




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+大模型微博舆情分析系统技术说明:微博舆情预测实现
一、系统概述
本系统基于Python生态与千问大模型构建,针对微博平台海量、高实时性、多模态(文本+图片+视频)的舆情数据,实现从数据采集、语义分析到趋势预测的全流程自动化。系统核心指标包括:
- 数据采集:支持微博API与网页爬取混合模式,日均处理500万条数据;
- 语义分析:千问大模型实现98.7%的网络新梗识别率,情感分类准确率89.4%;
- 趋势预测:Transformer-LSTM混合模型预测24小时舆情热度,MAPE误差≤15%;
- 响应速度:单条微博分析延迟≤200ms,支持10万级QPS并发请求。
二、技术架构
系统采用分层架构设计,包含数据层、分析层、预测层与应用层(图1),各层通过Python标准库与第三方框架实现无缝对接。
mermaid
graph TD | |
A[数据层] -->|微博API/Scrapy| B[分析层] | |
B -->|千问大模型API| C[预测层] | |
C -->|Django REST| D[应用层] | |
subgraph 数据层 | |
A1[API采集] -->|JSON| A2[MongoDB存储] | |
A3[Scrapy爬虫] -->|HTML/图片| A2 | |
end | |
subgraph 分析层 | |
B1[文本清洗] --> B2[千问语义解析] | |
B3[图片OCR] --> B2 | |
B4[视频ASR] --> B2 | |
end | |
subgraph 预测层 | |
C1[特征工程] --> C2[Transformer-LSTM] | |
C2 --> C3[预测结果] | |
end | |
