




【GPT入门】第41课 Model Scope在线平台部署Llama3
1. 硬件配置分析
在本地对8B版本的Llama3进行部署测试,最低硬件配置为
- CPU: Intel Core i7 或 AMD 等价(至少 4 个核心)
- GPU: NVIDIA GeForce GTX 1060 或 AMD Radeon RX 580(至少 6 GB VRAM)
- 内存: 至少 16 GB 的 RAM
- 操作系统: Ubuntu 20.04 或更高版本,或者 Windows 10 或更高版本
2.Llama3模型介绍
Llama3是Meta于2024年4月18日开源的LLM,目前开放了8B和70B两个版本,两个版本均支持最
大为8192个token的序列长度( GPT-4支持128K )
Llama3在Meta自制的两个24K GPU集群上进行预训练,使用15T的训练数据,其中5%为非英文数
据,故Llama3的中文能力稍弱,Meta认为Llama3是目前最强的开源大模型。
3.Model Scope在线平台部署Llama3
3.1 下载模型
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# 下载模型参数
model_dir=snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')
print(model_dir)
查看模型大小:30G

3.2 加载模型
# 使用transformer加载模型
# 这行设置将模型加载到 GPU 设备上,以利用 GPU 的计算能力进行快速,
model_dir = '/mnt/workspace/.cache/modelscope/hub/models/LLM-Research/Meta-Llama-3-8B-Instruct'
device ="cuda"
# 加载了一个因果语言模型。
# model dir 是模型文件所在的目录。# torch_dtype="auto" 自动选择最优的数据类型以平衡性
#能和精度。# device_map="auto" 自动将模型的不同部分映射到可用的设备上。
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype='auto',device_map="auto")
# 加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
tokenizer = AutoTokenizer.from_pretrained(model_dir)
pip install nvitop 用于查看gpu使用情况
nvitop 命令:直接查看
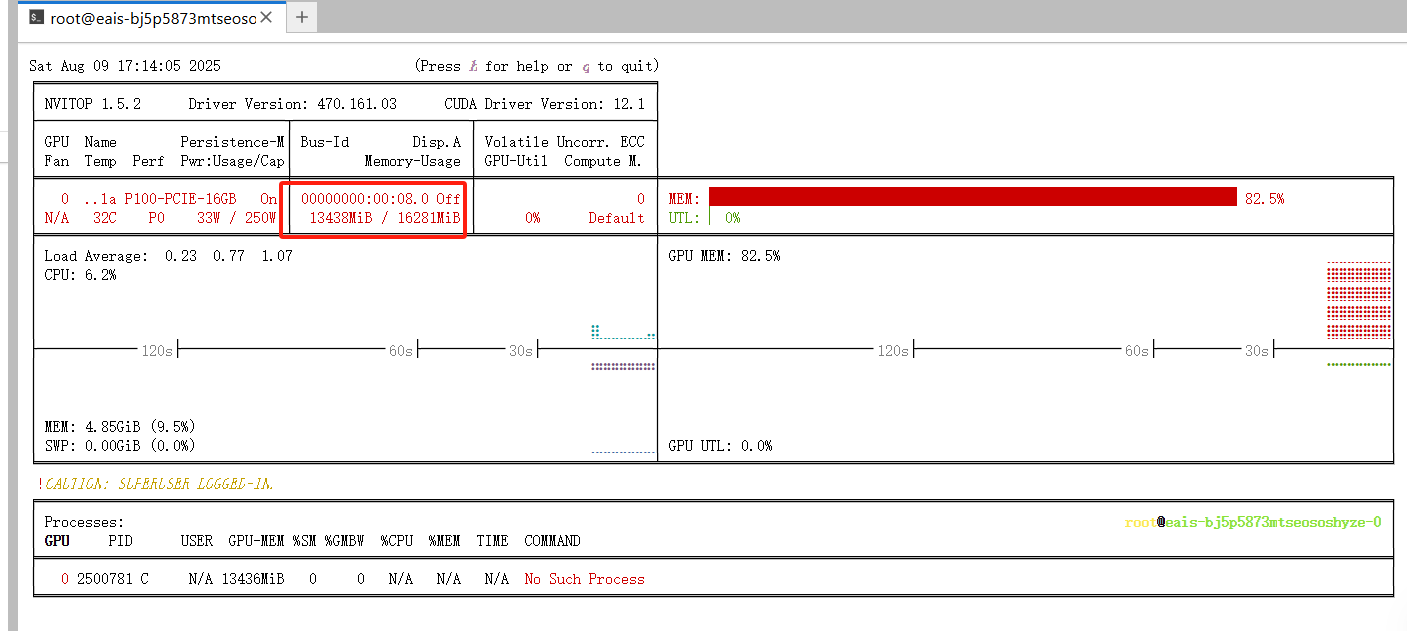
3.3 调用模型
#加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
prompt="你好,请介绍下你自己。"
messages=[{'role':'system','content':'You are a helpful assistant system'},
{'role': 'user','content': prompt}]
# 使用分词器的 apply_chat_template 方法将上面定义的消,息列表转护# tokenize=False 表
#示此时不进行令牌化,add_generation_promp
text =tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
#将处理后的文本令牌化并转换为模型输入张量,然后将这些张量移至之前
model_inputs=tokenizer([text],return_tensors="pt").to('cuda')
print(text)
print('-------------------')
print(model_inputs)
输出
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant system<|eot_id|><|start_header_id|>user<|end_header_id|>
