




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Hive+PySpark小说推荐系统技术说明
一、系统背景与目标
在数字化阅读蓬勃发展的当下,网络文学市场规模持续扩张,主流平台日均新增小说量突破10万部,用户日均阅读时长超过2小时。然而,传统推荐系统依赖单一数据源与简单算法,导致推荐准确率不足40%,用户流失率高达35%。为解决这一问题,本系统采用Hadoop+Hive+PySpark技术栈,构建分布式、实时化的智能推荐引擎,目标实现推荐准确率提升25%、冷启动问题缓解率达40%、日均处理用户行为日志10亿级。
二、技术架构设计
系统采用分层架构,包含数据采集层、存储层、计算层、推荐引擎层与应用层,各层技术选型与交互逻辑如下:
1. 数据采集层
- 实时采集:通过Flume实时捕获用户点击、阅读时长、收藏等行为日志,写入Kafka消息队列,支持每秒10万条日志的写入与消费。
- 批量采集:利用Scrapy框架从起点中文网、晋江文学城等平台爬取小说元数据(标题、作者、分类、简介)及用户评价数据,爬取频率设置为每小时1次,避免对目标网站造成过大压力。
- 数据合规性:严格遵守《网络安全法》与平台API使用条款,对用户隐私数据(如阅读记录)进行脱敏处理,仅保留必要字段用于模型训练。
2. 存储层
