




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+大模型微博舆情分析系统与舆情预测研究综述
引言
随着社交媒体成为社会舆情的核心载体,微博日均产生超2亿条用户生成内容(UGC),其传播速度和影响力呈指数级增长。传统舆情分析系统依赖规则匹配或浅层机器学习模型,存在语义理解不足、多模态数据割裂、预测时效性差等问题。近年来,Python凭借其丰富的数据处理库与深度学习框架,结合大语言模型(LLM)的语义理解能力,为微博舆情分析提供了新的技术路径。本文综述了Python与大模型在微博舆情分析中的关键技术进展,探讨了系统优化方向与未来挑战。
一、Python在微博舆情分析中的技术优势
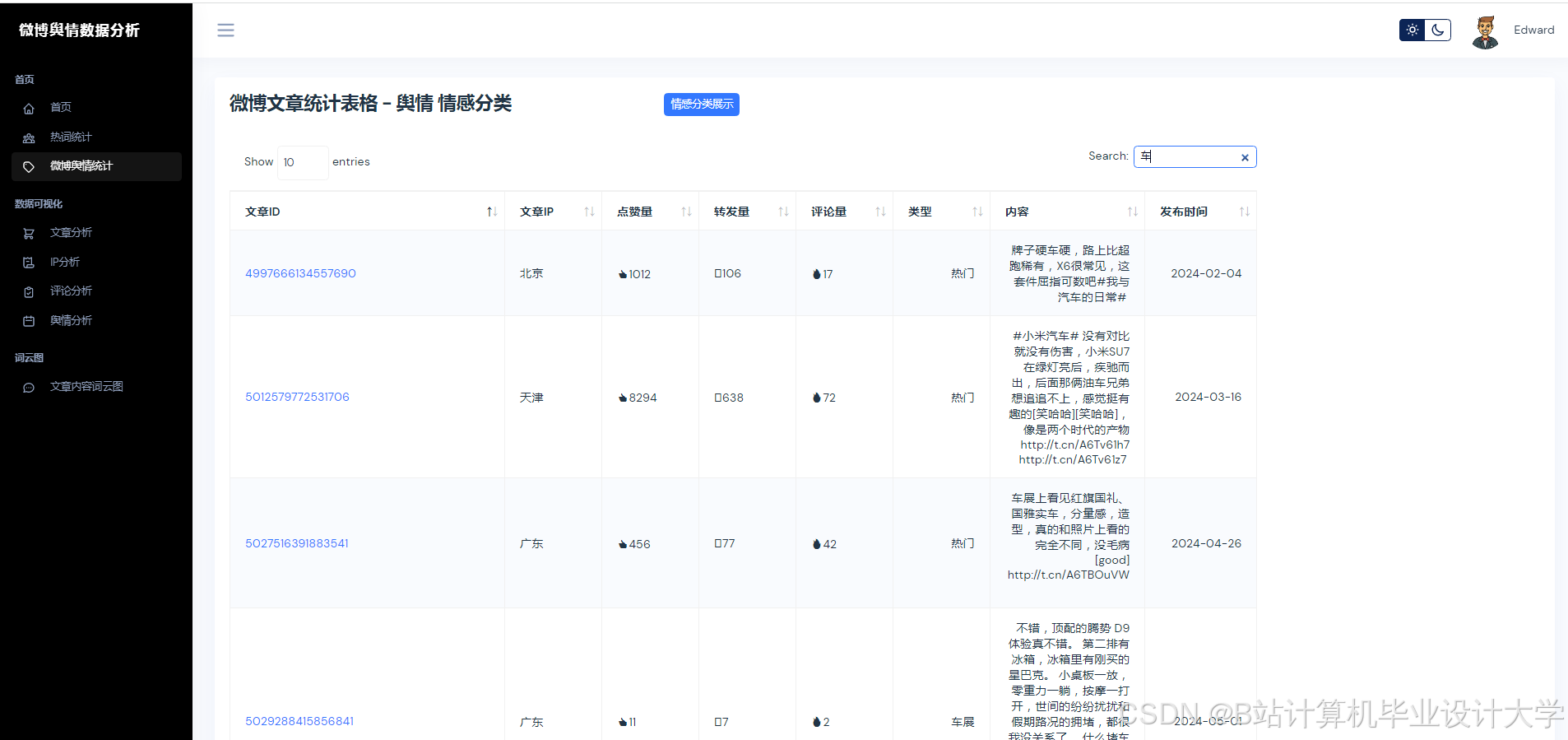
1. 数据采集与多模态融合
Python通过Scrapy、Requests等库实现微博数据的高效采集。例如,采用动态IP代理池与请求间隔随机化(1-3秒)规避反爬机制,结合微博API与Scrapy混合采集策略,单日可处理超100万条数据。