




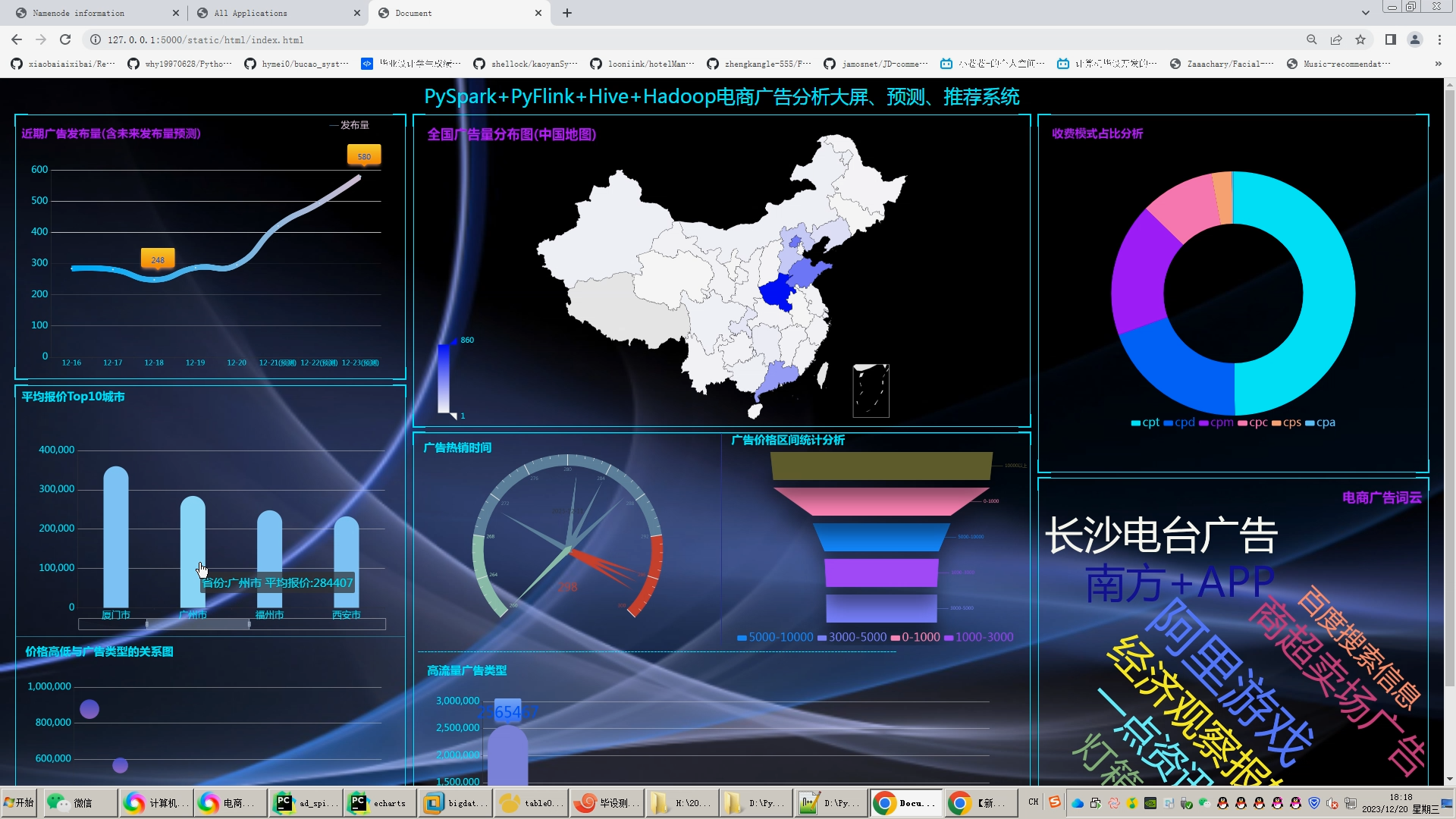
广告数仓项目以广告主投放到媒体平台为业务基础,收集管理平台数据及媒体平台发送的广告曝光点击次数之后,进行数据分析与统计,最终实现可视化报表展示。
项目共分六大部分:广告业务详情介绍、数仓建模原理介绍、数仓集群部署和环境搭建、数仓数据分析及ETL完整流程、DolphinScheduler全流程调度、FineBI可视化大屏展示,是一套完整的数仓项目,学习者部署本地虚拟机即可实现全部项目流程。
教程介绍了媒体投放广告的详细流程,帮助学习者了解广告投放业务体系,掌握ETL流程中常用的技术手段。项目中使用的框架包括:Hadoop、Hive、Spark、Kafka、ClickHouse、DolphinScheduler、Flume、Datax、FineBI等。

