



一种用于Domino逻辑的新型低功耗、高性能设计技术
Sunil Kavatkar
Girish Gidaye
电子系,VIT,孟买
sunilkavatkar@gmail.com
girish.gidaye@vit.edu.in
摘要
Domino逻辑电路由于其高速和相较于静态逻辑更小的面积,常用于微处理器等高性能设计中。但这些Domino逻辑存在功耗高和噪声容限低的问题。本文分析了先前提出的降低Domino逻辑功耗的技术,如双阈值电压(DTV)、双阈值电压‐电压缩放(DTVS)和堆叠晶体管双阈值电压(ST‐DTV)。本文提出了一种新颖的技术,该技术在上拉路径中仅使用双阈值电压技术和堆叠晶体管,并结合电压缩放与电荷共享技术。与先前的功耗降低技术相比,所提出的技术具有更低的功耗和更优的功耗延迟积(PDP)。栅极长度偏置技术可用于进一步降低漏电功耗。本文后续部分展示了栅极长度偏置对所提出设计的影响。所提出的电路设计基于三输入OR门,在28纳米体硅CMOS技术下进行仿真。仿真使用Mentor Graphics ELDO 13.2和EZ‐wave仿真器完成。
关键词 - 动态逻辑,功耗,功耗延迟积,栅极长度偏置
一、引言
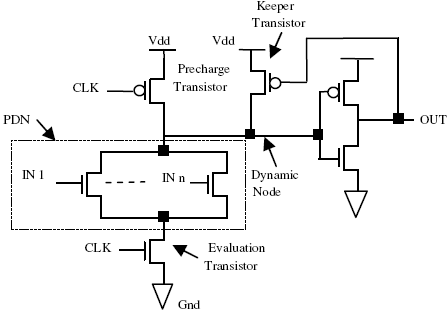
高性能和面积减小的优势使得动态逻辑电路成为微处理器等高性能电路的主要实现方案。然而,这种性能优势伴随着较高的功耗代价。动态逻辑通过在动态门的输出端添加一个反相器构成。图1展示了(n型)动态逻辑门的基本结构。其中下拉网络(PDN)的构造与互补CMOS完全相同[4]。当时钟信号=0时,图1中所示的动态节点将被预充电至Vdd;当时钟信号=1时,动态节点将根据输入值和下拉拓扑结构条件性地放电。动态节点上的电荷泄漏通过使用PMOS保持晶体管[8]进行补偿。
通过增大PMOS保持晶体管的尺寸(加宽),可提高其导通能力,从而试图维持动态节点上的电荷,进而提升动态逻辑的噪声鲁棒性[9]。相比静态CMOS逻辑,动态逻辑的延迟减少了42%。但其平均功耗比静态CMOS逻辑高出155%[5]。
任何电路消耗的功率可分为两部分:动态功耗和静态功耗。动态功耗是指电路在输入或输出发生转换时所消耗的功率。所消耗的动态功耗可由 $ P_{dyn} = CV_{dd}^2f $ 给出,其中,$ C $ 为负载电容,$ V_{dd} $ 为电源电压,$ f $ 为电路的时钟频率。静态功耗是指电路在静态或稳定状态条件下所消耗的功率,即输入或输出无转换时的功耗。静态功耗是由于MOS晶体管在稳态或稳定状态下存在漏电流而产生的。
早期,动态功耗是功耗的主要部分,而静态功耗非常小,可以忽略不计。但随着技术的进步,由于电源电压的缩放,当前CMOS技术中的动态功耗随电压平方下降。然而,电源电压的缩放会降低电路的性能。因此,阈值电压被相应降低,以减轻因电源电压缩放导致的性能下降。但随着阈值电压的降低,MOS晶体管中的亚阈值漏电流呈指数级增加[7]。由于亚阈值漏电流的增加,静态功耗也随之上升,因而不可再被忽略。
