



一、什么是EPICS ARCHIVER APPLIANCE?
Archiver是一款基于JAVA的开源数据归档系统。专门用于长期采集、存储和检索EPICS控制系统中的实时数据(主要是高性能检索)。核心功能包括:
1.数据采集:支持大规模PV(过程变量)监控,可同时采集数万个PV,采集策略灵活(周期触发/阈值触发)。通过Channel Access/PVAccess协议与EPICS IOC通信
2.存储架构:分层存储设计。短期存储将最近1小时的数据存储在内存中;中期存储将最近1天的数据存储在本地硬盘;长期存储将一年的数据存储在分布式数据库或网络存储中。支持高压缩和荣誉存储,确保数据可靠性。
3.数据管理:通过Extract\Transform\Load模块实现数据在不同存储层的迁移,支持数据抽取和特征值(最大/最小/平均)生成,以提高检索效率。
4.检索服务:提供web界面和API接口查询历史数据
部署方式:部署在tomcat服务器,包含四个核心组件:Engine负责数据采集和归档(该组件为设备中的每个PV建立EPICS通道访问监视器。数据被写入STS。该组件基于CS-Studio引擎)、ETL数据存储和迁移(从STS传输到MTS,以及从MTS传输到LTS)、DataRetrieval数据查询请求(该组件从所有存储中收集数据,将它们拼接在一起以满足数据检索请求)、Management提供配置和管理页面( 该组件执行业务逻辑,管理其他三个组件并保存运行时配置状态)。
二、系统要求
1.LINUX系统:redhat6.1
2.JDK16
3.tomcat11.0.12之后+
4.firefox
5.mysql5.1以后
三、关键特性
1.集群化部署与扩展
2.多级存储架构:快存、中存、长存
3.数据迁移与降采样机制
4.简化的WEB管理页面和脚本化管理
5.易于集成和定制
6.提供从channel Archiver迁移路径
四、架构设计
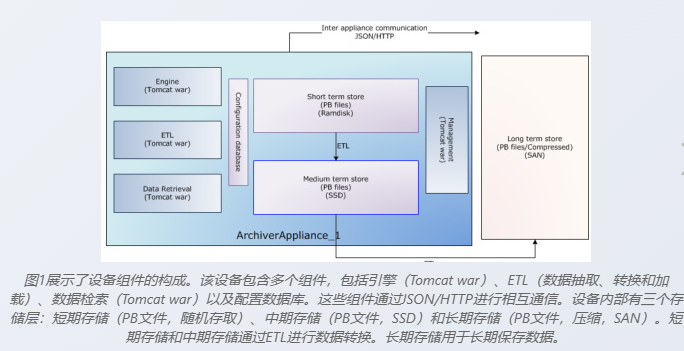
存储阶段 (可按PV配置):
STS (短期存储): 最近几小时数据,通常为RAM磁盘。
MTS (中期存储): 最近几天数据,使用RAID或镜像SAS硬盘。
LTS (长期存储): 其余数据,使用租用的批量存储(如GFPS/NFS挂载)或NetApp等。
核心进程 (J2EE WAR文件, Tomcat容器):
Engine:建立EPICS通道访问监控,写入STS。基于CS-Studio引擎。
ETL:在存储间移动数据(STS->MTS, MTS->LTS),可进行数据降采样。
Retrieval:从所有存储中收集数据,拼接响应查询请求。
Mgmt:执行业务逻辑,管理其他组件,保存运行时配置。
通信: 组件间通过JSON/HTTP通信。
配置: 存储在MySQL数据库(每个设备独立)。
六、序列化机制
配置: 每个PV的归档配置存储为JSON对象,包含采样模式、速率及数据存储列表。

