




目录
本文是对 http://mnemstudio.org/path-finding-q-learning-tutorial.htm的翻译,共分两部分,第一部分为中文翻译。翻译时为方便读者理解,有些地方采用了意译的方式,此外,原文中有几处笔误,在翻译时已进行了更正。这篇教程通俗易懂,是一份很不错的学习理解 Q-learning 算法工作原理的材料。
1. Step by step tourial
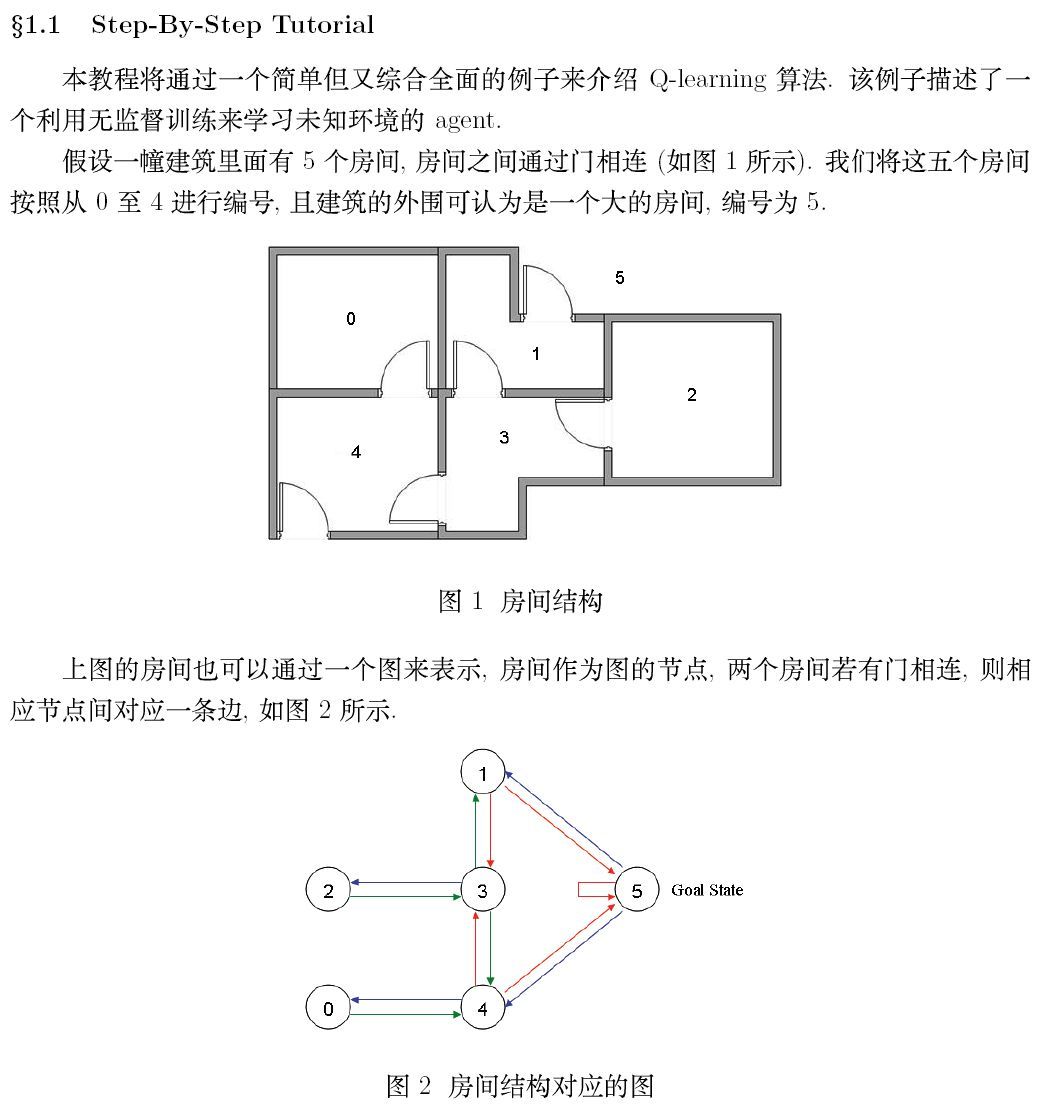
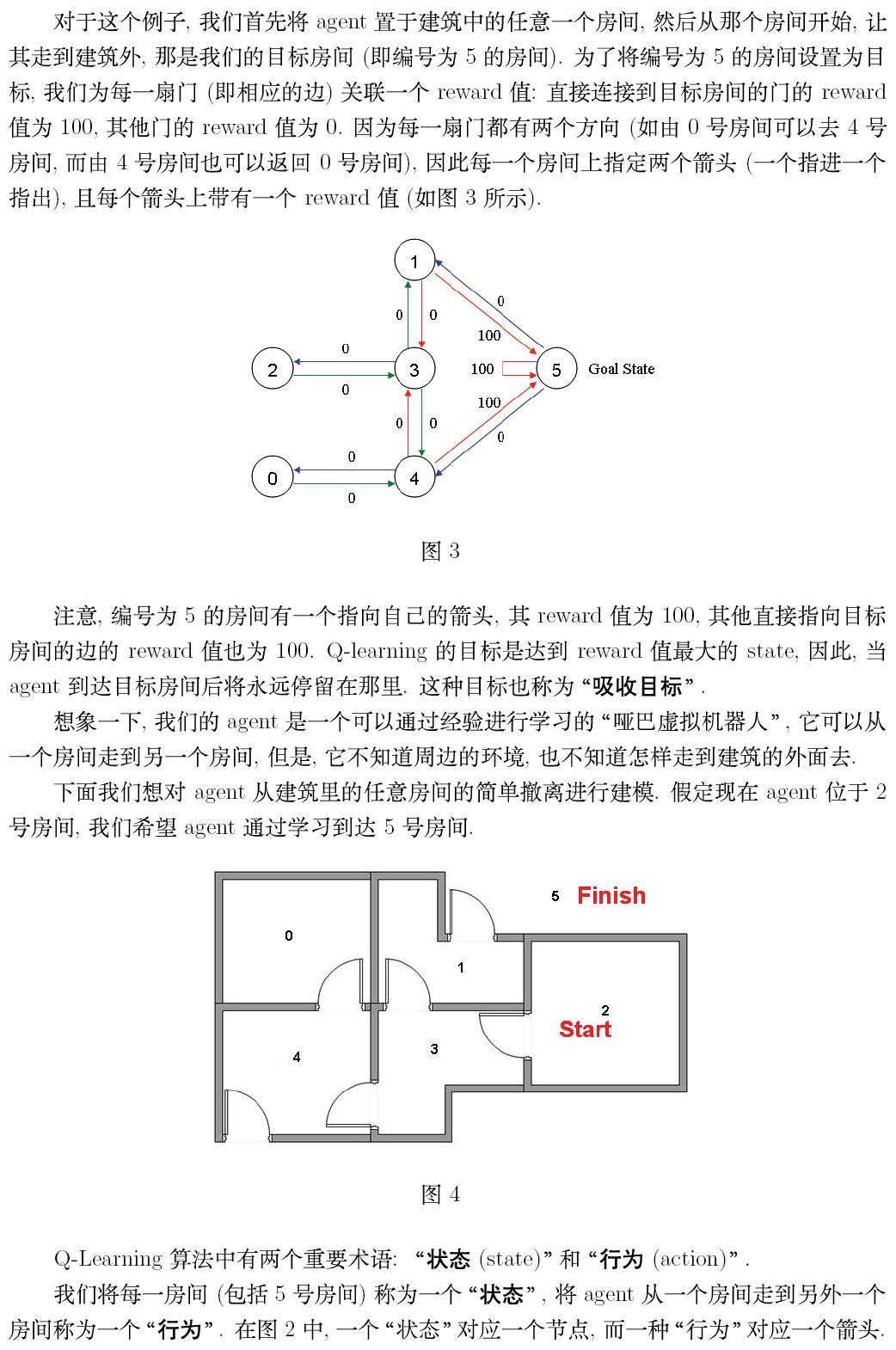


2. Q-learning example by hand

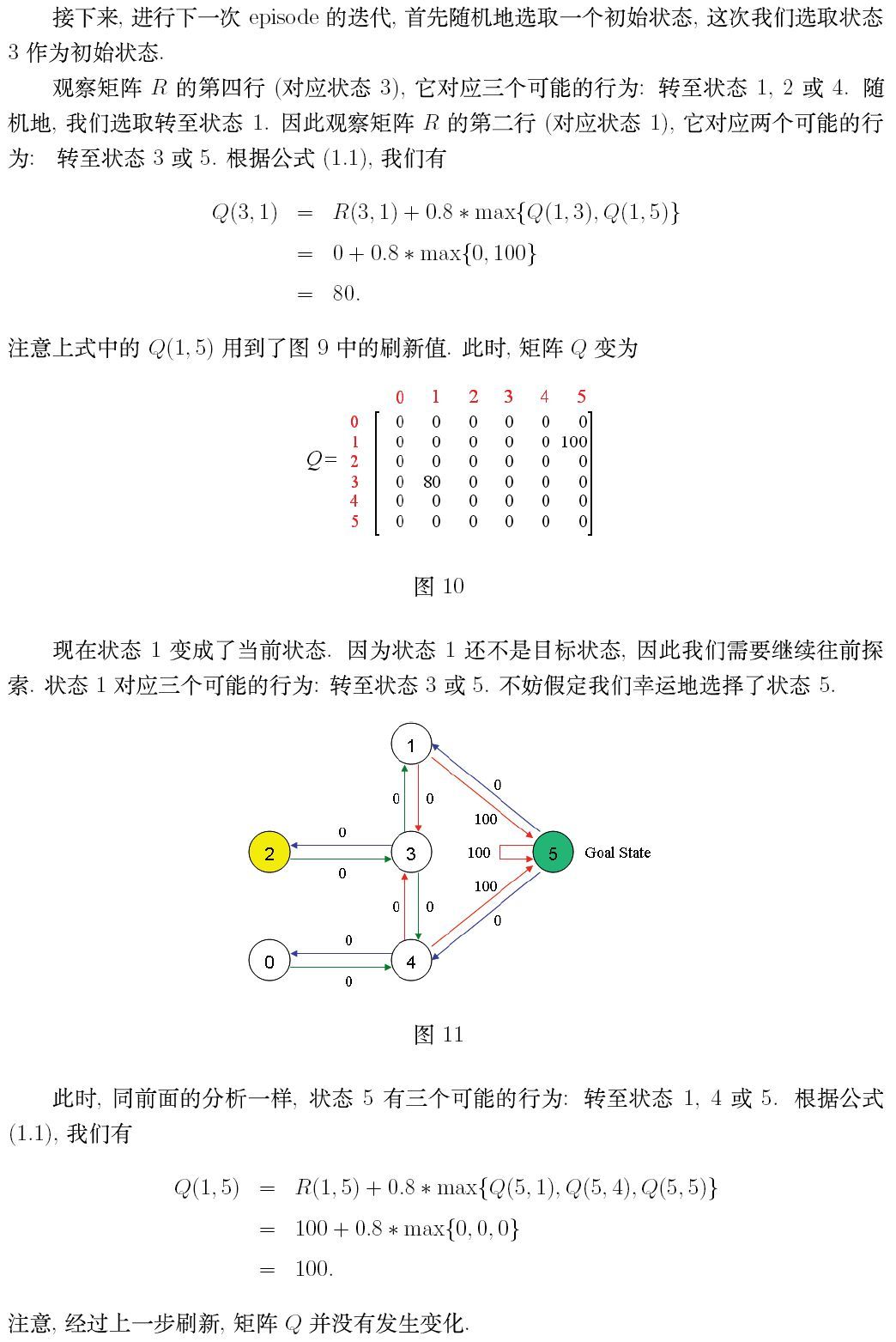

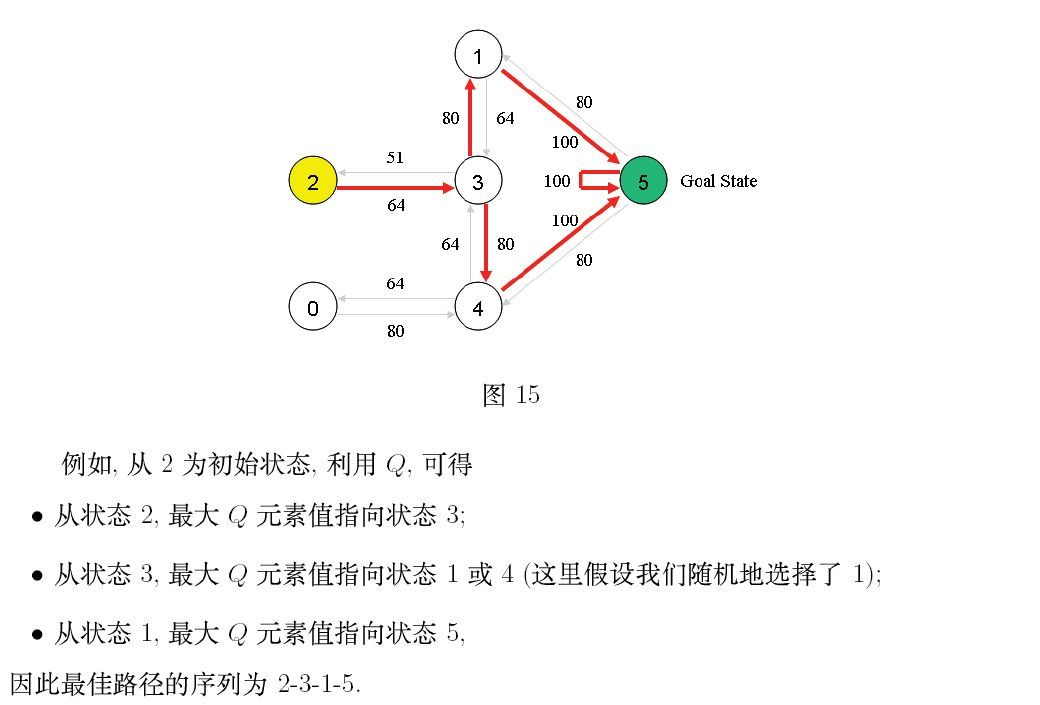
3. 用Python实现
3.1 QLearning
1. 给定参数r和R矩阵
2. 初始化 Q
3. for each episode:
3.1 随机选择一个初始状态s
3.2 若未达到目标状态,则执行以下几步
(1)在当前状态s的所有可能行为中选取一个行为a
(2)利用选定的行为a,得到下一个状态 。
(3)按照 Q(s,a)=R(s,a)+r max{Q( ,
)}
(4) s=
r 为学习参数, R为奖励机制, 为在s状态下,执行Q所得到的值。随机选择一个一个状态,即开始搜索的起点,在为100的点为终点。
3.2 程序