你好,请介绍下你自己。<|eot_id|><|start_header_id|>assistant<|end_header_id|>
-------------------
{'input_ids': tensor([[128000, 128000, 128006, 9125, 128007, 271, 2675, 527, 264,
11190, 18328, 1887, 128009, 128006, 882, 128007, 271, 57668,
53901, 39045, 117814, 17297, 57668, 102099, 1811, 128009, 128006,
78191, 128007, 271]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1]], device='cuda:0')}
预测:
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 对输出进行解码
response=tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_ids)
print('---------------')
print(response)
查看输出:
tensor([[128000, 128000, 128006, 9125, 128007, 271, 2675, 527, 264,
11190, 18328, 1887, 128009, 128006, 882, 128007, 271, 57668,
53901, 39045, 117814, 17297, 57668, 102099, 1811, 128009, 128006,
78191, 128007, 271, 76460, 232, 271, 46078, 311, 3449,
499, 0, 358, 2846, 264, 11190, 18328, 1887, 11,
6319, 311, 7945, 323, 19570, 449, 499, 304, 264,
5933, 323, 7669, 1697, 1648, 13, 358, 2846, 264,
5780, 6975, 1646, 16572, 389, 264, 13057, 3392, 315,
1495, 828, 11, 902, 20682, 757, 311, 3619, 323,
6013, 311, 264, 7029, 2134, 315, 4860, 11, 13650,
11, 323, 9256, 382, 40, 649, 1520, 449, 1473,
16, 13, 22559, 287, 4860, 25, 358, 649, 3493,
2038, 389, 5370, 13650, 11, 505, 8198, 323, 3925,
311, 16924, 323, 7829, 627, 17, 13, 97554, 1495,
25, 358, 649, 1520, 449, 4477, 323, 11311, 6285,
11, 439, 1664, 439, 24038, 11782, 2262, 1093, 7493,
11, 45319, 11, 477, 1524, 4553, 9908, 627, 18,
13, 39141, 25, 358, 649, 15025, 1495, 505, 832,
4221, 311, 2500, 11, 2737, 5526, 15823, 1093, 15506,
11, 8753, 11, 6063, 11, 8620, 11, 323, 1690,
810, 627, 19, 13, 8279, 5730, 2065, 25, 358,
649, 63179, 1317, 9863, 315, 1495, 11, 1093, 9908,
477, 9477, 11, 1139, 64694, 323, 4228, 4791, 29906,
70022, 627, 20, 13, 56496, 1697, 21976, 25, 358,
649, 16988, 304, 5933, 1355, 13900, 21633, 11, 1701,
2317, 323, 8830, 311, 6013, 311, 701, 4860, 323,
