




一、数据提前打包的优点
① Embedding 是最耗时步骤之一
SAM 的 image encoder(比如 ViT-H)对每张图做 embedding 的计算成本很高。将分割数据集中的“图像 + GT + 嵌入” 数据提前打包保存好,可以让之后训练、测试、推理阶段更快。
② 保证数据一致性
在做分割任务时需要:原始图像(imgs)、目标标签 GT(gts)和特征嵌入(img_embeddings一一对应、结构化保存,.npz 文件非常合适。
③ 避免冗余预处理计算
图像归一化、resize 到标准尺寸(256 或 1024)、通道转换等预处理,如果每次使用模型都做一次,重复计算会浪费时间。
④ 供下游分割、训练、评估使用
一旦有了 .npz 文件,你可以直接用它去:
-
Fine-tune 自己的头部分类器(基于 SAM 提取的 features);
-
输入 SAM 的 mask decoder;
-
做语义/实例分割的训练与评估;
-
可视化 GT vs prediction 等。
二、整体实现思路
① 初始化和加载配置
-
设置图像路径(原图 + 掩码)、保存路径、模型类型、SAM checkpoint 等。
-
使用
sam_model_registry加载指定的 SAM 模型并移动到 GPU。
② 读取并预处理 Ground Truth 掩码图像
对每张掩码图像(GT):
-
读取并转换为灰度图(只保留一个通道)
-
缩放为统一尺寸(如 256x256)
-
统计非零像素和目标标签种类
-
过滤掉太小或不符合要求的掩码图像
-
例如:非零像素 < 100,或者没有包含多个目标(如 obstacle 和 rail
-
③ 预处理原始图像
对每张通过筛选的图像:
-
读取原图(RGB)
-
图像像素值拉伸至0.5%~99.5%范围内(去除极值)
-
归一化至 [0, 255]
-
Resize 到统一尺寸(1024x1024) 用于训练模型使用
④ 提取 SAM 图像嵌入
-
使用
ResizeLongestSide把图像 resize 成 SAM 要求的(1024, 1024) -
通过 SAM 自带的
preprocess进行预处理 -
使用
sam_model.image_encoder提取图像的 embedding(特征向量) -
保存为
img_embeddings
⑤ 打包并保存为 .npz 文件
-
将所有的
imgs(256x256)、gts(256x256)、img_embeddings(1024x1024 -> embedding)打包成一个.npz文件,方便后续加载使用。
三、实现代码
1. 数据打包
本文处理的是语义分割任务,GT图像中包含背景和两类目标,因此选择将彩色的 GT 标注图(RGB 掩码)转换为语义分割所需的整数标签图(label mask),每个像素的值代表其属于的类别。在我的GT 掩码图中:
-
背景像素是黑色(RGB
[0, 0, 0]) -
第一类目标是红色(RGB
[255, 0, 0]) -
第二类目标是绿色(RGB
[0, 128, 0])
手动将颜色映射到类别编号:
-
背景:0(默认值)
-
红色
[255, 0, 0]:第一类目标 -> 标签 1 -
绿色
[0, 128, 0]:第二类目标-> 标签 2
最终得到一个 GT 标签图 mapped_gt,每个像素是类别编号 [0, 1, 2] 中的一个整数。这张图可以直接喂给语义分割模型作为监督信号,或者用于指标评估(如 mIoU)。
因此,在下面代码中,首先替换文件中路径配置部分,然后根据自己的GT图像中目标的颜色修改对应的像素值。如果你的 GT 图还有其他颜色类别,可以继续扩展这个映射逻辑。
这段代码的主要工作是对图像数据及其对应的伪彩色目标图像(GT 图像)进行预处理,提取图像嵌入(embeddings),并最终将处理后的图像数据、标签数据和图像嵌入保存为一个 .npz 文件。具体来说,代码读取 GT 图像,将其调整为固定大小并映射为标签掩码(例如将特定颜色映射为不同的类别标签)。同时,代码读取对应的原始图像,进行归一化和大小调整,并通过 SAM 模型提取图像嵌入。生成的 .npz 文件中包含以下数据:
imgs:处理后的图像数据,形状为 (N, 1024, 1024),其中 N 是有效图像的数量。
gts:对应的标签掩码数据,形状为 (N, 256, 256),表示每个像素的类别标签。
img_embeddings:通过 SAM 模型提取的图像嵌入,形状为 (N, D),其中 D 是嵌入的维度。
# 将分割数据集中的“图像 + GT + 嵌入” 数据打包
# 提取图像嵌入(embeddings),并最终将处理后的图像数据、标签数据和图像嵌入保存为一个 .npz 文件。
# 生成的 .npz 文件中包含以下数据:
# imgs:处理后的图像数据,形状为 (N, 256, 256),其中 N 是有效图像的数量。
# gts:对应的标签掩码数据,形状为 (N, 256, 256),表示每个像素的类别标签。
# img_embeddings:通过 SAM 模型提取的图像嵌入,形状为 (N, D),其中 D 是嵌入的维度。
import numpy as np
import os
from skimage import transform, io
from tqdm import tqdm
import torch
from segment_anything import sam_model_registry
from segment_anything.utils.transforms import ResizeLongestSide
