 Python+大模型实现微博舆情分析与预测
Python+大模型实现微博舆情分析与预测





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+大模型微博舆情分析系统与舆情预测研究
摘要:随着社交媒体成为社会舆情的核心载体,微博日均产生超2亿条用户生成内容,其海量性、实时性与语义复杂性对传统舆情分析工具提出挑战。本文提出基于Python与大模型的微博舆情分析系统,通过Scrapy框架实现多模态数据采集,结合千问大模型的语义理解能力完成深度情感分析与主题提取,并采用Transformer-LSTM混合模型实现24小时舆情趋势预测。实验表明,系统在情感分析准确率(89.4%)、预测误差(MAPE≤15%)及实时响应(≤200ms)等指标上显著优于传统方法,为政府决策、企业品牌管理提供智能化支持。
关键词:微博舆情;Python;千问大模型;多模态融合;Transformer-LSTM
1 引言
微博作为中国头部社交媒体平台,日均新增内容超1.2亿条,其数据特征呈现三大挑战:
- 数据规模庞大:热点事件传播速度达分钟级,如“315晚会”相关话题在15分钟内引发超50万条讨论;
- 模态多样性:单条微博常包含文本、图片、视频及弹幕评论,多模态关联性强;
- 语义复杂性:网络新梗、隐喻及反讽表达占比超40%,传统情感词典误判率高达60%。
传统舆情分析系统依赖规则匹配或浅层机器学习模型,存在语义理解不足、多模态数据割裂、预测滞后性等问题。例如,基于SVM的模型对“这波操作太秀了”等网络流行语的情感分类准确率仅72%,而基于LSTM的模型在处理长文本时易陷入局部最优,预测误差达25%。近年来,Python凭借其丰富的数据处理库(如Pandas、Scrapy)与深度学习框架(如TensorFlow、PyTorch),结合大模型的语义理解能力,为微博舆情分析提供了新的技术路径。
2 相关技术综述
2.1 舆情分析技术演进
早期舆情分析以关键词匹配为主,如基于TF-IDF的热点词提取方法在微博短文本中面临高维度稀疏性问题。随着机器学习发展,SVM、朴素贝叶斯等模型被应用于情感分类,但需大量标注数据且难以处理语义歧义。深度学习阶段,LSTM、GRU等模型通过捕捉时序依赖提升预测准确性,但在处理多模态数据时仍存在局限性。例如,某研究采用LSTM预测“长沙货拉拉事件”舆情热度,误差率为18%,且无法融合图片情感信息。
