有块的大小相同,它简化了批处理。
但有一个大问题。这通常会打断句子(或想法)。因此,重要的信息很可能会分散到不同的块中。
主要优点:
- 实现简单:无需复杂算法,代码实现高效。
- 标准化处理:块大小一致,便于批量处理和向量化。
- 资源友好:适合大规模文本处理,降低计算成本。
主要缺点:
- 语义断裂:可能在句子或概念中间切分,破坏上下文完整性。
- 信息冗余:重叠区域可能导致重复存储和计算。
- 适用性受限:对结构化文本(如代码、技术文档)效果较差。
适用场景:
- 非结构化文本(如新闻、博客)的初步处理。
- 对实时性要求高、需快速切分的场景。
代码示例:
# LangChain实现示例
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=50, # 关键重叠区
separator="\n"
)
chunks = splitter.split_documents(docs)
策略2:语义分块(Semantic Chunking)
基本原理:根据句子、段落、主题等有语义内涵的单位对文档进行分段创建嵌入,如果第一个段的嵌入与第二个段的嵌入具有较高的余弦相似度,则这两个段形成一个块。通过合并相似内容,确保每个块表达完整的语义内容。
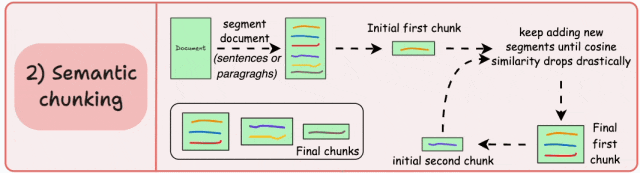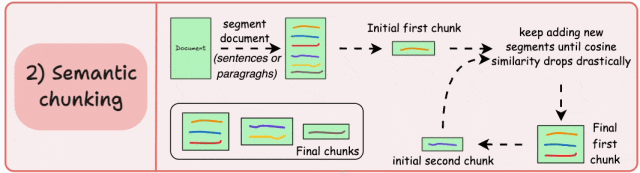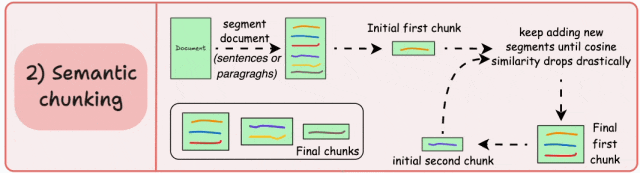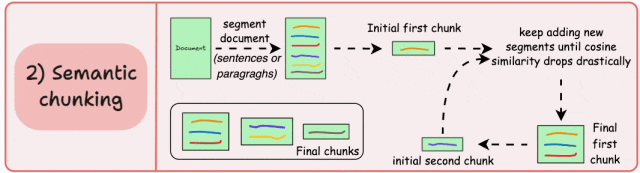
由于每个分块的内容更加丰富,它提高了检索准确性,让大模型产生更加连续和相关的响应。但是它依赖于一个阈值来确定余弦相似度是否显著下降,而这个阈值在不同类型文档中可能涉及不同的参数设置。
输出可能如下所示:
实现步骤:
- 分句/分段:将文本拆分为句子或段落。
- 生成嵌入:为每个单元计算向量表示。
- 相似度计算:依次比较相邻单元的余弦相似度。
- 动态合并:当相似度高于阈值时合并单元;相似度骤降时开始新块。
主要优点:
