




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
《Python+大模型气象预测系统》开题报告
一、研究背景与意义
天气预测一直是人们关注的焦点,准确的天气预测对于农业、交通、能源、旅游等众多领域都有着重要的意义。随着大数据时代的到来,天气数据的获取和处理变得更加便捷,这也为天气预测分析提供了更多的可能性和工具。传统的天气预测方法主要基于气象观测数据和数值模式,通过建立复杂的物理模型进行预测。然而,随着大数据和机器学习技术的发展,基于数据驱动的天气预测方法逐渐受到关注,并取得了一系列重要进展。
本研究旨在开发一个基于Python和大模型(如深度学习模型)的气象预测系统,该系统能够实现对大量天气数据的快速处理和分析,提高天气预测的准确性和时效性。通过结合机器学习和可视化技术,该系统可以为用户提供更直观、更易于理解的预测结果,从而满足不同领域的需求。
二、研究目标与内容
研究目标
- 构建一个基于Python的气象数据收集与处理系统,实现实时和历史天气数据的获取、清洗和预处理。
- 利用大模型和机器学习算法,构建天气预测模型,并进行训练和调优,以提高预测的准确性。
- 设计并实现一个直观的可视化界面,用于展示预测结果和天气数据的变化趋势。
- 通过系统测试和性能优化,确保系统的稳定性和可靠性。
研究内容
- 数据收集与处理:通过合适的数据源收集历史天气数据,并进行数据清洗和预处理,为后续的分析和预测提供可用的数据集。
- 特征提取与建模:对预处理后的数据进行特征提取,利用机器学习算法(如LSTM、GRU等)建立天气预测模型。通过对模型进行训练和调优,提高预测的准确性。
