




论文链接:
[2307.15478] Local and Global Information in Obstacle Detection on Railway Tracks
(1)概述
该论文提出了一种结合局部与有限全局信息的数据驱动的新型铁路障碍物检测方法,依托安装在驱动平台上的可变焦高焦距摄像机,实现远距离潜在障碍物检测。作者利用铁路轨道结构高度规则、局部纹理显著的特点,将异常检测问题重新表述为局部分割任务,用感受野受限的浅层网络学习铁路与背景的分割,并通过加入随机非铁路图像作为反例来增强模型对异常的识别能力;同时,引入由自编码器或GAN生成的“无障碍铁路图像”,通过比较原始图像与重建图像的语义差异,进一步提升检测性能。该方法无需真实障碍物样本即可训练,训练集由RailSem19的子集组成,并在其障碍增强版本上进行评估,表现优异,尤其在检测小型或与背景颜色相近的障碍时优势明显,但在重建失败或极端环境下仍存在一定局限。

(2)贡献
目前为止,大多数研究都集中在通过在定制的铁路障碍数据集[4]-[8]上训练对象检测网络来检测预定义的类别,例如人类或其他列车。然而,根据设计,这些系统仅限于这组预定义的类别,不能推广到未知的障碍类型。此外,必须根据数据集对模型进行训练包含人工插入的障碍物或铁路领域之外的数据集,因为包含铁轨上障碍物的真实图像很难获得。这导致了探测器中的强烈偏见,并引发了人们对其在现实世界应用中能力的怀疑。在这项工作中,我们专注于数据驱动的异常检测任务,其中,我们不是学习检测一组预定义的障碍类别,而是学习识别铁路环境,通过排除不属于的一切,即异常,也是潜在的障碍。从现在开始,我们将使用术语异常检测来指代一般的障碍物检测,其中对象类别在训练时是未知的。除了检测一般障碍物的能力外,我们方法的另一个优势是,培训不需要铁路上真实的或人为制造的障碍物样本。具体贡献如下:
- 提出了一种新的基于浅层网络的视觉异常检测方法,该方法非常适合于高度结构化的铁路环境。此外,我们的方法不需要铁路上难以获得的真实异常图像。
- 我们通过使用幻觉无障碍重构来探索全局信息的包含,并将异常检测问题重新表述为语义差异检测任务。
- 对对象增强版本的RailSem19数据集进行了广泛的评估,将我们的解决方案与多个基线进行了比较,并评估了每种方法的优缺点。
(3)相关工作
1)视觉异常检测
视觉异常检测方面的研究成果可分为五大类。概率方法,如高斯(混合)模型、核密度估计[17]或变分自动编码器(AEs)[18],旨在估计正常图像的概率分布并检测脱离该分布的图像。单类分类方法遵循类似的方法,通过支持向量机[19]、支持向量数据描述符[20]或深度学习[21]、[22]来构建决策边界。基于重构的方法通常使用声学估计来学习低维表示,从中可以重构原始输入[10]、[23]-[25]。然后,将测试时的重建误差用作异常图像区域的度量。自监督异常检测方法旨在学习正常样本的重要和高级别特征,例如,通过辅助学习任务[26]、[27]。这避免了精确定义异常是什么的需要,并且不需要异常的示例数据。特征建模方法不检测图像空间中的异常,而是在手工制作或学习的特征空间中检测异常,例如预先训练的卷积神经网络(CNN)的特征[11]、[28]、[29]。
2)铁路上的视觉障碍物检测
【自动列车的障碍物检测系统】介绍了一种使用边缘检测、光流和纹理统计的跟踪和障碍物检测系统,其方法主要针对特定领域的灰度图像。然而,对不同对象类别的评价仍然有限。
An obstacle detection system for automated trains | IEEE Conference Publication | IEEE Xplore
【移动摄像机背景减法用于铁轨上的障碍物检测】和【基于背景减去和帧配准的前部障碍物检测】提出了一种基于背景减去的方法,然而该方法容易受到光照或环境变化的影响。
Frontal Obstacle Detection Using Background Subtraction and Frame Registration
【基于霍夫变换的轨道上障碍物检测】在使用霍夫变换和坎尼边缘检测器观察到的铁轨上解决这个问题。此检测过程中的不连续表示轨道上的障碍物,尽管健壮性有限,因为对轨道几何形状的假设会导致此方法在具有弯曲轨道的情况下失败。
