







 本文介绍了Python编程的基础规则,包括编码规范、命名约定、代码长度限制、异常处理、数据类型操作、函数编写原则、字符串处理、枚举与数据结构等,旨在提升代码质量和可维护性。
本文介绍了Python编程的基础规则,包括编码规范、命名约定、代码长度限制、异常处理、数据类型操作、函数编写原则、字符串处理、枚举与数据结构等,旨在提升代码质量和可维护性。
1 Basics
1.1 解释器指令(也叫做Shebang)
在运行模式中指定python解释器
#!/usr/bin/env python3
1.2 代码风格规范
1.2.1 命名规则
变量名
单词都使用小写,两个单词之间使用下划线 “_” 进行连接,
例如:
nums_batch
类名
类名我们采样大驼峰法来进行命名,
例如:
DataLoader
项目文件夹命名
包名不要使用“-”短横线,因为如果文件夹名称中包含“-”,则无法被python识别为包名;可以使用下划线“_”;
包名不要与包内部的python文件重名,否则也会出现问题;
1.2.2 单个文件避免超过700行
Troubleshooting
(1)错误:出现“ModuleNotFoundError: No module named ‘xxx’; ‘xxx’ is not a package”
python文件与上级目录的包名名称相同;
1.2 常见缩写释义
PEP: Python Enhancement Proposal
2 Python编程哲学
请参阅博文【Python编程哲学学习笔记】
3 Variable
3.1 Python中的immutable变量
Immutable变量类型: str, tuple和numbers。
2.2 判断变量类型
# 判断变量是否是字符串
isinstance(a,str)
# 使用match表达式实现类型分支
x = 0.0
match x:
case int():
print('Int')
case float():
print('Float')
case _:
print('Other')
2.3 使用 Type hints进行类型验证
关于在PyCharm中使用 Type hints请参考《Type hinting in PyCharm》;
验证表达式类型

2.4 使用typeguard进行运行时类型检查
官方教程:User guide — Typeguard documentation
2.5 美元方式用_定义整数
Python中可以使用美元金额的表示方法,使用_代替 , 标记整数的千分位,
例如:x = 1_000_000
2.6 编写模式常量
使用枚举类来定义模式常量,关于枚举类的使用,请参考《Python 标准库 » 数据类型 » enum — 对枚举的支持》;
4 Operator
3.1 :=:海象运算符
:=可以用在赋值表达式中,使其在完成赋值的同时,也使表达式本身会返回当前运算的赋值结果,(Python文档的英文描述如下),
[Docs.Python | 6.12. Assignment expressions]: An assignment expression (sometimes also called a “named expression” or “walrus”) assigns an expression to an identifier, while also returning the value of the expression.
示例代码:
# Handle a matched regex
if (match := pattern.search(data)) is not None:
# Do something with match
2.2 算术运算
Int():整数截取运算
a = 2.9
for a in (0.1, 2.1,2.9,-2.9,-2.1,-2.9):
print(f"{a} --> {int(a)}")
>>>
0.1--> 0
2.1 --> 2
2.9 --> 2
-2.9 --> -2
-2.1 --> -2
-2.9 --> -2
2.3 逻辑运算
支持数值链式比较的表达式:a < b < c
Python中在高版本中可以支持链式比较的表达式,例如:
a < b < ca == b == c
2.4 自定义操作符
2.4.1 添加索引操作符:data[i]
__getitem__():实现索引操作
示例代码如下:
class MyIter:
def __init__(self, data):
self.data = data
def __getitem__(self, idx):
return self.data[idx]
my_iter = MyIter("Hello, PaddleVit")
for ch in my_iter:
print(ch)
2.4.2 算数运算符
__rmul__():在自定义类中实现乘法交换律

5 Function
写作原则