- 预测结果评估:采用合适的评估指标对预测结果进行评估,包括准确率、召回率、F1分数等,以验证模型的有效性和可靠性。
- 可视化展示与系统实现:利用Python的可视化库(如Matplotlib、Plotly等),将预测结果进行可视化展示。设计并实现一个完整的天气数据预测分析及可视化系统,包括后台数据处理和前台用户界面两个部分。
三、研究方法与技术路线
研究方法
本研究将采用基于Python的数据分析和可视化技术,结合机器学习算法,构建一套完整的天气数据预测分析及可视化系统。具体方法包括:
- 数据收集与预处理:通过API接口或爬虫技术获取实时和历史天气数据,并进行数据清洗和预处理。
- 特征提取与建模:利用机器学习算法对预处理后的数据进行特征提取和建模,构建天气预测模型。
- 模型训练与调优:使用训练集对模型进行训练,并使用测试集评估模型的性能。通过调整超参数和优化模型结构,提高预测的准确性。
- 可视化展示与系统实现:利用Python的可视化库将预测结果进行可视化展示,并设计并实现一个完整的天气数据预测分析及可视化系统。
技术路线
本研究采用的技术路线主要包括以下几个步骤:
- 数据收集:通过气象观测站、卫星遥感、雷达和数值预报模型等多种方式收集天气数据。
- 数据处理:使用Python的数据处理库(如Pandas、NumPy等)对收集到的数据进行清洗、归一化和特征工程。
- 模型构建:利用深度学习框架(如TensorFlow、Keras等)构建天气预测模型,如LSTM、GRU等。
- 模型训练与调优:使用训练集对模型进行训练,并通过交叉验证、网格搜索等方法进行模型调优。
- 结果评估:采用合适的评估指标对预测结果进行评估,以验证模型的有效性和可靠性。
- 可视化展示:利用Python的可视化库将预测结果进行可视化展示,包括时间序列图、饼状图、箱线图等。
