







 本文详细介绍了Q-Learning算法的工作原理、实现步骤,以及如何应用于求解从(0,0)到(5,5)的路径问题。通过实例演示和代码展示,读者将理解如何设计Q表、更新策略并训练代理。
本文详细介绍了Q-Learning算法的工作原理、实现步骤,以及如何应用于求解从(0,0)到(5,5)的路径问题。通过实例演示和代码展示,读者将理解如何设计Q表、更新策略并训练代理。
前言
在本篇文章中,我将描述Q-Learning算法相关知识,并通过一个示例展示拿到一个问题后,如何用Q-Learning算法解决这个问题,从算法设计到算法实现都会涉及,由于Q-Learning算法相关数学推导和马尔可夫决策相关理论知识网上已经有大量教程,本文不再赘述,感兴趣的小伙伴儿可以自行查阅(作者本人用Q-Learning算法做过通信领域的研究与仿真)。
Q-Learning算法原理
要是用一个算法,我们先要知道这个算法到底是什么,是怎么运作的。本文不从数学推导上阐述该问题,而是从算法运行的层面阐述。
在前文提到,策略的表达方式中有一种是基于表格,Q-Learning算法便是其中的一个典型代表。代理的经验值全部存储在Q表中,由Q表决定代理在某一状态应该采取何种动作。
我们不妨回忆一下强化学习的实现过程,强化学习的目的是训练代理,使代理能够自主获得实现某一目的的策略。为实现这一目的,代理需要不断的向环境做出动作,环境会根据代理所做的动作带来的结果评价该动作的好坏,并反馈给代理奖励,奖励有积极奖励和消极奖励,分别表示在该状态下执行该动作的结果的好和坏,执行该动作后代理会到达下一个状态。从这里我们可以看出,代理在每一次改变状态时,都有当前状态,我们称之为旧状态(个人定义,方便理解),执行动作之后的状态,我们称之为新状态,以及在旧状态执行一个动作到达新状态后获得的奖励,我们可将奖励看作代理的经验。于是,我们可以得到强化学习的另一种定义方式,代理从一个旧的状态,执行某一个动作后到达一个新的状态,并且获得经验,而训练的结果便是代理能够根据学习到的经验,以最优的方式到达最终的目的。
在Q-Learning算法中,代理的经验是存储在Q表中,从上文不难看出,代理的每一个旧状态都有一个或者数个动作(不排除某些状态无动作可执行),每一个动作都会引导代理到达一个新的状态,因此我们可以得到一张二维表,表的大小为m*n,m表示所有动作的数量,n表示所有状态的数量,在表格中的数值表示代理在某一个状态,执行某一个动作获得的奖励,看到这里大家可能发现,在这张二维表中还存在一个信息,那便是新状态,因为一个状态执行一个动作对应的新状态唯一,因此便不在表中展示。

现在我们得到了这样一张表,那么代理如何更新以及使用这张表的呢,这里就需要提到Q-Learning算法的核心公示,这个公式便展示了,代理如何存储更新经验值:
Q
n
e
w
(
s
t
,
a
t
)
←
Q
(
s
t
,
a
t
)
⏟
旧的值
+
α
⏟
学习率
⋅
(
r
t
⏟
奖励
+
γ
⏟
奖励衰减因子
⋅
max
a
Q
(
s
t
+
1
,
a
)
⏟
estimate of optimal future value
⏟
new value (temporal difference target)
−
Q
(
s
t
,
a
t
)
⏟
旧的值
)
⏞
temporal difference
{\displaystyle Q^{new}(s_{t},a_{t})\leftarrow \underbrace {Q(s_{t},a_{t})} _{\text{旧的值}}+\underbrace {\alpha } _{\text{学习率}}\cdot \overbrace {{\bigg (}\underbrace {\underbrace {r_{t}} _{\text{奖励}}+\underbrace {\gamma } _{\text{奖励衰减因子}}\cdot \underbrace {\max _{a}Q(s_{t+1},a)} _{\text{estimate of optimal future value}}} _{\text{new value (temporal difference target)}}-\underbrace {Q(s_{t},a_{t})} _{\text{旧的值}}{\bigg )}} ^{\text{temporal difference}}}
