




流程:
1.爬取贝壳租房信息约1000万条,可以选择你想要爬取的城市,爬完生成.csv文件同时向mysql数据库保存一份;
2.上传csv到hdfs中,使用hive建表导入CSV数据。
3.一部分分析使用Spark实时计算完成,一部分分析使用hive sql完成;
4.计算结果使用sqoop工具对接到mysql数据库的指标表;
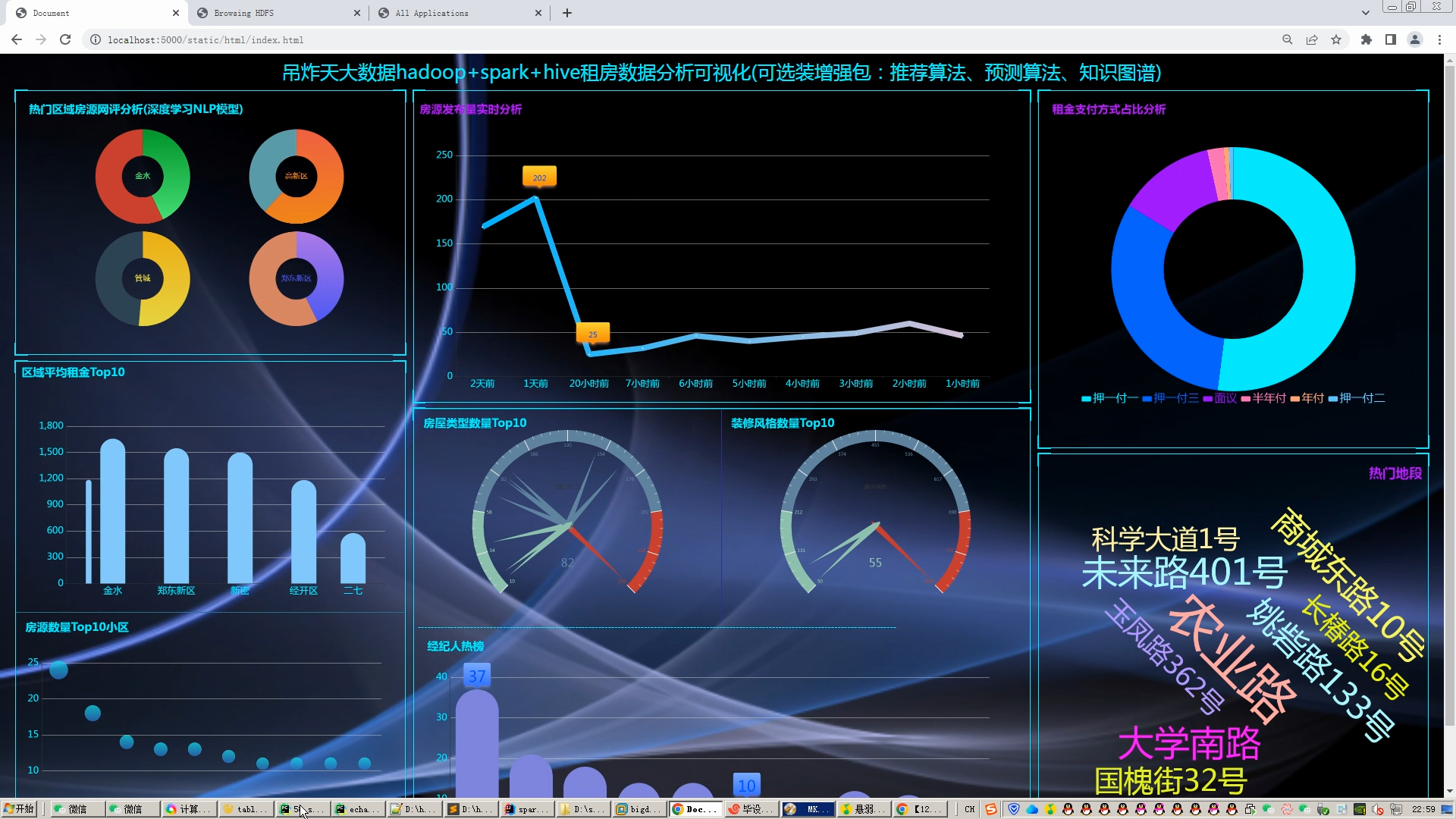
5.使用flask+echarts制作可视化大屏;
创新点:selenium采集海量租房数据、可视化大屏、spark+hive离线计算实时计算全部实现、使用NLP文本分类模型对租房信息的评论部分进行深度学习训练分析
注意:如果还觉得系统太简单不够工作量,可以选装推荐系统、预测系统、知识图谱、后台管理,我这边能1秒无缝对接
核心算法代码分享如下:
from flask import Flask, request
import json
from flask_mysqldb import MySQL
# 创建应用对象
app = Flask(__name__)
app.config['MYSQL_HOST'] = 'bigdata'
app.config['MYSQL_USER'] = 'root'
app.config['MYSQL_PASSWORD'] = '123456'
app.config['MYSQL_DB'] = 'beike_hive'
mysql = MySQL(app) # this is the instantiation
@app.route('/tables01')
def tables01():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table01''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['area','bads','goods'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables02')
def tables02():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table02''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['area','avg_pay'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables03')
def tables03():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table03 order by num desc''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['house_estate','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables04')
def tables04():
cur = mysql.connection.cursor()
cur.execute('''
select * from (
SELECT ctime,num,CAST(replace(ctime,'小时前','') AS UNSIGNED) ctime2 FROM table04 where ctime like '%小时前%'
union all
SELECT ctime,num,CAST(replace(ctime,'天前','')*24 AS UNSIGNED) ctime2 FROM table04 where ctime like '%天前%'
)t order by t.ctime2 desc;
''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['ctime','num','ctime2'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
# @app.route("/getmapcountryshowdata")
# def getmapcountryshowdata():
# filepath = r"D:\\hadoop_spark_hive_mooc2024\\server\\data\\maps\\china.json"
# with open(filepath, "r", encoding='utf-8') as f:
# data = json.load(f)
# return json.dumps(data, ensure_ascii=False)
@app.route('/tables05')
def tables05():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table05''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['agent_name','hot'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables06')
def tables06():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table06''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['house_type','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables07')
def tables07():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table07''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['house_decora','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables08')
def tables08():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table08''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['house_pay_way','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables09')
def tables09():
cur = mysql.connection.cursor()
#cur.execute('''SELECT SUBSTRING(address) address,num FROM table09''')
cur.execute('''SELECT SUBSTRING(address,-5) address,num FROM table09''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['address','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
if __name__ == "__main__":
app.run(debug=False)


















 8425
8425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