本文比较了多种降低动态逻辑功耗的技术,如双阈值电压(DTV)、双阈值电压‐电压缩放(DTVS)和堆叠晶体管双阈值电压(ST‐DTV),并提出了一种新颖的技术,该技术在上拉路径中仅使用堆叠晶体管结合双阈值电压技术,并辅以电压缩放与电荷共享技术来实现动态逻辑。与其他技术相比,所提出的技术具有更低的功耗和更优的功耗延迟积(PDP)。
各节内容组织如下。第二节讨论了近期一些降低动态逻辑功耗的技术。第三节介绍了提出的动态逻辑方案。第四节给出了比较结果。第五节分析了栅极长度偏置对提出逻辑的影响,第六节对全文进行了总结。
II. 以前的设计
动态逻辑的主要缺点是其功耗,需要解决这一问题。一些早期提出的降低功耗的技术如下所述。
A. 双阈值电压(DTV)技术
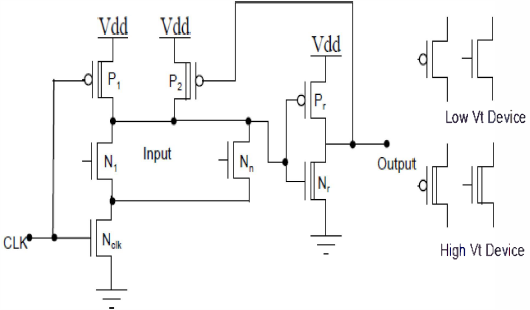
双阈值电压(DTV)技术用于降低漏电功耗[1][2]。图2展示了在动态逻辑中使用或门的DTV技术示例。动态逻辑中的延迟由评估路径中的晶体管决定[5],即评估路径是动态逻辑中的关键路径。因此,在双阈值电压动态电路中,评估路径中的所有晶体管均采用低阈值电压($ V_t $)。另一方面,预充电路径的转换非关键,因而具有较高的 $ V_t $。
B. 电压缩放与电荷共享技术
低功耗的电压缩放与电荷共享技术如图3所示。该技术用于降低电路中的动态功耗。
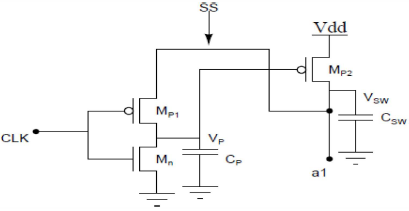
在第一级,时钟(CLK)信号同时提供给NMOS和PMOS,即 $ M_n $ 和 $ M_{p1} $。当CLK信号为高电平时,$ M_{p2} $ 导通,节点a1将被充电至高电平。当CLK信号为低电平时,$ M_{p2} $ 表现为具有非线性电阻的电阻器。$ C_p $ 和 $ C_{sw} $ 之间存在电荷共享。节点a1处的电压为 $ V_{sw} \leq V_{dd} - V_t $。
C. 双阈值电压-电压缩放(DTVS)技术
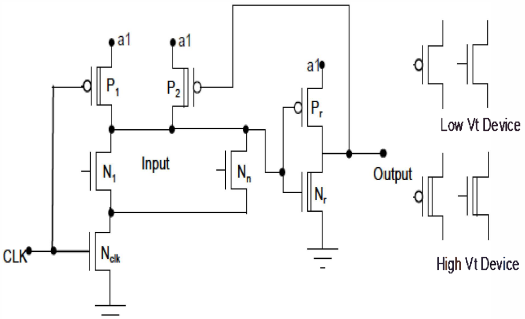
双阈值电压‐电压缩放(DTVS)技术是DTV技术和电压缩放技术的结合[5]。DTV技术可降低电路的静态功耗,而电压缩放技术可降低电路的动态功耗。因此,DTVS技术可同时降低电路的静态功耗和动态功耗。图4展示了使用或门实现的动态逻辑的DTVS结构。图3中的节点a1用于为电路提供电源。
D. 堆叠晶体管双阈值电压缩放技术
用于降低漏电流的晶体管强制堆叠方法被应用于堆叠晶体管双阈值电压(ST‐DTV)技术[6]中。在强制堆叠中,一个现有晶体管被两个晶体管替代,其 $ W/L $ 比例与原始晶体管相比减半。
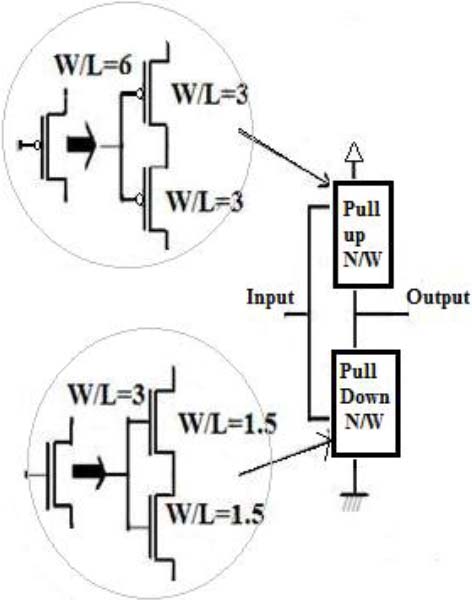
堆叠晶体管双阈值电压(ST‐DTV)技术如图6所示。当堆叠的晶体管关闭时,两者之间产生的反向偏置有助于减少漏电流。采用电压调节静态保持器(VRSK)代替传统保持器。在传统保持器中会发生竞争效应,而使用VRSK[6]可以减小该效应。
III. 提出的设计
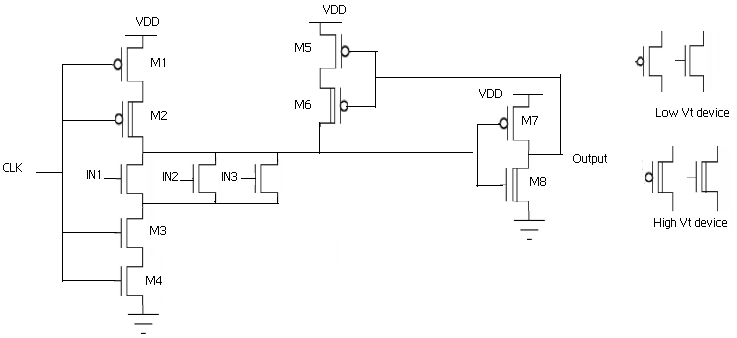