# 路径配置
img_path = "./images"
gt_path = "./mask/all"
save_path = "../data"
model_type = 'vit_h'
checkpoint = 'D:/1/SAM/segment-anything-main/models/sam_vit_h_4b8939.pth'
device = 'cuda:0'
# 类别颜色映射(rail: 红色,obstacle: 绿色)
COLOR_TO_LABEL = {
(128, 0, 0): 1, # rail
(0, 128, 0): 2 # obstacle
}
# 初始化
names = sorted(os.listdir(gt_path))
os.makedirs(save_path, exist_ok=True)
sam_model = sam_model_registry[model_type](checkpoint=checkpoint).to(device)
# 数据缓存
imgs, gts, embs = [], [], []
invalid_gt_images = []
def find_unique_colors(image):
unique_colors = np.unique(image.reshape(-1, image.shape[2]), axis=0)
return unique_colors
for gt_name in tqdm(names):
image_name = gt_name.split('.')[0] + ".jpg"
gt_rgb = io.imread(os.path.join(gt_path, gt_name))
# 检查GT是否为RGB图像
if gt_rgb.ndim != 3 or gt_rgb.shape[2] != 3:
print(f"Skipping {gt_name}: not RGB.")
invalid_gt_images.append(gt_name)
continue
unique_colors = find_unique_colors(gt_rgb)
# 调整大小并转换为uint8
gt_rgb = transform.resize(gt_rgb, (256, 256), order=0, preserve_range=True, mode='constant').astype(np.uint8)
# 创建统一标签图
gt_mask = np.zeros((256, 256), dtype=np.uint8)
for color, label in COLOR_TO_LABEL.items():
r, g, b = color
match = (gt_rgb[:, :, 0] == r) & (gt_rgb[:, :, 1] == g) & (gt_rgb[:, :, 2] == b)
gt_mask[match] = label
if np.sum(gt_mask > 0) > 100:
try:
image_data = io.imread(os.path.join(img_path, image_name))
if image_data.ndim == 2:
image_data = np.stack([image_data]*3, axis=-1)
# 归一化 + resize
lower, upper = np.percentile(image_data, 0.5), np.percentile(image_data, 99.5)
image_data = np.clip(image_data, lower, upper)
image_data = (image_data - image_data.min()) / (image_data.max() - image_data.min()) * 255.0
image_data[image_data == 0] = 0
image_data = transform.resize(image_data, (256, 256, 3), order=3, preserve_range=True, mode='constant', anti_aliasing=True)
image_data = np.uint8(image_data)
# 图像嵌入
sam_transform = ResizeLongestSide(sam_model.image_encoder.img_size)
resize_img = sam_transform.apply_image(image_data)
resize_tensor = torch.as_tensor(resize_img.transpose(2, 0, 1)).to(device)
input_tensor = sam_model.preprocess(resize_tensor[None, :, :, :])
with torch.no_grad():
embedding = sam_model.image_encoder(input_tensor).cpu().numpy()
# 存储
imgs.append(image_data)
gts.append(gt_mask)
embs.append(embedding)
except Exception as e:
print(f"Error processing {image_name}: {e}")
invalid_gt_images.append(gt_name)
else:
print(f"Skipping {gt_name}: Invalid mask.")