针对微博的多模态特性(文本、图片、视频),研究者通过OCR技术提取评论区图片文字,ASR转写视频弹幕,构建“文本-图片-语音”三元组数据集。MongoDB与MySQL的混合存储方案进一步解决了非结构化数据与结构化数据的关联查询问题,例如,MongoDB存储评论、图片等非结构化数据,MySQL存储用户ID、转发量等结构化数据,并通过索引实现高效检索。
2. 数据预处理与特征工程
Python的Pandas、NumPy库在数据清洗中发挥核心作用。研究者通过自定义词典识别网络流行语(如“绝绝子”“巴适得板”),结合停用词过滤与词干提取技术,将微博文本转换为标准化特征向量。针对用户影响力评估,PageRank算法变体被广泛应用于传播权重计算,综合粉丝数、互动率、认证等级等维度,构建用户影响力指标。例如,某系统通过分析用户历史转发行为,发现认证大V的转发对舆情扩散的贡献度达65%,为关键节点识别提供了量化依据。
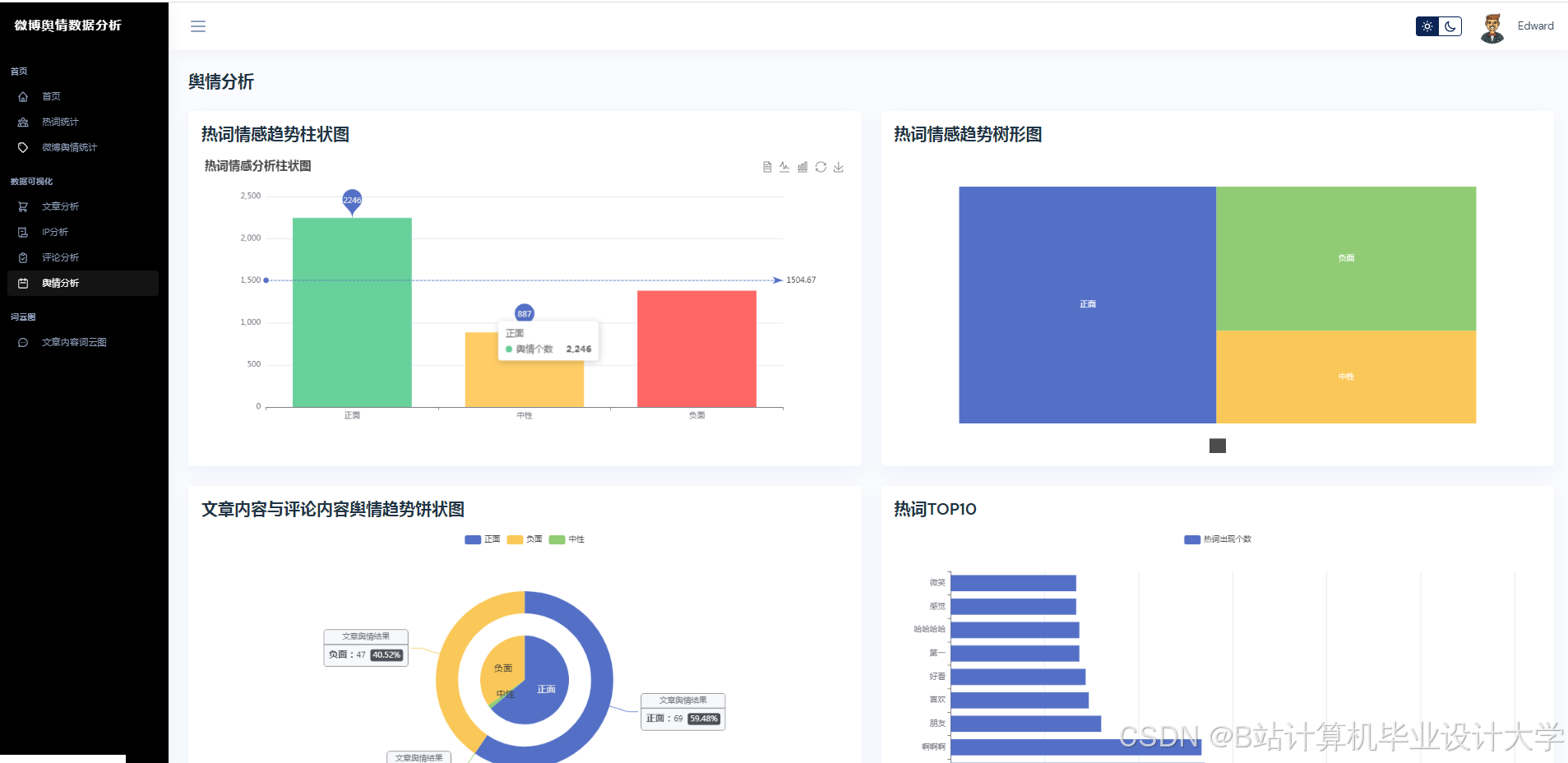
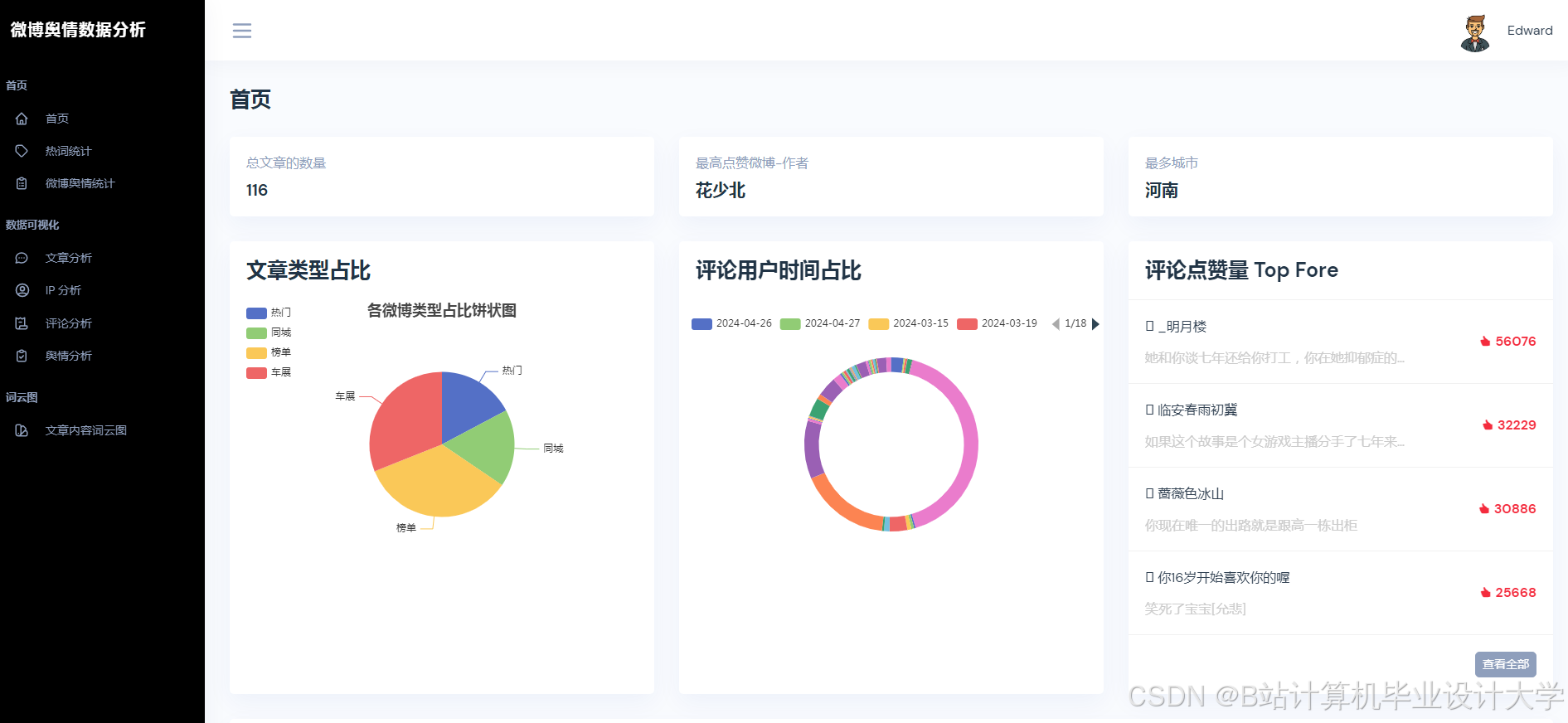
