







int x, y;
char buff_output[100], buff_input[100];
scanf("%d", &x);
scanf("%d", &y);
//--------------------------------
for (int i = x / 4, end = (y + 3) / 4;
i < end;
++i)
{ // 对未知的区间(假设是4字节对齐),按uint32复制
((uint32_t*)buff_output)[i] = ((uint32_t*)buff_input)[i];
}
//--------------------------------
puts(buff_output);
类似的循环,gcc和vs经编译都会形成memcpy的调用
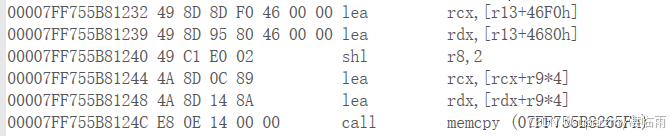
但如果终点和起点非常节点,则调用memcpy得不偿失性能较慢。
改用如下代码,可以强迫编译器放弃memcpy,性能可能会提速一倍
int x, y;
char buff_output[100], buff_input[100];
scanf("%d", &x);
scanf("%d", &y);
//--------------------------------
for (int i = x / 4, end = (y + 3) / 4;
i < end;
++i)
{ // 对未知的区间(假设是4字节对齐),按uint32复制
// 加上volatile
((volatile uint32_t*)buff_output)[i] = ((uint32_t*)buff_input)[i];
}
//--------------------------------
puts(buff_output);
但我们直到如果使用了volatile,就会导致一些编译器优化链断开,对最终性能未必是好事。
int x, y;
char buff_output[100], buff_input[100];
scanf("%d", &x);
scanf("%d", &y);
//--------------------------------
for (uint32_t i = x &~ 3 /*在这里修改x可以让编译器不那么确定范围*/, end = y; i < end; i += 4)
{
*(uint32_t*)(buff_output + i) = *(uint32_t*)(buff_input + i);
}
//--------------------------------
puts(buff_output);



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