(对于函数编写的原则,我们参考了网易云音乐大前端团队的博文网易云音乐大前端团队——《简明 JavaScript 函数式编程——入门篇 》)
在编写函数时,我们需要尽量注意以下原则:
- 数据不可变(不要改变输入数据)
5.1 使用dict传递参数
func(**dict_params)
5.2 默认参数
(1)如果函数的默认参数是可变(mutable)类型,则该形参相当于是共享的静态对象(static)
(2)若默认参数需要为可变类型,请在函数内部进行初始化
当函数的默认参数是可变对象(如列表或字典)并且在声明中初始化时,会导致所有函数调用共享同一个对象。为了避免这个问题,可以将不可变对象作为默认参数,并在函数内部进行初始化:
# 错误的示例:默认参数是可变对象
def add_item(item, my_list=[]):
my_list.append(item)
return my_list
result1 = add_item(1) # 返回[1]
result2 = add_item(2) # 返回[1, 2],而不是期望的[2]
# 正确的示例:默认参数是不可变对象
def add_item(item, my_list=None):
if my_list is None:
my_list = []
my_list.append(item)
return my_list
5.3 如何用列表或字典向函数传递参数
这里用一个简单的函数func来表示用列表或字典传递参数的过程,首先定义func:
def func(a,b,c):
print(a,b,c)
然后是列表传递参数,
args = [1,2,3]
func(*args)
字典传递参数,
kwargs = {'a':1,'b':2,'c':3}
func(**kwargs)
5.4 在嵌套函数时保持恒等参数传递
def math_func(*args, **kwargs):
return func(*args, **kwargs) # 保持恒等参数传递
5.5 位置参数&关键字参数
5.5.1 func(*, ...kwargs)表示禁止使用位置参数
示例:“reset(*, seed: int | None = None, options: dict[str, Any] | None = None)”
5.6 function和method是不同的类型
在python中,function和method是不同的类型,这一点可以通过下面的结果看到:

代码如下:
def func(n):
return n+1
print(type(func))
class FC:
a = 1
def add1(self,n):
return n+self.a
f = FC()
print(f.add1(2))
type(f.add1)
3.6 传递固定部分形参的函数:functools.partial(func, param)
可以使用functools.partial来设置函数的部分参数,来定制形参固定的函数操作;
6 String (immutable)
编程范式
I. 使用join()拼接字符串
当需要连接多个字符串时,使用join()方法比使用+操作符更高效。join()方法会创建一个生成器对象,逐个连接字符串,而+操作符会创建新的字符串对象;
# 错误的示例:使用+操作符连接字符串
result = ""
for i in range(1000):
result += str(i)
# 正确的示例:使用join()方法连接字符串
parts = []
for i in range(1000):
parts.append(str(i))
result = "".join(parts)
使用“+=”运算符进行拼接操作可能会导致性能问题
测试代码如下:
import time
long_num = 10000000
# 使用 "+=" 方法进行字符串拼接
def append_method():
result = ""
start_time = time.time()
for _ in range(long_num):
result += "a"
end_time = time.time()
print("Append method took:", end_time - start_time, "seconds")
# 使用 "join" 方法进行字符串拼接
def join_method():
strings = ["a" for _ in range(long_num)]
start_time = time.time()
result = "".join(strings)
end_time = time.time()
print("Join method took:", end_time - start_time, "seconds")
# 执行两种方法并比较结果
append_method()
join_method()
输出结果如下:
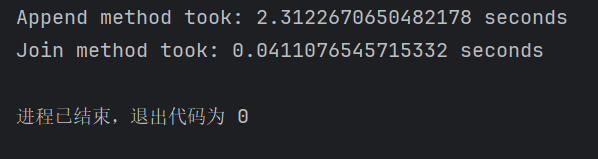