Obstacle detection over rails using hough transform | IEEE Conference Publication | IEEE Xplore
【基于视频的铁路碰撞预警系统】遵循类似的方法,但也有同样的缺点。
Video based system for railroad collision warning | IEEE Conference Publication | IEEE Xplore
基于学习的目标检测方法:【基于神经网络的铁路障碍物检测算法】、【基于更快的Better网络的真实世界铁路交通检测】、【基于深度卷积神经网络的轨道上实时障碍物检测】、【基于CNN的堆场机车轨道智能障碍物检测系统的研制】、【智能车载多传感器障碍物检测系统改善轨道交通安全】、【用于基于深度学习的铁路障碍物检测的对象级数据增强】、【自动驾驶列车行人检测与分类】、【基于深度视觉的防止火车与大象相撞的监控系统】、【基于差分特征融合卷积神经网络的轨道交通目标检测】在检测人类、火车或行李方面也取得了一些成功,但它们依赖于定制的数据集,并且局限于一组固定的目标类别。
Railway obstacle detection algorithm using neural network | ScienceGate
SMART on-board multi-sensor obstacle detection system for improvement of rail transport safety
Object-Level Data Augmentation for Deep Learning-Based Obstacle Detection in Railways
Deep vision-based surveillance system to prevent train–elephant collisions | Soft Computing
目前,将视觉异常检测方法应用于铁路障碍物检测的研究还很少。【铁路检测中的异常检测、定位和分类】将无监督图像重建与监督异常检测相结合,用于夜间铁路检查,但因此仅限于热像仪。【基于无监督学习的铁路障碍物检测:一项探索性研究】对具有不同优化器、激活和损失函数的AE结构执行网格搜索,并在带有人工插入障碍物和一个真实世界场景的自定义测试数据集上对其进行评估。在我们的实验中,这些基于声发射的方法无法检测到铁路环境中常见的小障碍物或颜色较大的障碍物。【基于无监督异常检测模型的高速铁路入侵检测】 类似地,训练AE,但通过直接分析潜在空间中的分布来检测异常,并且仅利用重建来定位检测到的异常。
https://uphf.hal.science/hal-03379755/document
(4)方法
1)基于局部分割的异常检测
由于缺乏包含铁路障碍物的训练数据,研究者提出了一种基于视觉异常检测的无监督障碍物检测方法。该方法通过学习铁路图像的正常结构模式,将不符合铁路特征的区域视为异常,从而隐式地检测潜在障碍物。网络以铁路与背景分割为辅助任务训练,采用小感受野以限制全局信息,防止过度自信。训练时使用无铁路的随机图像作为负样本,并在铁路区域内计算像素级二元交叉熵损失。部署阶段,通过已知的列车位姿和铁路地图,将轨道投影到图像中获得轨道掩膜,然后根据分类结果中被错误标为背景的铁路像素检测异常,并通过密度滤波与阈值处理生成障碍物掩膜,最终基于异常像素数量或聚类区域大小判断障碍物的存在。
通俗理解:因为铁路场景中很难获取带有障碍物的训练数据,研究者提出了一种不依赖障碍物样本的视觉异常检测方法。这个方法的核心思想是先让模型学会“正常铁路”应该是什么样子,当它在图像中看到不符合铁路特征的地方时,就认为那里可能有障碍物。为此,模型在训练时学习区分铁路和背景,并使用一些完全不含铁路的随机图片作为对照,让它更好地理解“非铁路”是什么样的。同时,模型只关注局部区域的信息,以避免判断过度自信。实际使用时,通过列车的定位和铁路地图,可以知道轨道在图像中的位置,然后根据模型的分类结果,如果轨道上的某些区域被错误地识别为背景,就说明那里可能有异常。最后,系统会对这些异常点进行筛选和聚合,得到可能的障碍物区域,并根据异常区域的大小或数量来判断是否真的存在障碍物。