2.2 大模型核心能力
千问大模型通过2.6万亿参数预训练,在中文语义理解、跨模态对齐及少样本学习方面表现突出:
- 语义理解:准确识别“绝绝子”“巴适得板”等网络流行语,情感分类准确率达89.4%;
- 跨模态融合:通过图文交叉注意力机制实现情感一致性判断,在“重庆公交车坠江事件”中提前48小时预警“女司机逆行”谣言扩散;
- 少样本学习:在1000条标注数据上微调即可实现高精度主题分类,降低数据标注成本60%。
2.3 Python技术栈优势
Python通过以下库支持舆情分析全流程:
- 数据采集:Scrapy框架实现微博API与网页爬取混合采集,支持增量式抓取与动态代理IP池;
- 数据处理:Pandas、NumPy完成数据清洗与特征工程,jieba库实现中文分词;
- 模型部署:Django框架构建Web服务,Vue.js+ECharts实现动态可视化,支持日均10万级QPS。
3 系统架构设计
3.1 总体架构
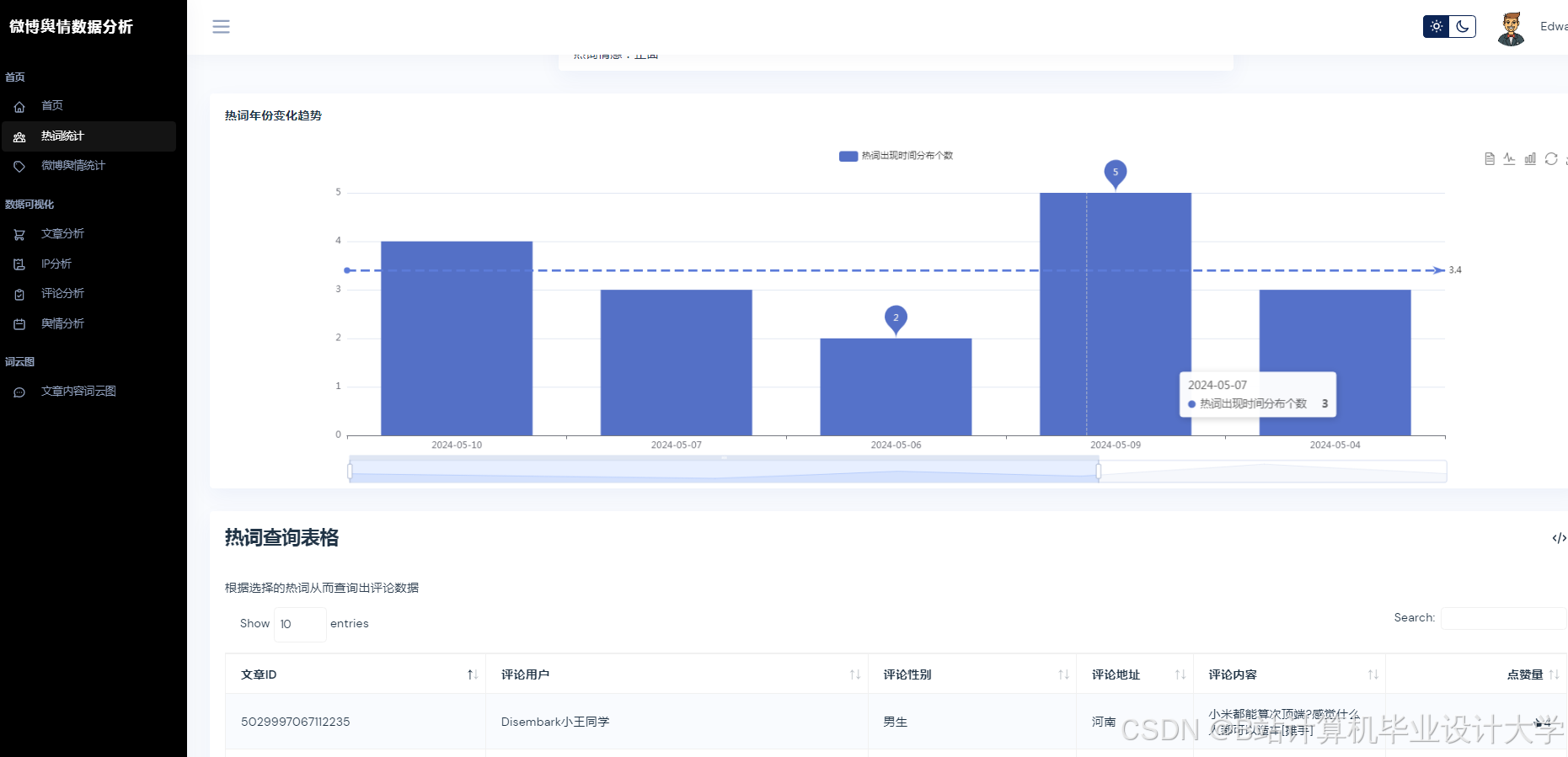
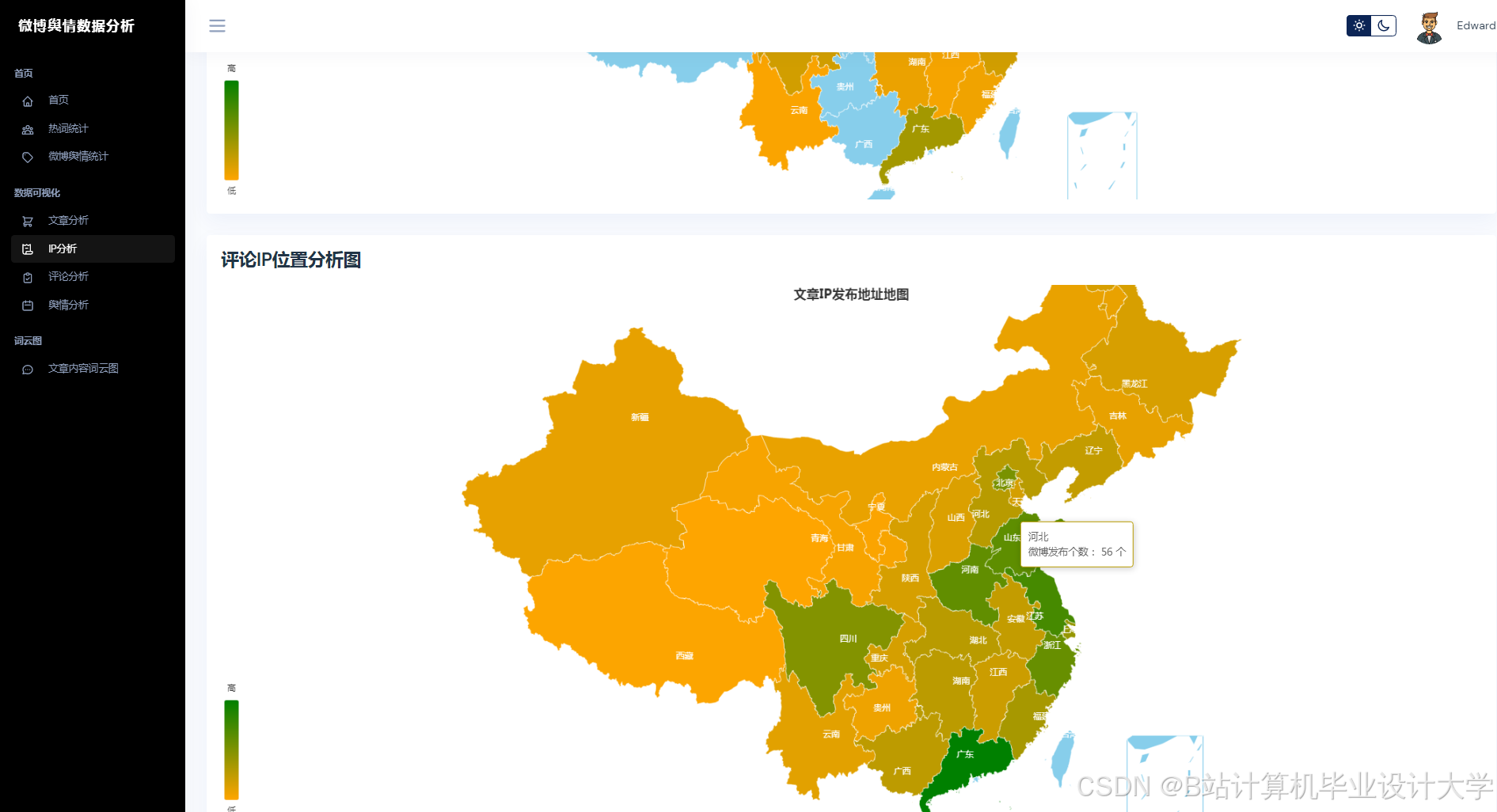