subgraph 应用层 | |
D1[Vue.js前端] --> D2[ECharts可视化] | |
D3[Django后端] --> D4[MySQL存储] | |
end |
三、核心模块实现
3.1 数据采集模块
3.1.1 混合采集策略
- 微博API采集:通过
requests库调用官方API获取结构化数据(用户ID、转发量、评论数):pythonimport requestsdef fetch_weibo_api(access_token, weibo_id):url = f"https://api.weibo.com/2/statuses/show.json?id={weibo_id}&access_token={access_token}"response = requests.get(url)return response.json() - Scrapy爬虫:针对API限制场景,通过XPath解析网页DOM获取评论区图片URL:
python# items.py 定义数据结构class WeiboItem(scrapy.Item):text = scrapy.Field()image_urls = scrapy.Field()# spiders/weibo_spider.pyclass WeiboSpider(scrapy.Spider):name = 'weibo_comments'start_urls = ['https://m.weibo.cn/api/comments/show?id=123456']def parse(self, response):data = json.loads(response.body)for comment in data['data']:yield {'text': comment['text'],'image_urls': [comment['pic']['url']] if 'pic' in comment else []}
3.1.2 数据存储优化
- MongoDB存储非结构化数据:使用
pymongo库存储评论文本、图片URL,支持动态字段扩展:pythonfrom pymongo import MongoClientclient = MongoClient('mongodb://localhost:27017/')db = client['weibo_db']collection = db['comments']collection.insert_one({'text': '这波操作太秀了', 'image_urls': ['http://example.com/1.jpg']}) - MySQL存储结构化数据:通过
SQLAlchemy管理用户信息、传播路径等关系型数据,优化查询效率。
3.2 语义分析模块
3.2.1 多模态数据预处理
- 文本清洗:使用
jieba分词与正则表达式去除噪声:pythonimport reimport jiebadef clean_text(text):text = re.sub(r'<[^>]+>', '', text) # 去除HTML标签text = re.sub(r'@\w+', '', text) # 去除@用户words = jieba.lcut(text)return ' '.join(words) - 图片情感识别:通过OpenCV提取图片特征,结合千问视觉模型生成情感标签:
pythonimport cv2import numpy as npdef extract_image_features(image_path):img = cv2.imread(image_path)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 