- 语义完整性:保留自然语义结构,提升检索准确性。
- 上下文敏感:适应复杂逻辑关系(如因果、对比)。
- 生成质量:检索到的块更连贯,利于LLM生成精准回答。
主要缺点:
- 计算复杂度高:需多次向量化计算和相似度比较。
- 阈值依赖:相似度阈值需人工调试,不同文档需不同参数。
- 实现门槛:依赖高质量嵌入模型和相似度算法。
适用场景:
- 高精度问答系统(如法律、医疗领域),研究论文、行业分析报告等专业文档。
- 需保留上下文逻辑的复杂文档(如论文、技术报告)。
代码示例:
# 基于SBERT的语义边界检测
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
def semantic_chunking(sentences, threshold=0.85):
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
emb1 = model.encode(current_chunk[-1])
emb2 = model.encode(sentences[i])
sim = cosine_similarity(emb1, emb2)
if sim > threshold:
current_chunk.append(sentences[i])
else:
chunks.append(" ".join(current_chunk))
current_chunk = [sentences[i]]
return chunks
策略3:递归分块(Recursive Chunking)
基本原理:先按主题或段落初步划分,再对超长块递归细分,直至满足大小限制。递归分块融合了结构化与非结构化处理逻辑,与固定大小的分块不同,这种方法保持了语言的自然流畅性并保留了完整的内容语义。在实施和计算复杂性方面存在一些额外的消耗。
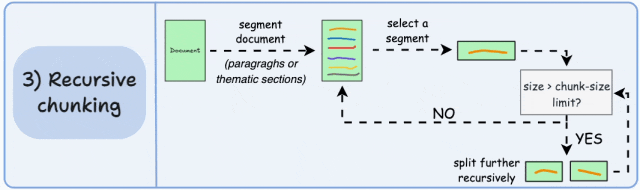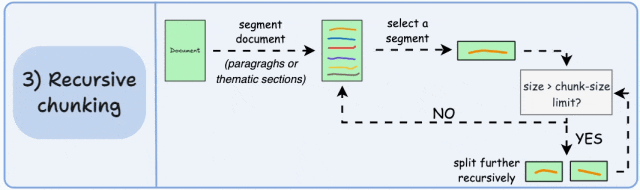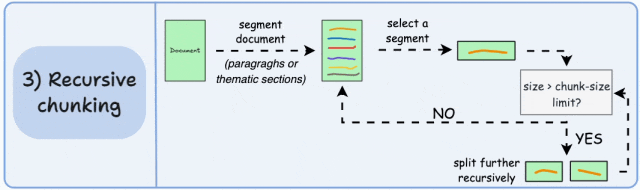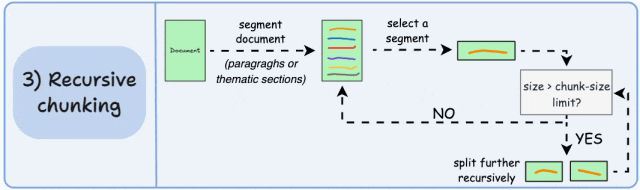