- 系统实现:设计并实现一个完整的天气数据预测分析及可视化系统,包括后台数据处理和前台用户界面两个部分。
四、预期成果与创新点
预期成果
- 构建一个基于Python和大模型的气象预测系统,实现对天气数据的快速处理和分析。
- 提高天气预测的准确性和时效性,为用户提供更直观、更易于理解的预测结果。
- 通过系统测试和性能优化,确保系统的稳定性和可靠性。
创新点
- 结合大数据技术和机器学习算法进行天气预测,提高了预测的准确性和时效性。
- 设计并实现了一个直观的可视化界面,方便用户理解和应用天气预测结果。
- 系统具有可扩展性和灵活性,可以根据用户需求进行定制和优化。
五、研究计划与进度安排
本研究计划分为以下几个阶段进行:
- 第一阶段(1-2个月):完成研究背景和国内外研究现状的调研工作,明确研究目标和任务。
- 第二阶段(3-4个月):进行数据收集、预处理和特征提取工作,建立初步的天气预测模型。
- 第三阶段(5-6个月):完成模型的训练和调优工作,进行预测结果评估。
- 第四阶段(7-8个月):开发系统后台功能,包括数据处理和分析模块的实现。
- 第五阶段(9-10个月):开发系统前端功能,完成用户界面的设计和实现。
- 第六阶段(11-12个月):进行系统测试和性能优化工作,完善论文写作并准备答辩。
六、参考文献
[此处列出相关参考文献,由于是开题报告,可以简要列出一些与天气预测、大数据、机器学习等相关的书籍、论文和网站]
以上是基于《Python+大模型气象预测系统》的开题报告内容,希望对您有所帮助。如有需要,您可以根据实际情况进行调整和补充。
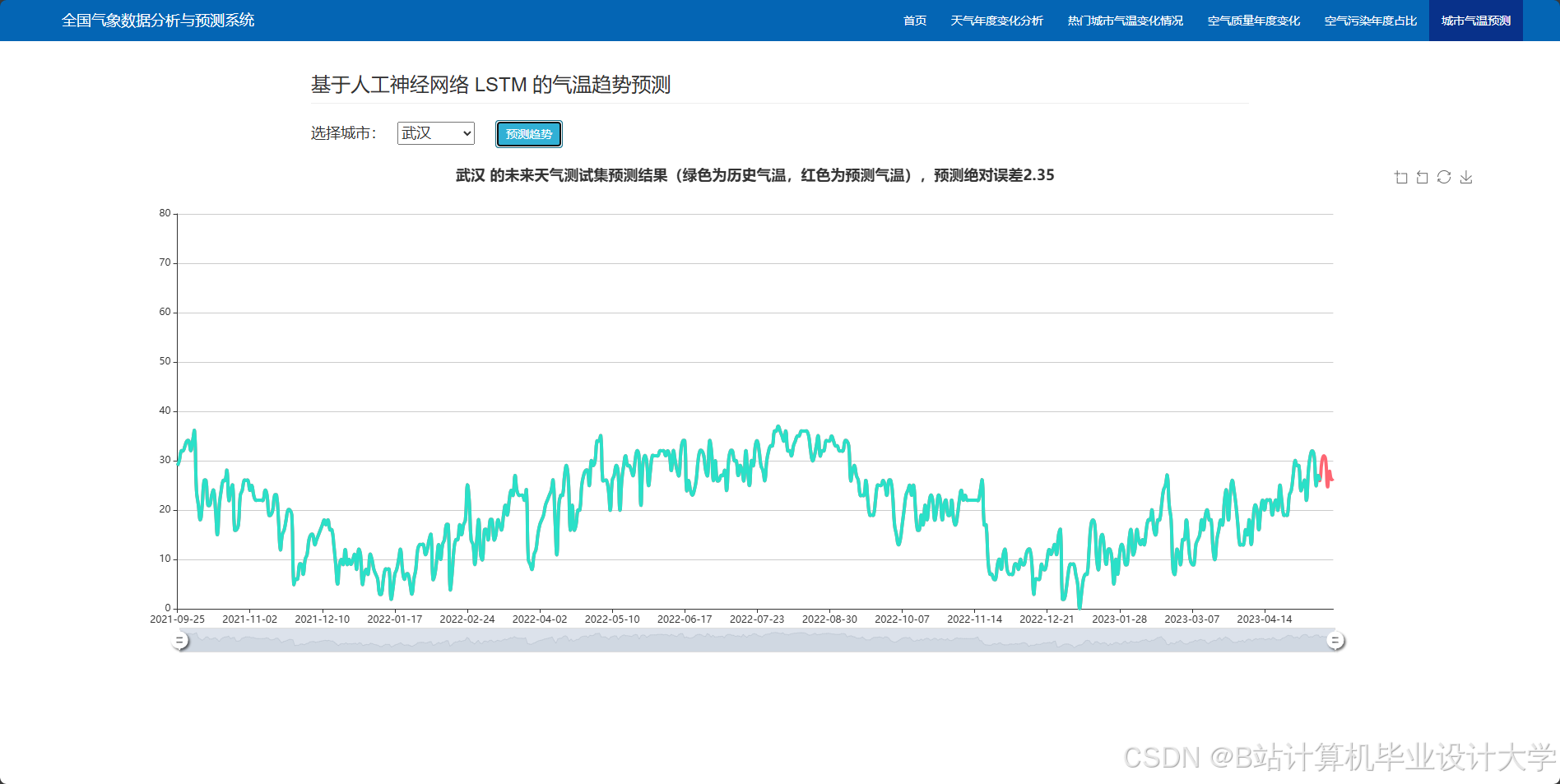
