







01 引言
OCR文字识别已经基本覆盖我们的日常的聊天工具,如微信、QQ等都有截图识别文字甚至直接从图片可以复制文字。开发项目中使用OCR图片识别、文案提取等经常用到。大多数小型企业都会选择云厂商的文字识别,如阿里云、百度云、腾讯云等的识别功能。
那有没有白嫖的OCR呢?当然有,但是很多的识别率并不高。今天介绍两款识别率较高的OCR项目,关键是可以部署,应用到业务项目中。
02 Umi-OCR
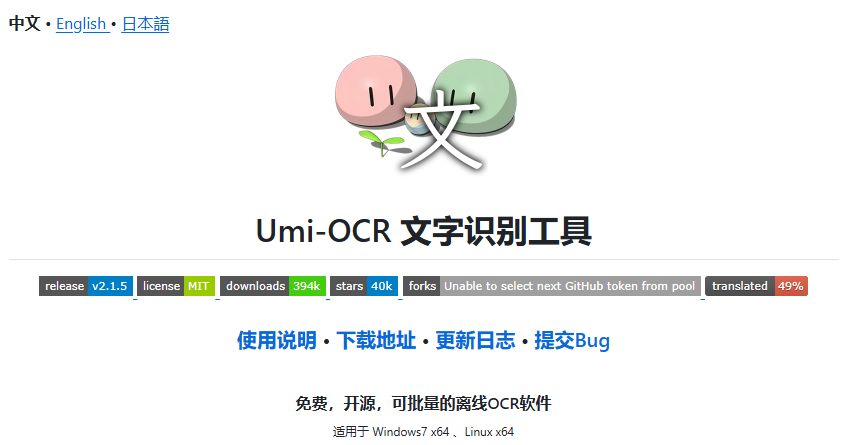
2.1 简介
Umi-OCR 是一个免费、开源、可离线的 OCR 文字识别工具,由开发者 hiroi-sora 使用 Python 编写。它的名字中 “Umi” 在日语里是“海”的意思,寓意着其“海纳百川”的特性。
该项目是基于百度开源的PaddleOCR开发,对中文和英文的识别准确率非常高,同时支持多国语言。它的主要目标是提供一个简单易用、功能强大且完全离线的图片文字识别解决方案,完美保护用户隐私,因为所有识别过程都在本地计算机上完成,无需连接任何外部服务器。
不仅支持本地部署,还支持windows系统:
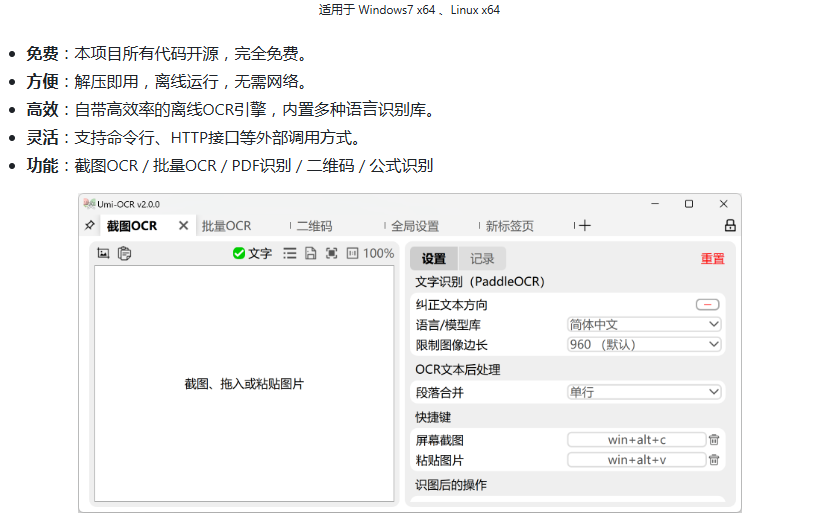
windows版本作为日常使用的工具大家可以自行探索。为了接入项目开发,我们主要了解一下本地部署的方式。
GitHub地址:https://github.com/hiroi-sora/Umi-OCR
2.2 部署
linux部署是新的项目:https://github.com/hiroi-sora/Umi-OCR_runtime_linux