可以看到运行时间相差50倍左右,所以在进行字符串拼接操作时需要谨记注意这个问题;
5.1 特殊字符:python支持在终端中输出emoji
5.2 '''三引号:可以书写多行字符串
这里我们引用“菜鸟教程”中对三引号字符串的介绍:
【菜鸟教程】:python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
5.3 字符串前缀
f"":可以显示变量或表达式的值
r"":声明此字符串为原生字符串(raw string)
fr"" | rf"":表示带有表达式且不进行转义的字符串
print(rf"12\t")
>>> 12\t
4.3 TXT文本字符串解析
string = '823.0 361.0 830.0 364.0 823.0 376.0 817.0 372.0 small-vehicle 1'
numbers = list(map(float, string.strip().split()[:8]))
4.4 使用re删除字符串结尾处的多种str
re.sub(r'.(jpg|bmp)$', "", file)
7 Enum
Enum可以用来记录状态信息;
8 List
检查列表是否空:if lst
快速获得列表的副本:a[:]
(这种方法比.copy()要方便一些)
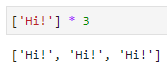
列表批量复制:lst*10
编程范式
I. 生成新列表,而不要修改迭代中的列表
在处理列表数据时,尽量不要在for循环遍历列表时修改其中的元素,因为这可能会导致意想不到的结果。如果需要修改列表中的元素,请创建一个新的列表,并将修改后的元素添加到新列表中。
7.1 条件筛选列表
可以使用filterfalse来条件筛选列表,这样可读性也很高:
a = [1, 2, 2, 3, 4]
def even(x):
return x % 2 == 0
from itertools import filterfalse
a[:] = filterfalse(even, a)
# --> a = [1, 3]
7.3 数据类型转换
string = ["823.0","361.0","830.0","364.0"]
numbers = map(float, list_strings)
9 Dictionary
8.1 同时遍历key和value
使用d.items()获得字典的key和value:
for key,val in d.items():
...
8.2 设置key的默认值:防止dict[key]的索引错误
# 如果键不存在于字典中,将会添加键并将值设为default
dict.setdefault(key, default=None)
6.3 使用OmegaConf管理字典对象
conf = OmegaConf.create(dict)
6.4 字典运算:|
dict1 = {"a": 1, "b": 2}
dict2 = {"c": 3, "d": 4}
print(dict1 | dict2)
# {'a': 1, 'b': 2, 'c': 3, 'd': 4}
10 Generator(生成器)
Claude-3-Opus-200k
当我们提到"generator"时,它通常指的是一个生成器对象(generator object);这个对象可能是由生成器函数创建的,也可能是由生成器表达式创建的。
10.1 Generator对象也是可迭代对象
11 Iterable (可迭代对象)
首先我们来看看怎么判断一个对象是不是可迭代的:
In [10]: from collections.abc import Iterable
# abc: abstract class
In [11]: isinstance([],Iterable)
Out[11]: True
In [12]: isinstance({},Iterable)
Out[12]: True
In [13]: isinstance('hello',Iterable)
Out[13]: True
In [14]: isinstance(mylist,Iterable)
Out[14]: False
In [15]: isinstance(100,Iterable)
Out[15]: False
可以看到就是使用isinstance(obj, Iterable)来进行判断;
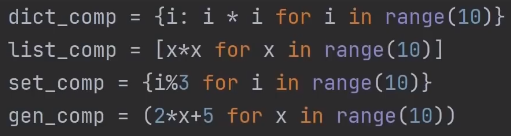
10.1 Comprehension (列表推导式)
10.2 数据遍历操作
10.3 排序操作:sorted()
对于排序操作,南溪推荐使用sorted()而不是iter.sort(),因为sorted(iter)会返回排序后的新列表,而iter.sort()是对iter内部进行原位排序而返回值为None,这不符合函数式编程的原则,所以这里南溪推荐使用sorted()。
Q:sorted()函数内部用的是什么排序算法?