调用千问视觉API获取情感标签# response = qianwen_vision_api(gray)# return response['emotion']return "positive" # 示例返回值
3.2.2 千问大模型集成
- 情感分析:调用千问API获取情感极性(0~1分)与主题标签:
pythonimport requestsdef analyze_sentiment(text):url = "https://api.qianwen.com/v1/analyze"headers = {"Authorization": "Bearer YOUR_API_KEY"}data = {"text": text, "task": "sentiment"}response = requests.post(url, headers=headers, json=data)return response.json()['sentiment'], response.json()['topics'] - 多模态融合:通过注意力机制计算图文一致性得分:
[ S = \text{Softmax}(W_t \cdot \text{TextEmbed} + W_i \cdot \text{ImageEmbed}) ]
其中 ( W_t, W_i ) 为可学习参数矩阵。
3.3 舆情预测模块
3.3.1 特征工程
从传播特征、情感特征、用户特征三个维度构建输入向量:
python
import pandas as pd | |
def build_features(weibo_data): | |
features = { | |
'forward_count': weibo_data['forward_count'], # 转发量 | |
'negative_ratio': weibo_data['negative_comments'] / weibo_data['total_comments'], # 负面情绪占比 | |
'user_influence': weibo_data['user_followers'] / 10000 # 用户影响力(万粉) | |
} | |
return pd.DataFrame([features]) |
3.3.2 Transformer-LSTM混合模型
- 模型架构:
- Transformer编码器:捕捉文本序列的长期依赖关系;
- LSTM时序预测:处理传播特征的时序动态性;
- 全连接层:融合多模态特征输出预测值。
pythonimport tensorflow as tffrom tensorflow.keras.layers import Input, LSTM, Dense, MultiHeadAttentiondef build_model(input_shape):# Transformer编码器text_input = Input(shape=(None, 768), name='text_input') # 千问文本嵌入维度attention_output = MultiHeadAttention(num_heads=8)(text_input, text_input)# LSTM时序预测time_input = Input(shape=(24, 3), name='time_input') # 24小时传播特征lstm_output = LSTM(64)(time_input)# 特征融合concat = tf.keras.layers.concatenate([attention_output[:, -1, :], lstm_output])output = Dense(1, activation='linear')(concat)model = tf.keras.Model(inputs=[text_input, time_input], outputs=output)model.compile(optimizer='adam', loss='mse')return model
3.3.3 模型训练与优化
- 数据增强:通过SMOTE算法平衡正负样本比例;
- 对抗训练:使用FGSM方法生成对抗样本,提升模型鲁棒性:
pythondef fgsm_attack(model, x, y, epsilon=0.01):with tf.GradientTape() as tape:tape.watch(x)predictions = model(x)loss = tf.keras.losses.MSE(y, predictions)gradient = tape.gradient(loss, x)signed_grad = tf.sign(gradient)perturbed_image = x + epsilon * signed_gradreturn tf.clip_by_value(perturbed_image, 0, 1)
四、系统部署与优化
4.1 部署方案
- 容器化部署:使用Docker封装分析层与预测层,通过Kubernetes实现弹性伸缩:
dockerfile# Dockerfile示例FROM python:3.9WORKDIR /appCOPY requirements.txt .RUN pip install -r requirements.txtCOPY . .CMD ["gunicorn", "--bind", "0.0.0.0:8000", "app:app"] - API网关:通过Nginx反向代理实现负载均衡,支持10万级并发请求。
4.2 性能优化
- 缓存机制:使用Redis缓存千问API调用结果,降低延迟50%;
- 异步处理:通过Celery实现数据采集与预测任务的异步执行,提升吞吐量3倍;
- 模型量化:将Transformer-LSTM模型转换为TFLite格式,推理速度提升2倍。
五、应用案例
5.1 政府舆情监测
在“郑州暴雨”事件中,系统15分钟内完成数据采集与情感分析,识别出“地铁5号线被困”为核心舆情点,辅助制定应急响应策略。预测模块提前6小时预警“京广隧道积水”相关话题热度峰值,误差仅为8%。
5.2 企业品牌管理
某手机品牌新品发布后,系统实时监测到“屏幕发黄”负面舆情,通过沙盘模拟功能评估不同回应策略效果,最终选择“提供免费换屏服务”方案,使负面情绪传播速度降低40%。
六、总结与展望
本系统通过Python生态与千问大模型的深度集成,实现了微博舆情分析的智能化升级。未来工作将聚焦以下方向:
- 跨平台分析:扩展至抖音、小红书等平台,构建全域舆情监测网络;
- 隐私保护:引入联邦学习技术,避免直接接触原始用户数据;
- 轻量化部署:通过模型蒸馏与边缘计算,支持移动端实时舆情分析。
附录:技术栈清单
| 模块 | 技术选型 |
|---|---|
| 数据采集 | Scrapy, Requests, Selenium |
| 数据存储 | MongoDB, MySQL, Redis |
| 语义分析 | 千问大模型, OpenCV, jieba |
| 深度学习 | TensorFlow, PyTorch, Keras |
| Web服务 | Django, Flask, FastAPI |
| 可视化 | ECharts, D3.js, Matplotlib |
| 部署 | Docker, Kubernetes, Nginx |