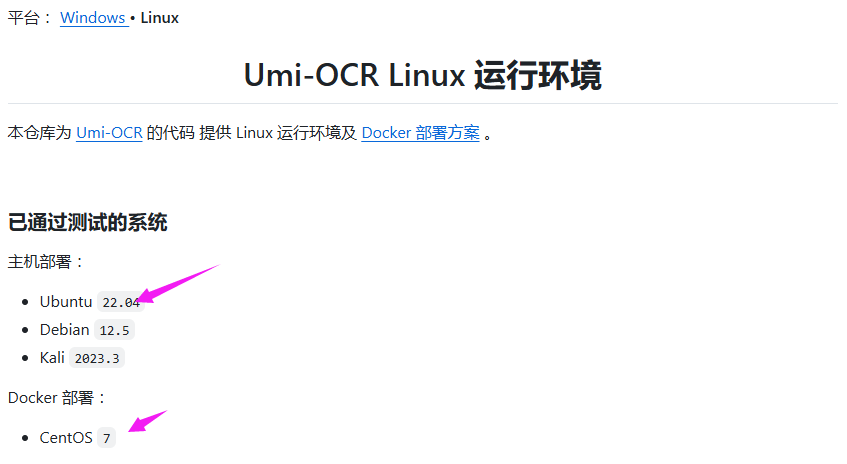
由于官方给出的测试的系统类型并没有Centos。尝试通过Centos8部署,结果失败:缺少一些基本组件,升级不成功。

所以这里我们使用Docker部署。
Docker部署的地址:https://github.com/hiroi-sora/Umi-OCR_runtime_linux/blob/main/README-docker.md
官方文档介绍的很明白了。
检查主机CUP
因为目前主机的CPU只支持AVX指令集。
lscpu | grep avx
如果输出了类似如下的结果,那么可以继续部署。如果没有则无法部署
Flags: ... avx ... avx2 ...

所以小编的机器是可以部署的。
构建镜像
由于远程镜像仓库里面没有上传,需要使用Dockerfile自行构建。
# 拉取Dockerfile文件
wget https://raw.githubusercontent.com/hiroi-sora/Umi-OCR_runtime_linux/main/Dockerfile
# 构建镜像
docker build -t umi-ocr-paddle .
umi-ocr-paddle表示构建的镜像名称。
启动容器
容器的运行支持无头模式和GUI模式。因为我们是为了项目的调用,所以这里我们使用悟透模式。
docker run -d --name umi-ocr \
-e HEADLESS=true \
-p 1224:1224 \
umi-ocr-paddle
说明:
- 设置容器名称为
umi-ocr。你也可以设置为任意名称。 - 设置环境变量