import numpy as np
初始化:
# 动作数。
ACTIONS = 6
# 探索次数。
episode = 100
# 目标状态,即:移动到 5 号房间。
target_state = 5
# γ,折损率,取值是 0 到 1 之间。
gamma = 0.8
# 经验矩阵。
q = np.zeros((6, 6))
def create_r():
r = np.array([[-1, -1, -1, -1, 0, -1],
[-1, -1, -1, 0, -1, 100.0],
[-1, -1, -1, 0, -1, -1],
[-1, 0, 0, -1, 0, -1],
[0, -1, -1, 1, -1, 100],
[-1, 0, -1, -1, 0, 100],
])
return r执行代码:
if __name__ == '__main__':
r = create_r()
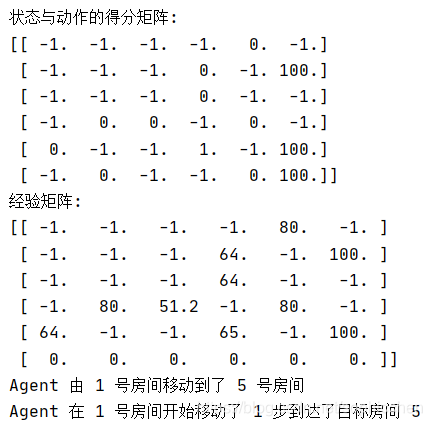
print("状态与动作的得分矩阵:")
print(r)
# 搜索次数。
for index in range(episode):
# Agent 的初始位置的状态。
start_room = np.random.randint(0, 5)
# 当前状态。
current_state = start_room
while current_state != target_state:
# 当前状态中的随机选取下一个可执行的动作。
current_action = np.random.randint(0, ACTIONS)
