







写在前面:
本系列文章是对于自己自学吴恩达教授的系列视频做的笔记及总结,所以很多地方可能会比较口语化,不太专业,原视频链接:吴恩达给你的人工智能第一课,感兴趣的朋友还是建议看原视频,毕竟是大师的视频。
所以在系列视频中实现的各种神经网络,包括DNN、RNN、LSTM等等,有时间的情况下,应该会都更新上自己手撕的代码
因为是新手,所以文章中可能会有很多错误的理解或者实现...希望大佬们多多指教
一、什么是LR
LR,全称为logistic regression,逻辑回归,是一个监督学习的二分分类算法。因为是二分分类,所以训练集的标签只能是两种类型。
用途的话,比如识别下图中是否有猫,判别某个人对某种商品是否有购买意向,猜测一个西瓜是否是好瓜:

根据我上面的描述,也能大概看出来,LR大部分做的都是进行“是否”的判断(毕竟是二分分类
既然输出的是“是否”,是一种“猜测”,所以我们其实想要的,是一个概率,即可以解释为:在给定条件下,预期结果发生的概率为多大。
二、loss function
以判定图片中是否有猫为例子,图片就是我们的输入x,真实是否有猫就是我们数据的标签y,假设有猫时令y = 1,没有猫时令y = 0,使用概率形式可以将问题描述为,在给定x的条件下,y = 1的概率,那该如何计算
呢
比较直观的一个想法就是使用线性回归公式去计算,但是这个公式是线性函数,取值范围很大,因为我们想要的是一个概率,所以我们希望
在0 ~ 1之间,这时候我们引入sigmoid函数:
,图像如下(求导的特殊性质说明参考之前写的文章【机器学习】【数学推导】神经网络(NN)及误差逆传播(BP详细推导过程)):