模型流程:首先,输入一张可能包含障碍物的铁路图像,将其输入到铁路分割网络(Railway Segmentation Network)中,该网络通过对铁路轨道特征的识别与学习,精准分割出铁路轨道区域,并生成分类图(Classification Map),明确区分轨道与背景;接着,在分类图的基础上进行障碍物定位,先计算密度图,它依据局部区域的特征信息,反映出各区域存在障碍物的可能性大小;随后进行阈值处理,设定合适阈值将密度图中可能性较高的区域提取出来,形成阈值图;最后通过计算质心,精确确定障碍物在图像中的位置,从而实现对铁路轨道上障碍物的有效检测。
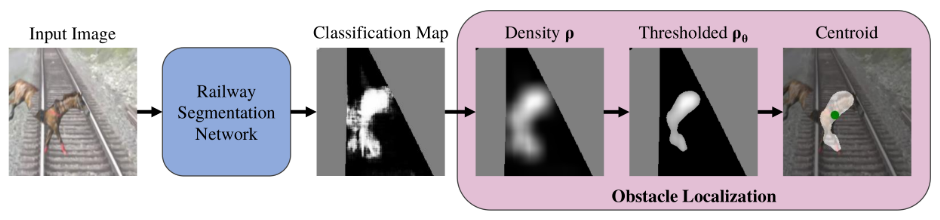
2)整合全局信息
研究者在原本基于局部特征的异常检测方法上引入全局信息,以提升障碍物检测效果。他们借鉴图像重建的思路,利用神经网络生成没有障碍物的“虚拟”铁路图像(即障碍物被自动去除的版本),并通过比较原图与生成图在语义上的差异来发现异常区域。为此,他们设计了一个具有局部感受野的语义差异网络,用于判断两幅图像在像素层面上语义是否不同,而无需显式分类。在生成无障碍铁路图像时,他们采用自编码器结构,通过小的瓶颈层强制模型学习铁路的典型模式,使其无法重建障碍物,并测试了四种不同的重建损失函数(包括MSE、SSIM、GAN和带直方图损失的GAN)以平衡图像的真实感与结构保真度。最后,系统通过比较原图和重建图的语义差异图定位障碍物,从而实现基于“虚拟无障碍图像”的全局—局部结合的视觉异常检测方法。
通俗理解:为了让障碍物检测更准确,研究者在原本只依靠局部图像特征的方法上,引入了全局信息。他们让神经网络先学会“想象”一张没有障碍物的铁路图片,也就是根据输入图像生成一张“障碍物被去掉后的版本”。然后,通过比较原图和“想象出来的无障碍图”之间的差异,就能找到哪些地方可能存在障碍物。为了实现这一点,他们设计了一个语义差异网络,用来判断两张图在每个像素上是否属于不同的语义区域,比如一处原本该是轨道却出现了不同的结构。生成无障碍图像的模型采用自编码器结构,通过压缩信息来强迫模型学习铁路的规律,而不是简单复制输入图像。研究者还尝试了多种训练方法,包括均方误差、结构相似度、以及利用生成对抗网络(GAN)来生成更逼真的图像。最后,系统通过分析原图与无障碍图的语义差异,就能准确地标出障碍物的位置,从而实现一种结合全局理解与局部特征的智能检测方法。
模型流程:首先接收一张包含铁路轨道及其可能障碍物的输入图像,随后利用一个精心设计的语义差异器(Semantic Differentiator),该网络通过比较输入图像与由无障碍图像生成器(Obstacle - free Image Generator)所创建的幻觉无障碍图像(Hallucinated Obstacle - free Image)之间的像素级语义差异,生成一个精细的语义差异图(Semantic Difference Map),此图能够突出显示两幅图像在语义上的不同之处,进而通过计算密度图和应用阈值处理技术,系统能够准确地在语义差异图上定位出潜在的障碍物区域,这一流程结合了局部信息(通过有限感受野的网络设计来限制全局信息的干扰)和全局信息(通过幻觉无障碍图像的生成和比较来引入),从而在无需真实障碍物样本训练的情况下,实现了对铁路轨道上未知障碍物的有效检测。
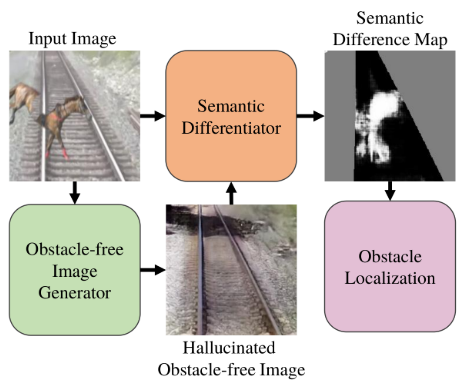
(5)实验
1)数据集
我们使用了公开的 RailSem19 数据集中的 7500 张标注训练图像(去除电车轨道部分),并从中截取了分辨率为 224×224 的感兴趣区域,总计得到 26,810 张铁路相关图像作为训练样本。为了让模型能够区分铁路与非铁路场景,我们还从 ImageNet 数据集中提取了 1,281,167 张随机图像作为非铁路样本。在测试阶段,我们构建了一个新的评估数据集 FishyRails,它基于 RailSem19 的官方测试集,并将 PascalVOC 数据集中的物体粘贴到铁路图像上,以模拟现实中障碍物出现在轨道上的情况。为了让这些合成障碍物更加逼真,我们在生成过程中加入了边缘平滑、亮度校正、运动模糊、景深模糊以及高斯噪声等效果。
2)对比方法
我们选用了几种已有的主流模型作为基线:
-
DeeplabV3:一种标准的语义分割网络,我们用它来区分铁路与背景,作为最基础的基线。