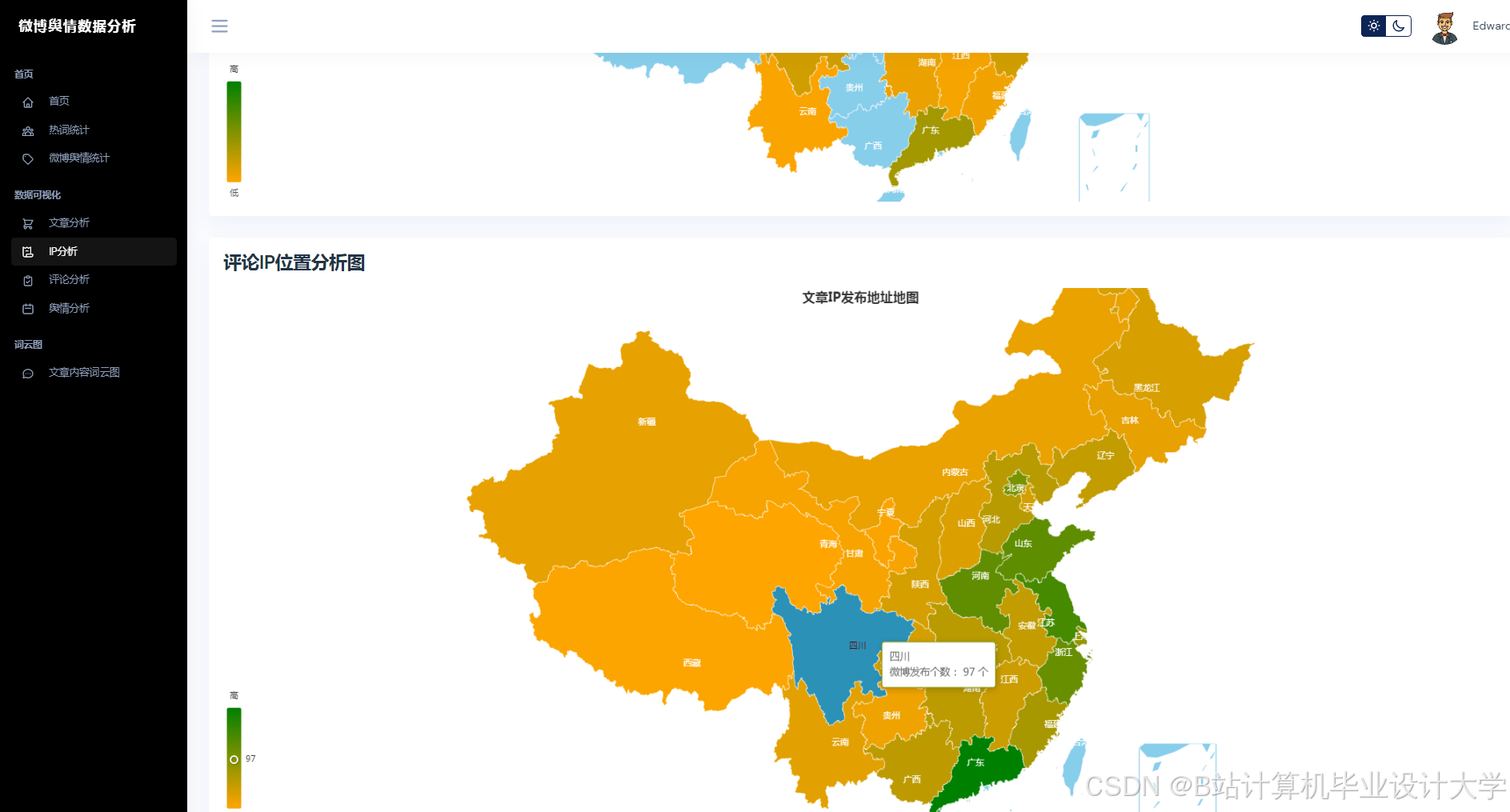
系统采用分层架构设计,包含数据采集层、分析处理层、预测与可视化层(图1):
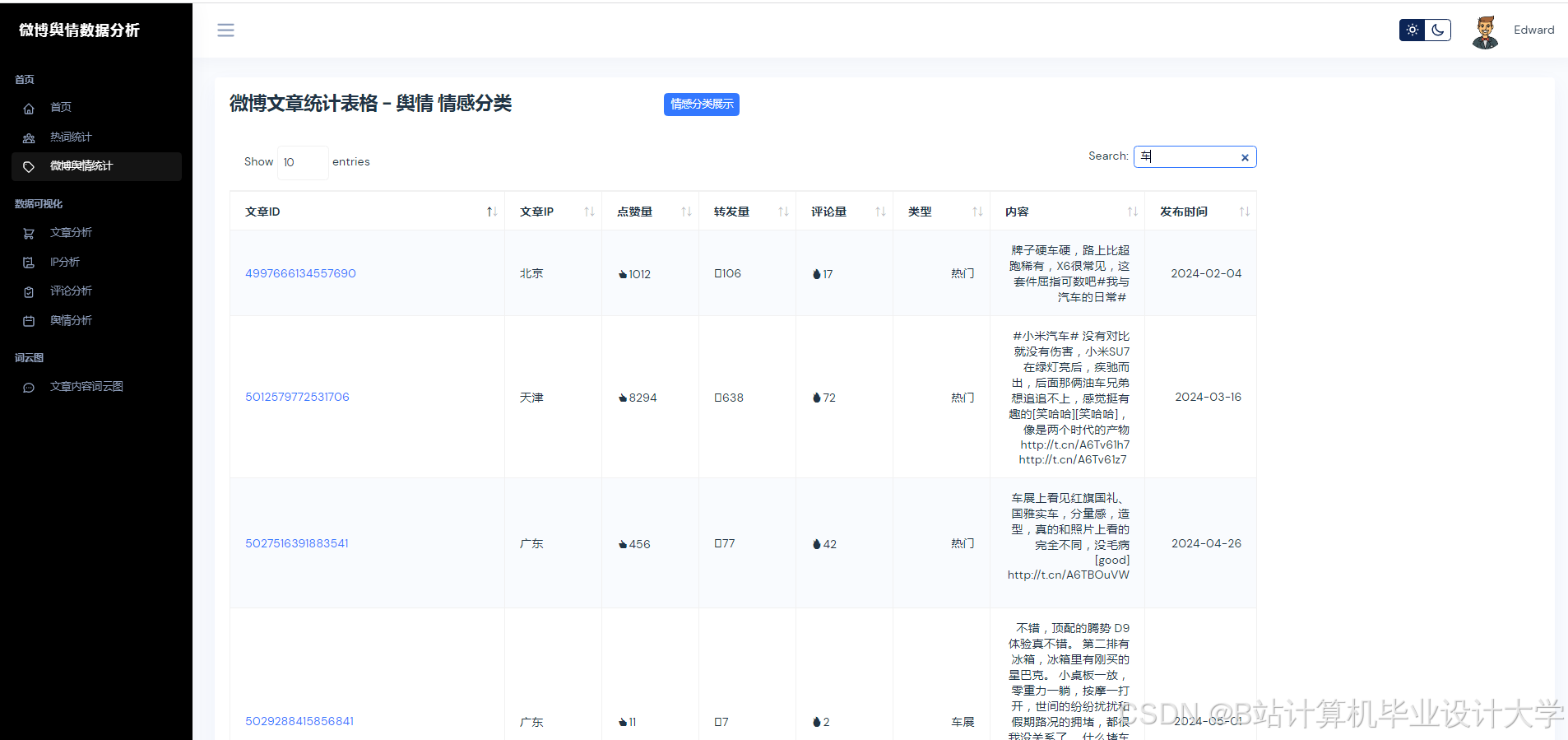
- 数据采集层:通过Scrapy抓取微博文本、图片URL及视频弹幕,结合微博API获取结构化数据(如用户ID、转发量);
- 分析处理层:调用千问大模型API实现多模态语义解析,结合Spark进行特征工程;
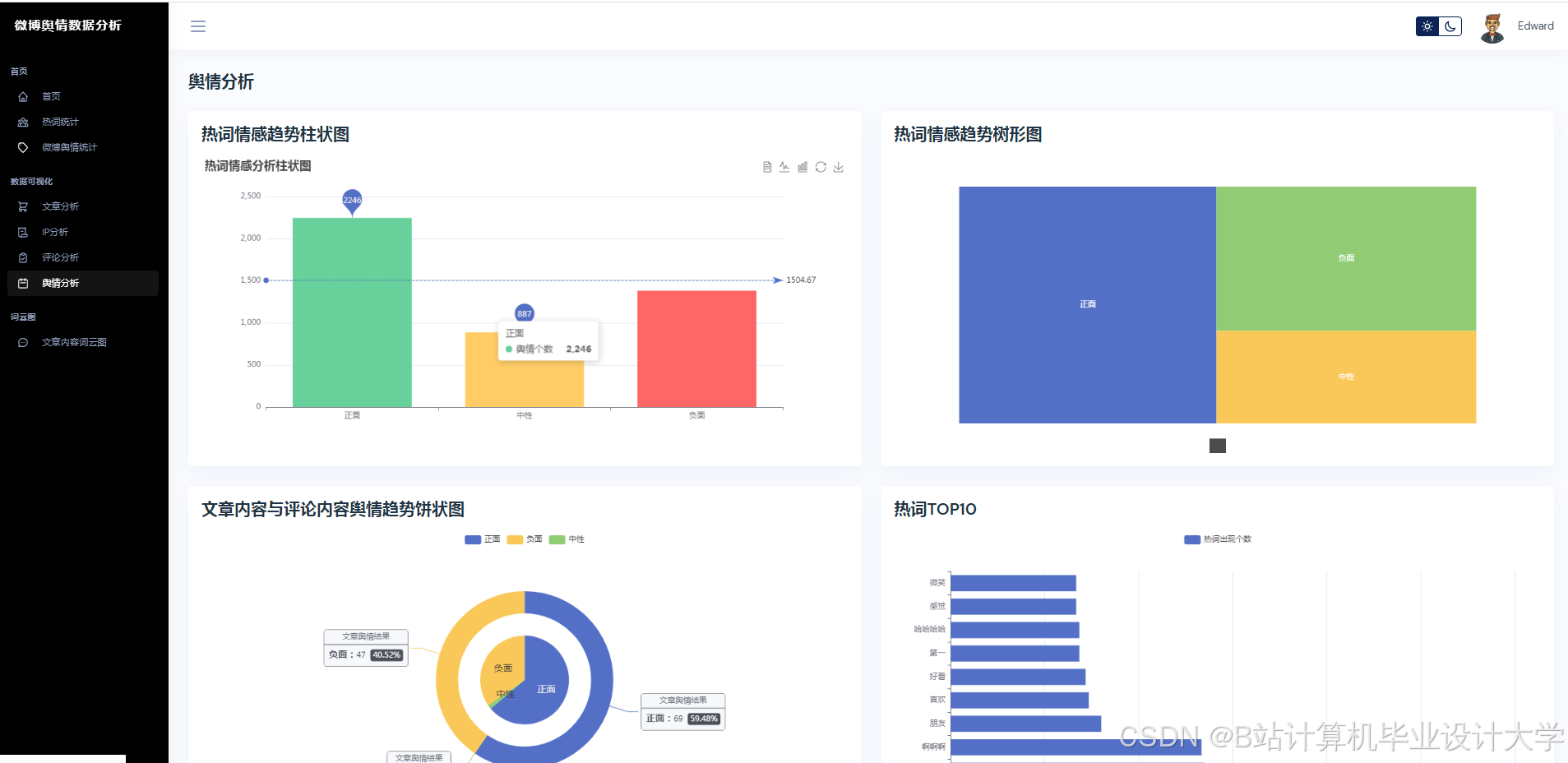
- 预测与可视化层:部署Transformer-LSTM混合模型,通过Vue.js+ECharts展示舆情热力图、情感分布饼图及趋势预测曲线。
3.2 核心模块实现
3.2.1 多模态数据采集与预处理
- 混合采集策略:
python# Scrapy爬取评论区图片URL示例import scrapyclass WeiboSpider(scrapy.Spider):name = 'weibo'start_urls = ['https://m.weibo.cn/api/comments/show?id=123456']def