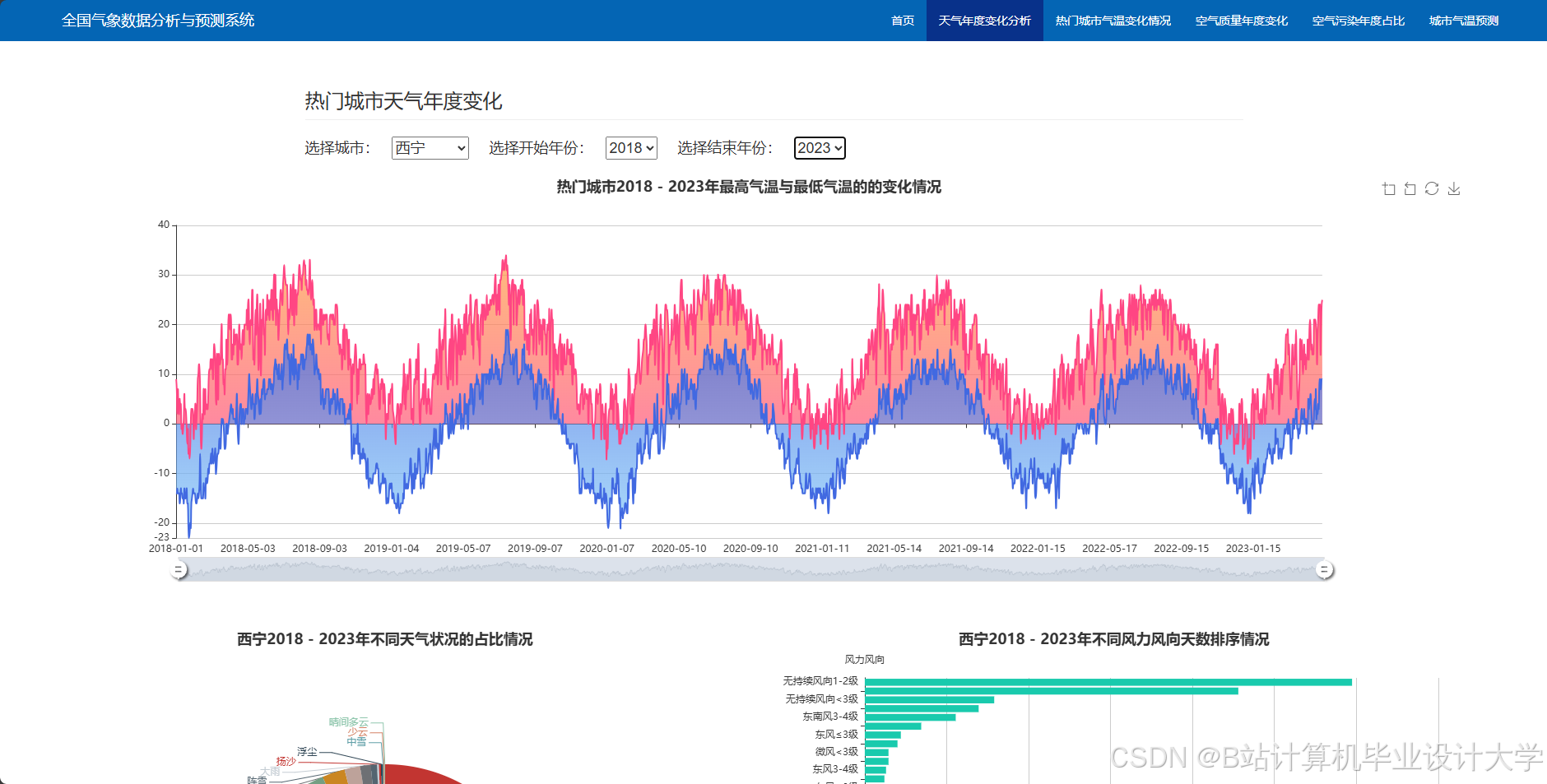
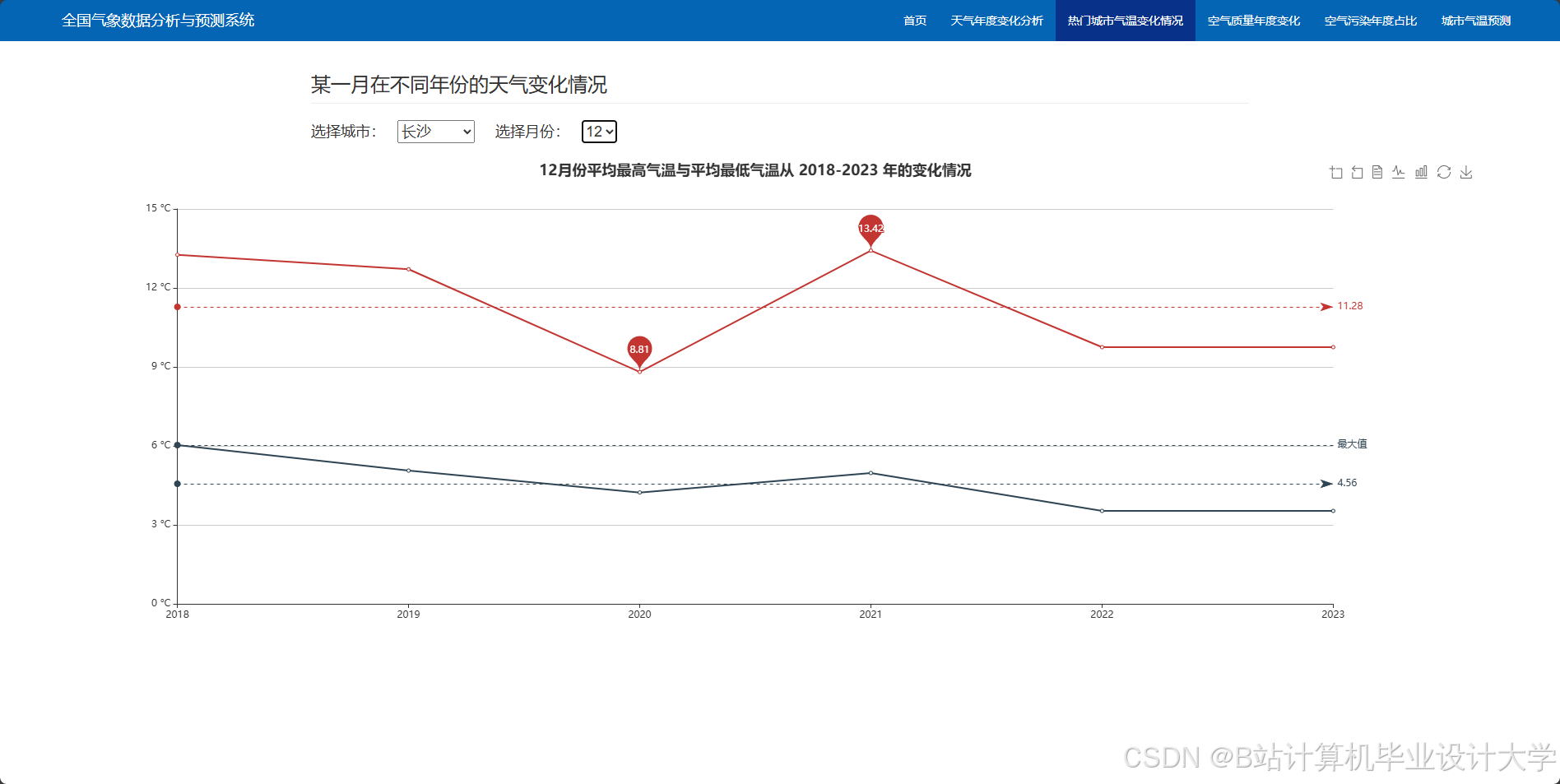
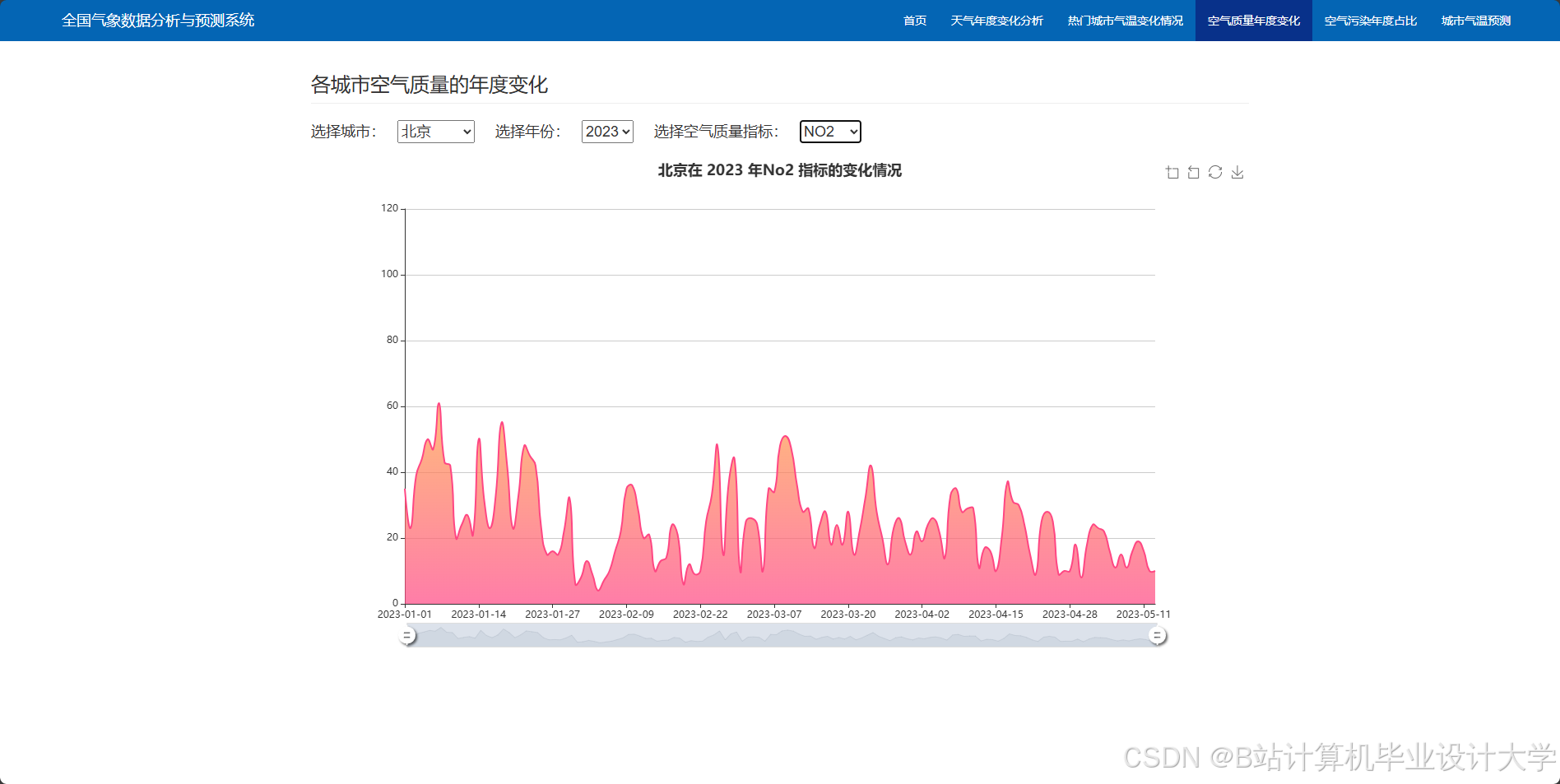
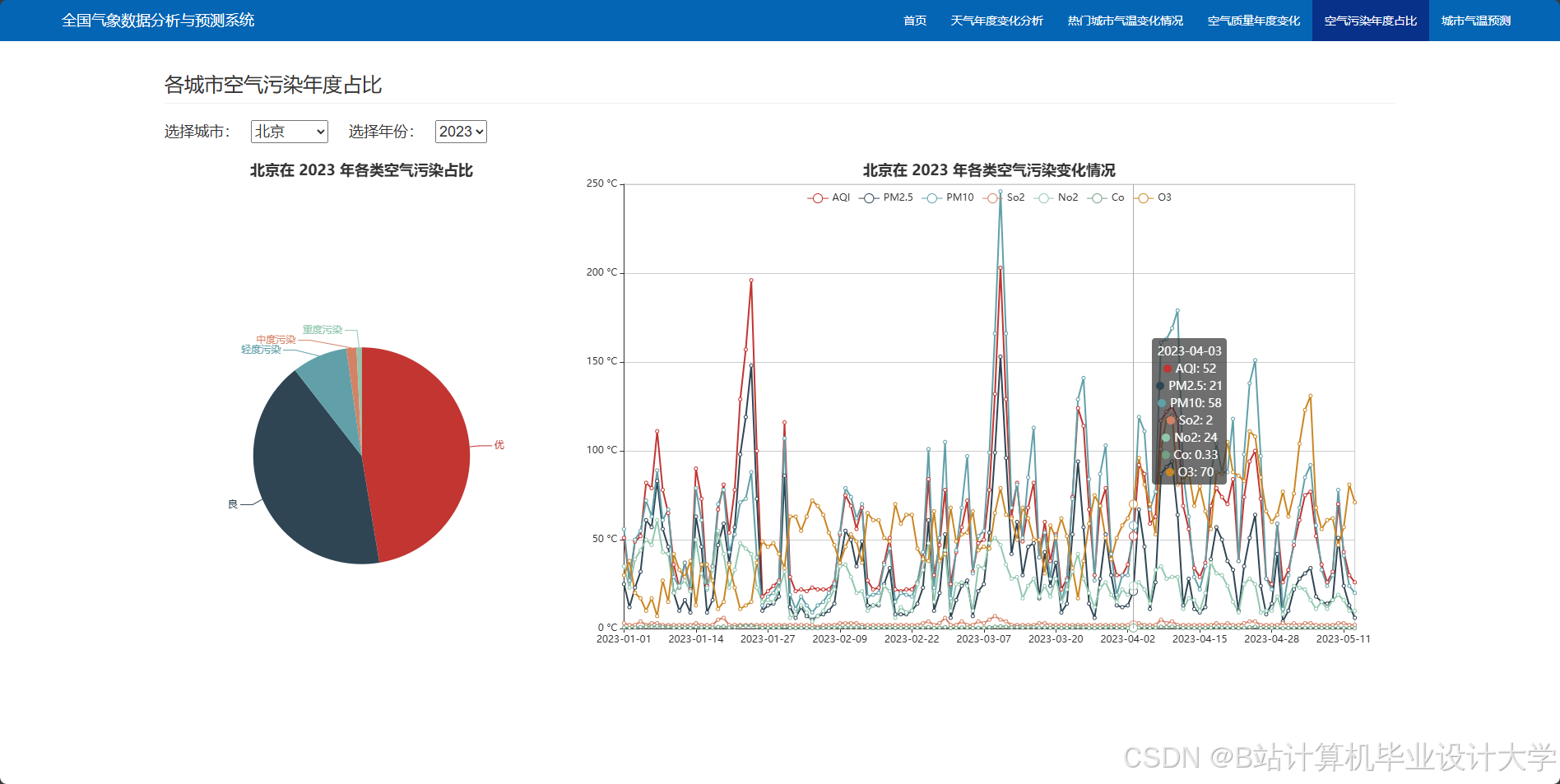
编写一个完整的气象预测深度学习算法代码涉及多个步骤,包括数据预处理、模型构建、训练和评估。以下是一个简化的示例,使用Python和TensorFlow/Keras库来构建和训练一个基本的神经网络模型进行气象预测。
假设我们有一个CSV文件weather_data.csv,其中包含日期、温度、湿度、风速等特征,以及我们要预测的目标变量(例如,未来一天的温度)。
1. 导入必要的库
python复制代码
import pandas as pd | |
import numpy as np | |
from sklearn.model_selection import train_test_split | |
from sklearn.preprocessing import StandardScaler | |
from tensorflow.keras.models import Sequential | |
from tensorflow.keras.layers import Dense, LSTM | |
from tensorflow.keras.optimizers import Adam | |
import matplotlib.pyplot as plt |
2. 数据预处理
python复制代码