DTV技术在不影响关键路径延迟的情况下降低了动态逻辑中的功耗,但功耗仍然较高。可以使用ST‐DTV技术进一步降低功耗,但ST‐DTV的缺点是会增加关键路径延迟,在许多情况下这可能无法接受。因此,提出了一种仅在上拉路径中使用堆叠晶体管的双阈值电压‐电压缩放技术,以进一步降低功耗而不影响关键路径延迟。所提出的技术如图7所示。
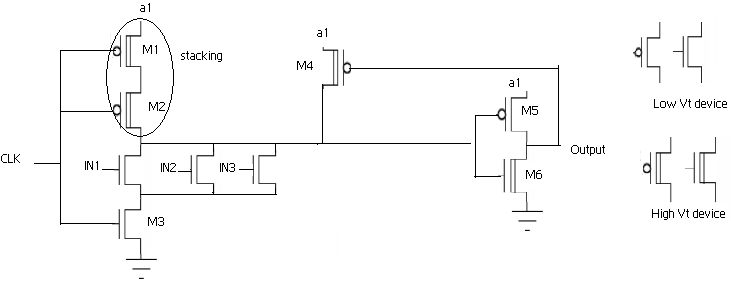
如图7所示,低 $ V_t $ 晶体管用于评估路径(关键路径),而预充电路径则使用高 $ V_t $ 晶体管实现。上拉路径中采用了堆叠结构,这将显著降低漏电功耗。关键路径中未使用堆叠结构,因为它会增加延迟。动态功耗可以通过在电源网络中采用如图3所示的电压缩放与电荷共享技术来降低。
IV. 仿真结果与比较
仿真在室温下使用Mentor Graphics ELDO 13.2和EZ‐wave在28纳米体硅CMOS技术中进行。仿真时使用了三输入OR门。仿真电路时未考虑保持电路。此外,仿真过程中使用常规 $ V_t $ 晶体管代替高 $ V_t $ 晶体管。通过使用高 $ V_t $,可以进一步降低漏电流。
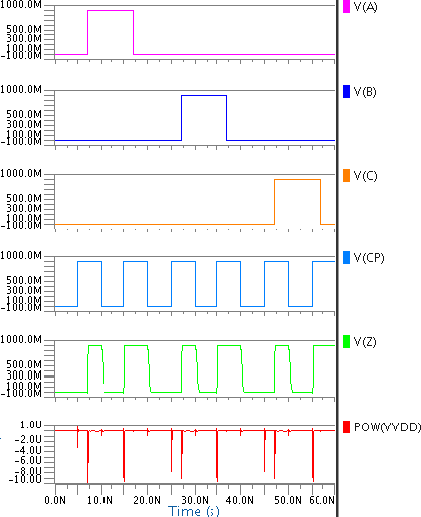
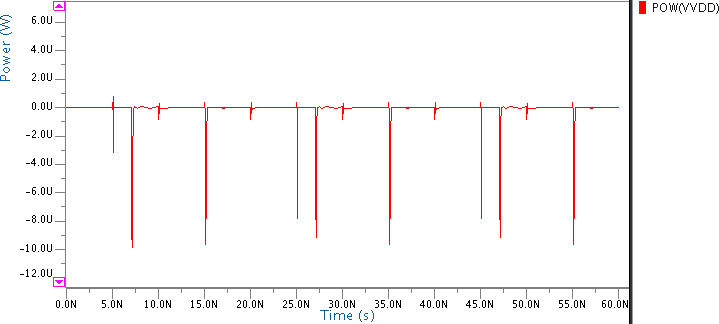
在100兆赫频率下,提出的动态逻辑与三输入OR门的仿真波形如图8所示,相同仿真的总功耗如图9所示。
提出的技巧与一些现有技术的平均功耗和关键路径延迟在以下表1和表2中进行了比较。
表1:Vdd= 0.9下的功率和延迟比较
| 频率 (MHz) | 技术 | 平均功率 (nw) | 延迟(纳秒) |
|---|---|---|---|
| 100 | DTV | 141 | 0.077 |
| 100 | DTVS | 133 | 0.08 |
| 100 | ST‐DTV | 129 | 0.11 |
| 100 | 提出的 | 126 | 0.08 |
| 166 | DTV | 224 | 0.073 |
| 166 | DTVS | 209 | 0.076 |
| 166 | ST‐DTV | 204 | 0.1 |
| 166 | 提出的 | 196 | 0.076 |
| 250 | DTV | 330 | 0.071 |
| 250 | DTVS | 308 | 0.075 |
| 250 | ST‐DTV | 300 | 0.098 |
| 250 | 提出的 | 290 | 0.075 |
| 500 | DTV | 597 | 0.045 |
| 500 | DTVS | 567 | 0.049 |
| 500 | ST‐DTV | 574 | 0.072 |
| 500 | 提出的 | 539 | 0.049 |
表2:Vdd= 1.2下的功率和延迟比较
| 频率 (MHz) | 技术 | 平均功率 (nw) | 延迟(纳秒) |
|---|---|---|---|
| 100 | DTV | 270 | 0.05 |
| 100 | DTVS | 257 | 0.0511 |
| 100 | ST‐DTV | 242 | 0.07 |
| 100 | 提出的 | 240 | 0.0511 |