经过查阅资料可知:
Python中的sorted()函数内部实现使用的是 Timsort,这是一种混合排序算法,结合了归并排序和插入排序的优点,具有较高的性能和稳定性。
Timsort由Tim Peters在2002年设计,是Python中的默认排序算法。它的时间复杂度为O(n log n),且对于已经部分排序的数据,Timsort具有较高的性能优势。
具体来说,Timsort将待排序序列分为若干个小块,对每个小块使用插入排序算法进行排序,然后再通过归并排序算法将这些小块合并成一个有序的序列。该算法还使用了一些优化技巧,例如galloping mode和minrun等,进一步提高了排序性能。
10.4 生成器(Generator):yield构造的特殊函数
10 高阶函数
Filter: filter()
Python的内建函数filter()可以用于筛选一个容器对象;
Reduce: reduce(function, iterable[, initializer])
参数说明:
initializer:默认为None,若存在,则将其作为序列之前的初始项“
a
0
a_0
a0”。
11 Control Flow
10.1 For-else语句
"For-else"特性:else语句块只会在循环中没有中断(break | Error)时,才会执行;
使用 for-else 实现条件跳出外层循环
举例说明:
for i in range(3):
for j in range(3):
if i*j == 6:
print(f"找到组合({i},{j})")
break
else:
continue # 仅当内层循环完整执行时继续
break # 外层循环提前终止
相关实例:
10.2 Match-case语句:模式分支
我感觉可以用来实现函数形参的多态;
12 Class
12.1 Attribute
12.1.1 静态属性:“类属性”
Python中可以通过定义类属性的方法来定义静态属性,静态属性可以帮助我们实现具有单例性质的成员变量,因为有些变量会占用比较大的内存资源,如果分别独立初始化的话会占用大量的内存资源,这是我们就可以使用类属性来将这些资源进行统一管理;
12.1.2 私有属性:以__开头(双下划线)
Python定义私有属性有一个默认的规则
“Private” instance variables that cannot be accessed except from inside an object don’t exist in Python. However, there is a convention that is followed by most Python code: a name prefixed with an underscore (e.g. _spam) should be treated as a non-public part of the API (whether it is a function, a method or a data member). …
… Any identifier of the form __spam (at least two leading underscores, at most one trailing underscore) is textually replaced with _classname__spam, where classname is the current class name with leading underscore(s) stripped…
(关于“python中私有属性定义的分析”可以参考《[Python]Python中的私有变量》)
也就是说,python中对于私有成员的默认规则是:使用双下划线(eg. __member)定义的成员变量。
12.1.3 定义只读属性:@property
使用装饰器@property+私有变量可以定义只读属性;
class Comment:
def __init__(self, id: int, text: str):
self.__id: int = id
self.__text: str
@property
def id(self):
return self.__id
@property
def text(self):
return self.__text
使用@property修饰的函数具有以下性质:
- 只能有一个参数
self; - 不能与其它成员属性同名;
- 此函数在调用时不需要加
()。
我们可以使用
__将属性私有化,然后通过@property声明该属性的函数接口,实现该成员属性的read-only特性;
12.1.4 @property_name.setter:实现属性赋值的检查
对于某些属性,由于对参数值有着一定要求,比如:batch-size就需要是正整数;
这时我们可以使用**@property_name.setter**在对属性赋值时先对参数值进行合法性检查,例如:
class A():
def __init__(self):
self.__value = 1
@property
def value(self):
return self.__value
@value.setter
def value(self, x):
if x < 0:
raise ValueError("value must > 0")
self.__value = x
a = A()
a.value = -1
12.1.5 使用@property实时计算属性值
我们可以使用@property声明属性函数,然后在此property函数中实时计算属性的值,减少代码的逻辑冗余;
这里可以看看知乎回答“谁能给我解释一下python中,@property装饰器的用途和意义? - 深度学习可好玩了的回答 - 知乎”;答主在回答中使用的“电压、电阻和电流”的原理,这里摘录如下:
[答主“深度学习可好玩了”]:解释一下第三种情况,比如我们已知电阻阻值和电压,要求电流,最好的方式就是实现@property装饰的函数,可以像属性一样访问电流,并且是实时计算的。
12.1.6 __get__():“类似属性的装饰器”