Qnew(st,at)←旧的值
Q(st,at)+学习率
α⋅(new value (temporal difference target)
奖励
rt+奖励衰减因子
γ⋅estimate of optimal future value
amaxQ(st+1,a)−旧的值
Q(st,at))
temporal difference
首先解释一下公示中的各个变量的含义:
Q
n
e
w
(
s
t
,
a
t
)
:
该
变
量
表
示
代
理
在
状
态
s
执
行
动
作
a
后
,
Q
表
的
值
,
即
改
变
后
的
值
。
Q^{new}(s_{t},a_{t}):该变量表示代理在状态s执行动作a后,Q表的值,即改变后的值。
Qnew(st,at):该变量表示代理在状态s执行动作a后,Q表的值,即改变后的值。
Q
(
s
t
,
a
t
)
:
该
变
量
表
示
代
理
在
状
态
s
执
行
动
作
a
之
前
的
值
,
即
旧
的
值
。
Q_{(s_t,a_t)}:该变量表示代理在状态s执行动作a之前的值,即旧的值。
Q(st,at):该变量表示代理在状态s执行动作a之前的值,即旧的值。
α
和
γ
分
别
是
学
习
率
和
折
扣
因
子
,
相
关
的
介
绍
可
以
看
之
前
的
文
章
。
\alpha和\gamma分别是学习率和折扣因子,相关的介绍可以看之前的文章。
α和γ分别是学习率和折扣因子,相关的介绍可以看之前的文章。
m
a
x
Q
(
s
t
+
1
,
a
)
:
该
变
量
表
示
代
理
在
状
态
s
执
行
动
作
a
之
后
达
到
下
一
个
状
态
的
奖
励
最
大
值
。
maxQ{(s_{t+1},a)}:该变量表示代理在状态s执行动作a之后达到下一个状态的奖励最大值。
maxQ(st+1,a):该变量表示代理在状态s执行动作a之后达到下一个状态的奖励最大值。
为了更加便于理解该算法,这里用https://blog.youkuaiyun.com/weixin_54445841/article/details/112909771?spm=1001.2014.3001.5501中提到的方格世界举例,假设代理从(0,0)出发,目标是到达(5,5),则在(0,0)点,假设代理执行向上的动作,获得奖励为0,则会更新一次Q表,其中旧的Q值为执行动作前的Q值0,对应的动作为向上,获得的奖励r为0,由核心公式更新Q表,得到在(0,0)执行向上的动作到达(0,1)的新的Q值,这样一直循环,直到代理到达(5,5)。这里需要说明,初始化的Q表为一个全零矩阵。
Q-Learning算法实现步骤
从上文可以看出,Q-Learning算法的核心步骤如下:
1、初始化参数以及Q表,参数包括学习率、贪婪系数、折扣因子;
2、确定代理状态;
3、判断状态是否为最终状态;
4、若不是最终状态,选取动作,并根据该动作获取下一个状态以及获得的奖励;
5、根据核心公示更新Q表;
6、将当前状态更新为新的状态,重复第三步,直到到达最终状态。
Q-Learning算法设计