| 166 | DTV | 419 | 0.046 |
| 166 | DTVS | 402 | 0.05 |
| 166 | ST‐DTV | 390 | 0.062 |
| 166 | 提出的 | 382 | 0.05 |
| 250 | DTV | 622 | 0.046 |
| 250 | DTVS | 589 | 0.049 |
| 250 | ST‐DTV | 578 | 0.06 |
| 250 | 提出的 | 565 | 0.049 |
| 500 | DTV | 1080 | 0.027 |
| 500 | DTVS | 1050 | 0.029 |
| 500 | ST‐DTV | 1048 | 0.039 |
| 500 | 提出的 | 1002 | 0.029 |
上述结果表明,与所提及的其他技术相比,提出的设计技术具有更低的平均功耗。与上述讨论的技术相比,提出的设计具有更好的功耗延迟积。功耗延迟积在图10和图11中进行了比较。
与ST‐DTV技术相比,该提出的方案最多可降低6.09%的功率,PDP改善37.36%;与DTV技术相比,最多可降低12.5%的功率,PDP改善9.19%;与DTVS技术相比,功耗最多降低6.61%,PDP改善6.62%。
V. 在提出的设计中实现栅极长度偏置技术
通过使用栅极长度偏置技术,可以在较小的延迟代价下进一步降低功耗。随着栅极长度的增加,MOSFET的阈值电压也随之增加。阈值电压的增加将减少亚阈值漏电流,从而降低漏电功耗[3]。该技术的缺点是由于阈值电压增加导致延迟增大。因此,必须根据需求选择最佳的偏置。表3和表4分别显示了在Vdd等于0.9和1.2时,栅极长度偏置对提出的设计的漏电功耗的影响。所给结果是在100兆赫频率和室温下的结果。
表3:Vdd= 0.9V 下的栅极长度偏置
| 栅极长度偏置 (nm) | 漏电流功率(纳瓦) | 延迟(纳秒) |
|---|---|---|
| 0 | 15.98 | 0.08 |
| 4 | 12.43 | 0.09 |
| 8 | 10.026 | 0.095 |
| 16 | 6.89 | 0.1 |
表4:在Vdd= 1.2V下的栅极长度偏置
| 栅极长度偏置 (nm) | 漏电流功率(纳瓦) | 延迟(纳秒) |
|---|---|---|
| 0 | 56.33 | 0.0511 |
| 4 | 54.138 | 0.054 |
| 8 | 52.35 | 0.056 |
| 16 | 46.8 | 0.059 |
六、结论
本文提出了一种用于动态逻辑的新型低功耗高速设计技术,并将其与DTV、DTVS和ST‐DTV等早期功耗降低技术进行了比较。与最近的方案相比,该提出的技术显示出平均功耗最多降低12.5%,PDP改善达36.37%。栅极长度偏置技术可用于进一步降低漏电功耗,仅带来较小的延迟代价。分析了栅极长度变化对所提出设计的漏电功耗和延迟的影响。该提出的设计技术可用于高性能微处理器的设计中,其中低功耗是一个基本要求。

















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