核心算法代码分享如下:
# coding=utf-8
# 基于物品的协同过滤推荐
import random
import sys
import math
from operator import itemgetter
import pymysql
from rate import Rate
import db
"""
"""
class ItemBasedCF():
# 初始化参数
def __init__(self):
self.n_sim_movie = 8
self.n_rec_movie = 4
self.trainSet = {}
self.testSet = {}
self.movie_sim_matrix = {}
self.movie_popular = {}
self.movie_count = 0
print('Similar movie number = %d' % self.n_sim_movie)
print('Recommneded movie number = %d' % self.n_rec_movie)
def get_dataset(self, pivot=0.75):
trainSet_len = 0
testSet_len = 0
# sql = ' select * from tb_rate'
results = db.session.query(Rate).all()
# print(results)
for item in results:
user, movie, rating = item.uid, item.iid, item.rate
self.trainSet.setdefault(user, {})
self.trainSet[user][movie] = rating
trainSet_len += 1
self.testSet.setdefault(user, {})
self.testSet[user][movie] = rating
testSet_len += 1
# cnn.close()
# db.session.close()
print('Split trainingSet and testSet success!')
print('TrainSet = %s' % trainSet_len)
print('TestSet = %s' % testSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
print('Load %s success!' % filename)
# 计算电影之间的相似度
def calc_movie_sim(self):
for user, movies in self.trainSet.items():
for movie in movies:
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1
self.movie_count = len(self.movie_popular)
print("Total movie number = %d" % self.movie_count)
for user, movies in self.trainSet.items():
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
self.movie_sim_matrix.setdefault(m1, {})
self.movie_sim_matrix[m1].setdefault(m2, 0)
self.movie_sim_matrix[m1][m2] += 1
print("Build co-rated users matrix success!")
# 计算电影之间的相似性 similarity matrix
print("Calculating movie similarity matrix ...")
for m1, related_movies in self.movie_sim_matrix.items():
for m2, count in related_movies.items():
# 注意0向量的处理,即某电影的用户数为0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print('Calculate movie similarity matrix success!')
# 针对目标用户U,找到K部相似的电影,并推荐其N部电影
def recommend(self, user):
K = self.n_sim_movie
N = self.n_rec_movie
rank = {}
if user > len(self.trainSet):
user = random.randint(1, len(self.trainSet))
watched_movies = self.trainSet[user]
for movie, rating in watched_movies.items():
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies:
continue
rank.setdefault(related_movie, 0)
rank[related_movie] += w * float(rating)
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print('Evaluating start ...')
N = self.n_rec_movie
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
for i, user in enumerate(self.trainSet):
test_moives = self.testSet.get(user, {})
rec_movies = self.recommend(user)
for movie, w in rec_movies:
if movie in test_moives:
hit += 1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_moives)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))
def rec_one(self,userId):
print('推荐一个')
rec_movies = self.recommend(userId)
# print(rec_movies)
return rec_movies
# 推荐算法接口
def recommend(userId):
itemCF = ItemBasedCF()
itemCF.get_dataset()
itemCF.calc_movie_sim()
reclist = []
recs = itemCF.rec_one(userId)
return recs
if __name__ == '__main__':
#param1 = sys.argv[1]
param1 = "2"
result = recommend(int(param1))
list = []
for r in result:
list.append(dict(iid=r[0], rate=r[1]))
print(list)


















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