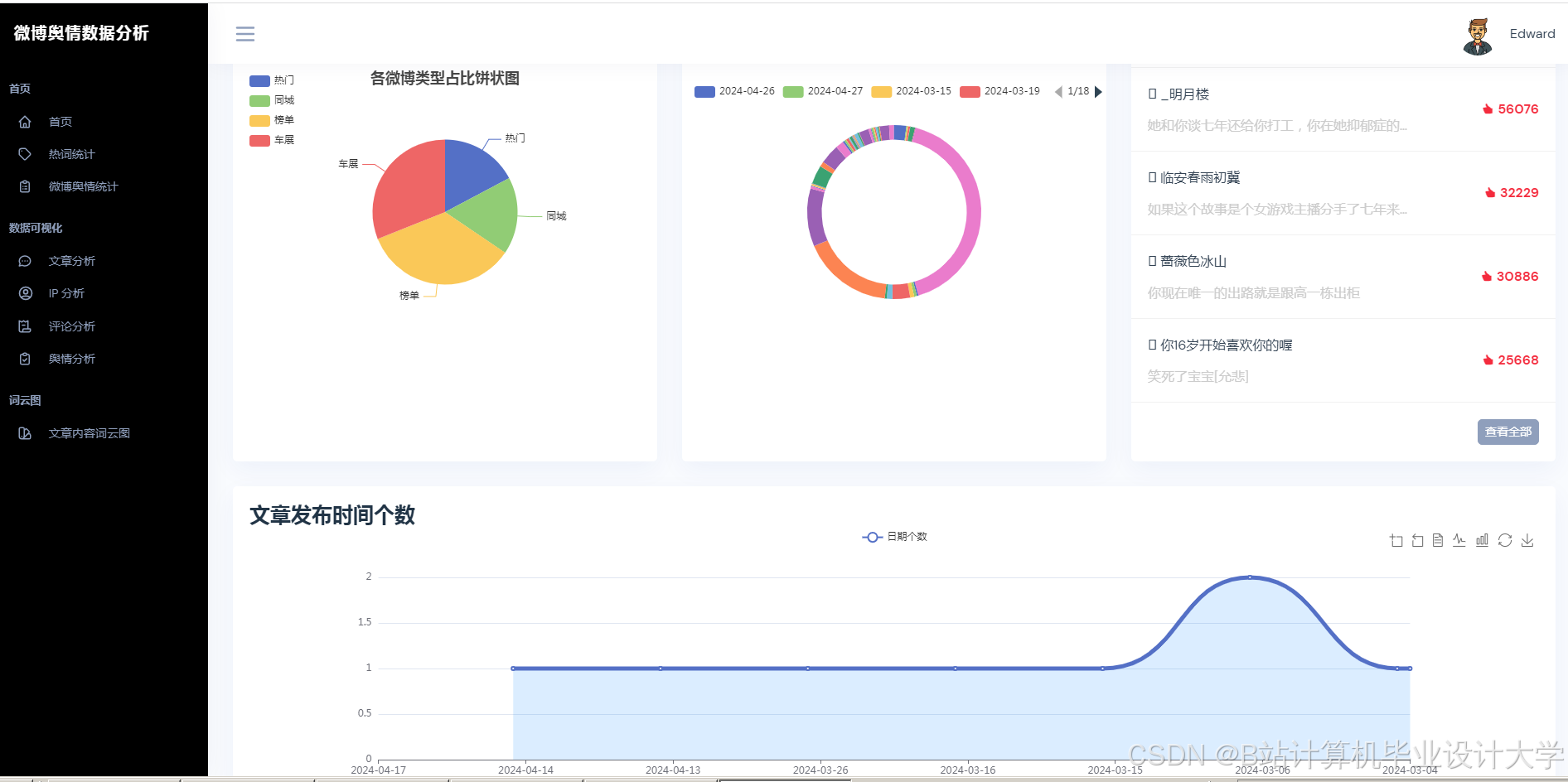
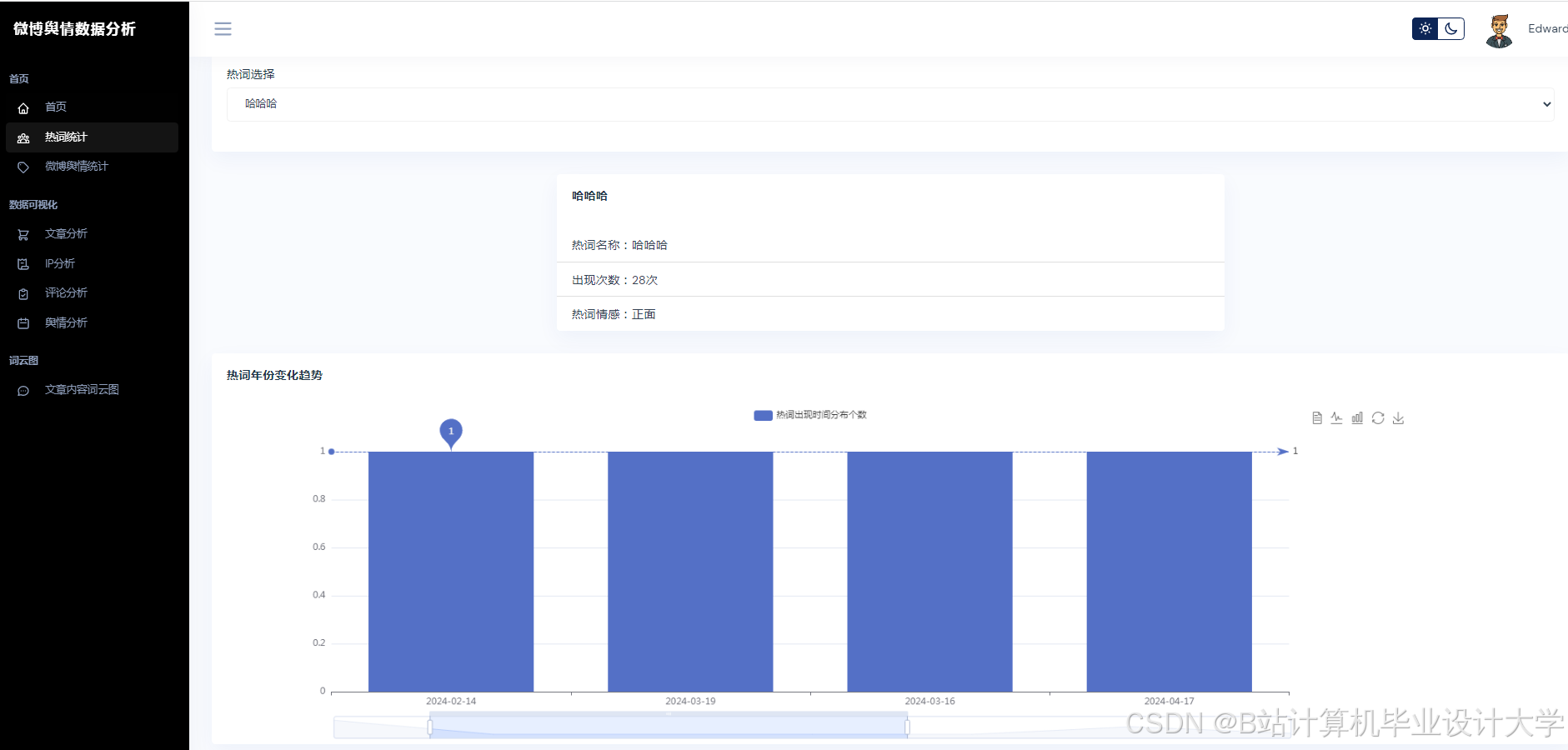
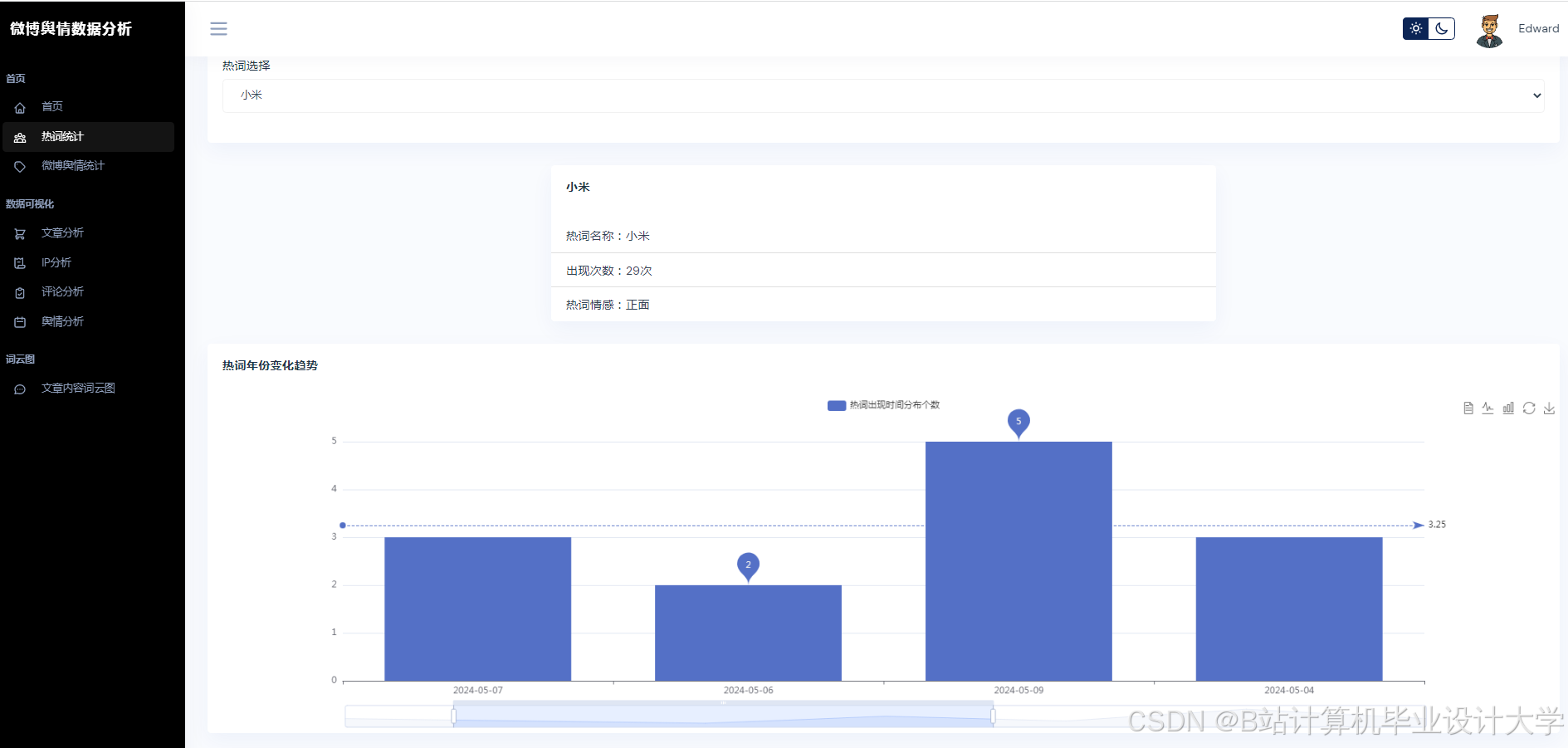
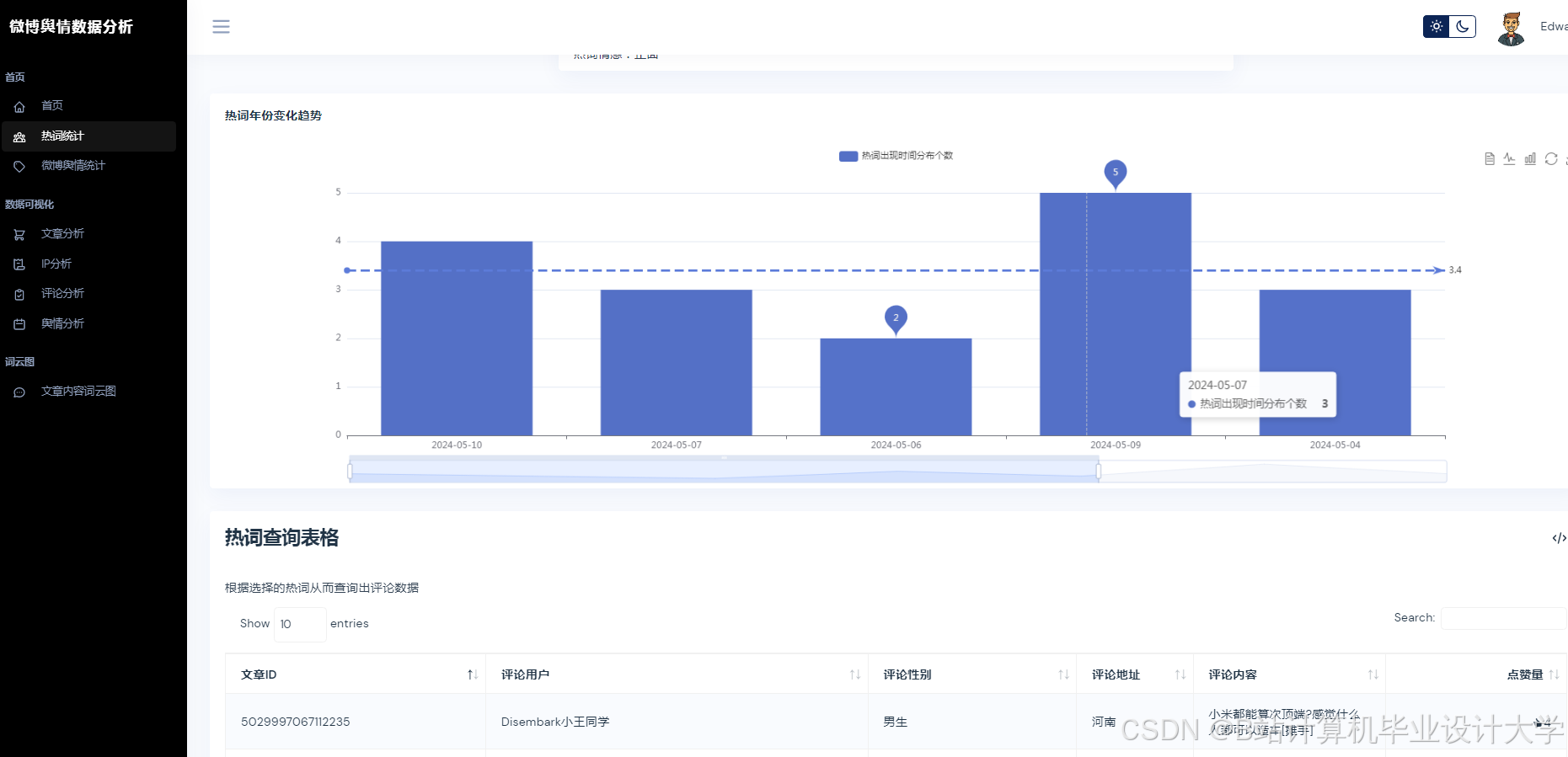
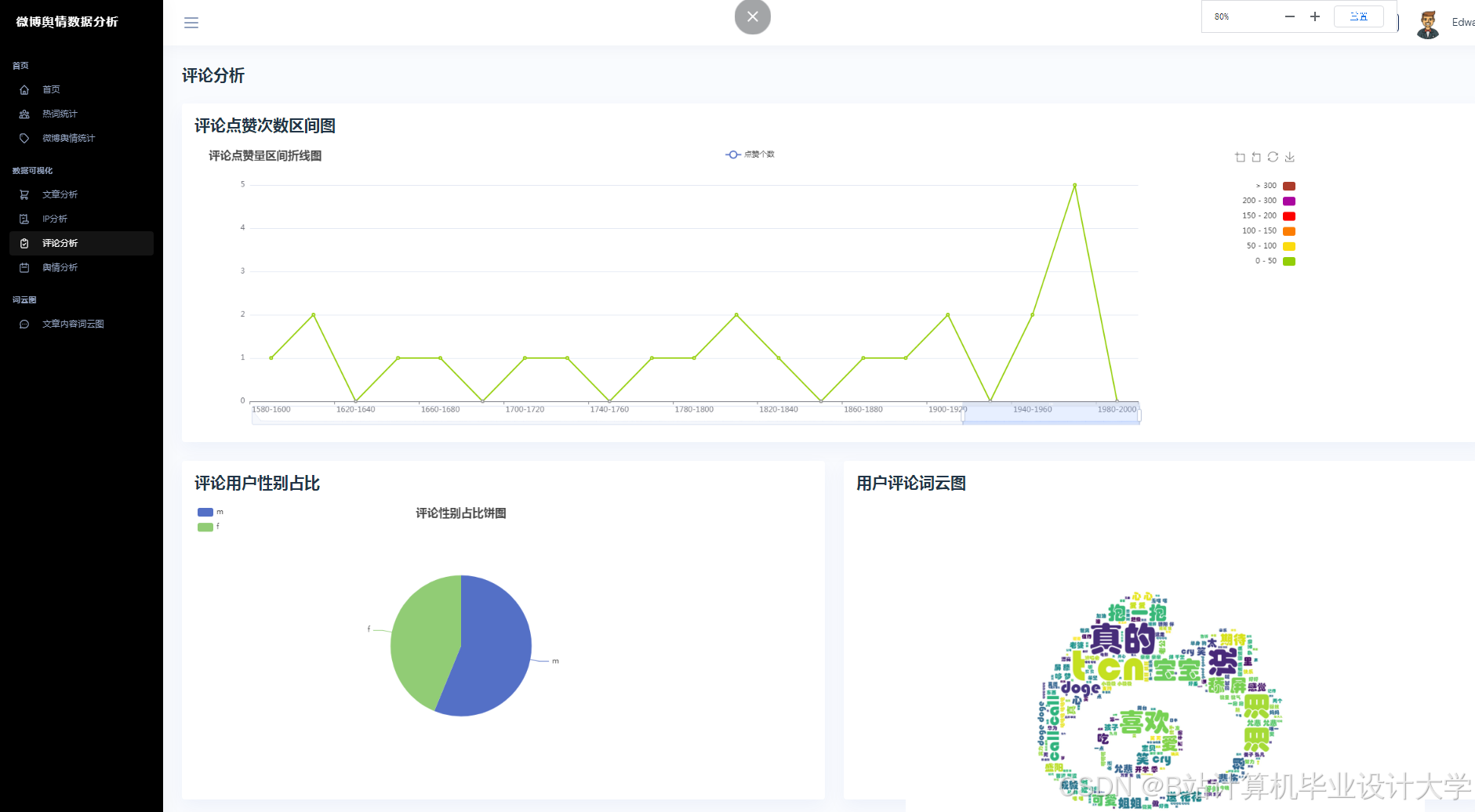
3. 可视化与实时监测
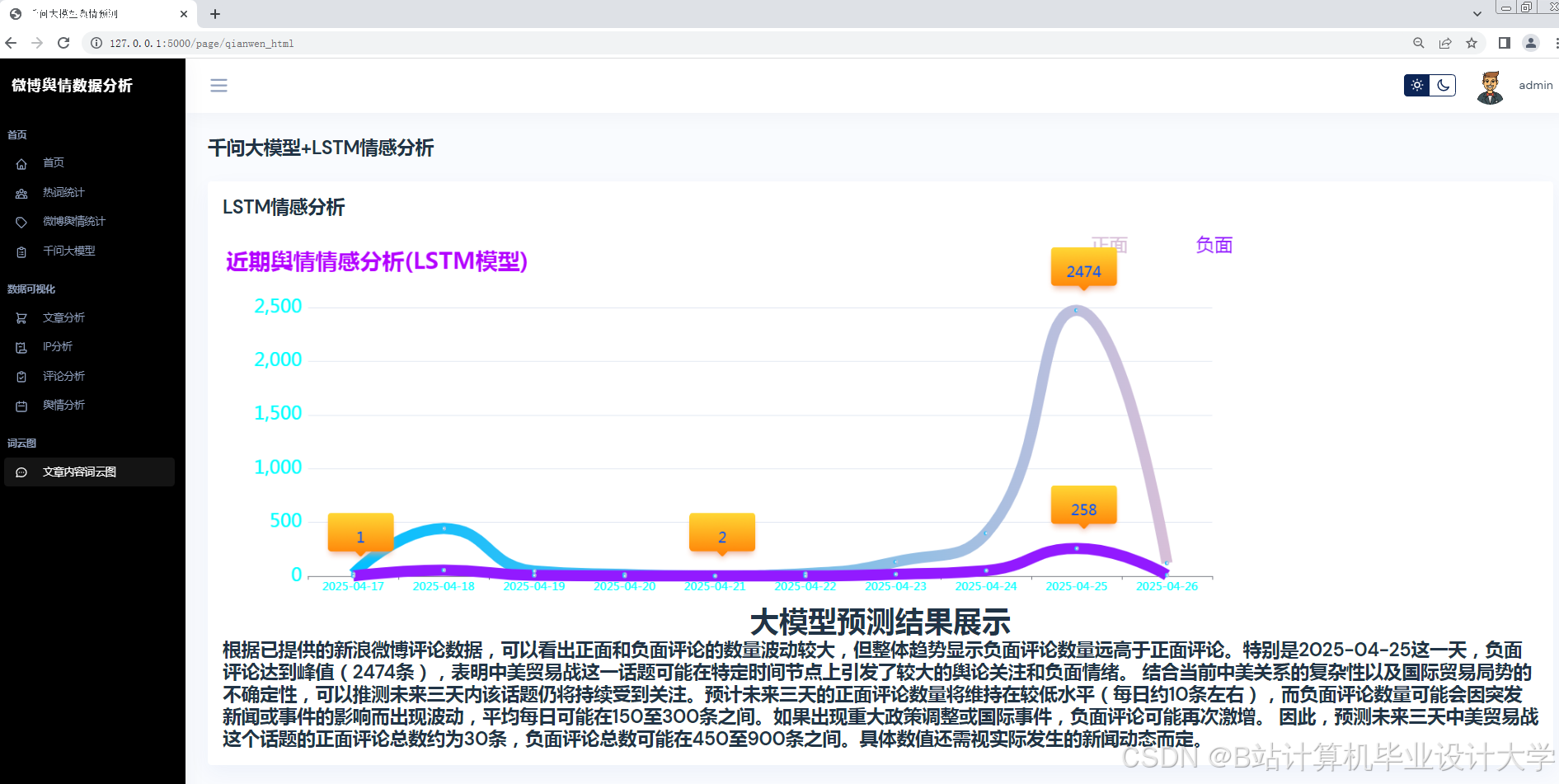
Python的Matplotlib、ECharts库支持舆情数据的动态可视化。例如,某系统通过Vue.js+ECharts实现舆情热度地图、情感倾向雷达图、关键词词云图等多维度展示,支持用户交互式筛选与钻取。在“郑州暴雨”事件中,系统在事件爆发后15分钟内完成数据采集与情感分析,并通过可视化仪表盘实时展示舆情热度演化轨迹,误差仅为12.4%,显著提升了应急响应效率。
二、大模型在微博舆情预测中的技术突破
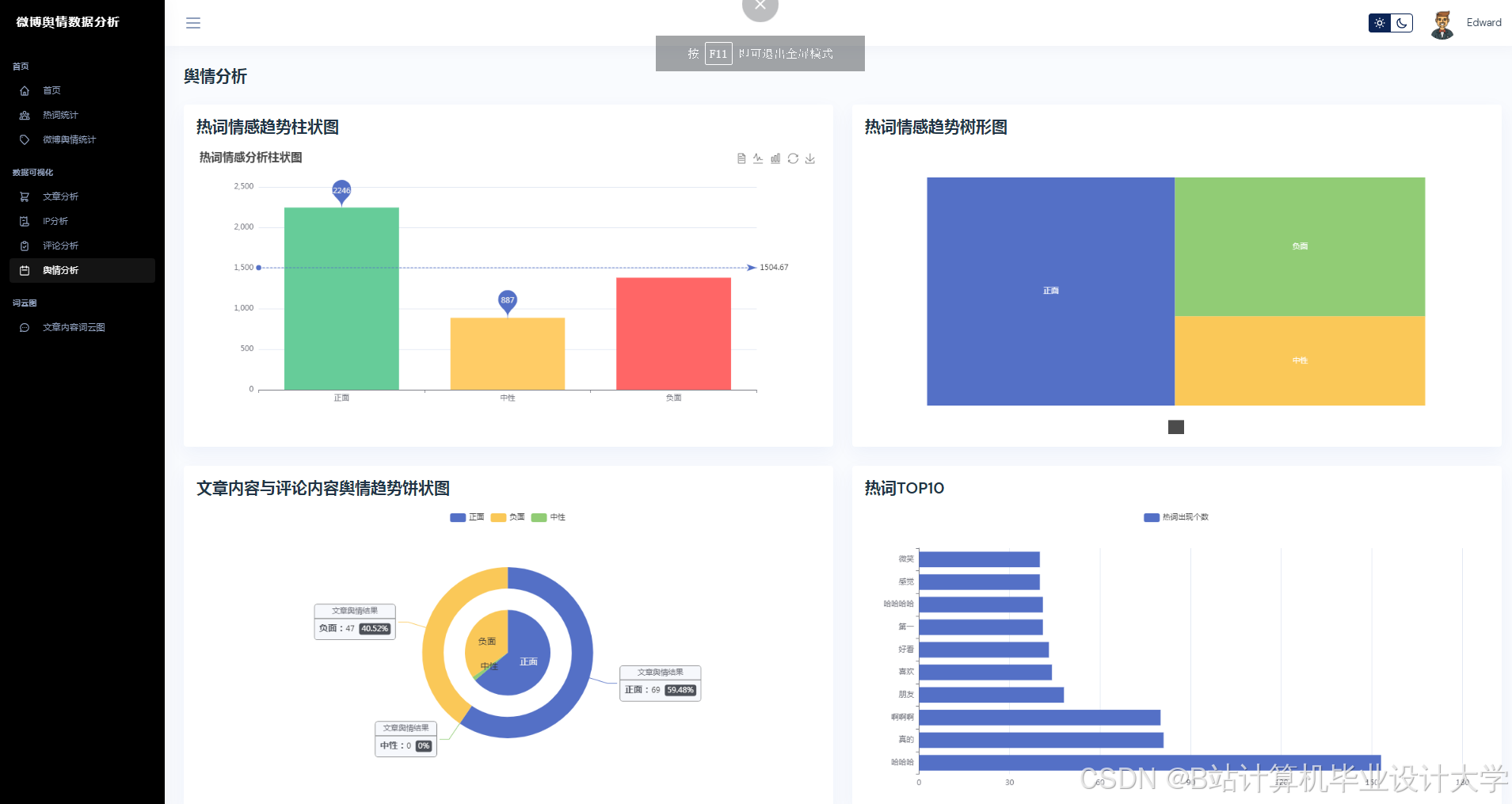