这个函数很好的符合了概率0 ~ 1的性质
当
时,
,所以
当
时,
,所以
所以,我们将求得的值,当做
带入,就可以将所有值映射到0 ~ 1中,符合概率的概念
那应该如何去求和
呢?
主要方法还是使用BP或者牛顿迭代的思想,在之前写的文章中都有写到。这里说些和之前写的不一样的东西
在之前介绍NN的数学原理中,使用的loss function为均方差:
但是使用均方差有个问题,他的函数图像类似于:
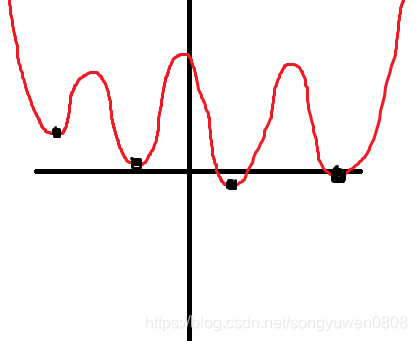
这样子可能从不同的位置出发,最终到达的不是全局最优解,而是陷入了局部最优解。所以对于LR,将loss function修改为:,这个函数的图像为:
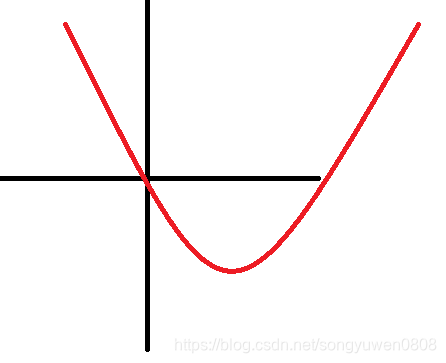
这样子能够保证,不管从哪个位置开始,最终都会到达全局最优解,那为什么选用这个loss而不是其他的呢,下面从两种思路解释一下
1. 直观上解释,因为我们希望求得的
更加靠近
,loss function就是衡量我们的预测值
,所以针对两种情况分别分析
当y = 1时,
,因为我们希望loss最小,所以我们希望
越小越好,所以希望
越大越好,所以我们希望
越大越好。因为
当y = 0时,
,所以希望
越小越好,也就是
越大越好,
越大越好,也就是
2. 从数学角度解释
我们定义
,是在X特征的情况下,y = 1的概率,因为是二分类问题,所以只有y = 1和y = 0两种概率,所以:
当y = 1时,概率为
当y = 0时,概率为
利用任何数的0次方都等于1,将两种情况合并为一种,可以写为式子:
。为了简化这个式子,更加方便做运算,我们对两边都取对数(因为log是严格单调递增的,所以对趋势不会有变化),将式子转换为:
因为这个是
三、算法过程
既然我们想求得最终概率,我们肯定就会有一个从前向后求概率的过程;然后我们又希望通过这个求得的概率和损失,来修正我们原式子中的w和t,使得再次求得的概率更加准确,所以我们就还会有一个反向的过程来修正w和b,图示如下:
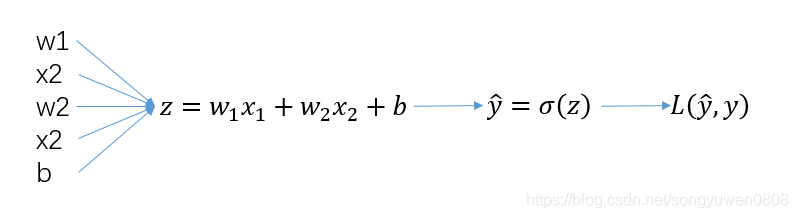
正向过程比较简单,按照公式进行计算,求得最终的loss就可以了,说一下反向的几个求导,我们先重新把所有的公式列一下:
我们最终是想要获得L对w和b的导数dw和db,用来修正w和b的值,使得求得的概率更加准确(不清楚为什么要求导得同学,还是请移步之前写的NN数学推导的文章里,实在不想再写一次了...)
利用链式法则,我们一步步求导:
(sigmoid求导性质,不清楚的请移步NN数学推导文章(我这么骗PV是不是有点不厚道))
将第1、2个式子综合一下,可以得到:
根据上面的求导公式,我们就可以获得w和b的更新公式为:
其中
为自定义的学习率系数
四、代码实现
当前只来得及写完for循环 + BP的代码,之后还会更新numpy + BP消除for循环的代码,再之后更新牛顿迭代的代码
附git地址:https://github.com/songyuwen0808/logistic_regression
import time
import numpy as np
import math
# 使用西瓜书中的特征样本
# 色泽
color_map = {
'青绿' : 1,
'乌黑' : 2,
'浅白' : 3
}
# 根底
root_map = {
'蜷缩' : 1,
'稍蜷' : 2,
'硬挺' : 3
}
# 敲声
sound_map = {
'浊响' : 1,
'沉闷' : 2,
'清脆' : 3
}
# 纹理
texture_map = {
'清晰' : 1,
'稍糊' : 2,
'模糊' : 3
}
# 脐部
umbilical_map = {
'凹陷' : 1,
'稍凹' : 2,
'平坦' : 3
}
# 触感
touch_map = {
'硬滑' : 1,
'软粘' : 2
}
# 分类类型
good_type = {
'好瓜' : 1,
'坏瓜' : 0
}
# https://blog.youkuaiyun.com/songyuwen0808/article/details/105378072
train_info = [
['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '青绿', '浅白', '浅白', '青绿', '浅白', '青绿', '浅白', '青绿'],
['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '硬挺', '硬挺', '蜷缩', '稍蜷', '稍蜷', '蜷缩', '蜷缩', '蜷缩'],
['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '清脆', '清脆', '浊响', '浊响', '沉闷', '浊响', '浊响', '沉闷'],
['清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '模糊', '模糊', '稍糊', '稍糊', '清晰', '模糊', '稍糊'],
['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '平坦', '平坦', '平坦', '凹陷', '凹陷', '凹陷', '平坦', '稍凹'],
['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '硬滑', '软粘', '硬滑', '软粘', '硬滑', '硬滑', '硬滑', '硬滑', '硬滑'],
[0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.437, 0.243, 0.245, 0.343, 0.639, 0.657, 0.360, 0.593, 0.719],
[0.460, 0.376, 0.264, 0.318, 0.215, 0.237, 0.211, 0.267, 0.057, 0.099, 0.161, 0.198, 0.370, 0.042, 0.103],
['好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜']
]
test_info = [
['乌黑', '乌黑'],
['稍蜷', '稍蜷'],
['沉闷', '浊响'],
['稍糊', '稍糊'],
['稍凹', '稍凹'],
['硬滑', '软粘'],
[0.666, 0.481],
[0.091, 0.149],
['坏瓜', '好瓜'],
]
def transfer_info(data_info):
for idx in range(len(data_info[0])):
data_info[0][idx] = color_map[data_info[0][idx]]
data_info[1][idx] = root_map[data_info[1][idx]]