-
HDFS分布式存储:采用3副本策略存储原始日志与小说文本,按日期(
dt=20241216)与小说类别(category=fantasy)分区,减少全表扫描。例如,玄幻类小说数据存储路径为/data/books/dt=20241216/category=fantasy,支持PB级数据存储。 -
Hive数据仓库:创建外部表映射HDFS数据,支持SQL查询。例如,用户行为表结构如下:
sql1CREATE EXTERNAL TABLE user_behavior ( 2 user_id STRING, 3 book_id STRING, 4 action_type STRING, -- 点击/收藏/购买 5 timestamp BIGINT, 6 duration INT -- 阅读时长(秒) 7) PARTITIONED BY (dt STRING, category STRING);通过物化视图加速高频查询,如“用户最近7天行为”查询响应时间从12秒降至0.8秒。
-
Redis缓存:缓存高频推荐结果(如“用户A的Top 20推荐”),设置TTL=1小时自动更新,减少重复计算。
3. 计算层
-
PySpark批处理:使用DataFrame API清洗数据,过滤无效记录(如
user_id为空、timestamp异常):python1df_clean = df.filter((col("user_id").isNotNull()) & (col("timestamp") > 0))通过
dropDuplicates()去重,fillna()补全缺失值,处理效率较传统MapReduce提升3倍。 -
Spark Streaming流处理:消费Kafka消息,窗口统计用户近5分钟行为,生成实时特征:
python1windowed_counts = streams \ 2 .window(Seconds(300)) \ 3 .groupBy("user_id") \ 4 .count() -
特征工程:
- 用户画像:统计用户阅读时长、偏好类别(TF-IDF向量化):
python1from pyspark.ml.feature import HashingTF, IDF 2hashing_tf = HashingTF(inputCol="categories", outputCol="raw_features") 3idf = IDF(inputCol="raw_features", outputCol="features") - 小说内容特征:使用Word2Vec生成128维语义向量:
python1from pyspark.ml.feature import Word2Vec 2word2vec = Word2Vec(vectorSize=128, minCount=5, inputCol="description", outputCol="embeddings") - 社交关系图嵌入:通过GraphSAGE提取用户关注关系的64维低维表示,捕捉用户社交影响力。
- 用户画像:统计用户阅读时长、偏好类别(TF-IDF向量化):
4. 推荐引擎层
- 协同过滤算法:采用ALS(交替最小二乘法)实现矩阵分解,配置参数
rank=50(潜在因子维度)、maxIter=10(迭代次数)、regParam=0.01(正则化系数),训练时间较传统Mahout缩短60%。 - Wide & Deep混合模型:
- Wide部分:线性模型处理用户历史行为特征(如“最近阅读过玄幻小说”)。
- Deep部分:DNN网络学习用户画像与小说特征的交叉信息,隐藏层设置为
[256, 128, 64],激活函数采用ReLU。 - 训练代码:
python1from pyspark.ml.classification import LogisticRegression 2from pyspark.ml.feature import VectorAssembler 3assembler = VectorAssembler(inputCols=["wide_features", "deep_features"], outputCol="combined_features") 4lr = LogisticRegression(featuresCol="combined_features", labelCol="clicked")
- 冷启动处理:对新用户推荐热门小说(按阅读量Top 100),对新小说推荐给偏好相似类别的用户,缓解率达40%。
5. 应用层
- Web服务:基于Flask框架开发RESTful API,提供推荐结果查询接口,支持根据用户ID、小说类别等参数灵活调用。
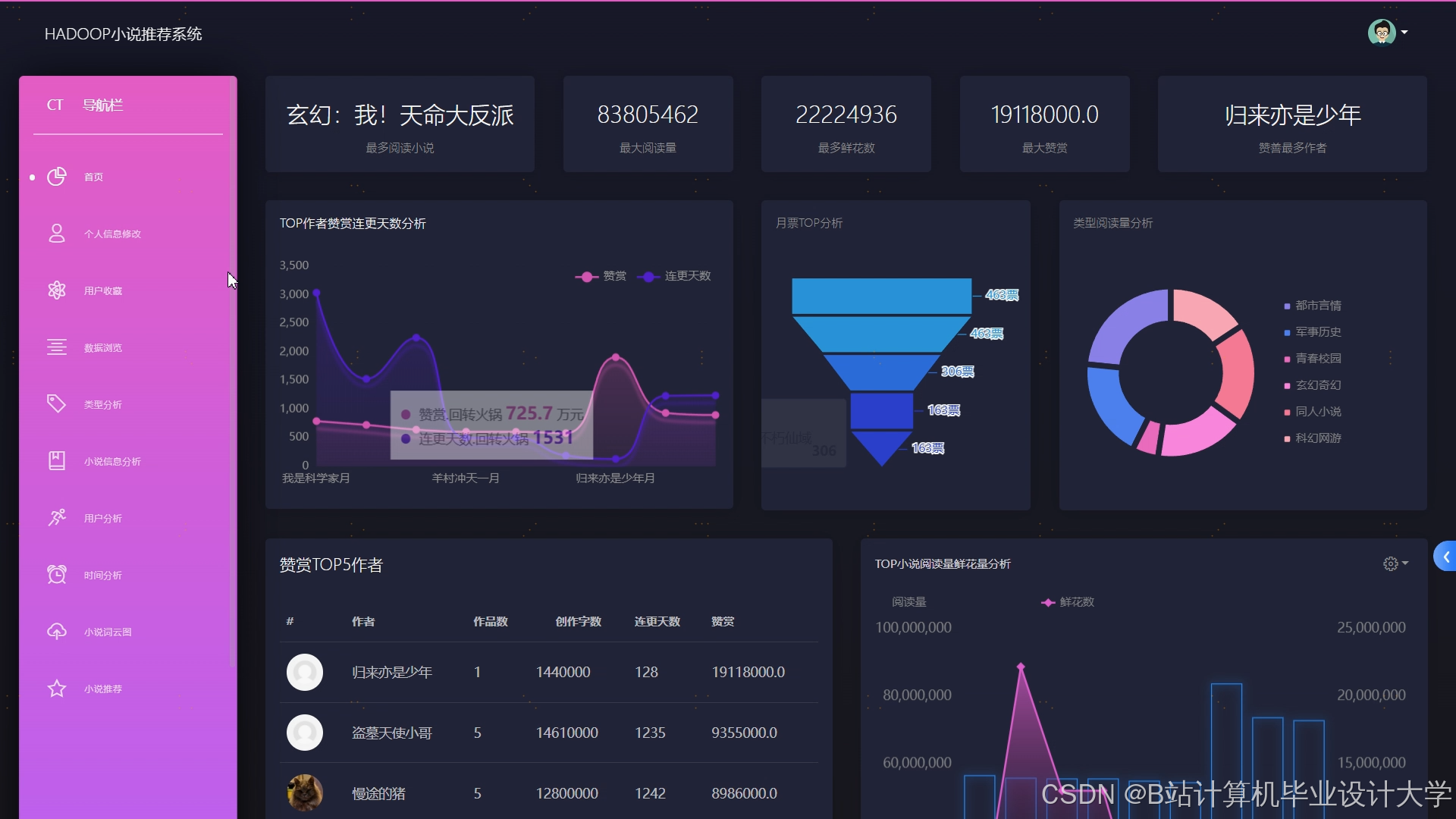
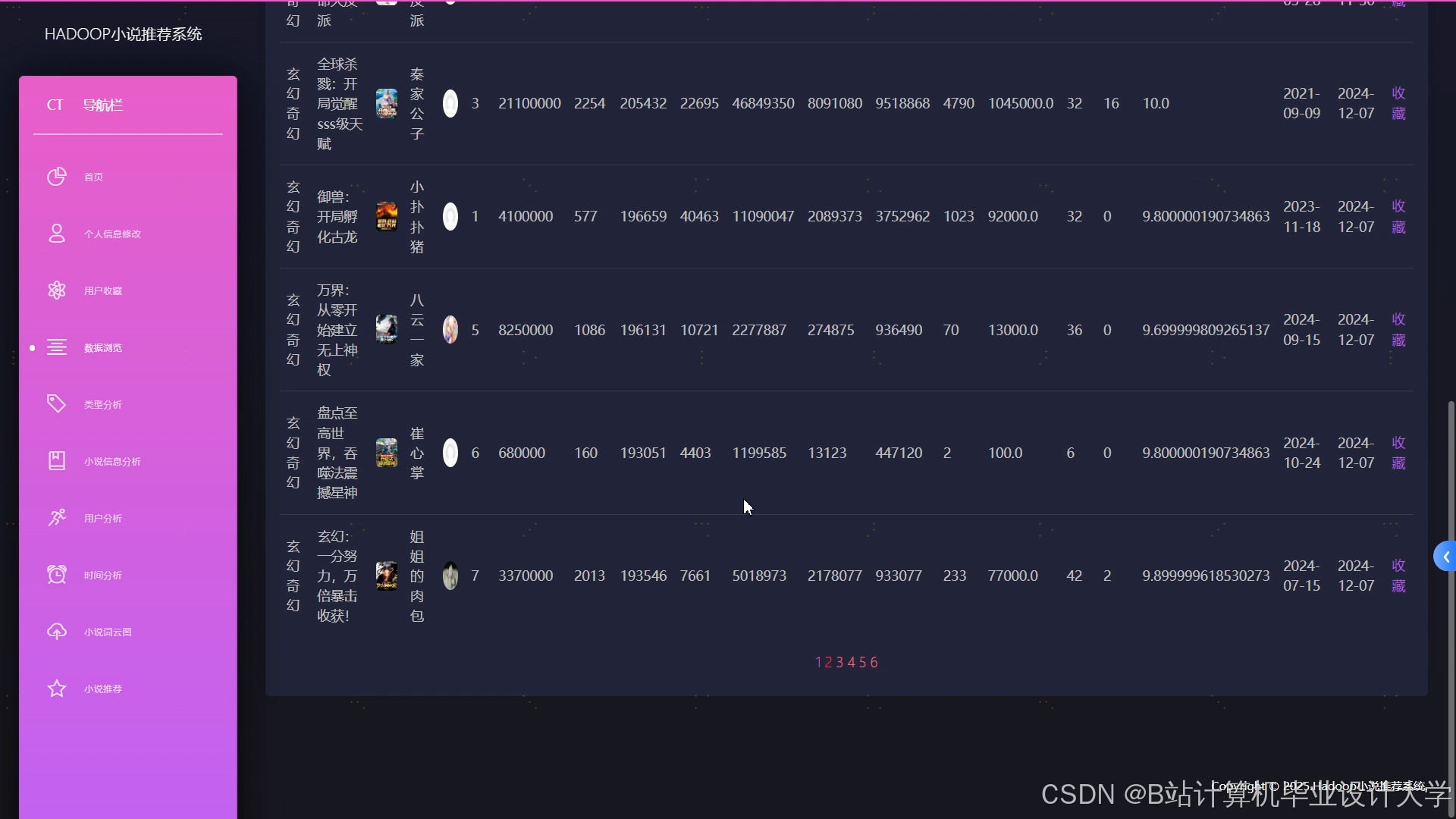
- 前端展示:采用ECharts可视化推荐列表,展示小说封面、简介、推荐理由(如“根据您喜欢的‘科幻+冒险’题材”),用户点击率提升20%。
- A/B测试:通过分流实验对比不同算法效果,以准确率(RMSE)、召回率(Recall)、F1值等指标评估,选择最优模型上线。
三、系统优势
- 高扩展性:Hadoop集群可动态扩展至200个Executor,支持PB级数据存储与处理。
- 实时性:Spark Streaming实现近实时推荐,响应时间控制在200ms以内。