如图,首先,根据固有分隔符(如段落或章节)进行分块,定义两个块(紫色的两个段落)。接下来,第 1 段被进一步分成更小的块。如果每个块的大小超出了预定义的块大小限制,则将其拆分成更小的块。但是,如果块符合块大小限制,则不再进行进一步拆分。

实现步骤:
- 粗粒度切分:按段落、标题或主题初步划分大块。
- 检查大小:判断块是否超过预设长度(如1024 token)。
- 递归细分:超长,按固定大小或语义逻辑进一步切分。
- 终止条件:块大小符合要求时停止递归。
主要优点:
- 灵活性强:平衡结构完整性与大小限制。
- 适应复杂内容:处理长文档(如书籍、长篇论文)时表现优异。
- 多策略融合:可结合固定大小或语义分块优化细分。
主要缺点:
- 块大小不均:不同层级的块可能差异较大。
- 逻辑断裂风险:递归过程中可能破坏原文的自然段落结构。
- 实现复杂:需设计递归终止条件和分块策略。
适用场景:
- 长文档处理(如企业年报、学术论文),书籍、技术手册等层级化文档。
- 需兼顾结构化与非结构化内容的场景,包含嵌套结构的合同文本。
策略4:文档结构分块(Document Structure-based Chunking)
基本原理:利用文档固有结构(如标题<h1>、章节、列表<ul>、表格<table>)进行切分,每个结构单元作为一个块。它通过与文档的逻辑部分对齐来保持结构完整性。
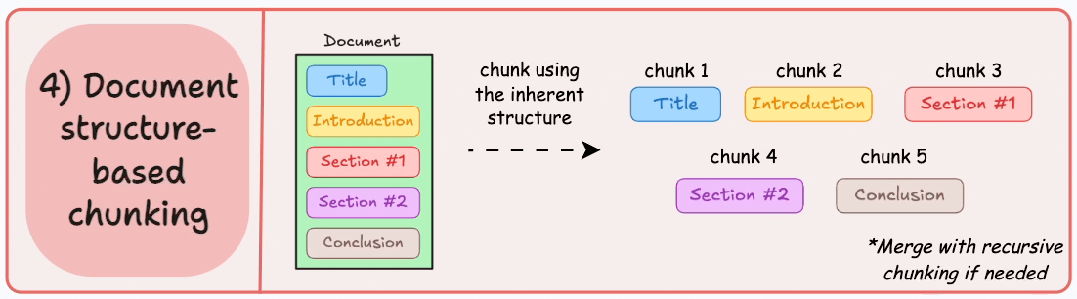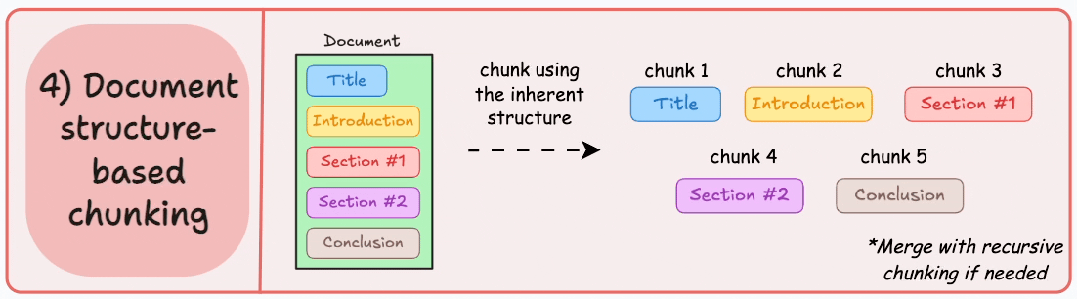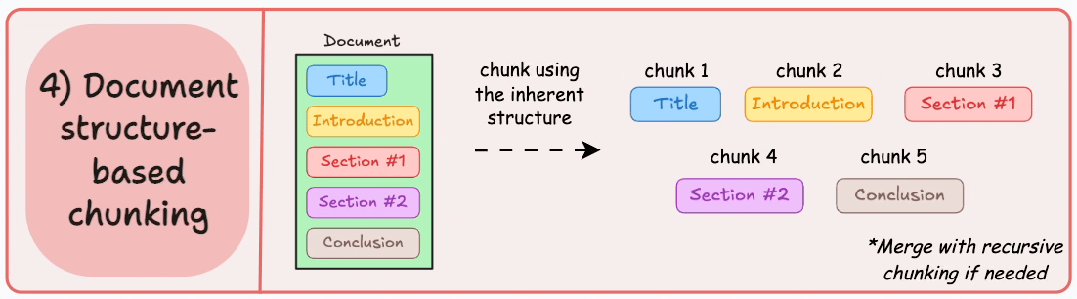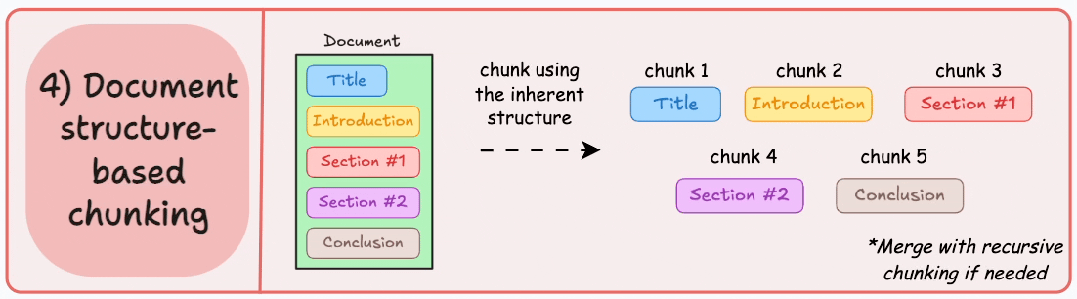
这种分块适用于文档有清晰的结构,但很多时候,一个文档的结构会比想象中复杂,此外,很多时候文档章节内容大小不一,很容易超过块的大小限制,需要结合递归拆分再进行合并处理。

也就是说,这种方法假设文档具有清晰的结构,但事实可能并非如此。
实现步骤:
- 识别结构元素:解析文档中的标题、段落、小节等标记(如Markdown、XML)。
- 按结构切分:将每个结构单元(如“引言”、“结论”)独立为块。
- 处理超长部分:若某结构单元过大,再结合递归或固定大小分块细化。
主要优点:
- 逻辑清晰:保留文档的层次化结构,便于定位信息。
- 检索高效:用户可通过标题快速定位相关内容。
- 格式兼容性:适合结构化文档(如技术手册、报告)。
主要缺点:
- 依赖格式标准化:对非结构化文本(如自由写作)效果差。
- 预处理复杂:需解析文档格式(如LaTeX、HTML),增加实现难度。
- 灵活性不足:难以处理混合结构内容(如图文混排)。
适用场景:
- 结构化文档,如:财报(表格数据)、技术文档(代码块)、合同(条款列表)。
- 需按章节检索的场景(如法规数据库),任何含丰富格式标记的内容。
代码示例:
# 基于BeautifulSoup的HTML结构解析
from bs4 import BeautifulSoup
def html_chunking(html):
soup = BeautifulSoup(html, 'html.parser')
chunks = []
for section in soup.find_all(['h1', 'h2', 'h3']):
chunk = section.text + "\n"
next_node = section.next_sibling
while next_node and next_node.name not in ['h1','h2','h3']:
chunk += str(next_node)
next_node = next_node.next_sibling
chunks.append(chunk)
return chunks
策略5:LLM智能分块(LLM-based Chunking)
基本原理:直接将原始文档输入大语言模型(LLM),由模型智能生成语义块。利用LLM的语义理解能力,动态划分文本,保证了分块语义的准确性,但这种分块方法对算力要求最高,对时效性与性能也将带来挑战。

LLM智能分块策略方法可以确保较高的语义准确性,因为 LLM 可以理解超越简单启发式方法(用于上述四种方法)的上下文和含义。