-e HEADLESS=true启用无头模式。 - 设置端口转发
-p xxxx:1224,将容器内的1224端口转发给主机xxxx端口。 - 使用的镜像为
umi-ocr-paddle。
2.3 接口调用
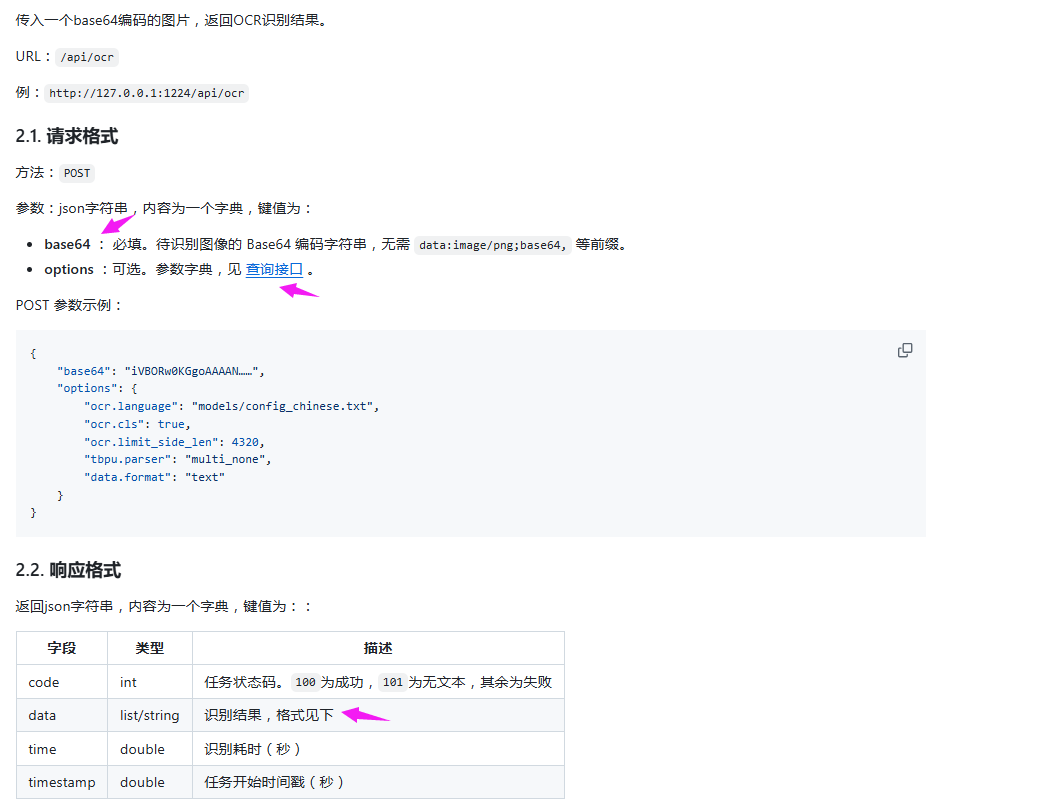
官方提供了HTTP接口手册:
https://github.com/hiroi-sora/Umi-OCR/blob/main/docs/http/README.md

我们这里以图片OCR:Base64识别为例:
Java案例
@Test
void test04() throws Exception {
File file = new File("C:\\Users\\ws\\Desktop\\00.jpg");
String encode = Base64.encode(Files.toByteArray(file));
JSONObject jsonObject = new JSONObject();
jsonObject.put("base64", encode);
JSONObject item = new JSONObject();
// item.put("ocr.language", "models/config_chinese.txt");
// item.put("ocr.cls", true);
// item.put("ocr.limit_side_len", 4320);
// item.put("tbpu.parser", "multi_none");
item.put("data.format", "text");