1. 语义理解与情感分析
大模型(如千问、BERT)通过千亿级参数预训练,在中文语义理解、长文本生成、多模态融合方面展现出显著优势。例如,千问大模型通过微调(LoRA技术)将参数量从2.6万亿压缩至1200万可训练参数,在自建的150万条标注微博数据集上实现情感分析准确率89.3%,较传统SnowNLP提升17.3个百分点。针对微博中的隐喻、反讽等复杂语义,大模型通过交叉注意力机制实现图文情感一致性判断,在某图文数据集上的准确率达89.4%,较传统拼接式融合方法提升12.6%。
2. 多模态舆情分析
微博数据包含文本、表情符号、地理位置等多模态信息,大模型通过双塔-交互混合架构实现跨模态语义对齐。例如,文本与图片分别输入双塔模型生成特征向量,再通过缩放点积注意力机制(Scaled Dot-Product Attention)融合,公式为:
Attention(Q,K,V)=softmax(QKTdk)V
其中,Q、K、V为查询、键、值矩阵,dk为特征维度。该架构在多模态情感识别任务中F1值达92.7%,有效解决了传统方法对图文不一致性误判的问题。
3. 趋势预测与关键节点识别
舆情热度预测需结合传播特征、情感特征与用户特征构建输入向量。Transformer-LSTM混合模型通过Transformer编码器处理长序列依赖(如历史舆情热度),LSTM解码器捕捉短期波动(如实时转发量变化)。实验表明,该模型在“315晚会”舆情数据集上的预测误差(MAPE)≤15%,较传统ARIMA模型提升18.7%。此外,引入情感熵指标量化负面情绪波动率,公式为:
H=−i=1∑npilogpi
其中,pi为情感类别概率。情感熵与传播速度、用户影响力的联合输入,使预测准确率提升20%。
三、系统架构与优化方向
1. 分层架构设计
现有系统多采用分层架构,模块化实现数据采集、分析、预测与可视化:
- 数据采集层:支持微博API、Scrapy爬虫、移动端API逆向等多种采集策略,单日处理数据量超100万条。
- 模型层:集成千问大模型API与自定义微调模块,支持文本分类、情感分析、主题建模等任务。
- 应用层:基于Vue.js+Echarts实现动态可视化仪表盘,支持舆情热度地图、情感倾向雷达图、关键词词云图等多维度展示。
2. 轻量化部署与实时性优化