12518, 382, 40, 2846, 15320, 6975, 323, 18899, 11,
779, 4587, 11984, 449, 757, 422, 358, 1304, 904,
21294, 13, 358, 2846, 1618, 311, 1520, 323, 3493,
13291, 11, 779, 2733, 1949, 311, 2610, 757, 4205,
0, 27623, 232, 128009]], device='cuda:0')
---------------
["system\n\nYou are a helpful assistant systemuser\n\n你好,请介绍下你自己。assistant\n\n😊\n\nNice to meet you! I'm a helpful assistant system, designed to assist and communicate with you in a natural and conversational way. I'm a machine learning model trained on a vast amount of text data, which enables me to understand and respond to a wide range of questions, topics, and tasks.\n\nI can help with:\n\n1. Answering questions: I can provide information on various topics, from science and history to entertainment and culture.\n2. Generating text: I can help with writing and proofreading, as well as generating creative content like stories, poems, or even entire articles.\n3. Translation: I can translate text from one language to another, including popular languages like Spanish, French, German, Chinese, and many more.\n4. Summarization: I can summarize long pieces of text, like articles or documents, into concise and easy-to-read summaries.\n5. Conversational dialogue: I can engage in natural-sounding conversations, using context and understanding to respond to your questions and statements.\n\nI'm constantly learning and improving, so please bear with me if I make any mistakes. I'm here to help and provide assistance, so feel free to ask me anything! 😊"]
查看模型GPU使用情况
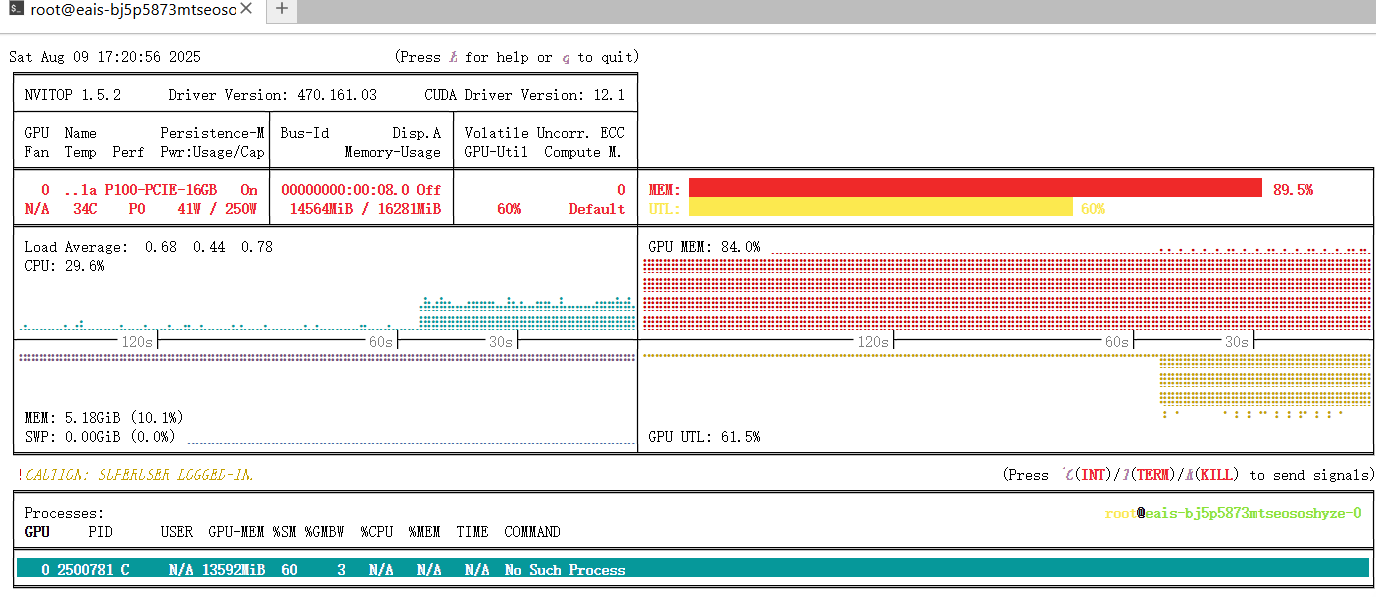
总结:
至此,完成了LLAMA3的模型部署,从测试的结果可以看到, llama3的基础模型对于中文的支持并不
好,我们的问题是中文,它却返回了英文的结果,原因可能是因为它的训练集有15个T但是其中95%是
英文,想要它支持中文更好,还需要使用中文的训练集进行微调,可喜的是,微调llma系列的中文训练
集并不少(可能是因为llama系列都有这个问题)

















 2384
2384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