// item.put("data.format", "dict");
jsonObject.put("options", item);
String post = HttpUtil.post("http://127.0.0.1:1224/api/ocr", JSON.toJSONString(jsonObject));
System.out.println(post);
System.out.println("----------------------------------------------");
System.out.println(UnicodeUtil.toString(post));
}
结果
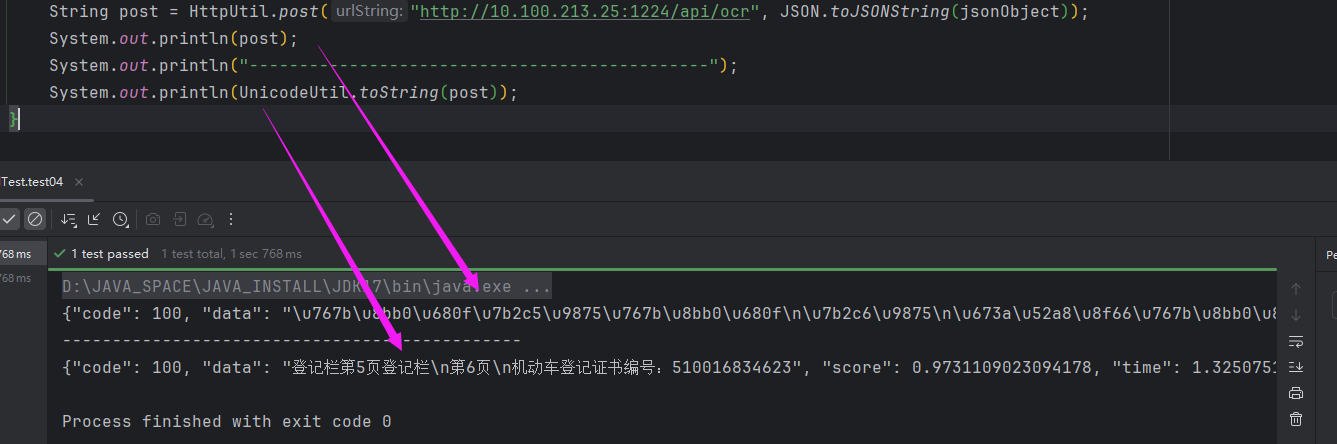
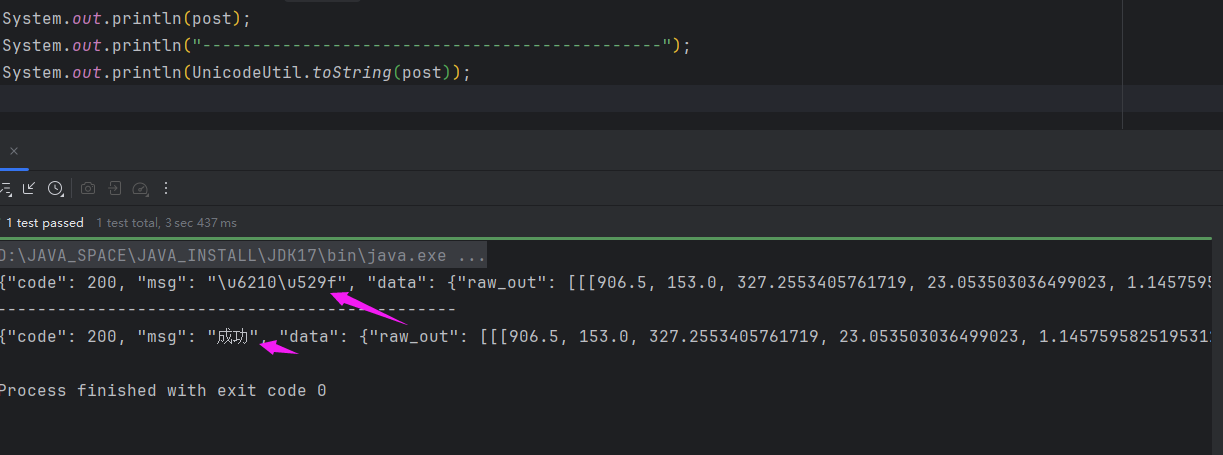
结果是识别出来了,但是有个小问题。第一行输出是unicode,需要我们将unicode转成中文。
03 TrWebOCR
3.1 简介
TrWebOCR基于开源项目 Tr 构建,目前已经停更了,tr官方说了项目转为研究性项目:
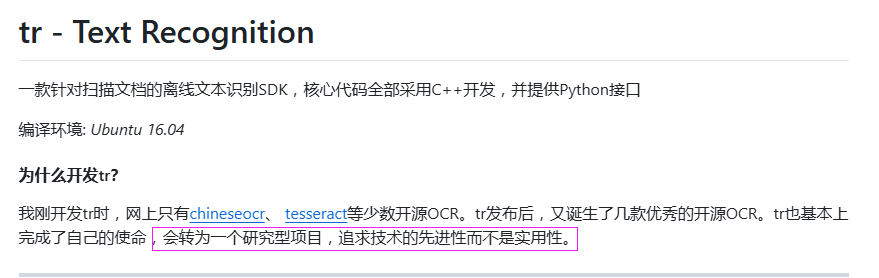
但是它仍然是一款好用的OCR工具。支持的平台比较多:

GitHub地址:https://github.com/alisen39/TrWebOCR
3.2 部署
我们同样以Docker的形式部署。这个就比较简单了,可以自行构建镜像,也可以拉取镜像。
构建镜像
# dockerfile 构建
docker build -t trwebocr:latest .