在本部分中,我将阐述拿到一个问题后如何用Q-Learning算法解决这个问题,首先需要清楚这个问题是否适合用该算法解决,该算法只适用于有限的马尔科夫决策过程,即有限的状态空间和动作空间。当明确使用该算法解决该问题后,首先确定代理要实现的目标,例如在前面提到的,代理需要到达(5,5);接下来需要确定代理所处的环境,这里有很多例子,例如经典的网格世界,以及各种游戏环境(例如贪吃蛇、超级玛丽等);确定环境后,需要确定代理的状态空间,状态空间即为代理所有状态的集合,例如在网格世界中代理的所有坐标的集合;然后确定代理的动作空间,动作空间为代理可执行动作的集合;然后根据动作空间和状态空间写出代理的状态转移方程(繁琐时可以不写,但要心中有数),即代理在所有状态下,执行每一个动作会到达哪一个状态;然后根据实际情况设计合适的奖励机制;最后编程实现。
Q-Learning举例
示例
编程实现代理自主求解路径,该路径为从一个点到达另一个点的路径。
分析思路
从要求中不难看出,这是一个求解代理从一个定点到另一个定点的问题,不妨将问题具体为求解代理从(0,0)到达(5,5)的路径,即最终的目标是代理到达(5,5);代理所处的环境便可定义为一个5*5的方格世界;确定环境后,便可知代理的状态空间可以用代理所处的位置表示;设代理在所有的状态下均可以执行上下左右四个动作,构成了动作空间;由于目的是到达(5,5),因此可以设置奖励规则为代理到达终点奖励1,其他奖励都是0。
代码编写
import numpy as np
import datetime
import random
import matplotlib.pyplot as plt
# 定义环境15*15方格
width = 15
height = 15
# 定义贪婪系数 学习率 折扣因数 Q表(零矩阵)
epsilon = 0.2
alpha = 0.6
gama = 0.99
# 最大遍历次数
max_episodes = 3000
step_display = []
# 0 1 2 3 上下左右
# 获取奖励
def get_back_reward(x, y):
if x == (width-1) and y == (height-1):
return 1
else:
return 0
# 根据当前位置和动作得到下一个位置
def get_next_state(x, y, action):
if action == 0:
if y == height - 1:
y = y
else:
y = y + 1
elif action == 1:
if y == 0:
y = y
else:
y = y - 1
elif action == 2:
if x == 0:
x = x
else:
x = x - 1
else:
if x == width - 1:
x = x
else:
x = x + 1
position = [x, y]
return position
# 选择Q值最大的索引
def get_max_index(x, y):
i = 0
index = 0
temp = q_table[x][y][0]
while i < 4:
if q_table[x][y][i] > temp:
index = i
i += 1
else:
temp = q_table[x][y][i]
i += 1
return index
# 选择动作
def choose_action(x, y):
t = random.random()
if t > epsilon:
return random.randint(0, 3)
else:
return get_max_index(x, y)
# 每一轮寻找最佳路径
def find_way():
# 初始化最初位置(0,0)
s_flag = 0
x = 0
y = 0
count_step = 0
while 1 > 0:
# 选择动作
action_new = choose_action(x, y)
# 通过当前位置和选择的动作确定下一个状态
position1 = get_next_state(x, y, action_new)
x_next = position1[0]