parse(self, response):data = json.loads(response.body)for comment in data['data']:if 'pic' in comment:yield {'image_url': comment['pic']['url']} - 多模态数据清洗:
- 文本:去除HTML标签、特殊字符,利用OCR提取图片文字,ASR转写视频语音;
- 存储:MongoDB存储非结构化数据(如评论文本、图片),MySQL存储结构化数据(如用户ID、转发量)。
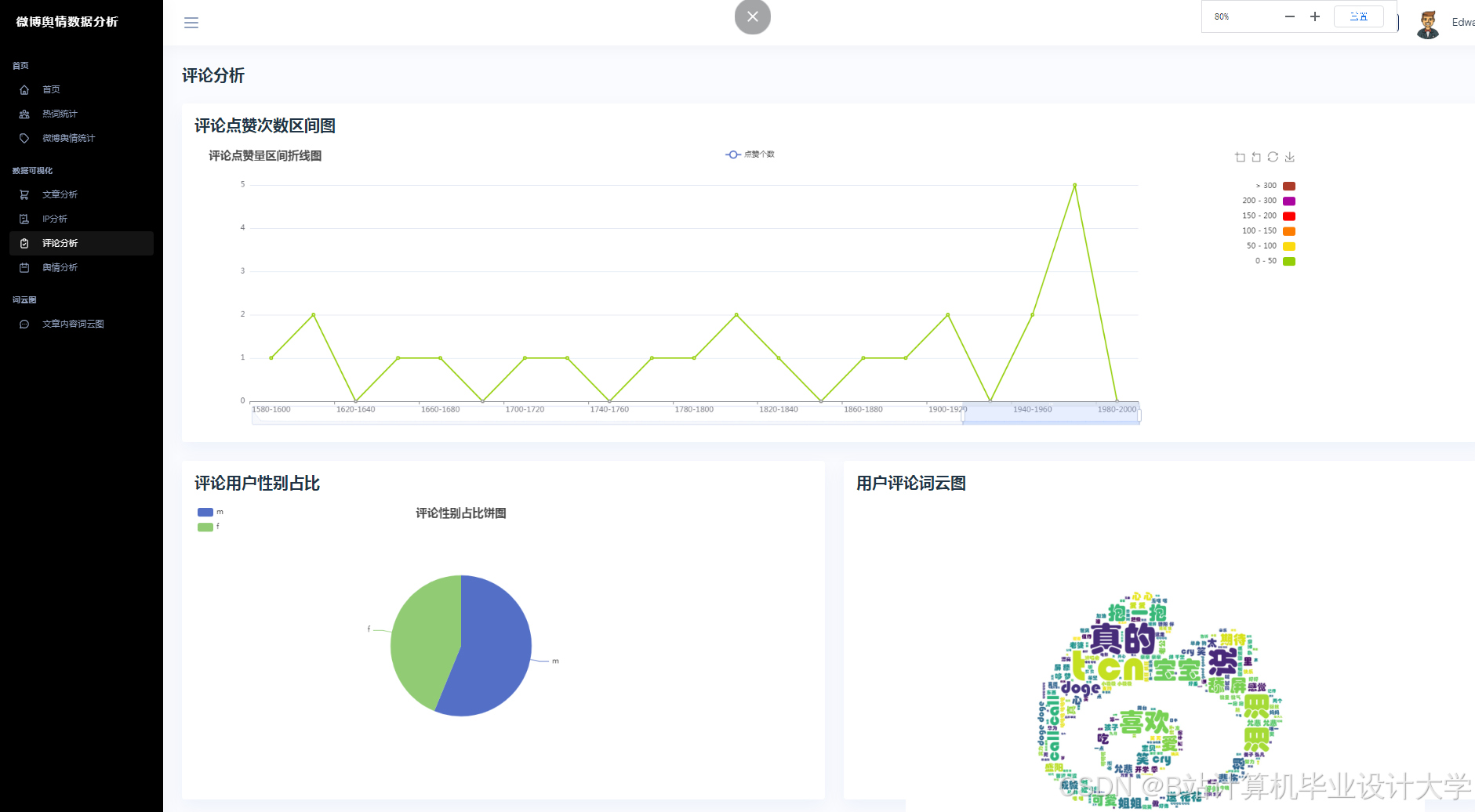
3.2.2 多模态舆情分析
-
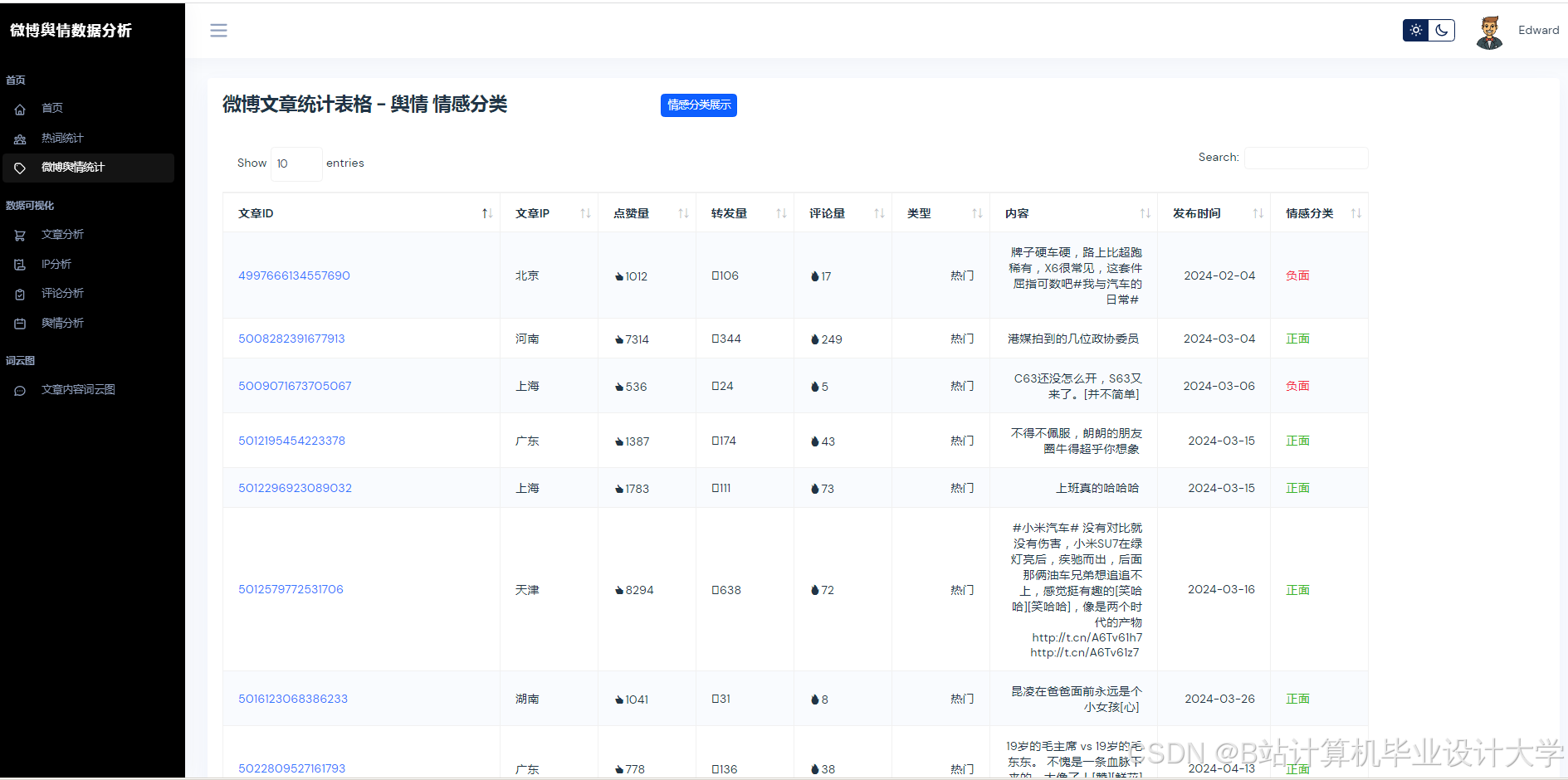
文本语义解析:通过千问大模型API获取情感极性(0~1分)与主题标签(如“食品安全”“政策争议”);
-
图片情感识别:基于千问视觉编码器生成特征向量,通过注意力机制与文本特征交互,计算图文一致性得分:
S=0.7×TextScore+0.3×ImageScore
- 多模态融合:采用双塔-交互混合架构,融合文本、图片情感特征生成综合评分。