运行截图
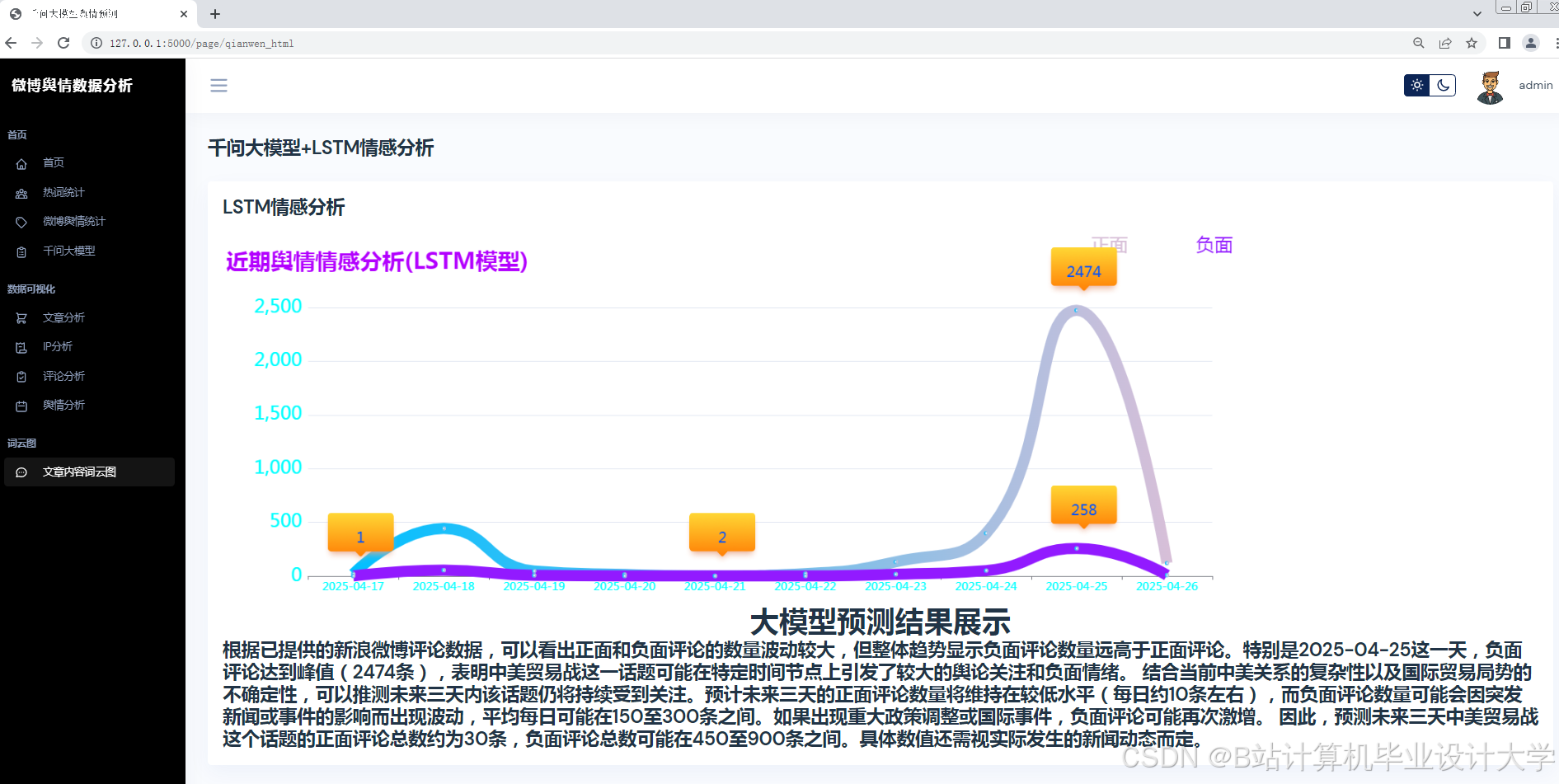
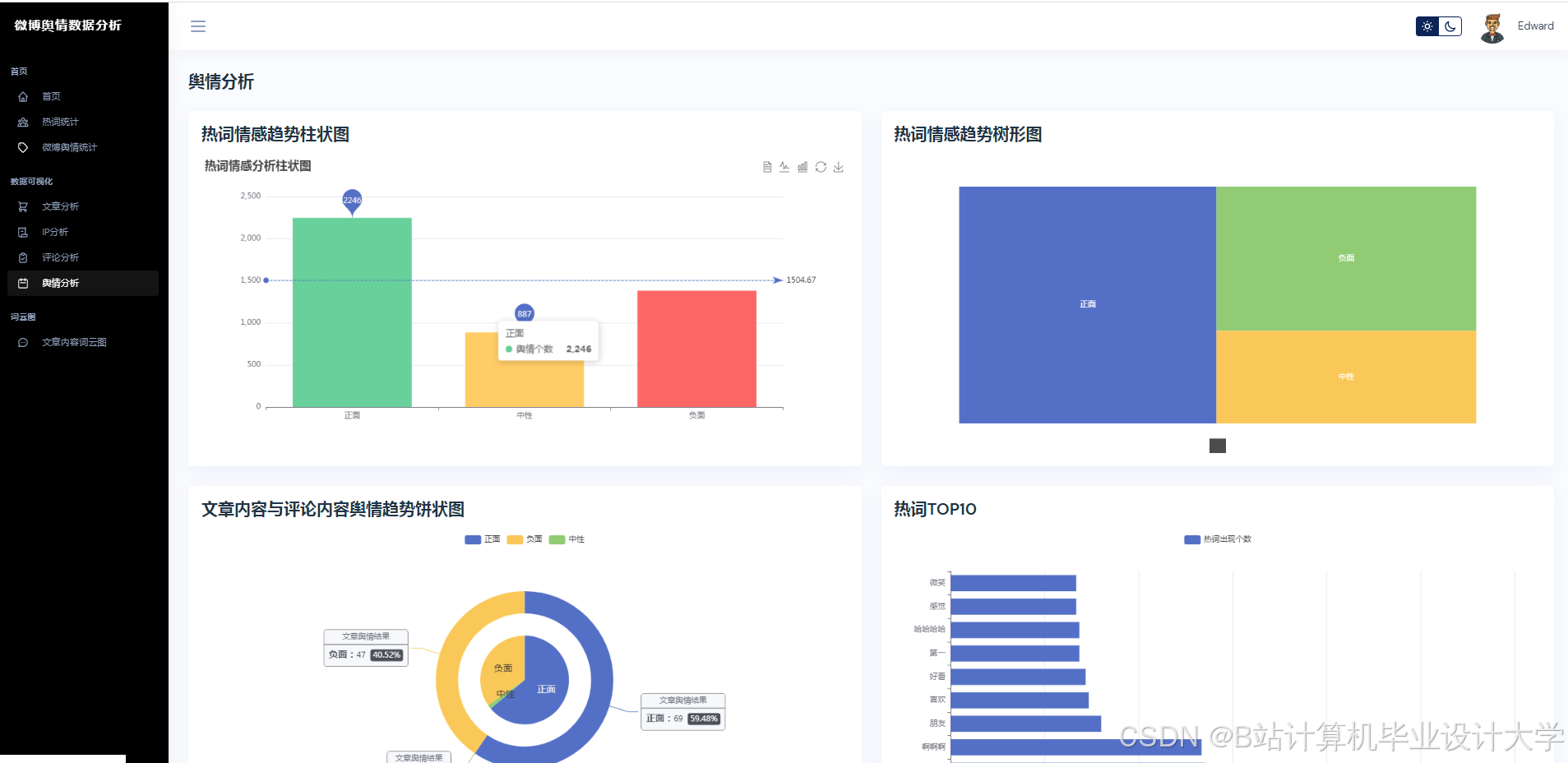
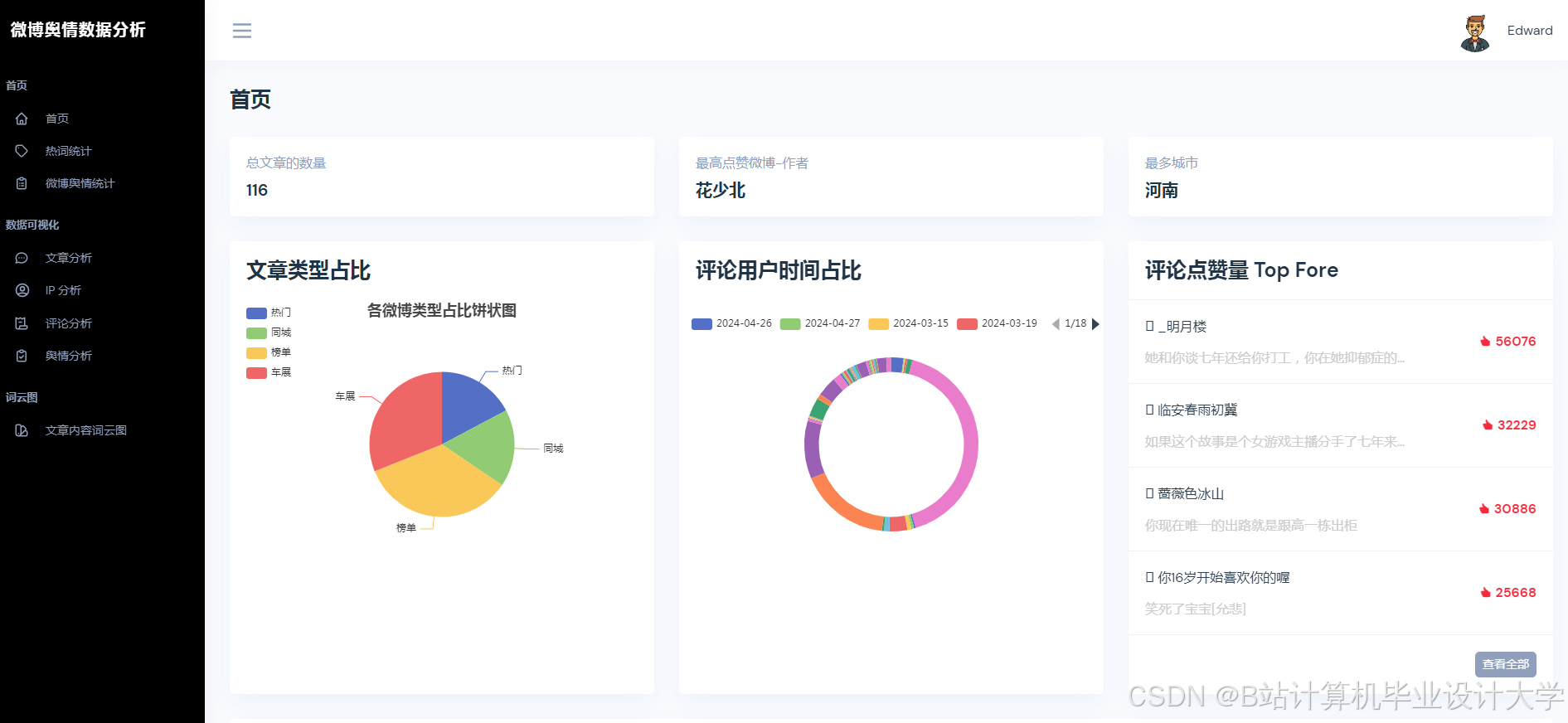
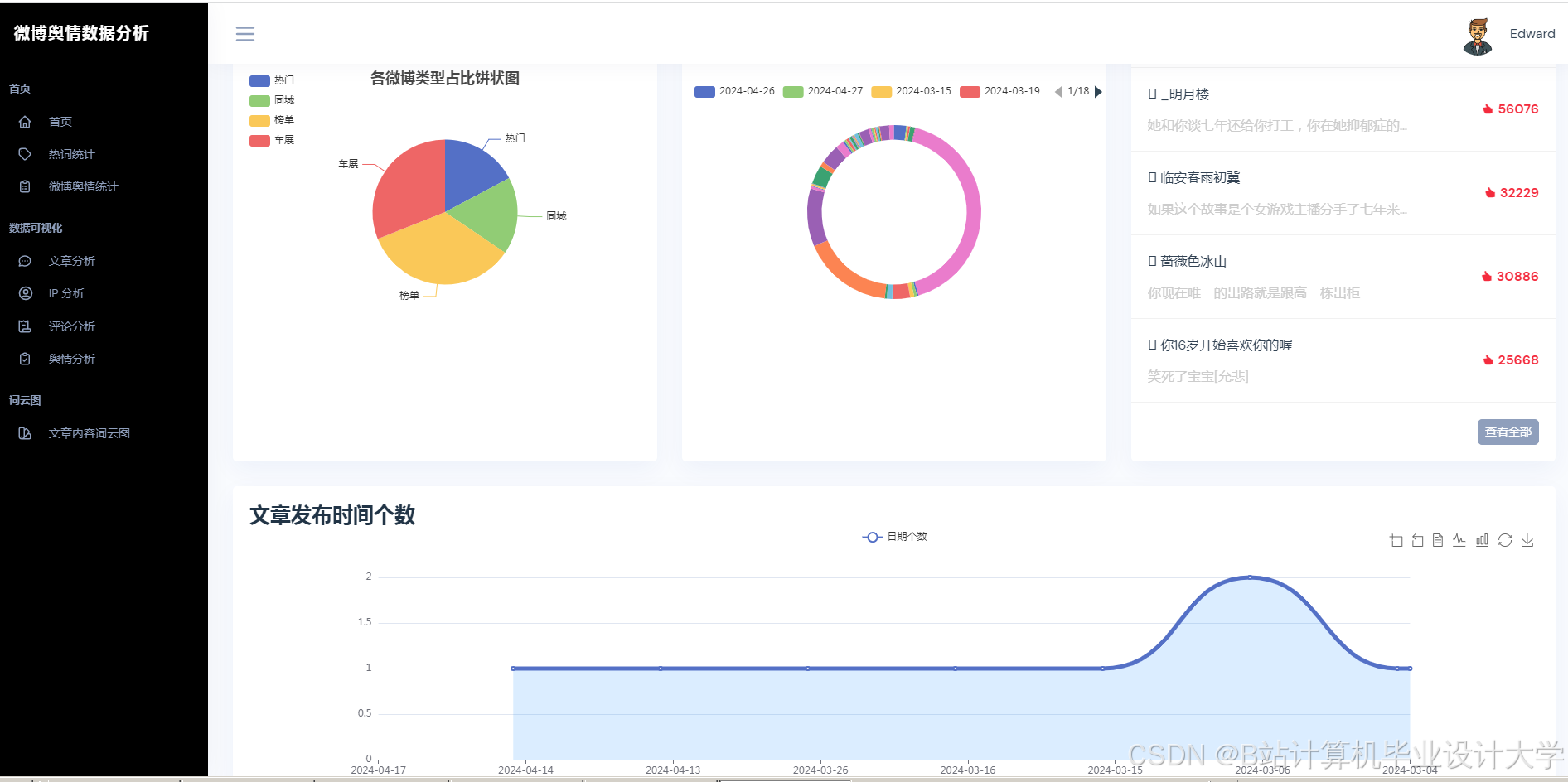

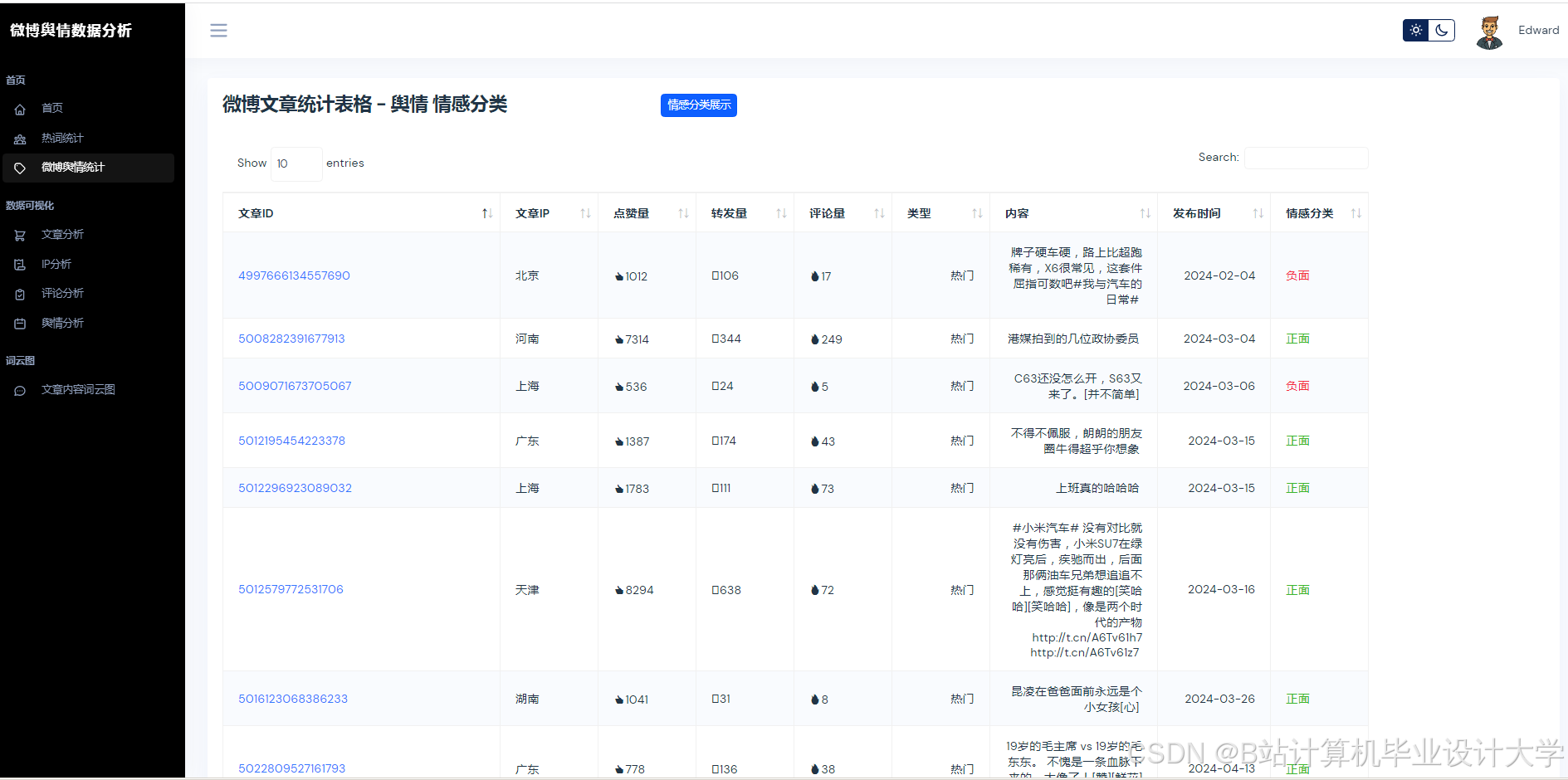
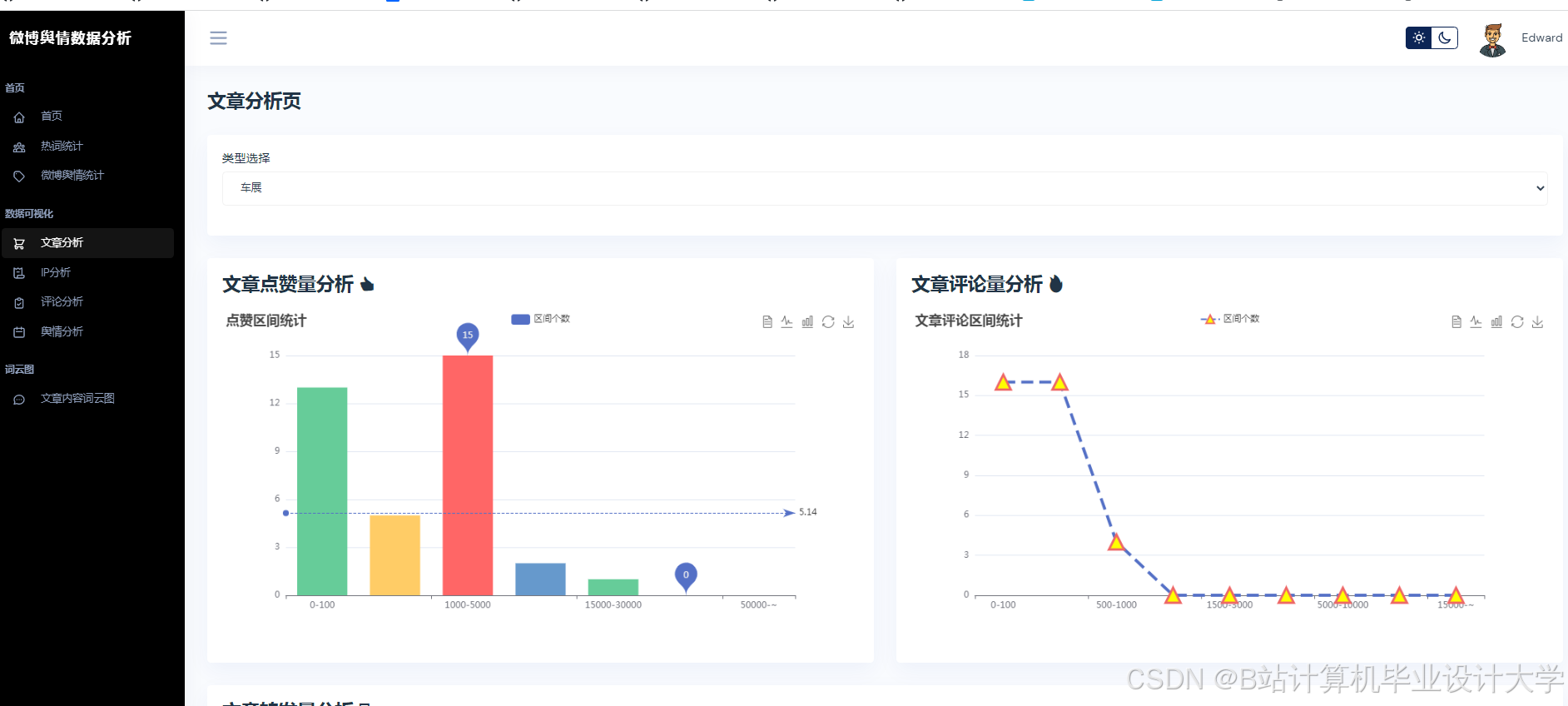
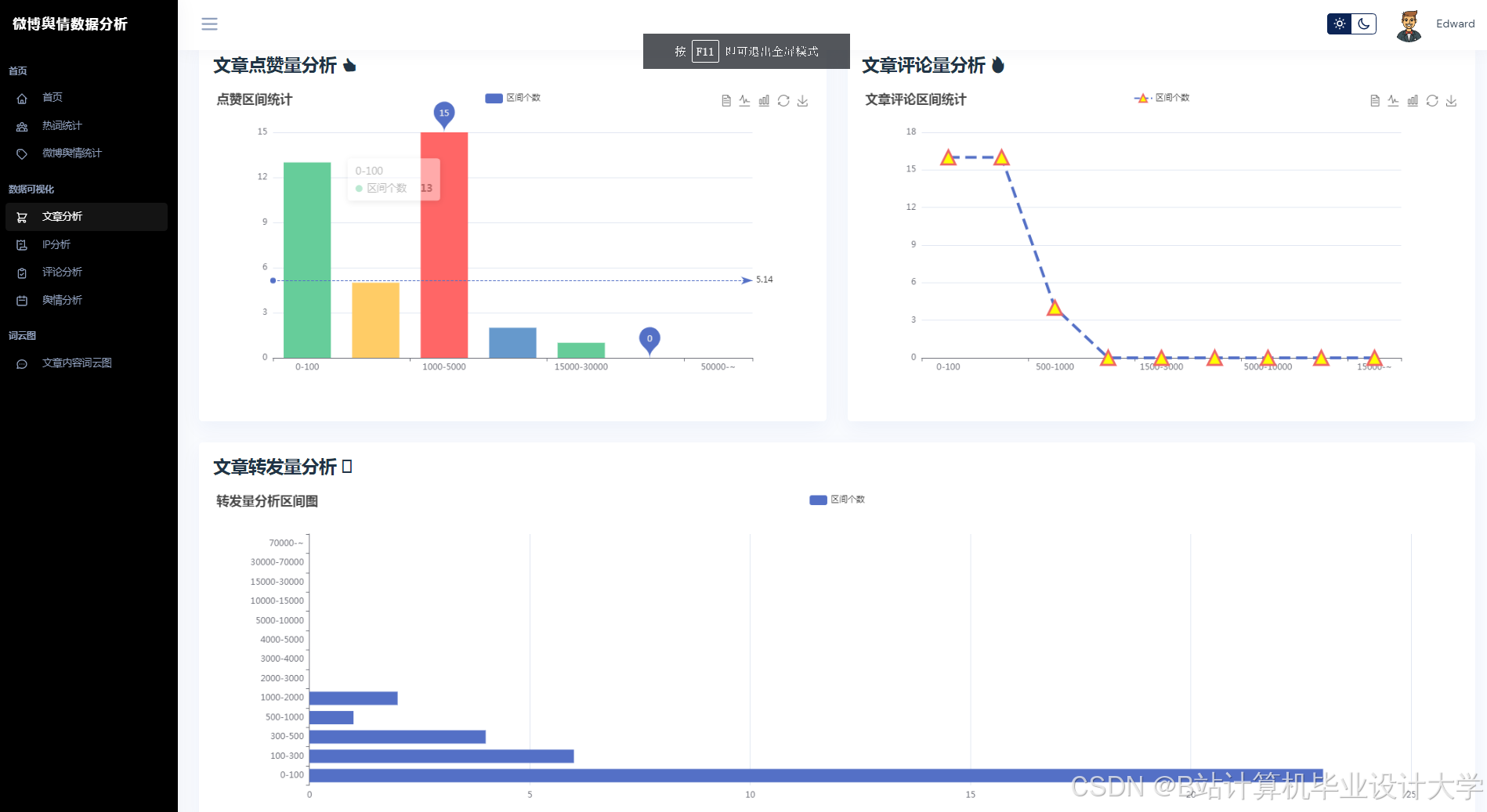
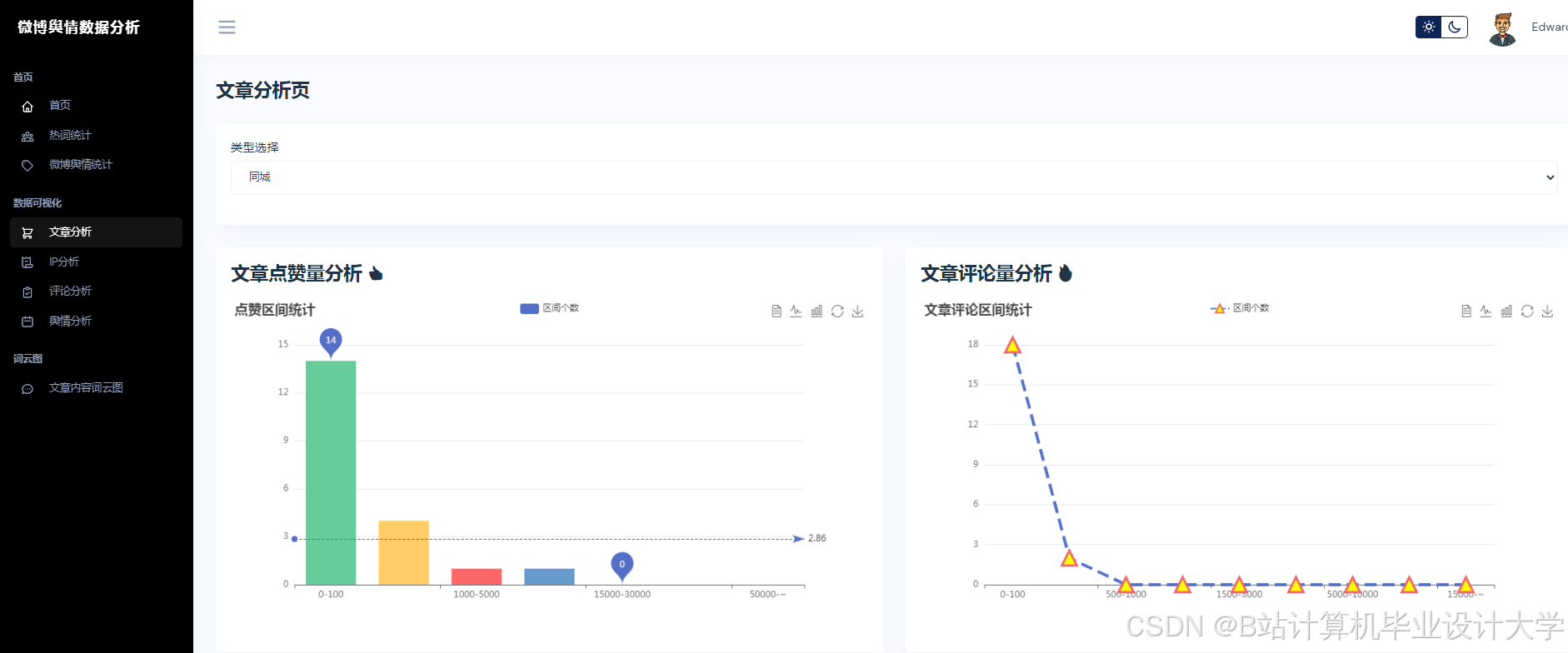
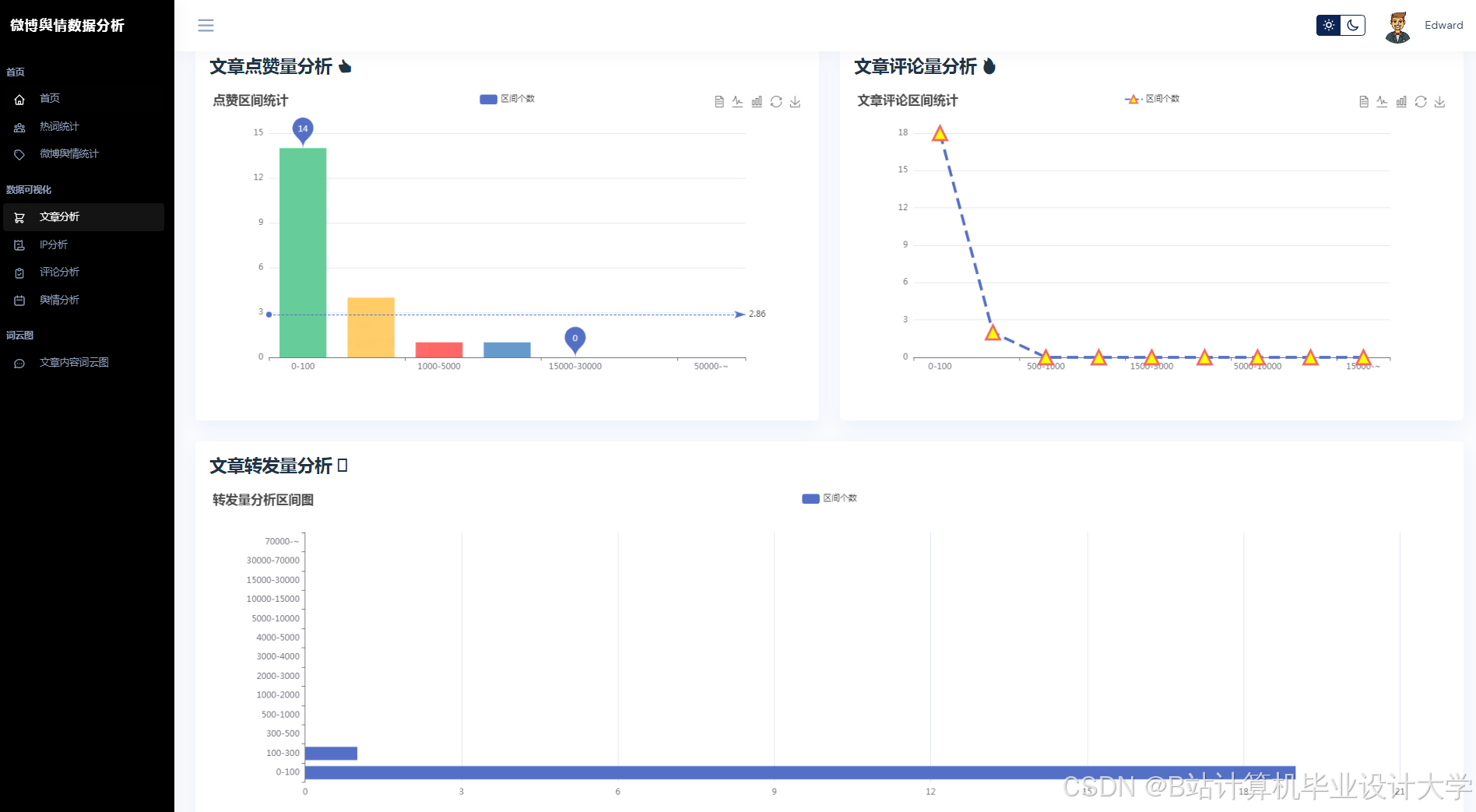
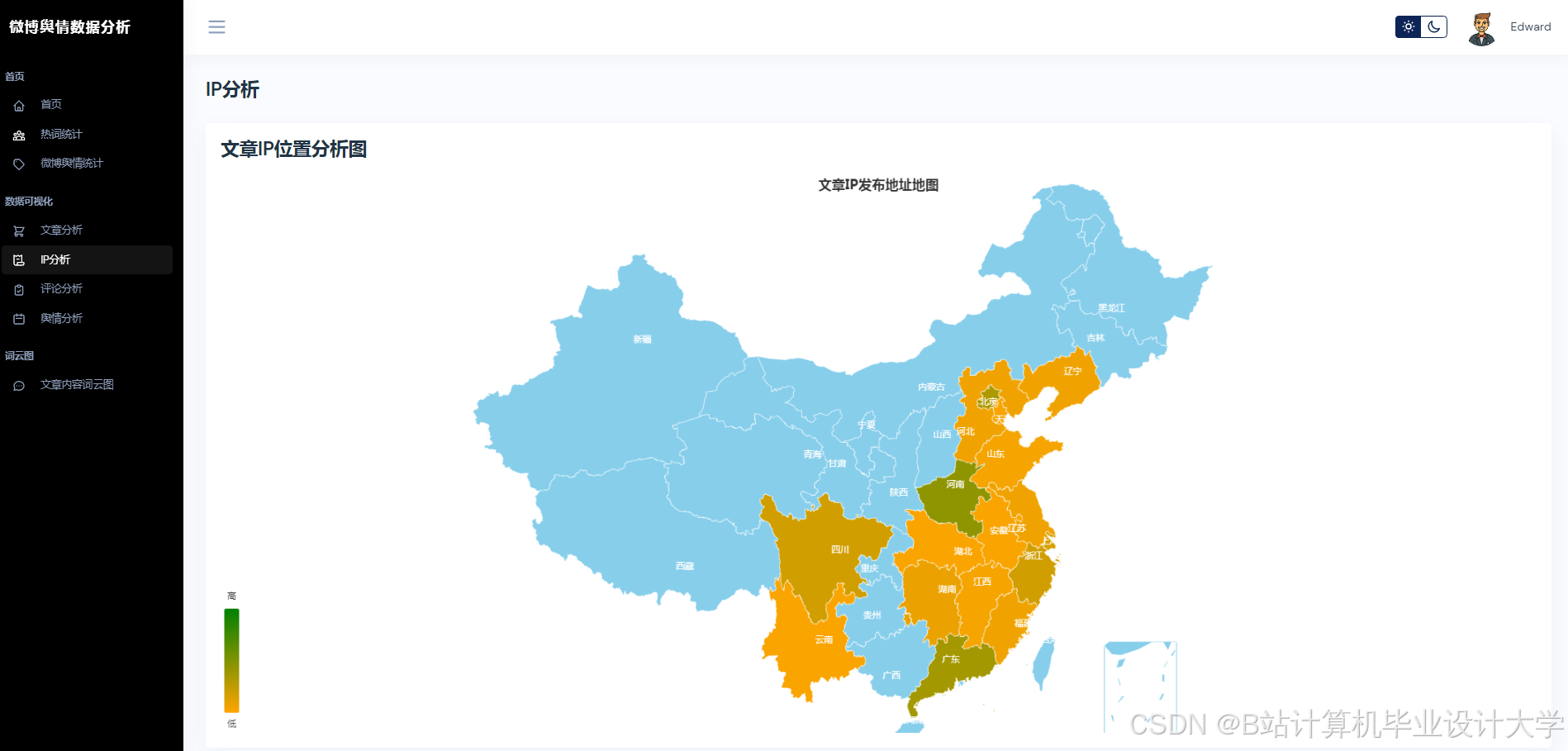
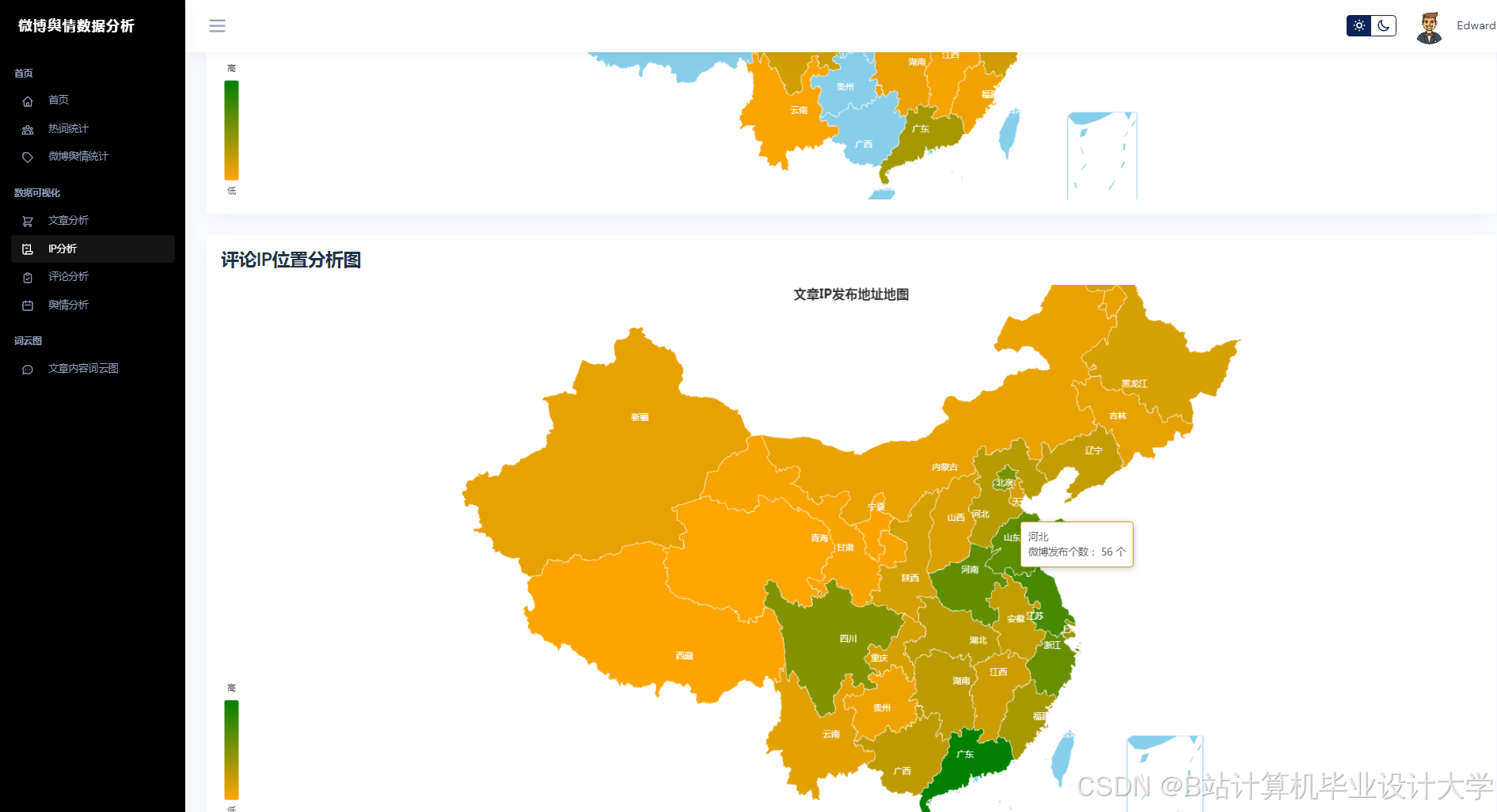
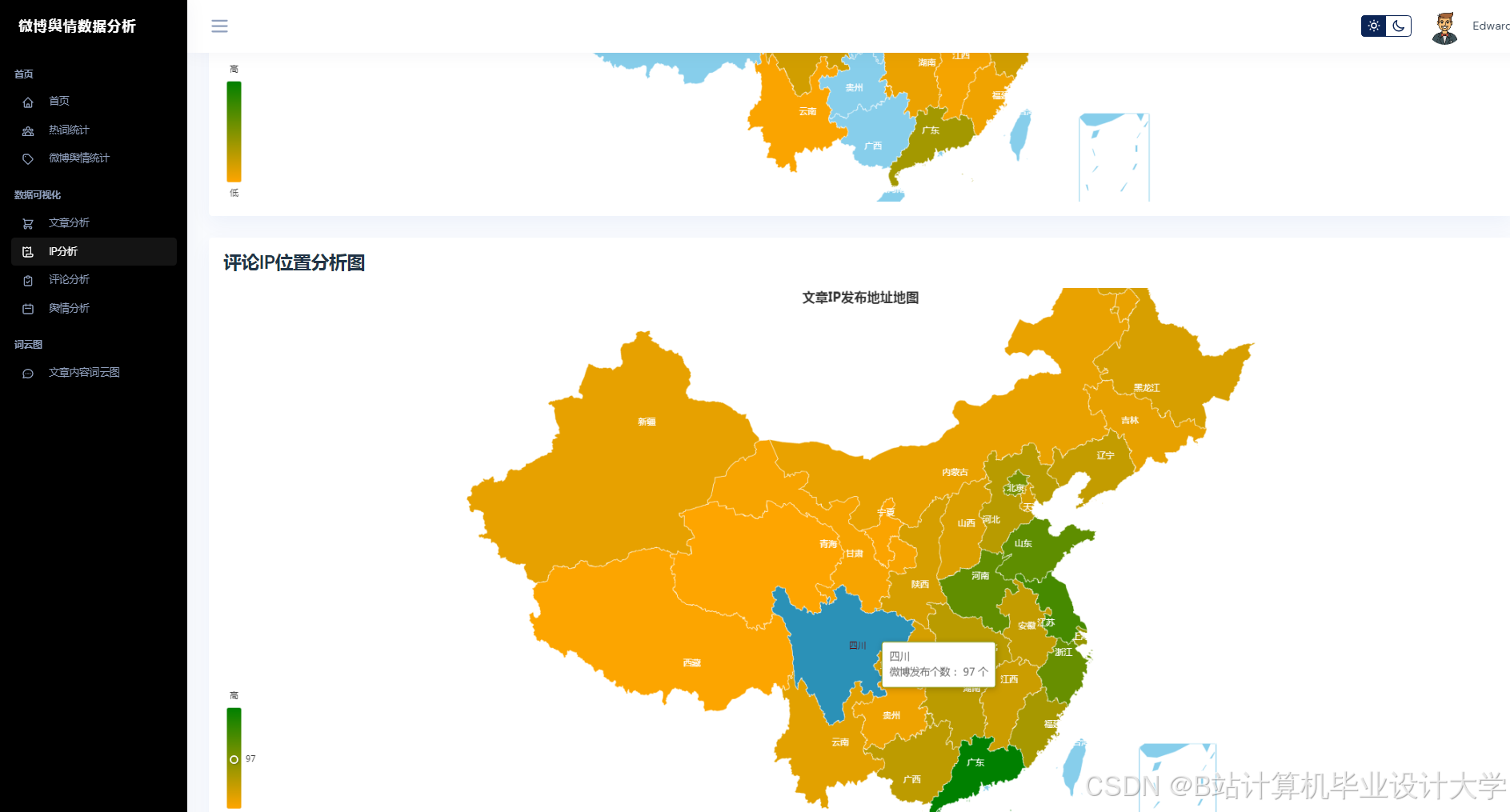
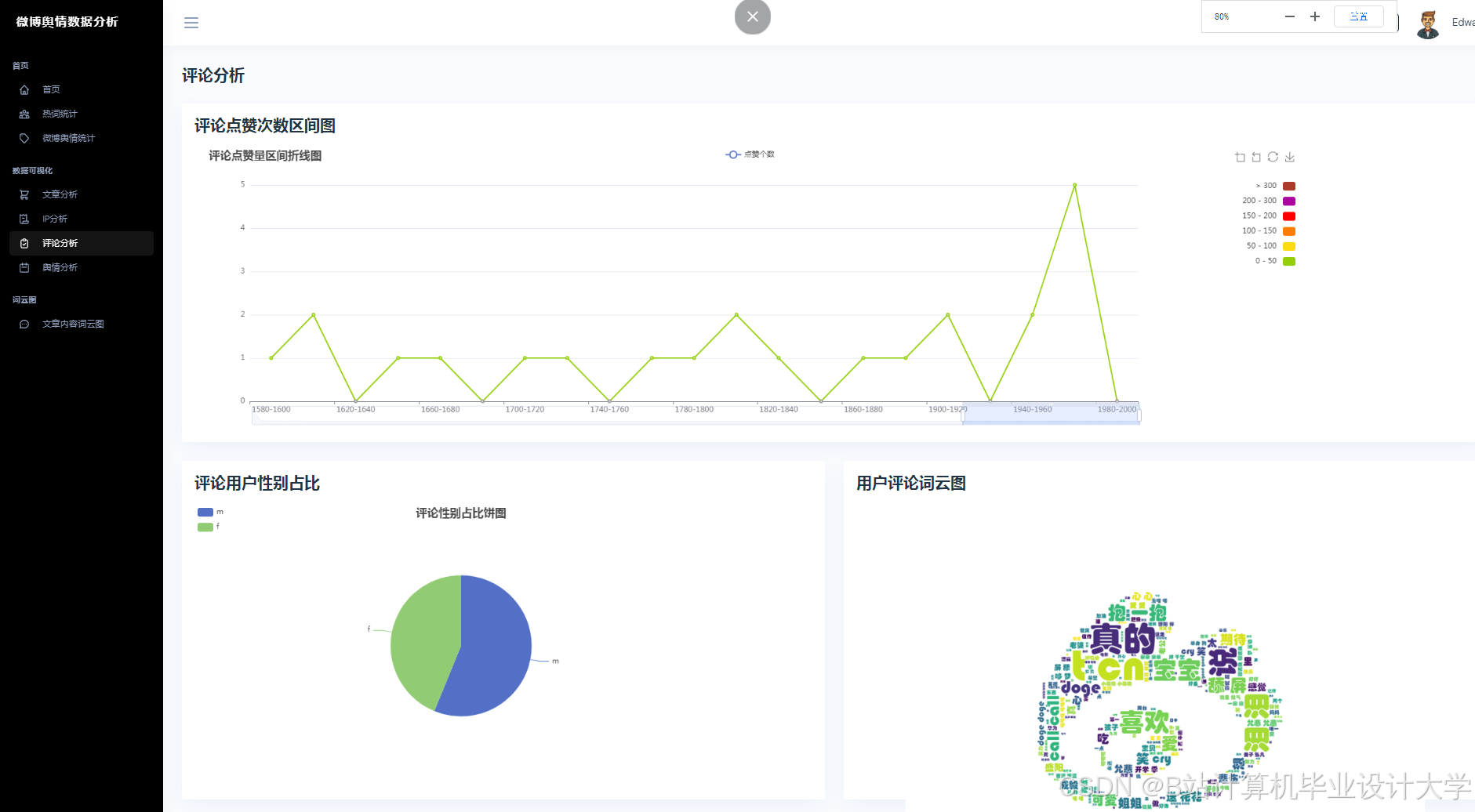
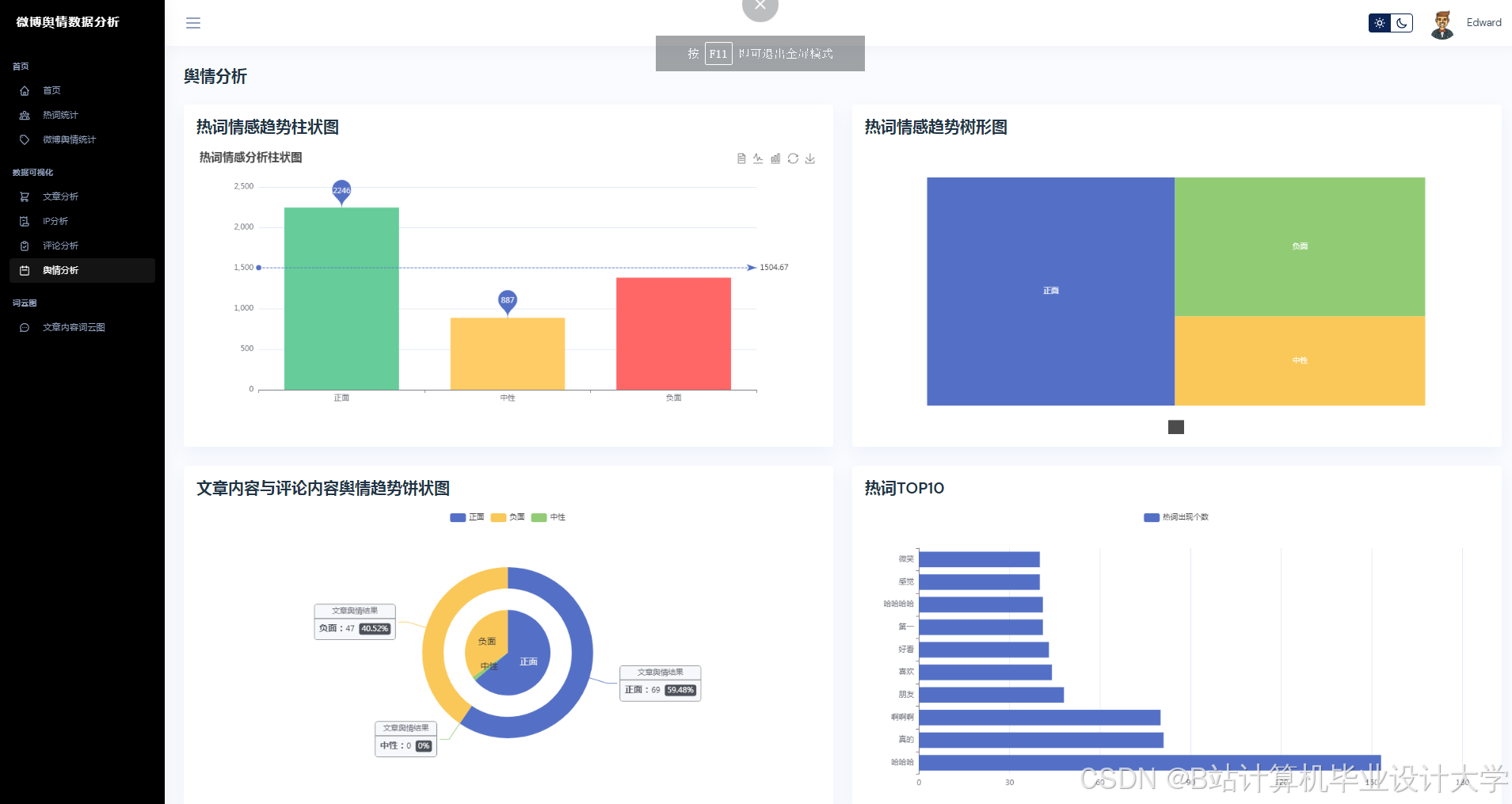

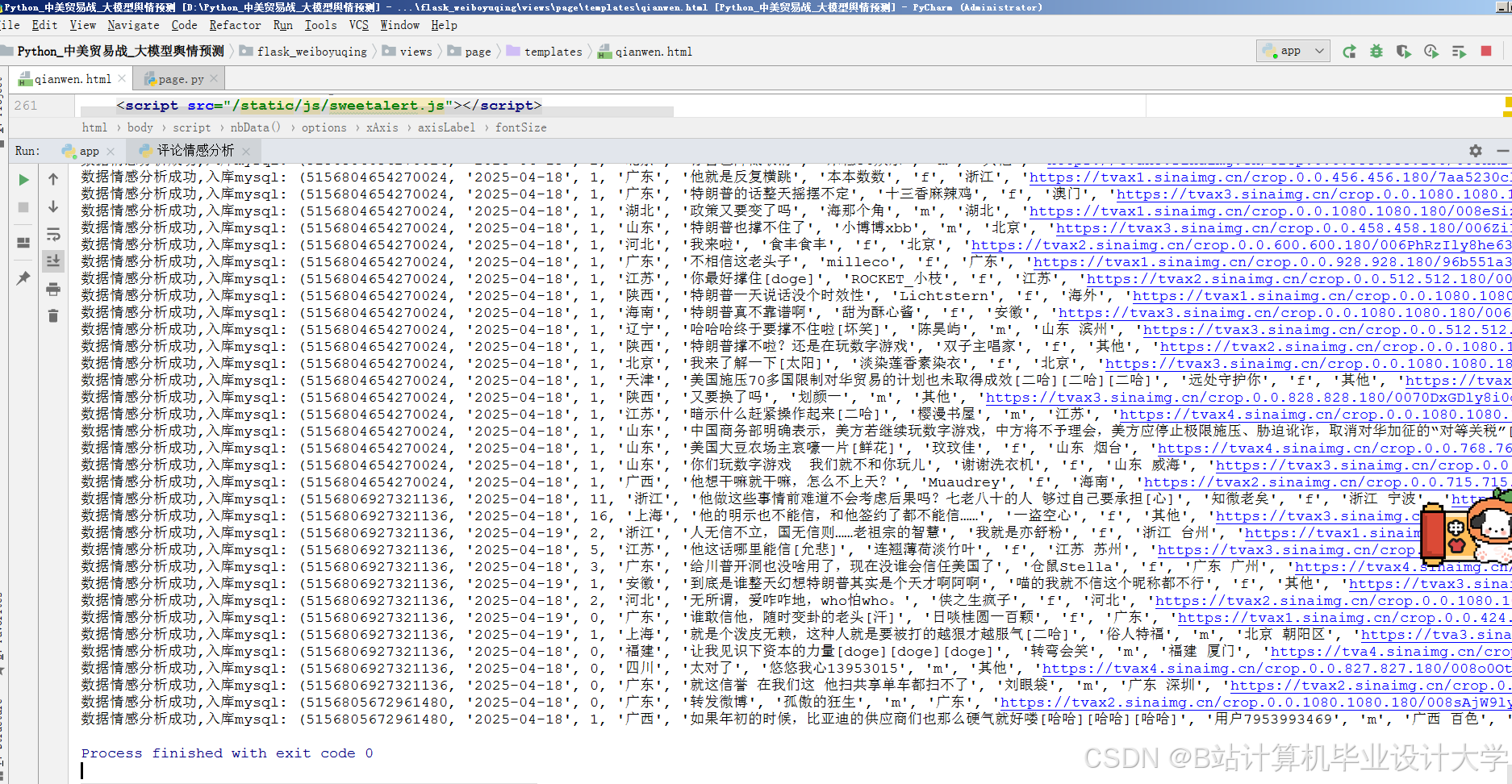
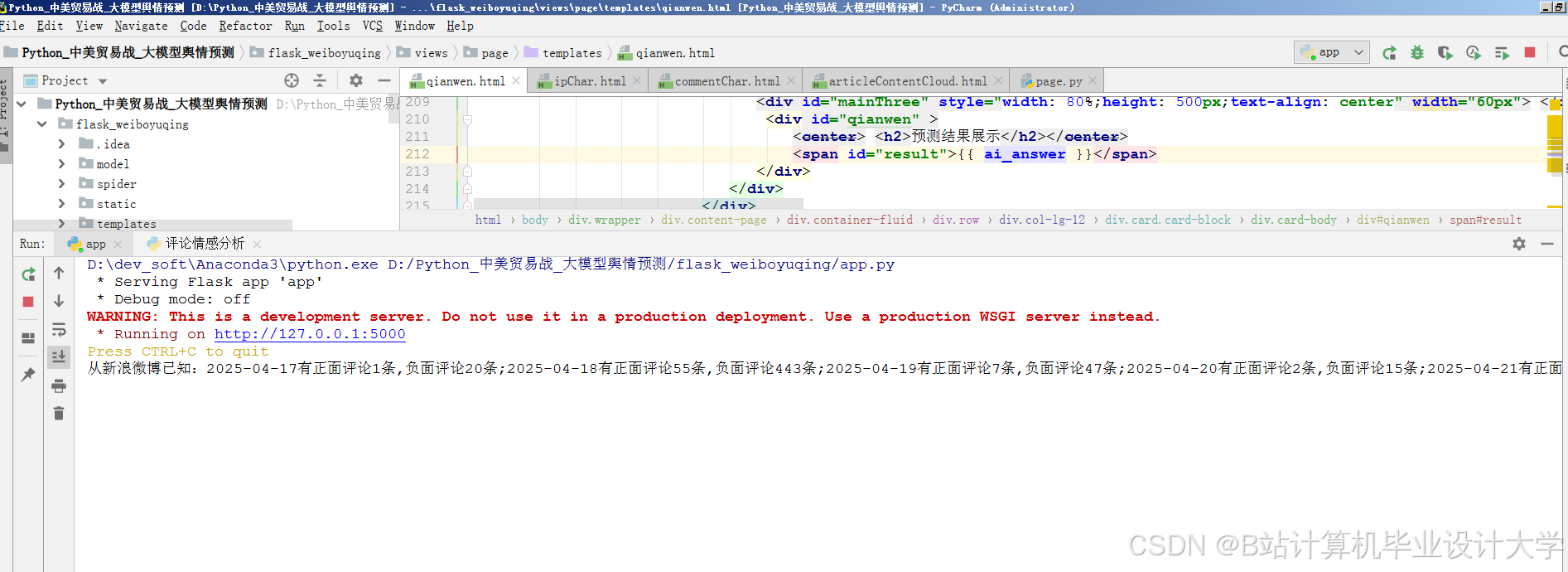
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 2123
2123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