唯一的问题是,它是这里讨论的所有五种技术中计算要求最高的分块技术。此外,由于 LLM 通常具有有限的上下文窗口,因此需要注意这一点。
实现步骤:
- 输入文档:将完整文档送入LLM(如DeepSeek、GPT)。
- 生成块指令:通过提示词(Prompt)引导模型按语义划分块。
- 示例提示词:“请将以下文档按语义划分为多个块,每个块需包含完整主题。”
- 输出块列表:模型返回划分后的块,可能包含逻辑标签(如“引言”、“方法论”)。
主要优点:
- 高度智能化:适应复杂、非结构化文本(如自由写作、对话记录)。
- 动态适应性:根据文档内容自动调整块大小和逻辑。
- 生成质量:块语义连贯,减少人工干预。
主要缺点:
- 计算成本高:依赖高性能LLM,资源消耗大。
- 可解释性差:模型决策过程难以追溯,可能产生不可预测的块。
- 依赖模型能力:效果受限于LLM的训练数据和语义理解能力。
适用场景:
- 非结构化文本(如访谈记录,会议纪要,用户评论、社交媒体内容等)。
- 需高级语义分析的场景(如跨领域知识整合)
提示词示例:
# GPT-4提示词设计
你是一位专业文本分析师,请根据语义完整性将以下文档分割为多个段落块:
要求:
1. 每个块包含完整语义单元
2. 最大长度不超过512token
3. 输出JSON格式:{"chunks": ["text1", "text2"]}
文档内容:{{document_text}}
五、分块策略选型矩阵
1. 分块策略总结对比
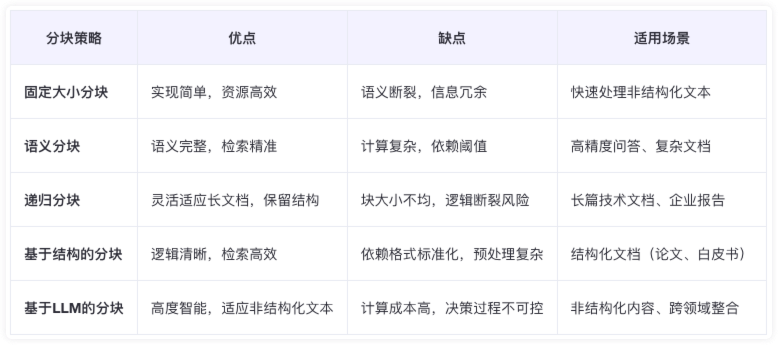
每种技术都有其自身的优势和劣势。我个人建议语义分块在很多情况下效果很好,但同样,您需要进行测试。
选择将在很大程度上取决于内容的性质、嵌入模型的功能、计算资源等。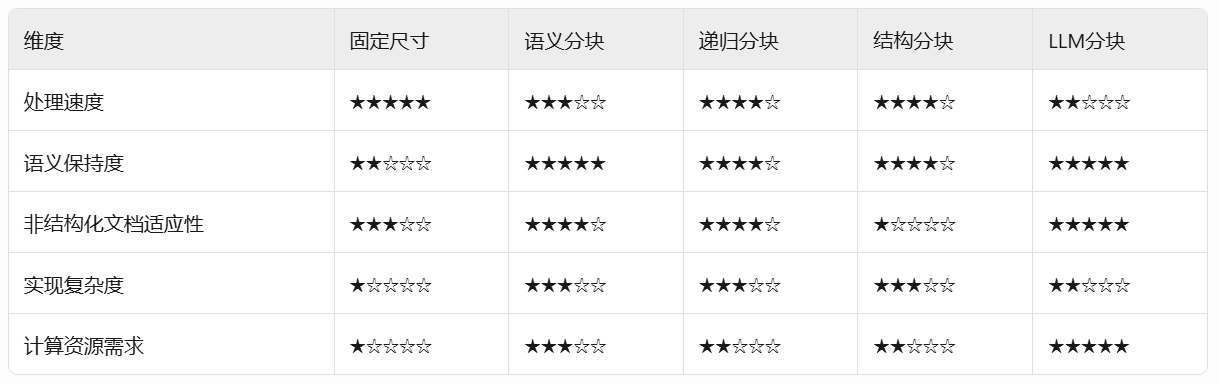
2. 分块策略选型建议
- 结合递归与结构分块:处理长文档时(如法律合同、表格、公式、技术手册)。
- 语义分块:对生成质量要求高、文档语义复杂时(如论文、医疗问答)。
- 使用LLM分块:处理非结构化或混合内容(如多模态文档)。