invalid_gt_images.append(gt_name)
# 保存数据
def stack_embeddings(emb_list):
return np.concatenate(emb_list, axis=0) if emb_list else np.array([])
np.savez_compressed(os.path.join(save_path, 'data.npz'),
imgs=np.stack(imgs) if imgs else np.array([]),
gts=np.stack(gts) if gts else np.array([]),
img_embeddings=stack_embeddings(embs))
print(f"Saved unified data to {save_path}/data.npz")
print(f"Invalid GT images: {invalid_gt_images}")
2. 查看.npz文件
.npz 文件中包含了三个主要的数据数组:imgs、gts 和 img_embeddings。通过以下代码可以查看上面打包的.npz文件内涵的数据。
import numpy as np
# 加载 .npz 文件
npz_file = np.load("./image/data.npz")
# 查看文件中包含的键(即数据的名称)
print("Keys in the .npz file:", npz_file.files)
# 查看每个键对应的数组的形状和内容
for key in npz_file.files:
print(f"Key: {key}, Shape: {npz_file[key].shape}")
print(f"Data: {npz_file[key]}")
本文使用十张图片数据,运行上述代码后生成.npz文件内部数据的内容如下图所示。
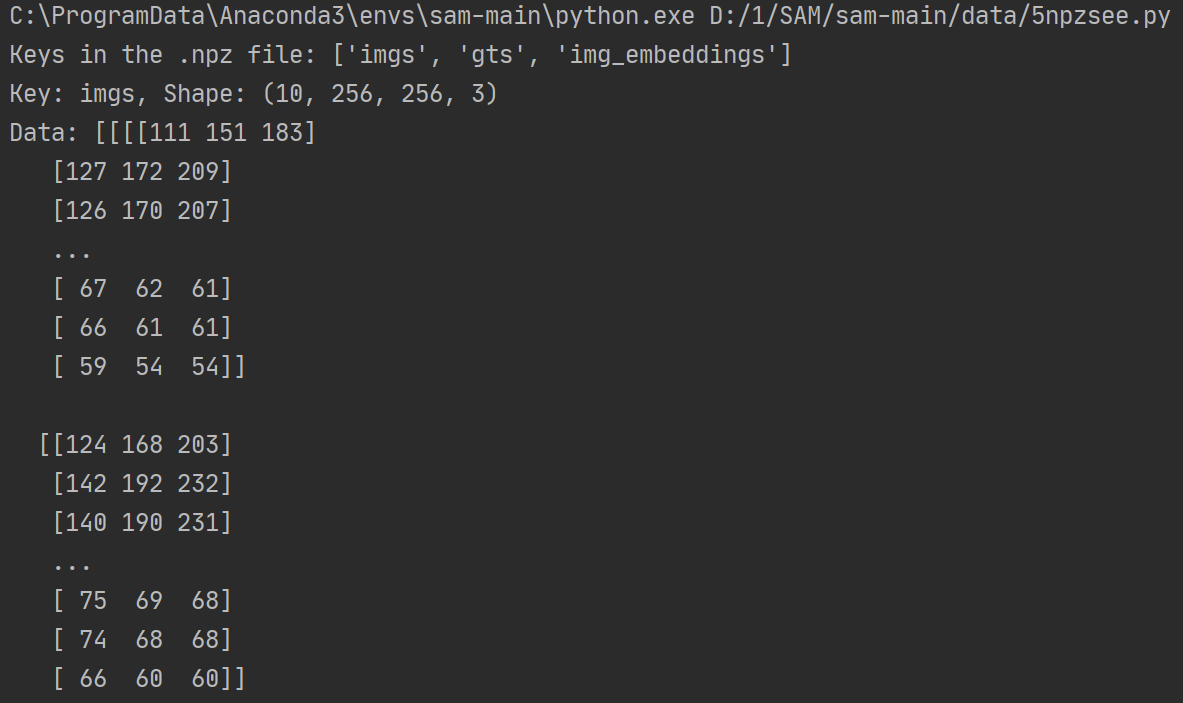
(1)imgs:处理后的图像数据
形状: (10, 256, 256, 3)
含义: 这是一个包含 10 张图像的数组,每张图像的大小为 256*256 像素,每个像素有 3 个通道(RGB)。
内容: 每个像素的值是一个 RGB 值,范围为 [0, 255]。例如图像的第一个像素是 (111, 151, 183),第二个像素是 (127, 170, 209),依此类推。
(2)gts:对应的标签掩码数据
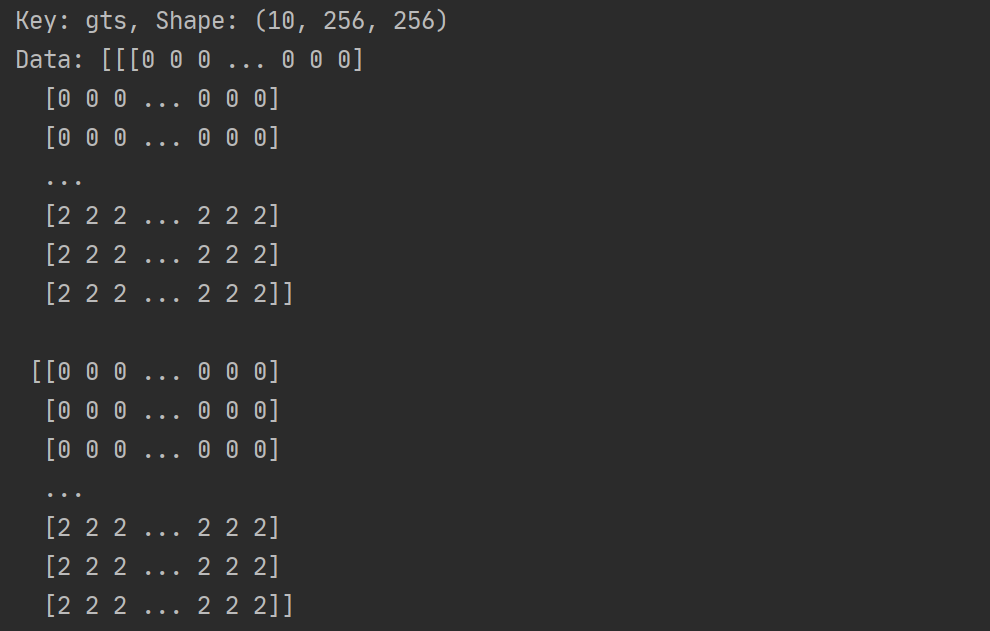
形状: (10, 256, 256)
含义: 这是一个包含 10 张标签掩码(GT)的数组,每张标签掩码的大小为 256×256 像素。
内容: 每个像素的值是一个整数,表示该像素的类别标签。在这个例子中,大部分像素的标签为 0(背景),而底部的像素标签为 2(轨道)。标签值 1 和 2 分别表示障碍物和轨道。
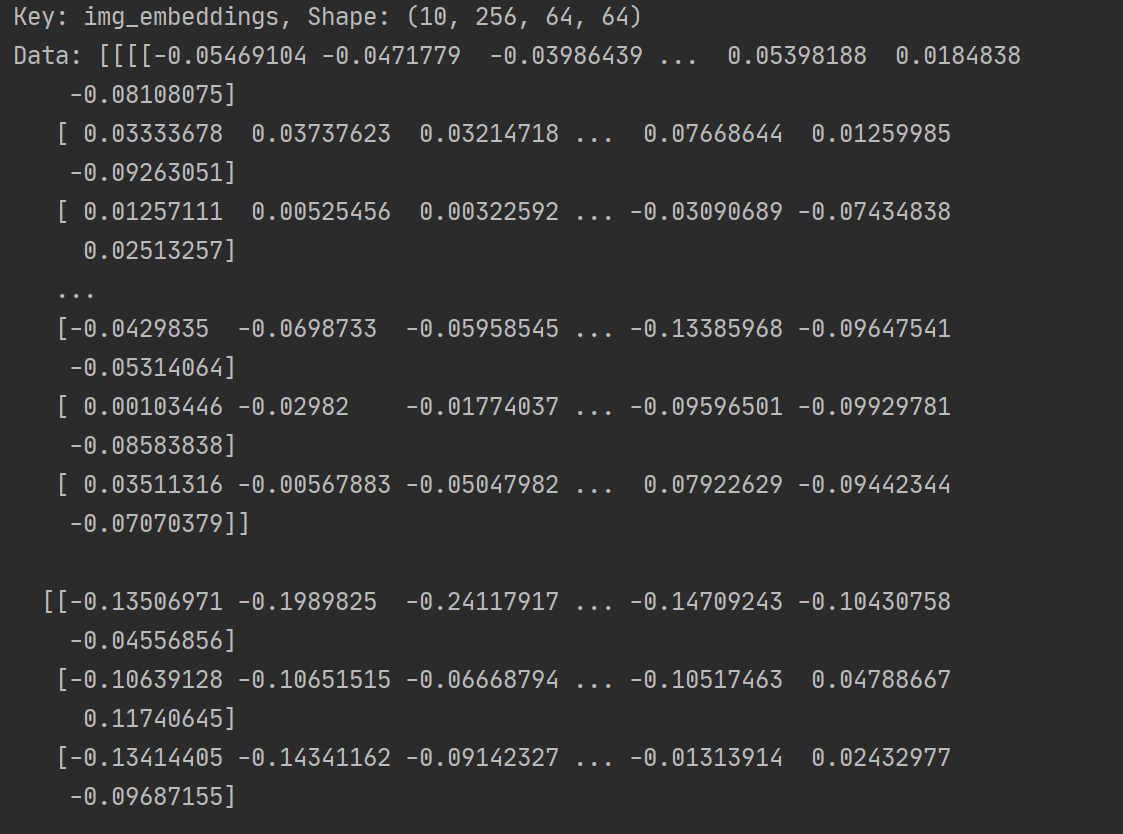
(3) img_embeddings:通过 SAM 模型提取的图像嵌入
形状: (10, 256, 64, 64)
含义: 这是一个包含 10 张图像的嵌入向量的数组。每张图像的嵌入是一个 4 维张量,形状为 (256, 64, 64)。
内容: 每个嵌入值是一个浮点数,表示图像的特征向量。这些嵌入值是通过 SAM 模型提取的图像特征,用于后续的分割任务。



















 3414
3414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