实现: 使用存储插件(Storage Plugins)实现数据存储,遵循标准接口。
默认插件: PlainPBStoragePlugin。
序列化: 使用Google Protocol Buffers (PB)。
- 提供未来兼容性,支持多种语言绑定。
- EPICS V3 DBR类型映射到特定PB消息。
- EPICS V4 NTScalars/NTScalarArrays映射到V3对应PB消息。
- 其他V4类型使用V4序列化存储为通用PB消息。
数据块 (Chunk): 存储序列化PB消息,每行一个样本。
•样本按记录处理时间戳排序(单调递增)。
•块键基于PV名和时间分区(如 `EIOC/L130/MP01/HEARTBEAT:2012_08_24_16.pb`)。
•分区边界严格,块键信息足以识别数据边界。
•默认存储为文件,块键作文件名。
优势: 无需索引即可进行搜索算法优化(未来可扩展)。
存储效率: 平均每个PB ScalarDouble约消耗21字节(含时间戳、值、状态、严重性等)。
七、PV归档工作流
流程:
- 用户请求: 请求归档PV。
- 信息采集: Mgmt和Engine组件采样PV,获取事件率、存储率、PV字段(NAME, ADEL, MDEL, RTYP等)。
- 策略评估: 将信息传递给安装特定的Python策略脚本。
- 配置决策: 策略脚本根据信息做出配置决定(例如:波形采样率不超过1Hz;AI记录归档VAL、HIHI、LOLO字段)。

八、数据检索
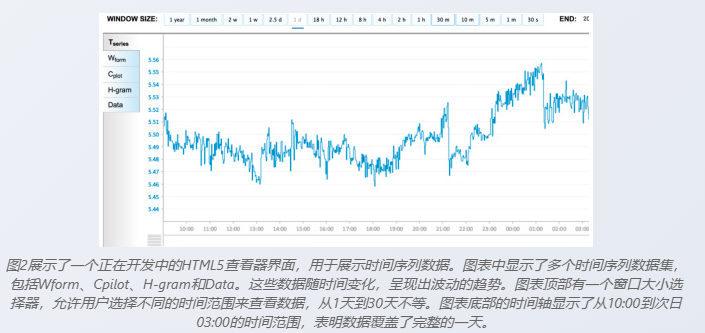
性能数据 :
>75% 请求时间跨度 < 1天,平均响应时间 < 100ms。
时间跨度达1周,平均响应时间约 250ms。
时间跨度达1年,带数据降采样,可在几秒内完成(例如:运行时将3000万样本合并为约8000个样本)。
协议与格式
HTTP,支持多种MIME类型:
RAW:二进制格式,最小化PB格式转换。提供Java/Python库,carchivetools支持。
JSON, CSV, MAT, TXT, SVG:
支持Matlab, Python, Excel, JMP等工具。
URL构建: URL仅包含PV名、开始和结束时间。
集群路由 : 请求可发送到集群中的任意设备,设备负责路由/代理。
负载均衡 : 可在集群前使用负载均衡器(如 mod_proxy_balancer)。
数据检索;将数据导入工具的第一步是构建数据检索URL;该URL仅包含PV名称以及数据检索请求的开始和结束时间。数据检索请求和业务逻辑请求都可以分发到集群中的任意随机设备(图4);该设备具备相应功能,可对请求进行路由/代理
九、降采样
根据需求,有多种降采样策略
实现
- 支持在检索时处理数据。
- 提供典型统计运算符(均值、标准差等)。
- 运算符将数据分箱(binning),然后对箱应用运算。

效果
可在快速存储中保存几天全速率数据,然后在迁移到慢速存储时进行降采样。
十、管理
通过JSON/HTTP与设备交互,调用Web服务接口。
•Web UI (图6): 提供常见配置任务界面。
•脚本化: 所有Web服务调用也可通过外部脚本(如Python)使用。
•丰富业务逻辑: 用户可添加/修改/删除PV、暂停/恢复、重新分片/合并数据等。
•无需重启: 任何业务逻辑操作都不需要重启设备。
•报告: 提供多种基于静态和动态信息的报告(存储速率、断开连接的PV等)。
•脚本化管理: 报告也可通过Python脚本访问,实现集群的完全监控和管理自动化。
十一、定制化
1外观:可生成定制构建版本,满足特定站点的视觉风格。
2策略:可定制站点特定的策略脚本。
3配置存储:可替换为站点特定的配置存储方案。
参考文献:THE EPICS ARCHIVER APPLIANCE,Murali Shankar, Luofeng Li, SLAC,Proceedings of ICALEPCS2015

















 2042
2042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









