






1 致谢
感谢赵老师的讲述~
2 前言
今天在学习CNN~
记得很久以前,小伙伴曾经问过我一个问题,为什么CNN网络要使用卷积运算作为神经元的输入,
那时候我还没怎么开始学深度学习,觉得这是一个很玄妙的问题;
关于CNN为什么要使用卷积的思考
其实对于CNN网络要使用卷积运算作为神经元的输入,其实没有很复杂很复杂的原因,
(其实这里隐含了一个小问题,就是为什么不直接用全连接层链接所有特征呢)
因为从计算过程看来,CNN和NN网络没有太大的区别,
只是:
- NN的输入是所有的参数,而CNN的输入只是Kernel对应的窗区域;
- NN的线性运算使用的是向量积,而CNN使用的是所谓的“卷积”,其实这种卷积实质上也是向量积,并不是数字信号处理中的“信号卷积”运算,因为信号卷积运算由于对“时间”这一维度十分敏感,所以需要进行对信号进行倒置后,再按照一定规律进行向量积运算;所以信号卷积和Conv从本质上是不一样的;
- 本质上,卷积是一种互相关运算。
综上所述,CNN中的卷积运算只是NN中线性运算的一种简化而已。
当然,这样解释似乎还是不太好理解,这里我们想说说关于CNN蕴含的哲理~
3 The Philosophy of CNN
3.1 邻域特性
邻域特性在许多常见的CNN算子上都有体现,其实Conv层本身就是邻域特性的体现,Conv使用一个矩形窗邻域作为输入,就是模拟视神经观察当前局部区域的特性;
“卷积层它是对局部信号比较敏感,就说长为3的这个核,然后它每次就看三个东西,然后它对局部的细节比较敏感。” ——《OpenAI Whisper 精读【论文精读】- 李沐》
4 CNN中的卷积算子(Convolution)
(区别与信号卷积)
卷积算子是CNN网络中的最基础操作,也是构成CNN网络的核心;指的是模板与输入图像对应窗型区域的卷积计算。
5 卷积的数学本质——交叉相关
关于卷积的数学本质,这里我们可以参考李沐老师的讲述,