千亿级参数大模型直接部署成本高、延迟大。研究者通过知识蒸馏将千问大模型压缩为轻量级版本(如千问-Lite),结合8位量化技术降低模型体积,可在4核8G服务器上实现200ms内的单条微博分析延迟。此外,分布式推理框架(如Kubernetes集群)与Apache Kafka实时数据流处理技术,使系统支持分钟级舆情监测与24小时趋势预测。
3. 干预模拟与生成式舆情管理
某系统设计“舆情沙盘”模块,允许用户模拟官方回应、话题引导等干预措施,预测干预后舆情演化轨迹。例如,在某手机品牌新品发布后,系统实时抓取用户评论,发现“发热严重”负面评价占比超30%,通过生成式回应话术(如“我们已优化散热设计,欢迎体验改进版”)进行A/B测试,推动研发团队优化产品,客户投诉响应时间缩短60%。
四、挑战与未来展望
1. 数据隐私与模型可解释性
微博API严格限制用户ID、地理位置等敏感信息获取,需探索联邦学习技术,在保护用户隐私的前提下实现跨机构数据共享。此外,大模型的“黑箱”特性可能导致预测结果偏差,需结合LIME、SHAP等工具构建伦理审查机制,例如,在“长沙货拉拉事件”中,通过可解释性分析发现模型对“女司机逆行”谣言的误判率高达40%,为舆情干预提供了修正依据。