data_info[2][idx] = sound_map[data_info[2][idx]]
data_info[3][idx] = texture_map[data_info[3][idx]]
data_info[4][idx] = umbilical_map[data_info[4][idx]]
data_info[5][idx] = touch_map[data_info[5][idx]]
data_info[8][idx] = good_type[data_info[8][idx]]
print("=================训练集转换前=================")
for line in train_info:
print(line)
transfer_info(train_info)
print("=================训练集转换前=================")
for line in train_info:
print(line)
print("=================测试集转换前=================")
for line in test_info:
print(line)
transfer_info(test_info)
print("=================测试集转换后=================")
for line in test_info:
print(line)
cycle_num = 100000
rate = 0.001
# for循环 + BP版本
def for_plus_bp():
# 特征数量
feature_num = len(train_info) - 1
# 样本数量
data_num = len(train_info[0])
# LR的初始化不用使用高斯随机
w = [0] * feature_num
b = 0
for k in range(cycle_num):
# 训练cycle_num次
z = [0] * data_num
a = [0] * data_num
l = [0] * data_num
j = 0
da = [0] * data_num
dz = [0] * data_num
dw = [0] * feature_num
db = 0
for i in range(data_num):
# 计算z = w^T * x + b
for j in range(feature_num):
z[i] += w[j] * train_info[j][i]
z[i] += b
# 计算sigmoid
a[i] = 1 / (1 + math.exp(z[i] * -1))
# 计算loss function = -(y * loga + (1 - y) * log(1 - a))
l[i] = -1 * (train_info[8][i] * math.log(a[i]) + (1 - train_info[8][i]) * math.log(1 - a[i]))
# 计算cost function = sum(loss function)
j += l[i]
# 计算da = - y / a + (1 - y) / (1 - a)
da[i] = -1 * train_info[8][i] / a[i] + (1 - train_info[8][i]) / (1 - a[i])
# 计算dz = a - y
dz[i] = a[i] - train_info[8][i]
# 计算dw = x * dz
for j in range(feature_num):
dw[j] += train_info[j][i] * dz[i]
db += dz[i]
j /= data_num
for j in range(feature_num):
dw[j] /= data_num
w[j] -= rate * dw[j]
db /= data_num
b -= rate * db
print("for循环训练结果:w = ", w, "b = ", b)
# 验证结果
test_num = len(train_info[0])
test_z = [0] * len(train_info[0])
for i in range(test_num):
for j in range(feature_num):
test_z[i] += w[j] * train_info[j][i]
test_z[i] += b
test_z[i] = 1 / (1 + math.exp(test_z[i] * -1))
print("for 循环预测结果:", test_z)
def np_plus_bp():
# numpy + bp优化版本
# for循环版本
# 特征数量
feature_num = len(train_info) - 1
# 样本数量
data_num = len(train_info[0])
# LR的初始化不用使用高斯随机
w = np.zeros(feature_num, 1)
b = 0
np_train_info = np.array(train_info[:-1])
np_label_info = np.array(train_info[-1])
for _ in range(cycle_num):
# 计算所有的z = w^T * x + b
z = np.dot(w.T, np_train_info) + b
# 计算所有的sigmod
a = 1 / (1 + np.exp(-z))
# 计算所有的dz
dz = a - np_label_info
# 计算所有的dw = x * dz
dw = np.dot(np_train_info, dz.T) / data_num
# 计算db
db = np.sum(dz) / data_num
# 更新所有的w
w = w - rate * dw
# 更新b
b = b - rate * db
print("np 训练结果, w = ", w, ", b = ", b)
test_num = len(train_info[0])
test_z = np.dot(w.T, np_train_info) + b
test_a = 1 / (1 + np.exp(-test_z))
print("np 预测结果 = ", test_a)
if __name__ == '__main__':
start_time = time.time()
for_plus_bp()
print("for_plus_bp cost time:", time.time() - start_time)
start_time = time.time()
np_plus_bp()
print("np_plus_bp cost time:", time.time() - start_time)性能比对:

在运行结果完全一致的情况下,性能从12.03秒提升至3.49秒


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