# 运行镜像
docker run -itd --rm -p 8089:8089 --name trwebocr trwebocr:latest
远程镜像
# 从 dockerhub pull
docker pull mmmz/trwebocr:latest
# 运行镜像
docker run -itd --rm -p 8089:8089 --name trwebocr mmmz/trwebocr:latest
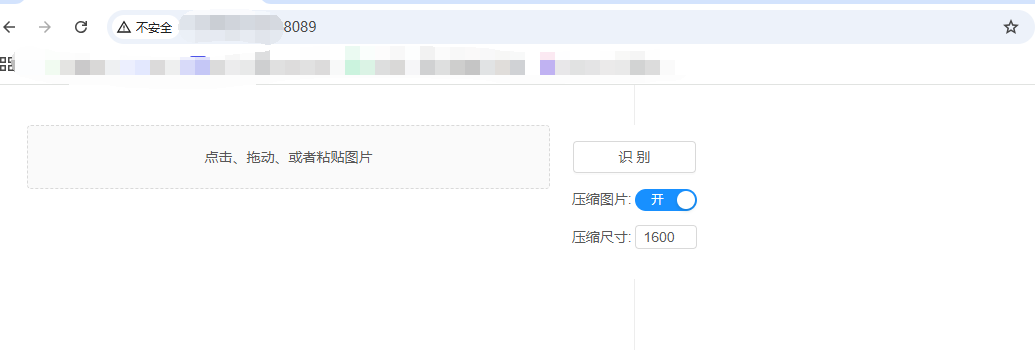
访问IP+端口,提供了网页端:
3.3 接口调用
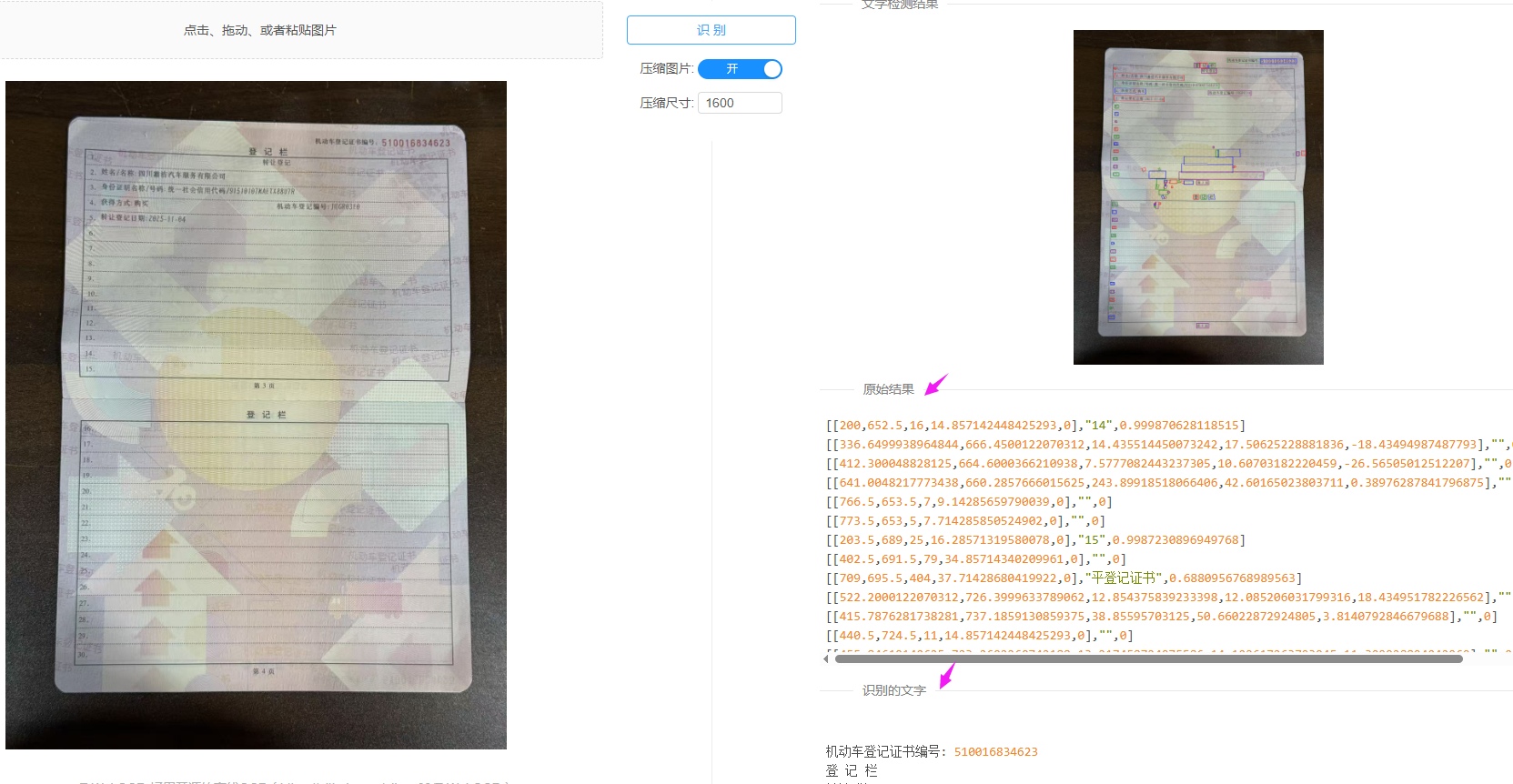
我们先试试网页端:
接口文档地址:
https://github.com/alisen39/TrWebOCR/wiki/%E6%8E%A5%E5%8F%A3%E6%96%87%E6%A1%A3
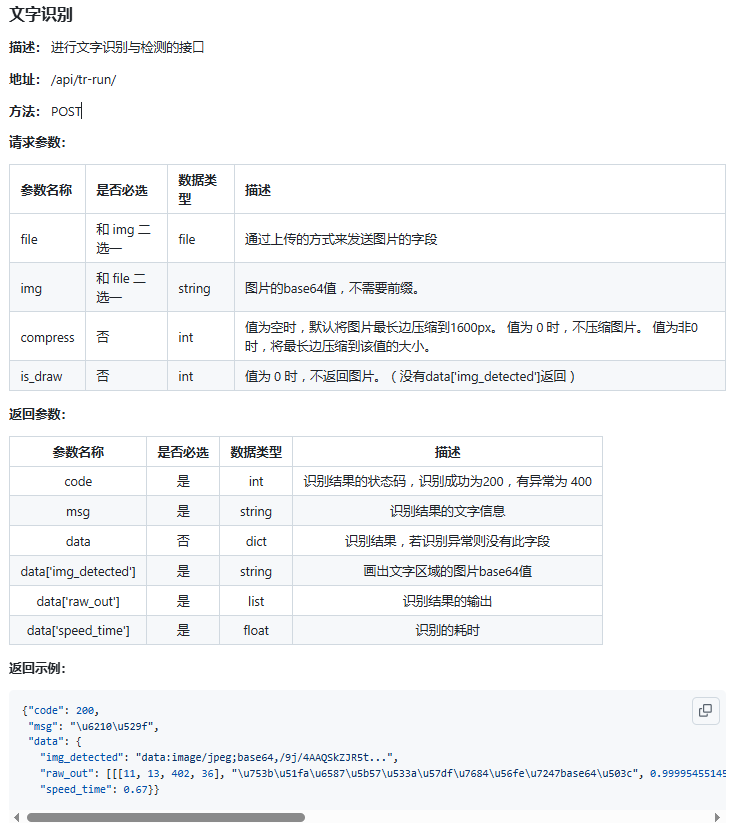
Java案例
@Test
void test07() {
File file = new File("C:\\Users\\ws\\Desktop\\34.png");
JSONObject item = new JSONObject();
item.put("file", file);
item.put("is_draw", 0);
String post = HttpUtil.post("http://127.0.0.1:8089/api/tr-run/", item);
System.out.println(post);
System.out.println("----------------------------------------------");
System.out.println(UnicodeUtil.toString(post));
}
结果
04 小结
第二款虽然停更,但是已有的功能可以满足常用的OCR识别。而第一款一直活跃在GitHub上,是一款非常值得关注的项目,不断的迭代新的功能。有特殊要求的OCR可以利用开源模型自行训练。


















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











