- 博客(176)
- 资源 (9)
- 收藏
- 关注
 RSS订阅
RSS订阅 1
1原创 Hive查询之分组与Join
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。(1)计算emp表每个部门的平均工资(2)计算emp每个部门中每个岗位的最高薪水Having语句where后面不能写分组函数,而having后面可以使用分组函数。having只用于group by分组统计语句。(1)求每个部门的平均薪水大于2000的部门求每个部门的平均薪水大于2000的部门Join语句等值Join案例实操表的别名好处使用别名可以简化查询
2025-02-16 12:17:57
 728
728
原创 SparkSubmit进程无法强制kill掉以及Flink相关error
SparkSubmit进程无法强制kill掉以及Flink相关error:Caused by: java.lang.ClassCastException: cannot assign instance of org.apache.commons.collections.map.LinkedMap to field org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.pendingOffsetsToCommit of type
2024-10-07 15:44:41
1151
原创 HBase有关ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
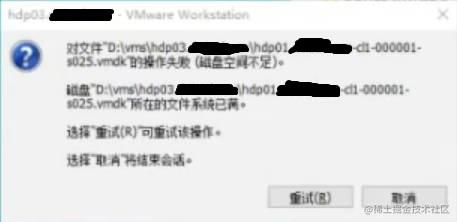
2024-09-09 23:20:29
1952
秒杀系统:第9章 课程总结及重难点回顾
2023-01-08
中图网爬取的不同种类书籍数据
2022-12-07
贝克找房网站爬取的二手房数据信息
2022-12-07
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人