-
MSE AE 和 SSIM AE:这两个自编码器模型分别采用均方误差和结构相似度作为重建损失,通过重建误差来判断异常区域。
-
Student-Teacher 方法:来自 Bergmann 等人的研究,在工业视觉异常检测中表现出色,我们希望它在结构规则的铁路场景中也能取得良好效果。
3)评价指标
我们对所有模型的参数(如滤波器大小 K 和阈值 θ)进行了网格搜索,以寻找能使 F1 分数最高的参数组合。实验中,我们假设每张图像中最多只有一个障碍物,这一设定在我们的数据集中是成立的。在实际应用中,如果存在多个障碍物,可以通过聚类或异常像素数量来进一步判断。
-
AUROC(曲线下面积):用于评估模型在像素级分类上的整体区分能力,不依赖阈值选择。
-
F1 分数:用于评估障碍物定位的准确性,当模型预测的障碍物中心点位于真实障碍物的标注框内时,视为检测成功。
4)FishyRails 数据集上的障碍物检测结果
我们在 FishyRails 测试集上采用固定的参数 ρ 和阈值 θ对所有方法进行了评估。结果显示,无论是局部方法还是结合全局信息的改进版(LGAN + LHIST),我们的模型 AUROC 均达到 0.926 以上,其中全局方法(LGAN + LHIST)最高达 0.936;F1 分数方面,本地方法表现最佳,达到 0.863,相比之下最好的基线方法 DeeplabV3 仅为 0.535。
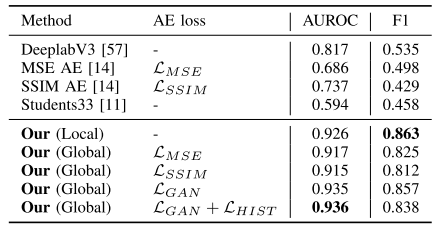
从下图中也可以看到,我们的方法能够准确检测到障碍物,而基线模型往往漏检或误判。尤其值得注意的是,DeeplabV3 虽然结构复杂、感受野大,但其性能明显不如我们的局部方法。这验证了我们提出的假设:过大的感受野导致模型过度依赖全局信息,从而出现过度自信的错误判断。进一步分析发现,DeeplabV3 在训练中从未见过带障碍物的铁路图像,因此倾向于错误地将轨道间的区域都归为“铁路”,对小型或颜色与轨道相近的障碍物尤其容易误判。此外,基于重建的 MSE AE 和 SSIM AE 在障碍物较小或颜色相似时也表现较差,其中 SSIM AE 在结构和对比度明显的障碍物上稍有优势。Student-Teacher 方法(Students33)则在所有模型中表现最差,因为它原本是为结构和颜色变化极小的工业图像设计的,难以应对铁路场景中的多样性。

5)全局信息引入的效果分析
虽然总体上我们的方法显著超越基线,但局部方法与全局方法之间的性能差距较小。全局方法(基于 LGAN + LHIST 的版本)取得了最高 AUROC(0.936),而局部方法在 F1 分数上表现更佳,说明其在障碍物定位方面更稳健。我们进一步分析了不同损失函数下全局方法的表现(如下图):LMSE 和 LSSIM 的生成模型主要关注像素级颜色差异,而非语义差异,因此容易将小障碍物“错误地重建出来”,导致漏检。基于 GAN 的方法(LGAN 和 LGAN + LHIST) 能够同时关注语义与视觉信息,从而在罕见或复杂场景中表现更好,减少了误报(false positives)。


但在障碍物过大时(例如占据画面很大比例的障碍),全局方法的“障碍物去除”重建会彻底失败(如下图),此时我们的本地方法反而更可靠,因为它不依赖于重建阶段。

总体而言,全局方法在视觉一致性强、障碍物较小或场景复杂时更具优势;局部方法在障碍物较大、生成阶段可能失败时更稳定,也更简单,适合安全关键场景(如铁路监测)。
6)消融实验(Ablation Study)
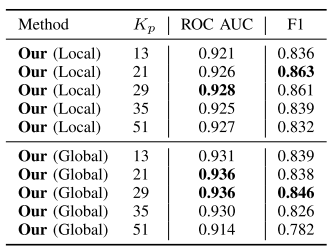
我们针对局部方法和全局方法(LGAN + LHIST 版本)分别研究了不同感受野(receptive field)大小对性能的影响。实验结果(表 II)显示:对于局部方法,感受野为 21 像素 时的 F1 分数最高;对于全局方法,最佳感受野为 29 像素。因此,我们在最终评估中分别采用了这两个感受野设置。这一实验进一步验证了我们关于“适度限制感受野有助于避免过度依赖全局上下文,从而提高异常检测效果”的假设。


















 1923
1923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