# 读取数据 | |
data = pd.read_csv('weather_data.csv') | |
# 假设CSV文件包含以下列:['date', 'temperature', 'humidity', 'wind_speed', 'target_temperature'] | |
# 提取特征和目标变量 | |
features = data[['temperature', 'humidity', 'wind_speed']] | |
target = data['target_temperature'] | |
# 将日期列转换为时间特征(可选,这里简单处理) | |
# data['date'] = pd.to_datetime(data['date']) | |
# data['day_of_year'] = data['date'].dt.dayofyear | |
# features = data[['day_of_year', 'temperature', 'humidity', 'wind_speed']] | |
# 标准化特征 | |
scaler = StandardScaler() | |
features_scaled = scaler.fit_transform(features) | |
# 创建时间序列数据 | |
def create_sequences(data, seq_length): | |
xs, ys = [], [] | |
for i in range(len(data) - seq_length): | |
x = data[i:i + seq_length] | |
y = target[i + seq_length] | |
xs.append(x) | |
ys.append(y) | |
return np.array(xs), np.array(ys) | |
SEQ_LENGTH = 10 # 使用过去10天的数据预测未来一天的温度 | |
X, y = create_sequences(features_scaled, SEQ_LENGTH) | |
# 划分训练集和测试集 | |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) | |
# 重塑输入数据以符合LSTM输入要求 [samples, time steps, features] | |
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], X_train.shape[2])) | |
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], X_test.shape[2])) |
3. 构建模型
python复制代码
model = Sequential() | |
model.add(LSTM(50, return_sequences=True, input_shape=(SEQ_LENGTH, features.shape[1]))) | |
model.add(LSTM(50)) | |
model.add(Dense(1)) | |
model.compile(optimizer=Adam(learning_rate=0.001), loss='mean_squared_error') |
4. 训练模型
python复制代码
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.1, verbose=1) |
5. 评估模型
python复制代码
# 预测 | |
y_pred = model.predict(X_test) | |
# 计算均方误差(MSE) | |
mse = np.mean((y_test - y_pred.flatten()) ** 2) | |
print(f'Mean Squared Error: {mse}') | |
# 可视化结果 | |
plt.figure(figsize=(10, 5)) | |
plt.plot(y_test, label='True Values') | |
plt.plot(y_pred, label='Predicted Values') | |
plt.legend() | |
plt.show() |
注意事项
- 数据预处理:实际项目中,数据预处理可能更加复杂,包括处理缺失值、异常值、特征工程等。
- 模型选择:LSTM(长短期记忆网络)适合处理时间序列数据,但根据具体任务和数据,可能需要尝试其他模型,如GRU、CNN或Transformer。
- 超参数调优:学习率、批次大小、层数、神经元数量等超参数对模型性能有显著影响,可以通过网格搜索或随机搜索进行调优。
- 评估指标:除了MSE,还可以考虑其他评估指标,如MAE(平均绝对误差)、R²(决定系数)等。
这个示例代码提供了一个基本的框架,实际应用中需要根据具体需求进行调整和优化。


















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