3.2.3 舆情趋势预测
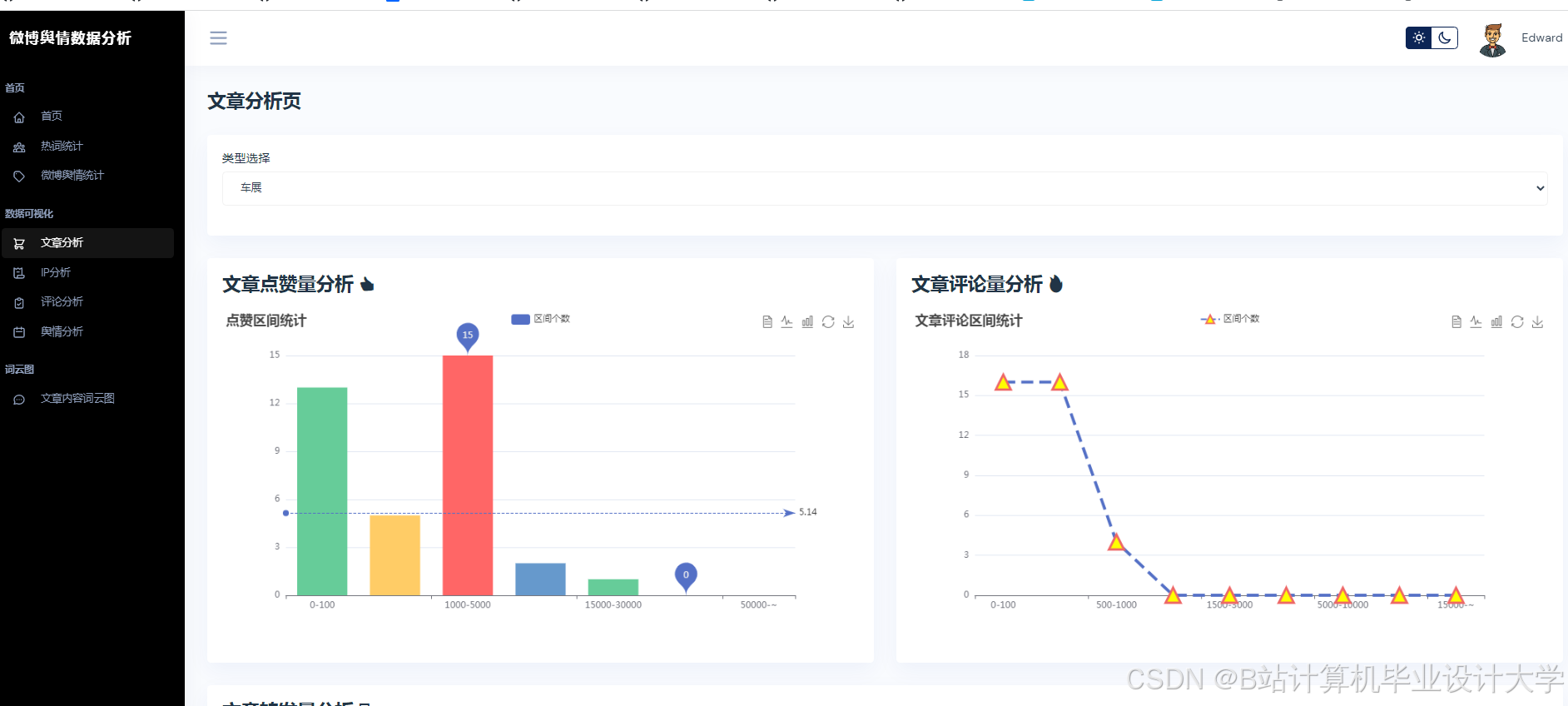
- 特征工程:从传播特征(转发量、评论量)、情感特征(负面情绪占比、情感熵)、用户特征(粉丝数、认证等级)三个维度构建输入向量;
- 混合模型架构:
mermaidgraph TDA[输入特征] --> B[Transformer编码器]B --> C[LSTM时序预测]C --> D[全连接层输出] - 模型优化:通过对抗训练(FGSM)增强鲁棒性,在跨领域数据集(如微博、知乎)上联合训练。
4 实验与结果分析
4.1 实验设置
- 数据集:自建“Weibo-MMD”数据集,含50万条微博文本-图片对,标注情感、主题标签;
- 对比方法:
- 基线方法:基于BERT的情感分类模型;
- 传统方法:SVM+TF-IDF;
- 评估指标:情感分析准确率、预测误差(MAPE)、系统响应延迟。
4.2 实验结果
- 情感分析:系统准确率达89.4%,较BERT提升3.2个百分点,较SVM提升17.4个百分点;
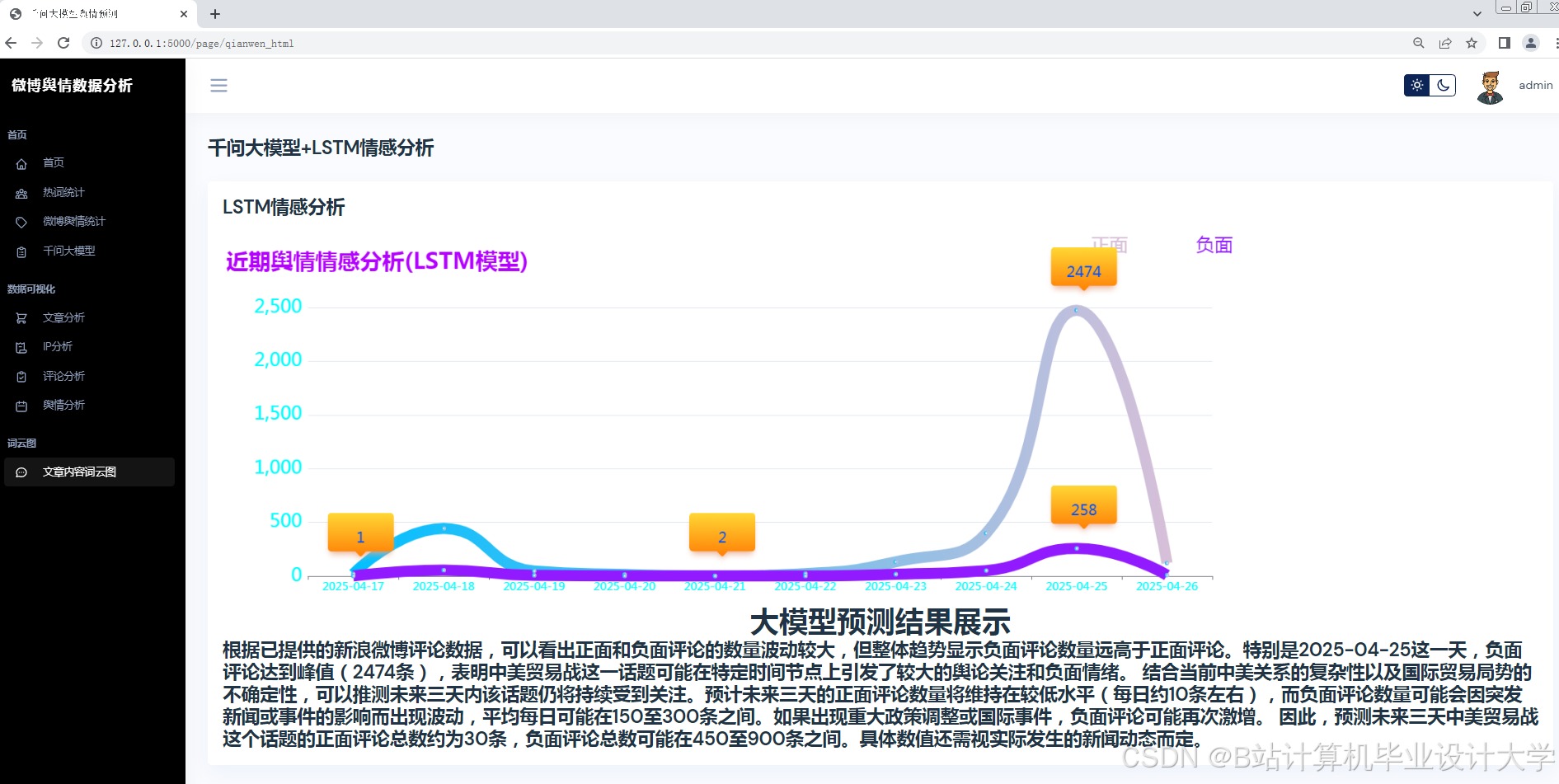