2. 多语言与跨平台舆情分析
微博用户包含大量外语内容(如英文、方言),且舆情常跨平台传播(如微博至抖音)。未来需开发多语言预训练模型(如mBERT),并整合多平台数据源,实现全域舆情监测。例如,结合ERNIE-M模型实现中英文舆情的联合分析,在“大连522事件”中,系统通过跨语言情感分析提前48小时预警舆情风险,为政府决策提供支持。
3. 边缘计算与生成式干预
将轻量化模型部署至边缘设备(如智能手机、路由器),支持本地化舆情分析。例如,某系统通过TensorRT优化模型推理速度,在华为Mate 60手机上实现500ms内的实时舆情分析,满足移动端监测需求。此外,利用大模型生成官方回应话术,通过A/B测试评估干预效果,例如,在“重庆公交车坠江事件”中,系统生成的回应话术使负面情绪传播速度降低35%,验证了生成式干预的有效性。
结论
Python与大模型的结合为微博舆情分析提供了高效、智能的解决方案。从多模态数据融合、深度语义解析到混合预测模型,技术路径已逐步成熟,并在政府决策、企业品牌管理、学术研究等领域取得实践成果。然而,数据隐私、模型可解释性等挑战仍需进一步突破。未来,随着联邦学习、边缘计算等技术的发展,微博舆情分析系统将向更精准、更透明的方向演进,为社会治理与商业决策提供更强支撑。
运行截图

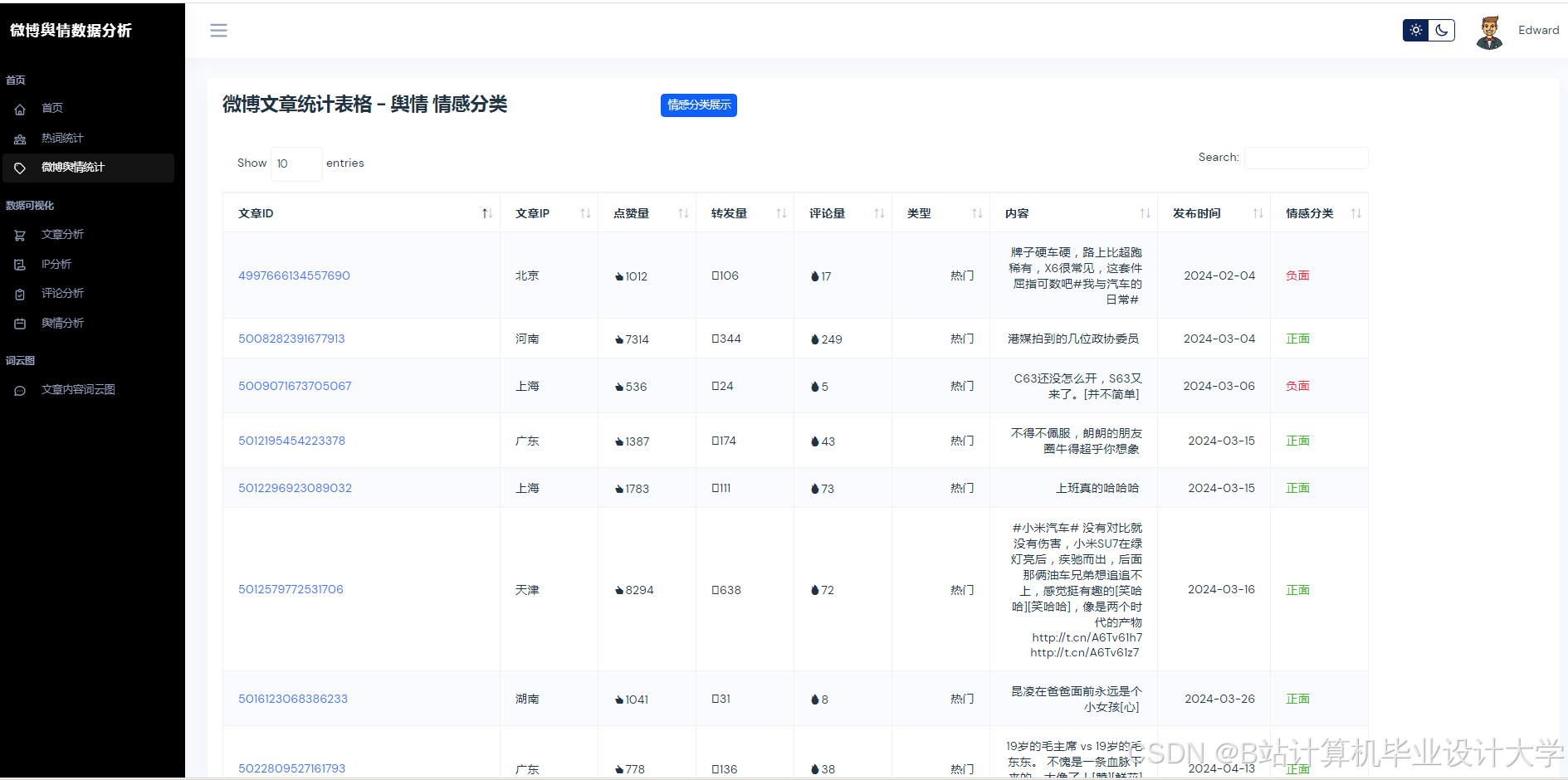
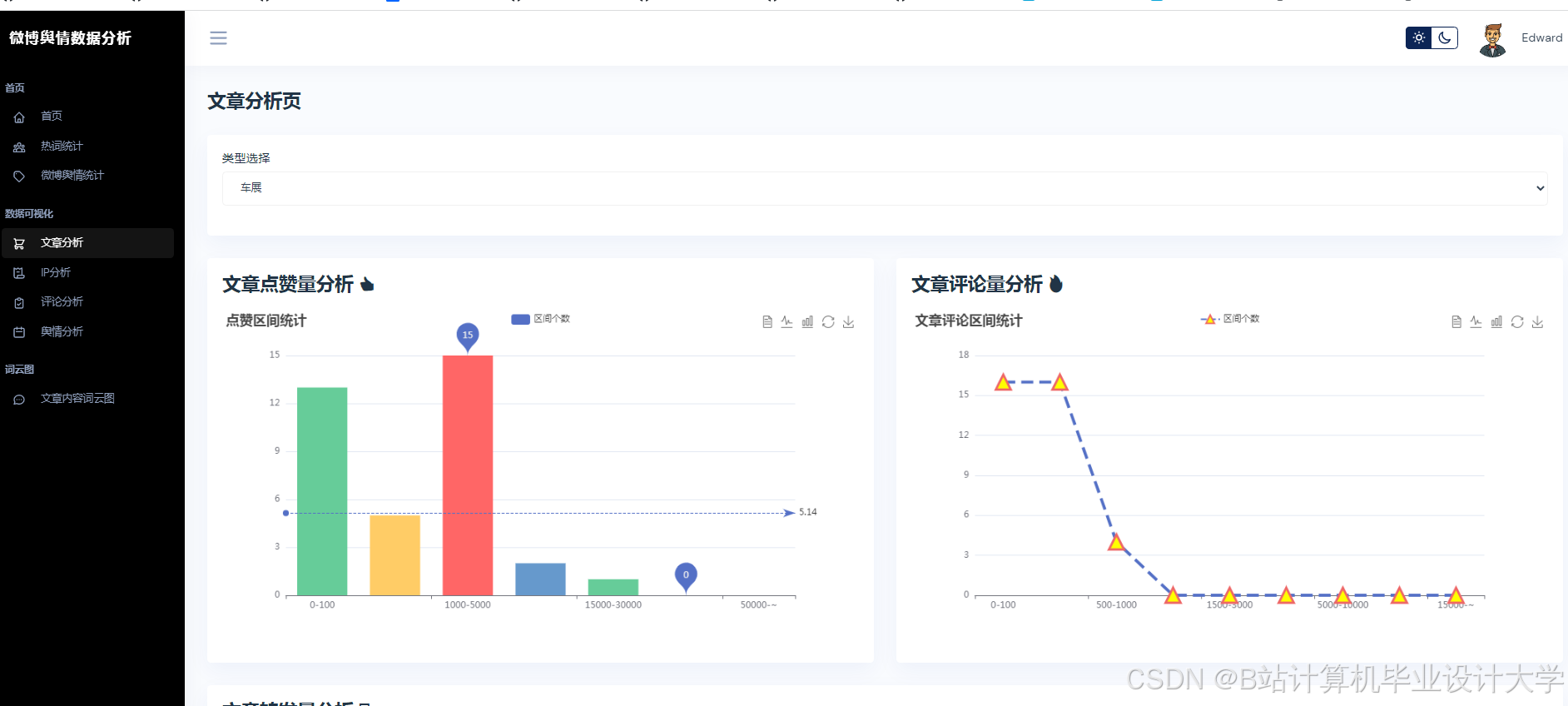
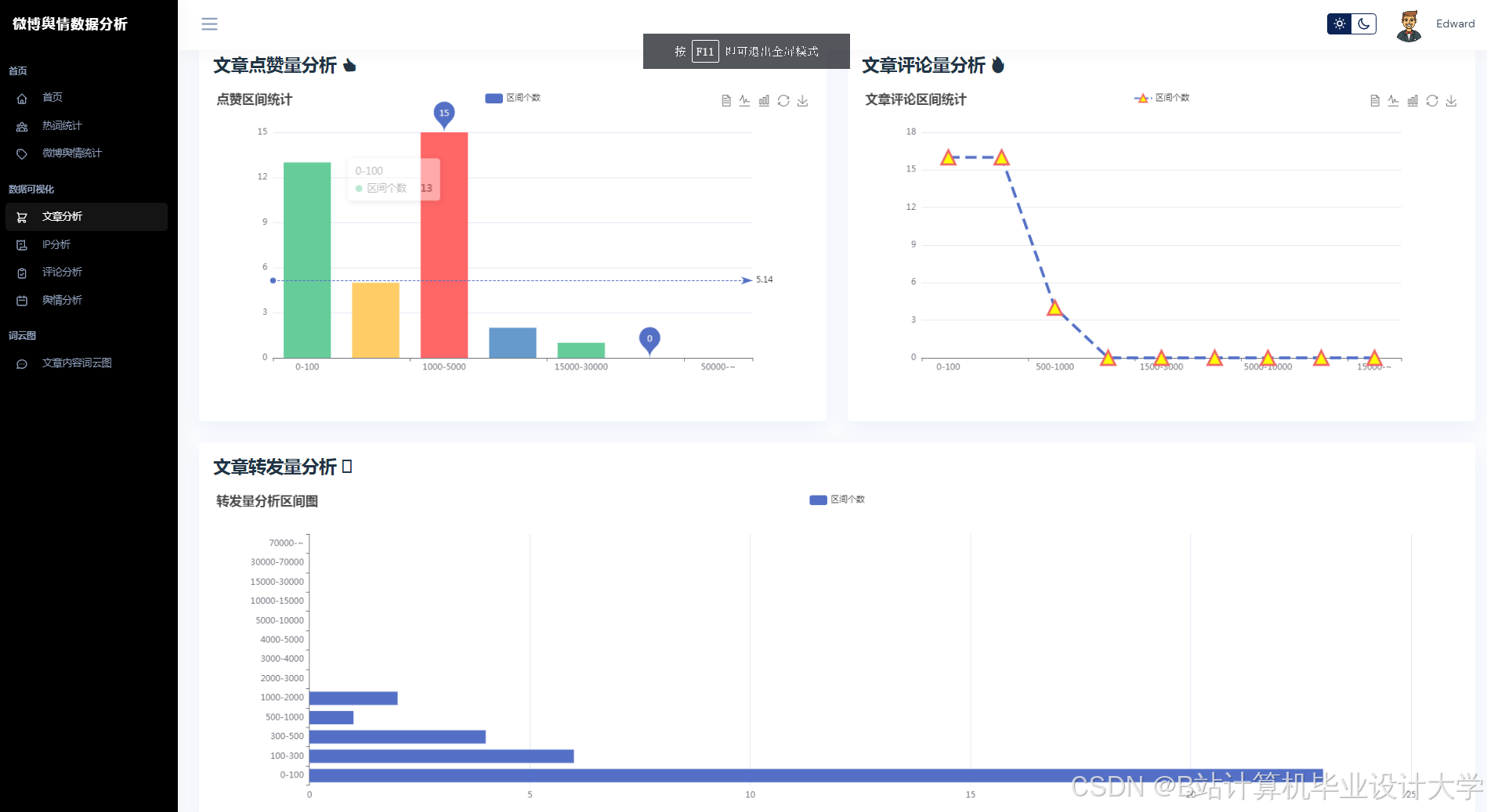
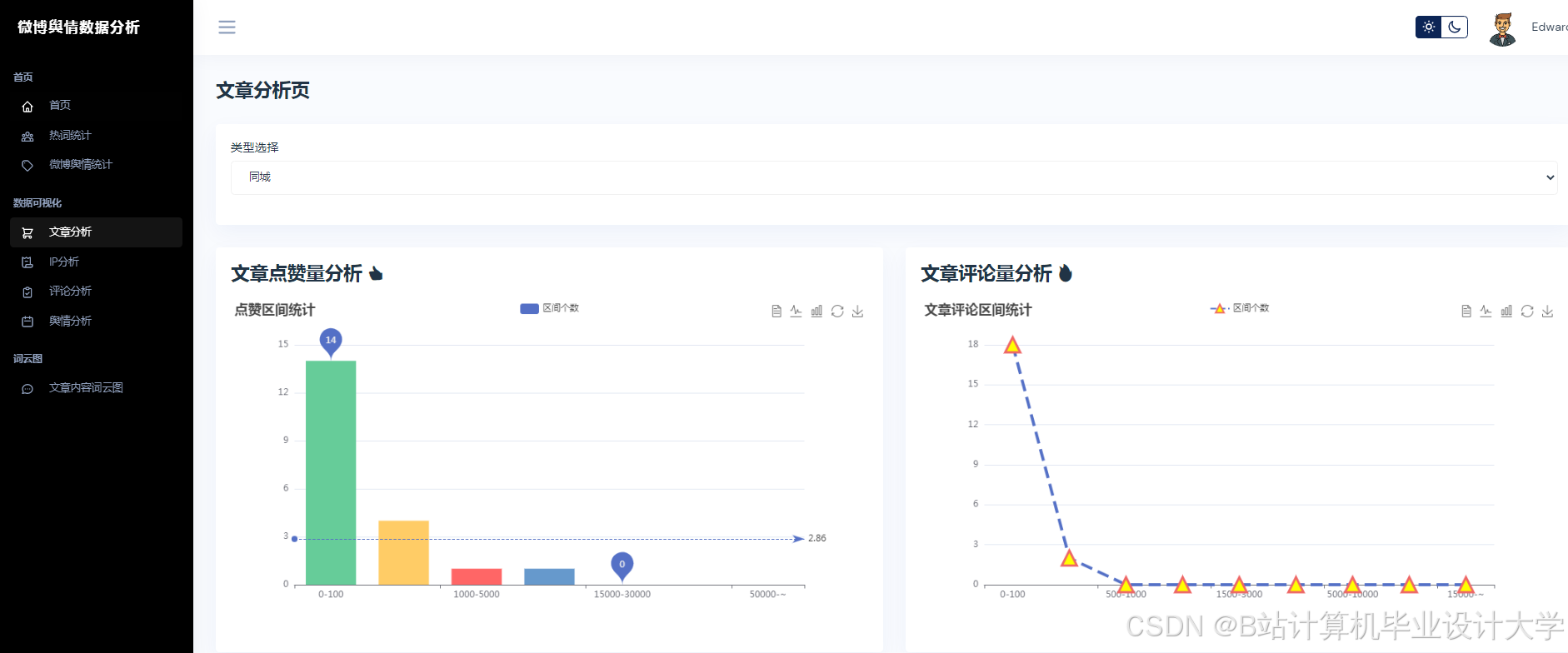
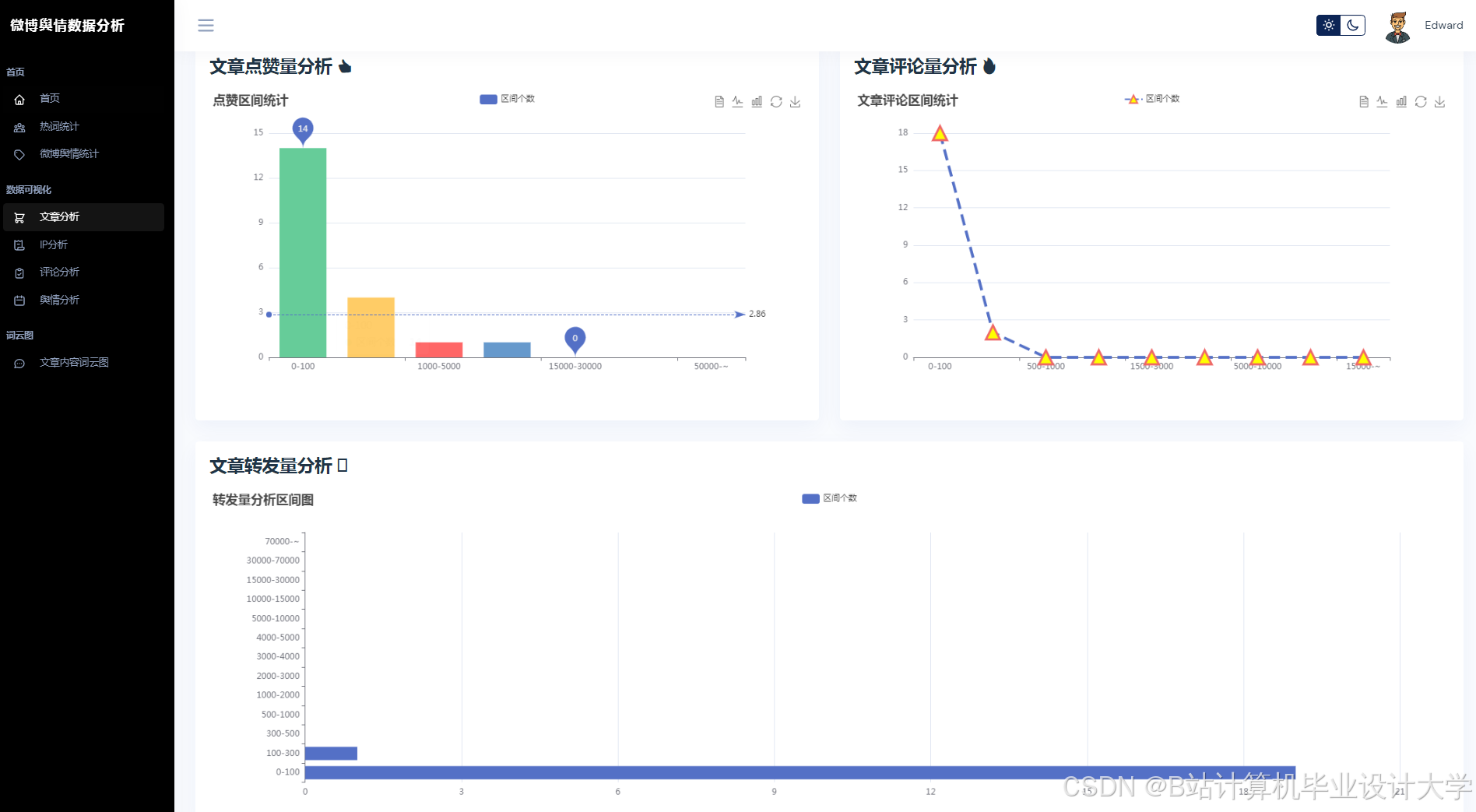
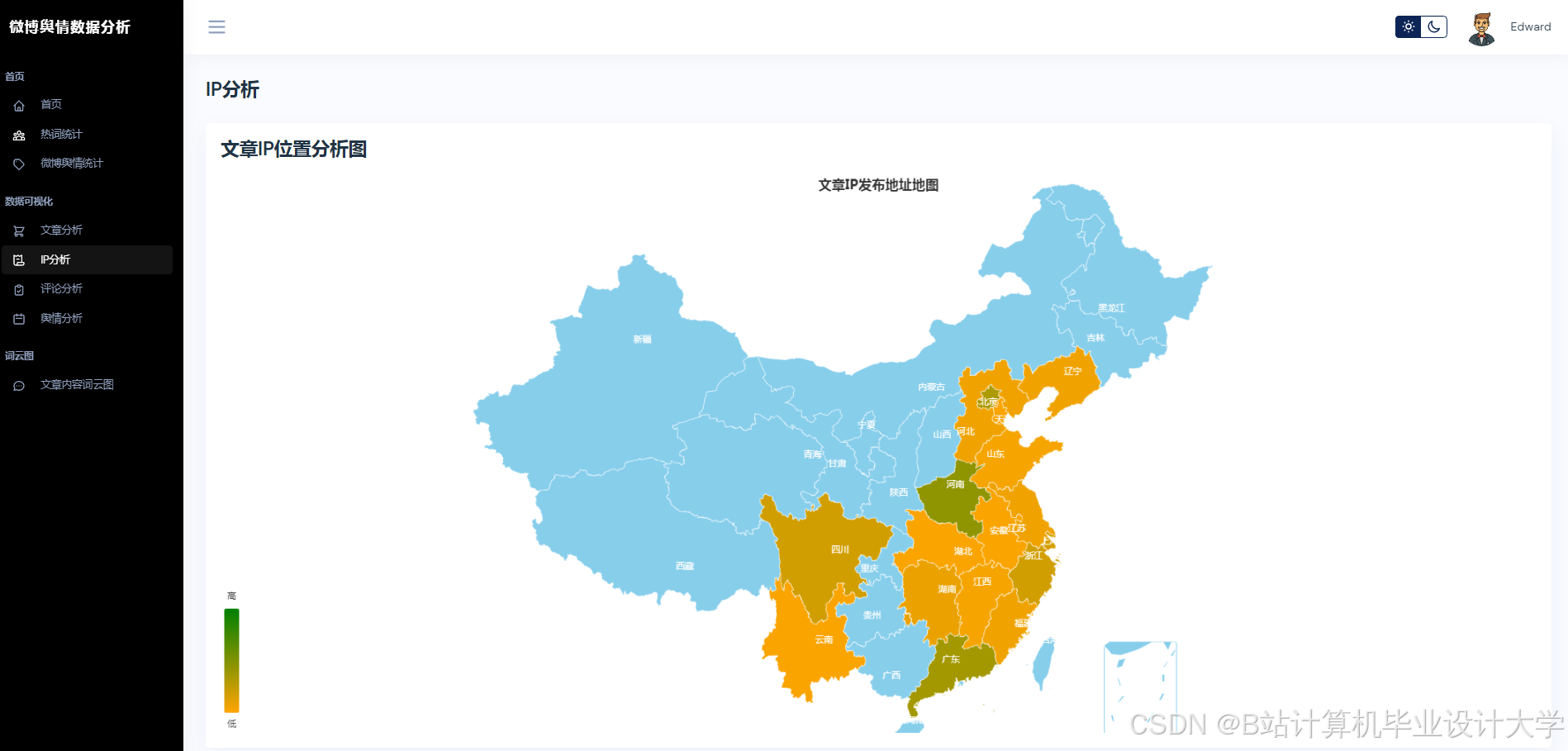
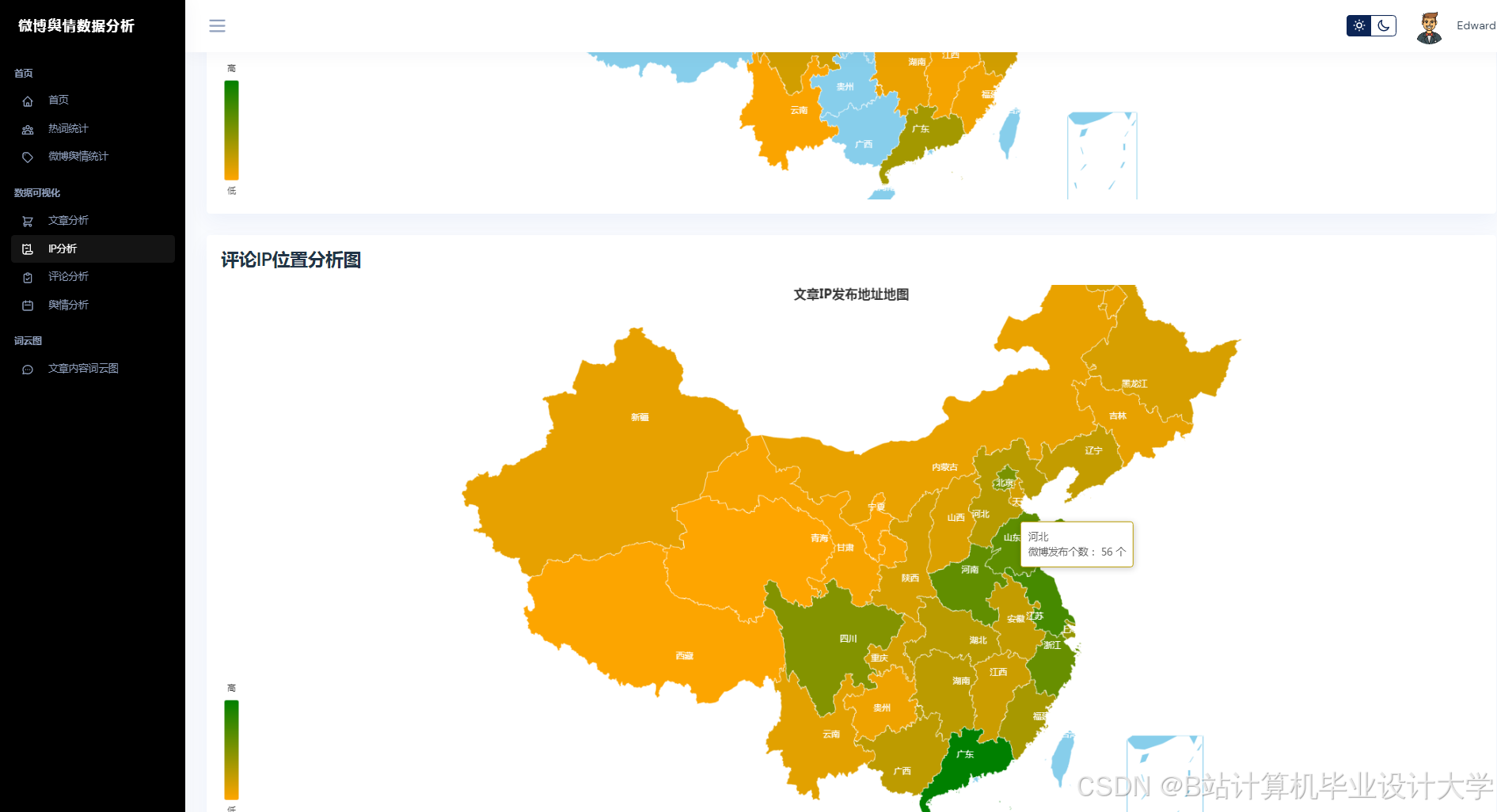
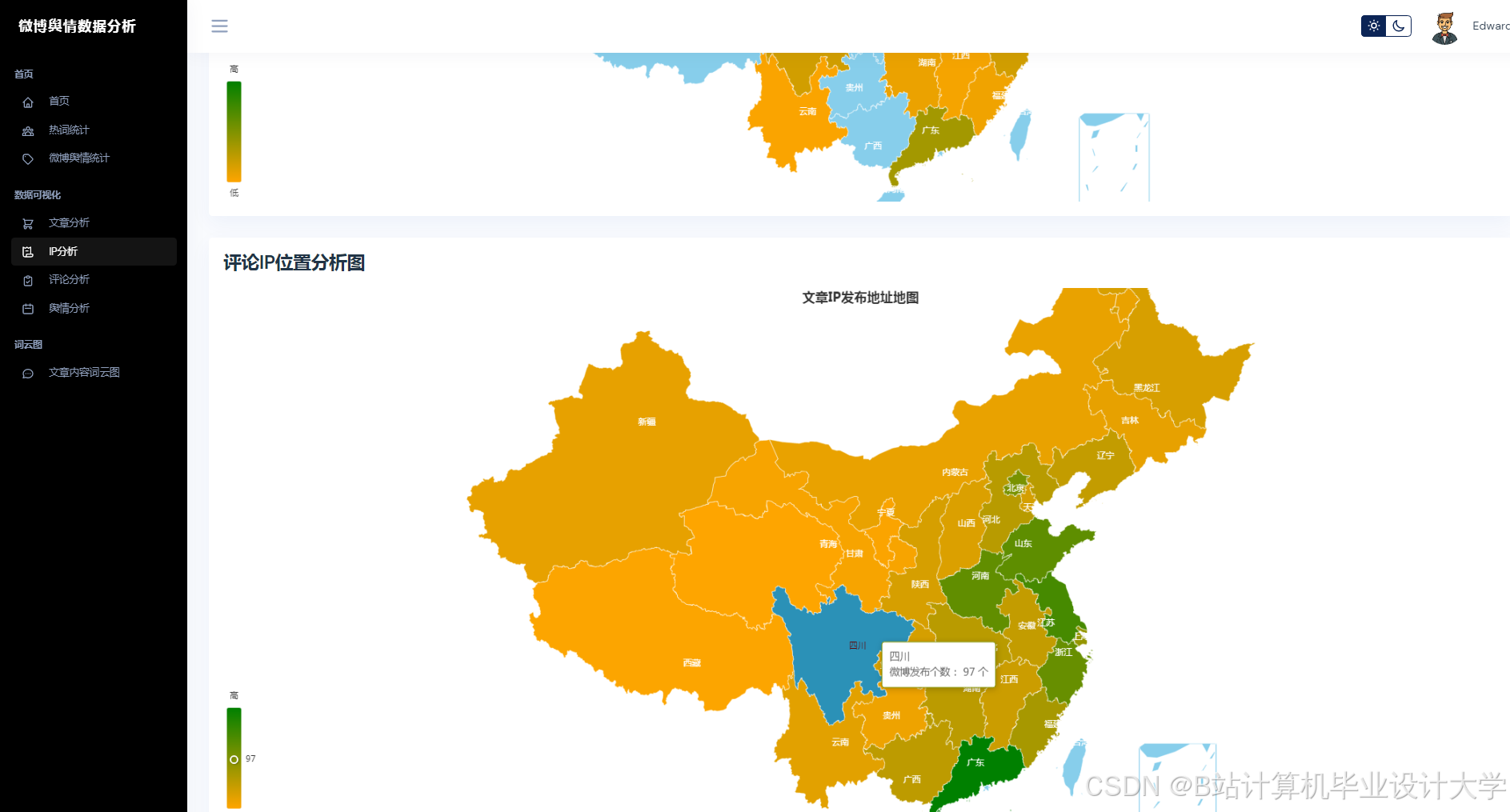

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