# 执行该动作后的得分。
current_action_point = r[current_state][current_action]
if current_action_point < 0:
q[current_state][current_action] = current_action_point
else:
# 得到下一个状态。
next_state = current_action
# 获得下一个状态中,在自我经验中,也就是 Q 矩阵的最有价值的动作的经验得分。
next_state_max_q = q[next_state].max()
# 当前动作的经验总得分 = 当前动作得分 + γ X 执行该动作后的下一个状态的最大的经验得分
# 即:积累经验 = 动作执行后的即时奖励 + 下一状态根据现有学习经验中最有价值的选择 X 折扣率
q[current_state][current_action] = current_action_point + gamma * next_state_max_q
current_state = next_state
print("经验矩阵:")
print(q)
start_room = np.random.randint(0, 5)
current_state = start_room
step = 0
while current_state != target_state:
next_state = np.argmax(q[current_state])
print("Agent 由", current_state, "号房间移动到了", next_state, "号房间")
current_state = next_state
step += 1
print("Agent 在", start_room, "号房间开始移动了", step, "步到达了目标房间 5")if __name__ == '__main__':
r = create_r()
print("状态与动作的得分矩阵:")
print(r)
# 搜索次数。
for index in range(episode):
# Agent 的初始位置的状态。
start_room = np.random.randint(0, 5)
# 当前状态。
current_state = start_room
while current_state != target_state:
# 当前状态中的随机选取下一个可执行的动作。
current_action = np.random.randint(0, ACTIONS)
# 执行该动作后的得分。
current_action_point = r[current_state][current_action]
if current_action_point < 0:
q[current_state][current_action] = current_action_point
else:
# 得到下一个状态。
next_state = current_action
# 获得下一个状态中,在自我经验中,也就是 Q 矩阵的最有价值的动作的经验得分。
next_state_max_q = q[next_state].max()
# 当前动作的经验总得分 = 当前动作得分 + γ X 执行该动作后的下一个状态的最大的经验得分
# 即:积累经验 = 动作执行后的即时奖励 + 下一状态根据现有学习经验中最有价值的选择 X 折扣率
q[current_state][current_action] = current_action_point + gamma * next_state_max_q
current_state = next_state
print("经验矩阵:")
print(q)
start_room = np.random.randint(0, 5)
current_state = start_room
step = 0
while current_state != target_state:
next_state = np.argmax(q[current_state])
print("Agent 由", current_state, "号房间移动到了", next_state, "号房间")
current_state = next_state
step += 1
print("Agent 在", start_room, "号房间开始移动了", step, "步到达了目标房间 5")执行结果:


















 642
642




 到【灌水乐园】发言
到【灌水乐园】发言