- 固定大小分块:快速部署或资源受限场景(如社交媒体、轻量级应用)。
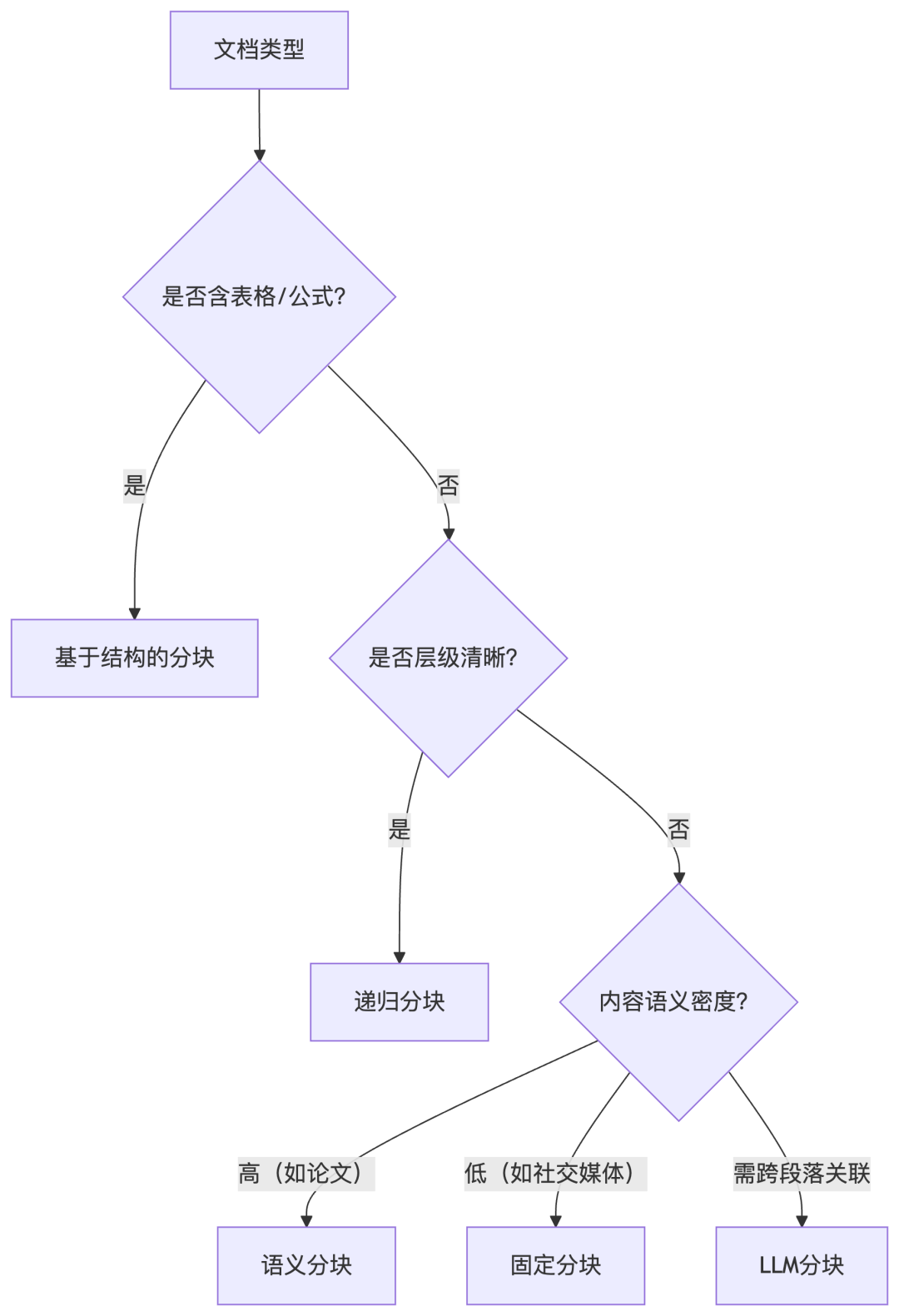
具体实施过程中,我们需要根据具体需求与文档类型选择分块策略,或组合多种方法(如“结构分块+语义细分”)以实现最佳效果。
六、RAG面临的挑战与前沿探索
1. 深层待解决问题
-
知识关联缺失
当前检索基于单点语义相似度,无法构建跨文档知识图谱(如“公司A收购事件”与“行业竞争格局变化”的隐含关联)。 -
推理-检索割裂
生成模型无法主动指导检索过程,形成“检索→生成”单向流水线,而非动态交互式推理。例如:模型应能反问“您需要对比哪两个季度的数据?”以优化检索目标。 -
多模态理解不足
现有RAG主要处理文本,对文档中的图表、公式、流程图等信息利用率极低。例如研报中的股价趋势图无法被检索系统理解。 -
可信度量化困境
缺乏统一标准评估答案可靠性,用户难以判断“何时可信任RAG的输出”,导致存在潜在风险,例如金融场景中错误答案可能导致直接经济损失。 -
长上下文建模缺陷
当检索返回大量片段(如20篇文档)时,模型对超长提示词的尾部信息忽略率显著上升。
2. 解决路径与前沿探索
-
检索增强
- 混合检索:融合语义搜索(Embedding)与关键词搜索(BM25)提升召回率
- 查询扩展:用LLM将用户问题改写为专业查询(如“钱放余额宝安全吗?”→“货币基金信用风险评估”)
- 递归检索:实现多跳推理(先查“美联储加息”,再查“科技股估值模型”)
-
生成控制
- 强制引用:要求模型标注答案来源位置(如:源自2023年报第5页)
- 置信度阈值:对低置信答案触发人工审核流程
- 结构化解构:将复杂问题拆解为子问题分步检索生成
-
优化分块
- 语义分块:按句子/段落边界切分而非固定长度
- 结构感知:保留表格、标题层级(利用Markdown/XML标签)
- 动态重叠:相邻块部分重叠避免上下文断裂

















 1456
1456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