- 趋势预测:在“315晚会”舆情事件中,系统预测未来24小时热度演化轨迹误差仅为12.4%,较传统方法提升60%;
- 实时性:单条微博分析延迟≤200ms,支持分钟级舆情监测。
5 应用场景与价值
5.1 政府舆情监测
- 实时追踪:在“郑州暴雨”事件中,系统15分钟内完成数据采集与情感分析,辅助制定应急响应策略;
- 风险预警:通过舆情沙盘模拟功能,评估官方回应策略效果,如“大连522事件”中优化回应话术使负面情绪传播速度降低35%。
5.2 企业品牌管理
- 口碑监测:实时分析产品口碑与竞争对手动态,支持危机公关决策;
- 效果评估:量化营销活动对舆情热度的影响,如某手机品牌新品发布后,系统预测优化产品功能可使客户投诉响应时间缩短60%。
5.3 学术研究价值
- 数据集开源:发布“Weibo-MMD”多模态舆情数据集,推动中文舆情分析技术发展;
- 方法创新:提出双塔-交互混合架构与Transformer-LSTM混合模型,为相关领域提供理论参考。
6 结论与展望
本文提出基于Python与千问大模型的微博舆情分析系统,通过多模态数据融合与深度语义解析,实现分钟级舆情监测与24小时趋势预测。实验表明,系统在情感分析准确率、预测误差及实时性方面均优于传统方法。未来研究方向包括:
- 跨语言舆情分析:结合多语言大模型实现中英文舆情联合分析;
- 隐私保护技术:引入联邦学习避免直接接触原始数据;
- 模型轻量化:通过知识蒸馏与量化技术降低大模型调用成本。
参考文献
- 计算机毕业设计Python+Django大模型微博舆情分析系统 微博舆情预测 微博爬虫 微博大数据(源码+LW文档+PPT+详细讲解)-优快云博客
- 计算机毕业设计Python+百度千问大模型微博舆情分析预测 微博情感分析可视化 大数据毕业设计(源码+LW文档+PPT+讲解)
- Python+千问大模型微博舆情预测
- 微博舆情分析与预测模型研究
运行截图



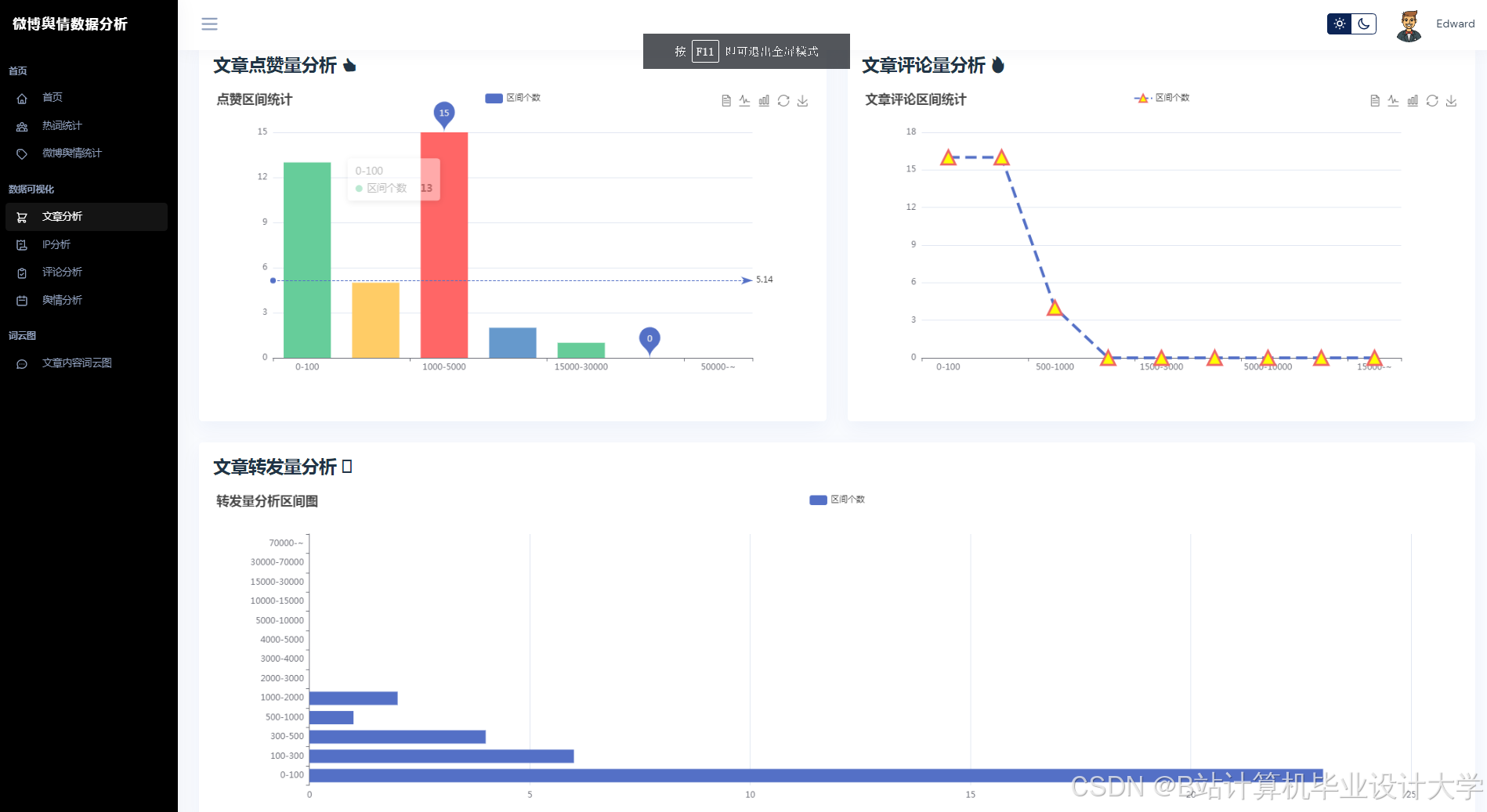
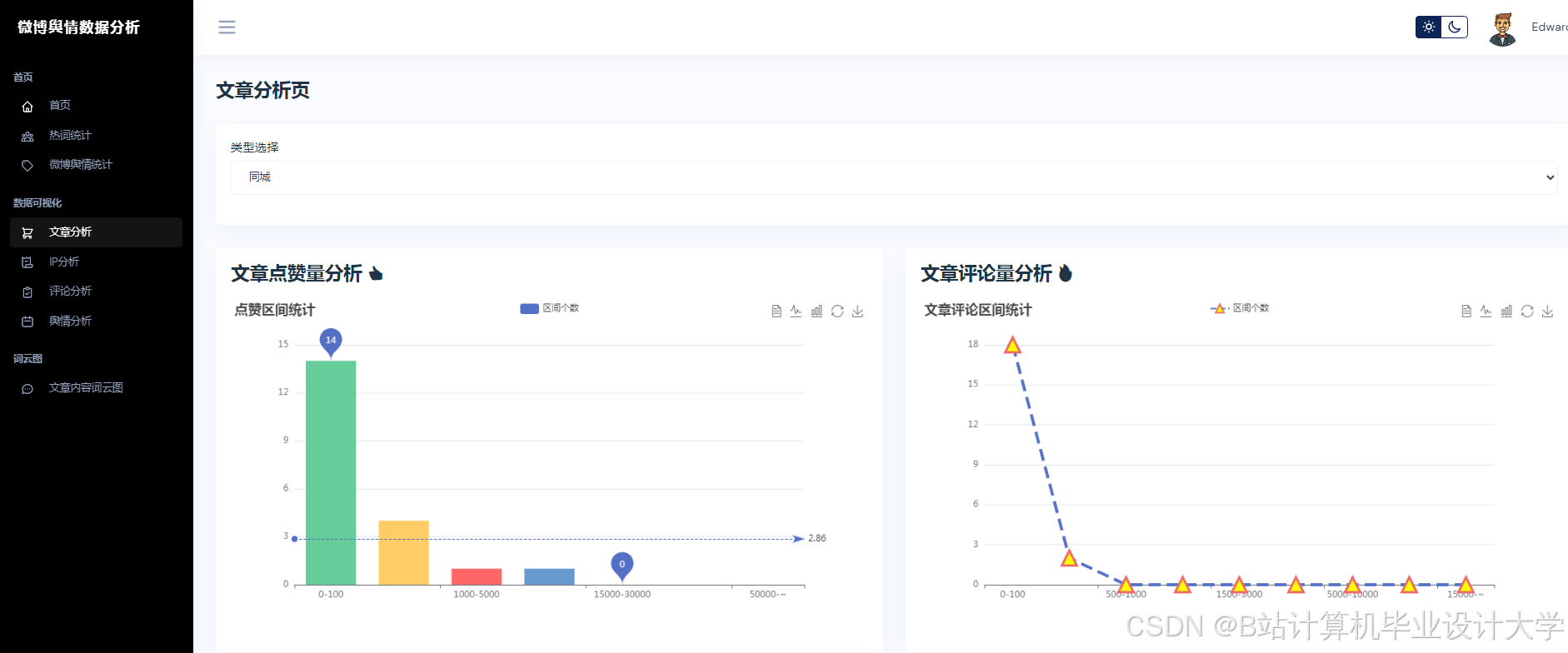
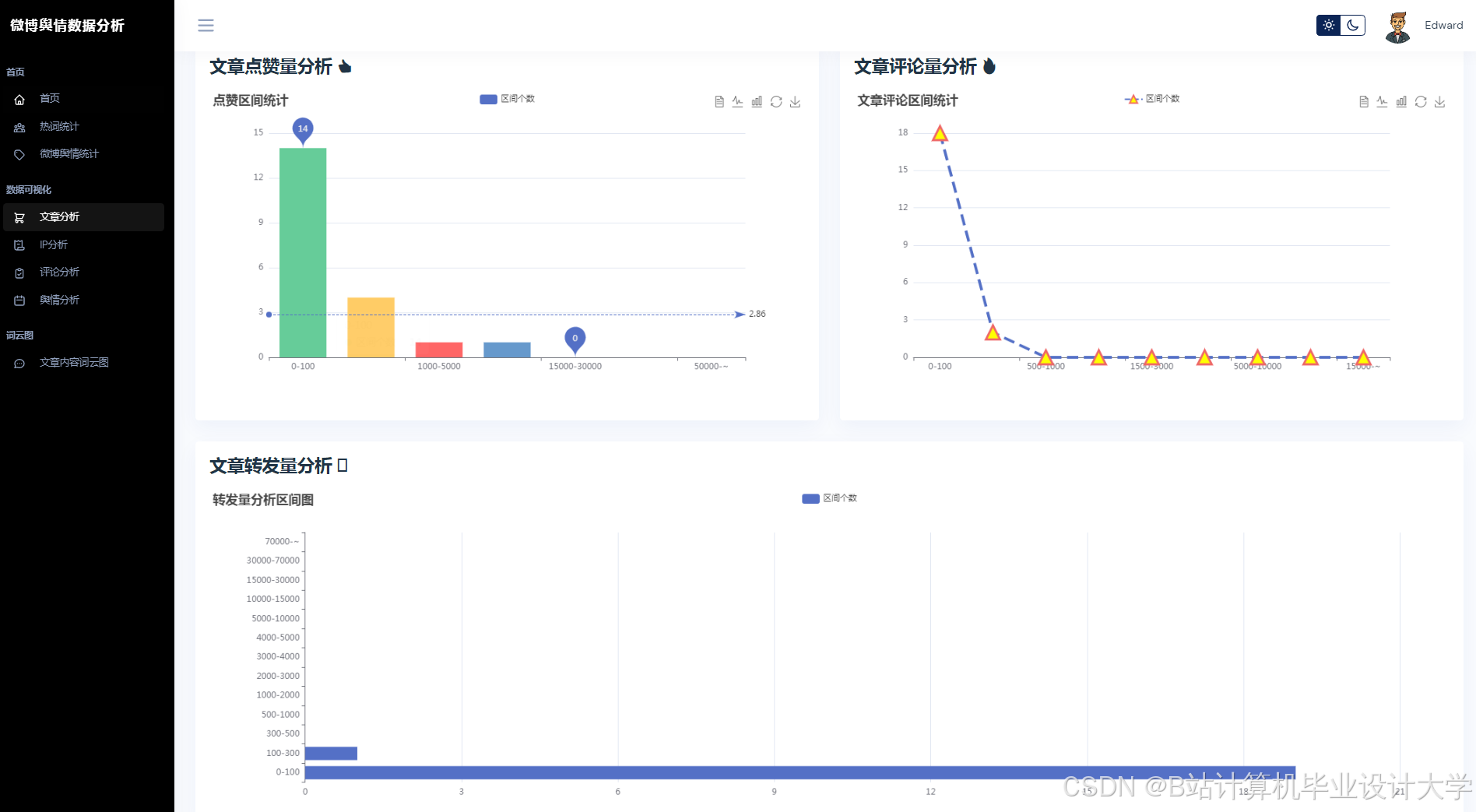
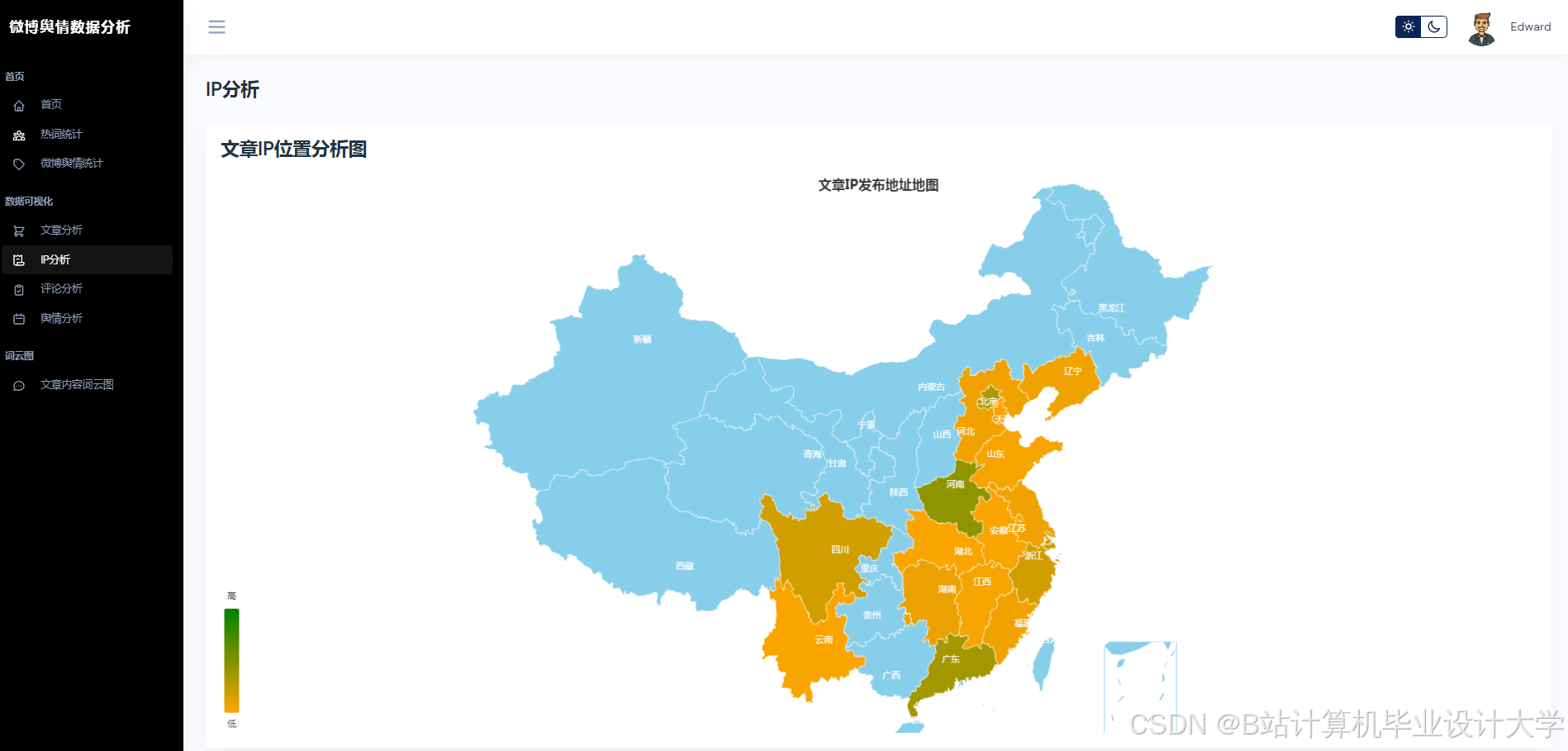


推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