6 Naive Convolution 实现
# 通过增加h和w的size,实现了padding的操作
X = torch.tensor([[0.0, 1.0, 2.0],
[3.0, 4.0, 5.0],
[6.0, 7.0, 8.0]])
X.unsqueeze_(0).unsqueeze_(0)
batch, input_channels, map_height, map_width = X.shape
# kernel = torch.zeros(1, input_channels, 2, 2)
kernel = torch.tensor([[0.0, 1.0],
[2.0, 3.0]])
if kernel.dim() == 2:
kernel.unsqueeze_(0).unsqueeze_(0)
out_channels = kernel.shape[1]
kernel_height, kernel_width = kernel.shape[-2:]
output = torch.zeros(batch, out_channels, map_height - kernel_height + 1, map_width - kernel_width + 1)
"""
Convolve `input` with `kernel` to generate `output`
X.shape = [batch, input_channels, input_height, input_width]
kernel.shape = [num_filters, input_channels, kernel_height, kernel_width]
output.shape = [batch, num_filters, output_height, output_width]
"""
for b in range(batch):
for filter in range(out_channels):
for c in range(input_channels):
for out_h in range(output.shape[-2]):
for out_w in range(output.shape[-1]):
for k_h in range(kernel_height):
for k_w in range(kernel_width):
output[b, filter, out_h, out_w] += kernel[filter, c, k_h, k_w] \
* X[b, c, out_h + k_h, out_w + k_w]
print(output)
计算复杂度: O ( b × o u t × i n × h × w × k h × k w ) O(b \times out \times in \times h \times w\times kh\times kw) O(b×out×in×h×w×kh×kw)
7 Feature Map的尺寸计算
Feature Map图像的尺寸计算公式如下:
H
o
u
t
=
⌊
H
i
n
+
2
×
p
a
d
H
−
d
i
l
a
t
i
o
n
H
×
(
k
H
−
1
)
−
1
s
t
r
i
d
e
H
+
1
⌋
W
o
u
t
=
⌊
W
i
n
+
2
×
p
a
d
W
−
d
i
l
a
t
i
o
n
W
×
(
k
W
−
1
)
−
1
s
t
r
i
d
e
W
+
1
⌋
H_{out}=\left \lfloor \frac{H_{in}+2\times pad_H-dilation_H \times \left ( k_H-1\right )-1}{stride_H}+1\right \rfloor \\ W_{out}=\left \lfloor \frac{W_{in}+2\times pad_W-dilation_W \times \left ( k_W-1\right )-1}{stride_W}+1\right \rfloor
Hout=⌊strideHHin+2×padH−dilationH×(kH−1)−1+1⌋Wout=⌊strideWWin+2×padW−dilationW×(kW−1)−1+1⌋
接下来,我们来看看这个公式是如何推导的,
首先,我们来看看各个参数表示的含义,
参数
d
i
l
a
t
i
o
n
H
dilation_H
dilationH表示基于第一个点的膨胀的宽度,如图所示,
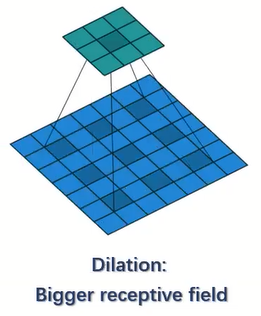
图中的卷积模板的高方向膨胀长度为2,即
d
i
l
a
t
i
o
n
H
=
2
dilation_H=2
dilationH=2;
这里我们以模板扫过的最右或者最下方的坐标来进行公式的推导,
这里不妨以高度坐标来进行推导,
这里我们推导时,对符号进行简化,
因为可以知道,高度坐标和宽度坐标的推理是同理的,
∴这里的符号简化后的推理过程对高度和宽度的公式推理都是适用的,
我们进行如下的简化;
H
i
n
→
H
d
i
l
a
t
i
o
n
H
→
d
s
t
r
i
d
e
H
→
s
p
a
d
H
→
p
k
H
→
k
H
o
u
t
→
x
H_{in} \rightarrow H \\ dilation_H \rightarrow d \\ stride_H \rightarrow s \\ pad_H \rightarrow p \\ k_H \rightarrow k \\ H_{out} \rightarrow x
Hin→HdilationH→dstrideH→spadH→pkH→kHout→x
对于卷积模板来说,模板的高度为
1
+
(
k
−
1
)
⋅
d
1+(k-1)\cdot d
1+(k−1)⋅d,
模板扫描的步长为s,共扫描
x
−
1
x-1
x−1次,
则最底下的坐标为
1
+
(
k
−
1
)
⋅
d
+
(
x
−
1
)
⋅
s
1+(k-1)\cdot d+(x-1)\cdot s
1+(k−1)⋅d+(x−1)⋅s,
通过padding之后的图像的总高度为
H
+
2
p
H+2p
H+2p,
则有
1
+
(
k
−
1
)
⋅
d
+
(
x
−
1
)
⋅
s
=
H
+
2
p
1+(k-1)\cdot d+(x-1)\cdot s = H+2p
1+(k−1)⋅d+(x−1)⋅s=H+2p,
解方程可得,
x
=
H
+
2
p
−
1
−
(
k
−
1
)
⋅
d
s
+
1
x=\frac{H+2p-1-(k-1)\cdot d}{s}+1
x=sH+2p−1−(k−1)⋅d+1
然后将简化的符号还原,即可得到上面的公式。
5 各种各样新形式的卷积
5.1 稀疏卷积(空洞卷积)
空洞卷积是我在语义分割中学到的一种卷积,
它跟普通3x3的卷积相比,具有更大的感受野,
在我看来:
空洞卷积更像是 = resize(最近邻采样) + 普通卷积
其实感受野扩大也是通过resize实现的;
5.1.1 空洞卷积的特点
忽略细节:因为使用了“空洞”操作,其实就是相当于最近邻的下采样,所以更多地忽略了纹理细节;
从而了增大感受野,于是对大目标很鲁棒,因为大目标我们只注重的是“轮廓”信息而不是细节的纹理信息,
对小目标不友好,因为小目标信息本来信息就少,而进行了“最近邻的下采样”,更容易丢失细节,于是就不太好了;
但是反过来一想,对大目标的检测,不仅可以增大感受野,还可以节省计算量;
5.2 DWConv (Depthwise Convolution)
DWConv就是可分离卷积,最近比较火热,旷世用其实现了“超大核卷积”(请参见《凭什么 31x31 大小卷积核的耗时可以和 9x9 卷积差不多?| 文末附 meetup 直播预告》)
DWConv的核心思想是分组数与输入通道数保持相同,实现通道内的卷积相应;
示例代码如下:
dwconv = nn.Conv2d(
in_channels=dim,
out_channels=dim,
kernel_size=ksize,
stride=1,
padding=1,
groups=dim)

















 6639
6639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