y_next = position1[1]
# 获取奖励
reward = get_back_reward(x_next, y_next)
# 记录更新Q表之前该位置的值
q_old = q_table[x][y][action_new]
# 判断是否到达目的地 若达到 退出 该阶段结束 反之 更新Q表
if reward == 1:
s_flag = 1
q_new = 0
if s_flag != 1:
q_new = reward + gama * q_table[x_next][y_next][get_max_index(x_next, y_next)]
else:
q_new = reward
q_table[x][y][action_new] += alpha * (q_new - q_old)
x = x_next
y = y_next
count_step += 1
# print(count_step)
# print(s_flag)
if s_flag == 1:
break
return count_step
if __name__ == '__main__':
q_table = np.zeros((width, height, 4))
flag = 1
min_epsilon = epsilon
while max_episodes >= 1:
time_begin = datetime.datetime.now()
step = find_way()
if flag % 100 == 0:
step_display.append(step)
if epsilon < 0.9:
epsilon += (1.0 - min_epsilon) / max_episodes
time_end = datetime.datetime.now()
time_pass = (time_end - time_begin).total_seconds()
print("第%i次训练,所用的时间为:%f ms,步数为:%i" % (flag,time_pass, step))
max_episodes -= 1
flag += 1
print(q_table)
len_step = len(step_display)
max_step = max(step_display)
min_step = min(step_display)
x = np.linspace(1, len_step, len_step)
plt.figure()
plt.xlabel("Round/✖️100")
plt.ylabel("Step")
plt.ylim(min_step - 5, max_step + 5)
plt.plot(x, step_display)
plt.show()
plt.close()
# print(q_table)
训练结果
训练3000次结果如图,每100次打印一次。
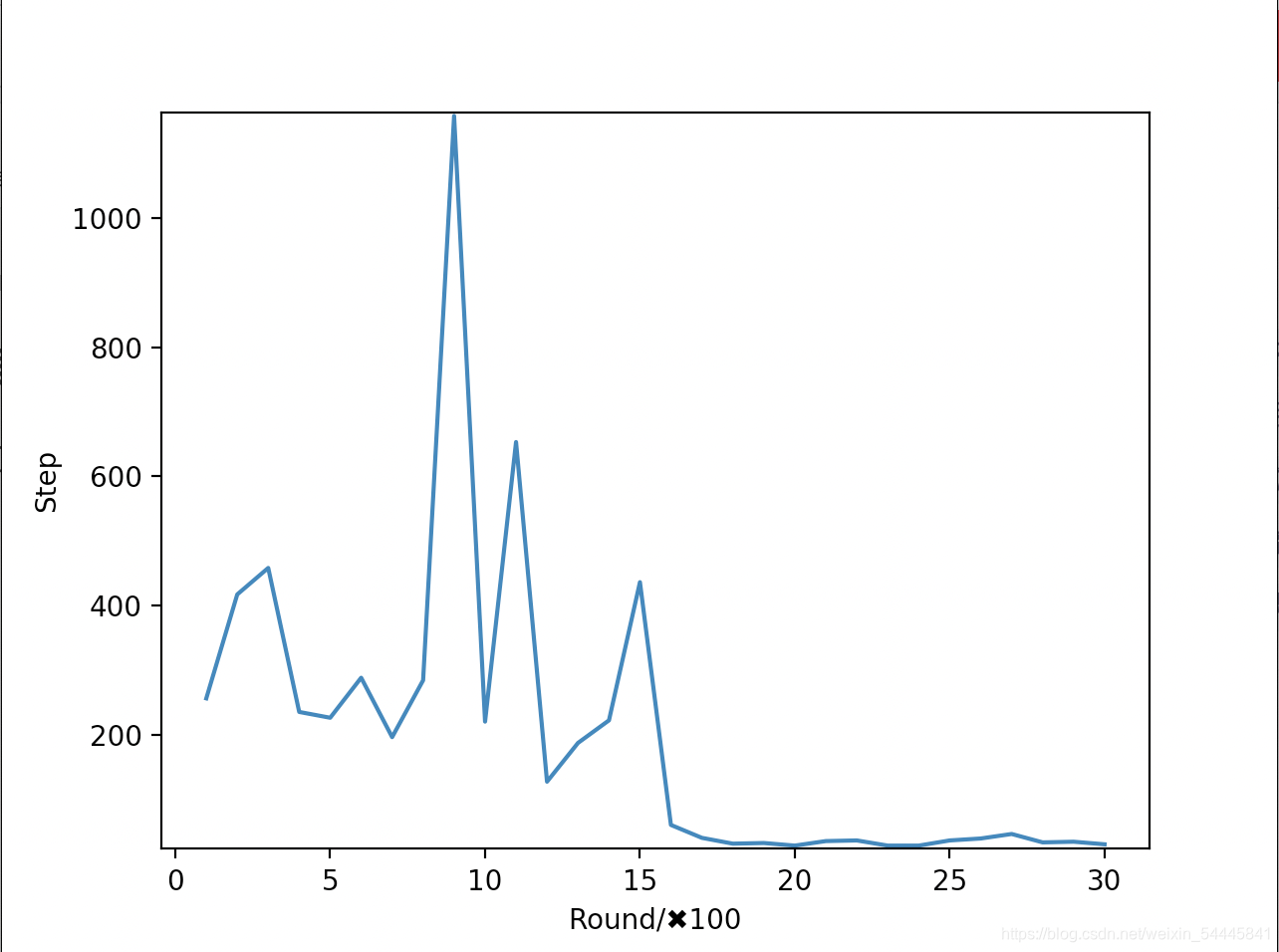
总结
Q-Learning算法是一个基础的强化学习算法,使用简单便于理解,是入门强化学习的一个优秀算法,但是其应用十分广泛,在一些顶级的会议期刊中,许多研究也是利用该算法实现,所以学会一个算法不难,难的是如何运用该算法解决实际问题,如何建模等。因此一定要多发散,不能仅仅做一个定点路径规划问题,作者在利用该算法解决通信相关问题中,需要代理到达多个定点,因此我将代理到达四个定点的代码上传,感兴趣的小伙伴儿可以下载研究,调试参数,链接在导航中。
导航
四个定点代码链接:https://download.youkuaiyun.com/download/weixin_54445841/16535894



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