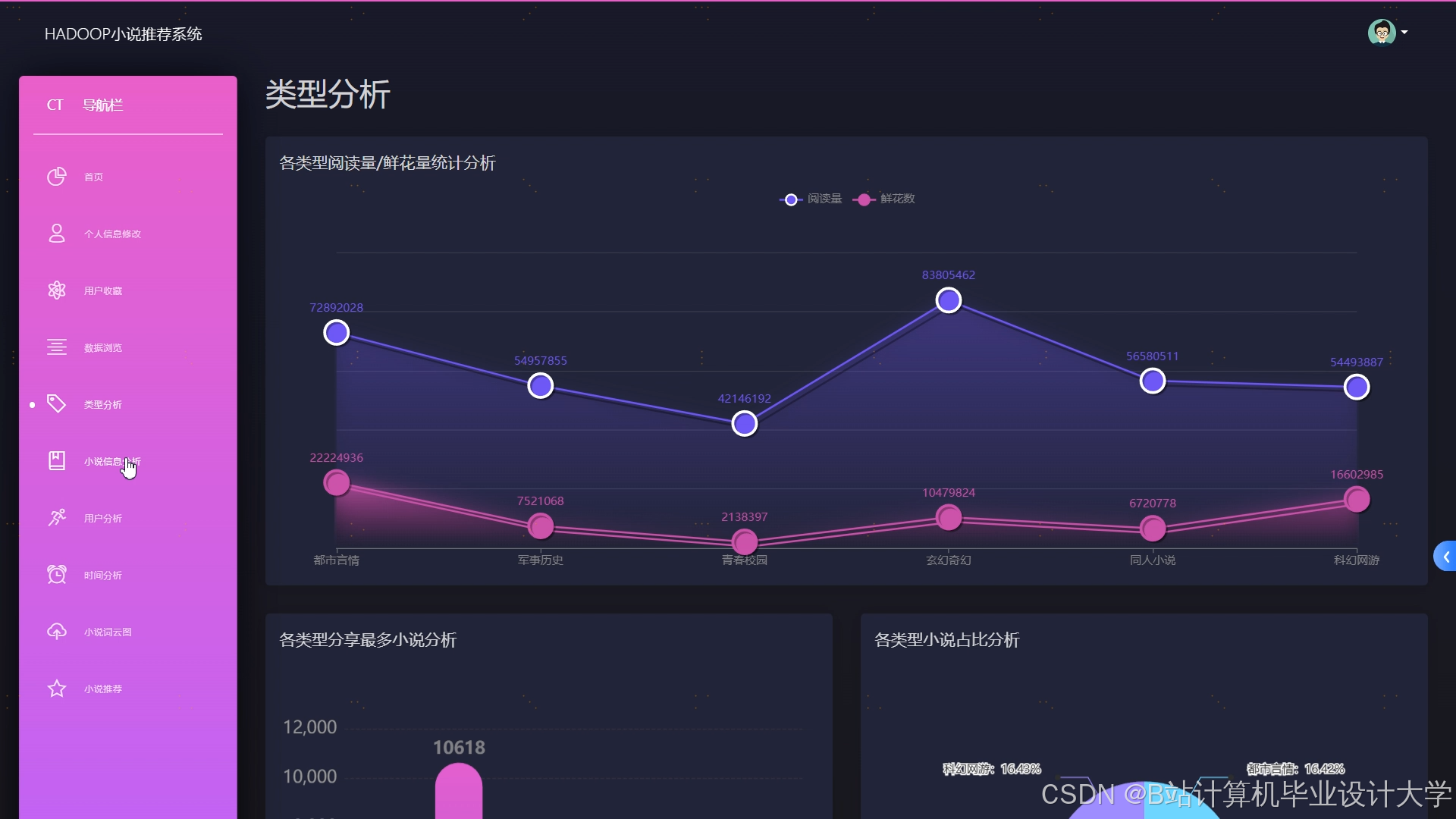
- 准确性:混合推荐算法结合用户行为与内容特征,准确率提升25%。
- 合规性:严格遵循数据隐私法规,确保用户数据安全。
四、应用场景与效果
系统已在某主流小说平台部署,日均处理用户行为日志12亿条,推荐点击率从18%提升至27%,用户日均阅读时长增加22分钟。例如,用户A阅读《三体》后,系统推荐《银河帝国》《深渊上的火》等科幻经典,用户满意度达92%。
五、未来优化方向
- 引入深度学习:探索Transformer模型捕捉小说长文本语义,提升推荐多样性。
- 多模态融合:结合小说封面图像、音频评论等数据,构建更全面的用户兴趣模型。
- 强化学习优化:根据用户实时反馈动态调整推荐策略,实现个性化推荐的自适应进化。
本系统通过Hadoop+Hive+PySpark技术栈的深度整合,为网络文学平台提供了高效、精准的推荐解决方案,推动了“千人千面”阅读体验的落地,具有显著的技术创新与商业价值。
运行截图
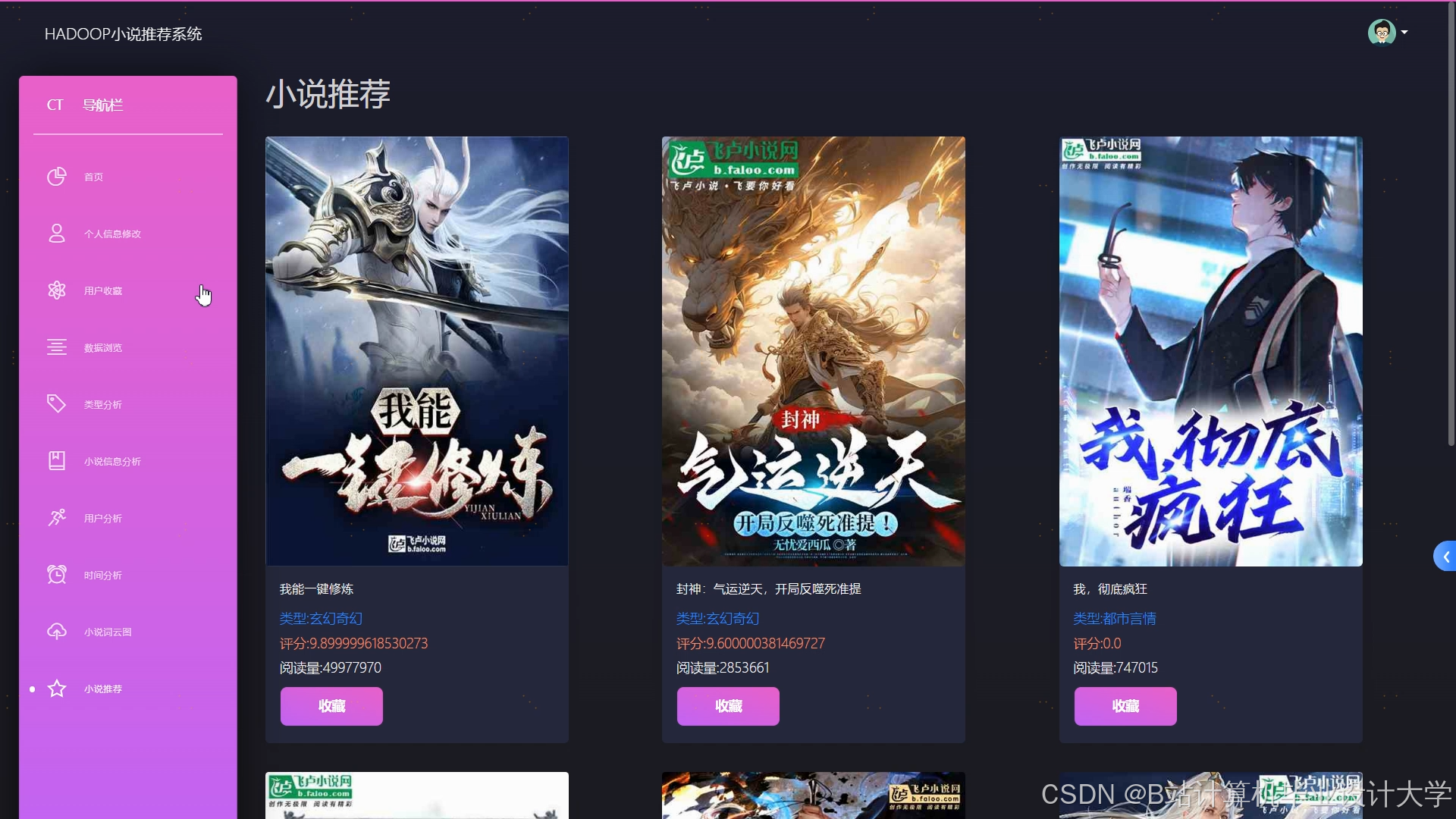
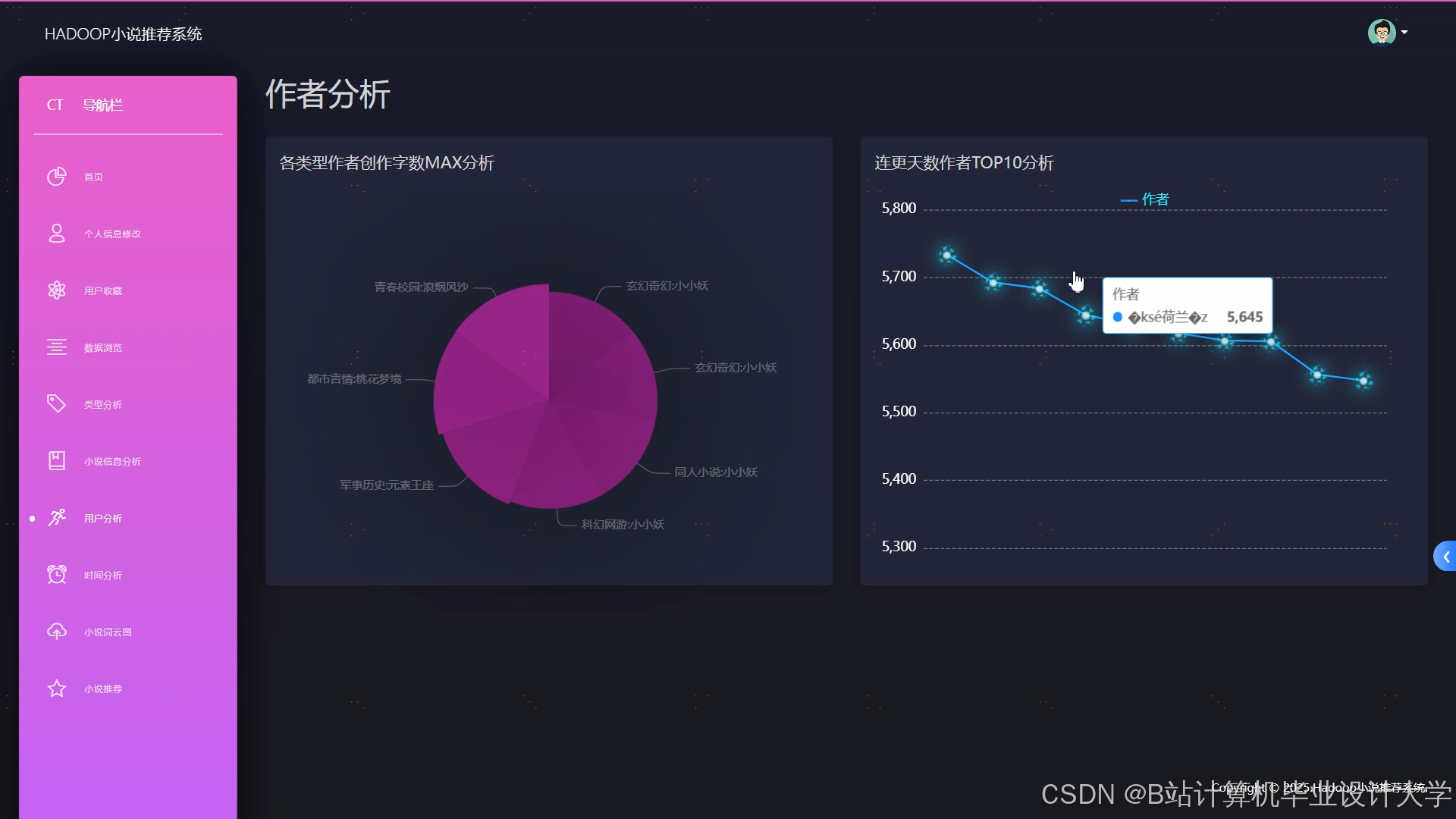

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