ChatGPT4:
描述符在Python中的属性访问过程中扮演了一个非常重要的角色。它们使得Python开发者能够创建高度定制化和控制精细的属性访问行为,这在很多高级应用中非常有用。
12.1.7 Python的属性查找机制
请参见博文《Python的属性查找机制的学习笔记》
13.2 Method
13.2.1 常见的method形式
在Python中,类(class)中的方法是定义在类内部的函数,它们可以访问和修改类的属性。方法的一般形式如下:
class MyClass:
def __init__(self, *args, **kwargs):
# 初始化方法,通常用于设置类的属性
self.attribute = value
def method_name(self, *args, **kwargs):
# 方法定义,self 是指向类的实例的引用
# 方法可以访问和修改实例的属性
# 方法可以有任意数量的参数,包括位置参数(args)和关键字参数(kwargs)
# 方法体中可以包含任何合法的Python代码
pass
@classmethod
def class_method_name(cls, *args, **kwargs):
# 类方法,第一个参数是类本身,而不是类的实例
# 类方法可以访问类的属性,但不能直接访问实例的属性
pass
@staticmethod
def static_method_name(*args, **kwargs):
# 静态方法,不能访问类的属性或实例的属性
# 静态方法通常用于实现与类无关的辅助功能
pass
Note:
__init__是构造方法,用于在创建类的实例时初始化对象。它通常包含self参数,代表类的实例本身,以及任意数量的位置参数和关键字参数,这些参数可以用来设置实例的属性。- 方法Method(如
method_name)是类的普通成员函数,它们可以访问和修改实例的属性。方法的第一个参数总是self,它指向调用方法的实例。
类方法 Class Method:第一个参数是cls
使用 @classmethod 装饰器,它们的第一个参数是cls,代表类本身。类方法可以访问类的属性,但不能直接访问实例的属性。
静态方法 Static Method:不用加cls和self
使用 @staticmethod 装饰器,它们不能访问类的属性或实例的属性。静态方法通常用于实现与类和实例都无关的通用功能。
这是 class-name 提供了一种命名空间的作用。
13.2.2 动态装饰类实例方法:MethodType()
class Test(object):
def revive(self):
print('revive from exception.')
# do something to restore
def read_value(self):
print('here I will do something.')
# do something.
a = Test()
# a.read_value()
def new_read_value(self,func):
print(f'My name is Alice. Nice to meet you!')
func()
from types import MethodType
import functools
a.read_value = MethodType(functools.partial(new_read_value,func = a.read_value), a)
a.read_value()
>>> My name is Alice. Nice to meet you!
here I will do something.
13.3 反射函数(magic function)
hasattr:判断instance是否包含某个属性
hasattr(ins, name) # name是属性名的字符串
13.4 运算符重载
| 函数名 | 逻辑运算符 | 等效形式 |
|---|---|---|
| A == B | __eq__ | A .__eq__(B) |
| A <= B | __le__ | A .__le__(B) |
13.5 Enum (枚举类)
from enum import Enum, unique
@unique # 确保枚举类型不会重复
class Color(Enum):
YELLOW = 1
RED = 2
BLUE = 3
12.5 数据类:dataclass
dataclass是python提供的一种装饰器,可以快速编写一个数据类;
关于dataclass的示例,请参考《mCoding | Python dataclasses will save you HOURS, also featuring attrs》;
from dataclasses import dataclass
@dataclass()
class Comment:
id: int
text: str
13 Decorator (装饰器)
15.1 函数装饰器
@functools.wraps(func):在装饰时保持原函数名称
对于函数的装饰,我们推荐使用@functools.wraps,此装饰器在进行装饰时也会保持原函数的名称,(而不加上此修饰,会使函数变成装饰器的名字);
使用@functools.wraps编写装饰器的模板如下(感谢无未大佬的分析):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 1、调用原函数
results = func(*args, **kwargs)
# 2、增加新功能
...
return results
return wrapper
使用装饰器为“子类”初始化添加检查代码
这里的“子类”我们用了双引号,因为最初我们本来是想在父类的代码中实现“对子类初始化参数的限制”,后来发现这是不可能实现的,因为子类在编写时具有足够的自由,父类无法对子类的行为作出任何限制;
于是我们想到使用Decorator来模仿一个“父类”来规范子类的行为,在我们的任务中:即需要检查“子类”在初始化之后参数的使用情况。
在此功能中我们同样需要用到@functools.wraps(),然而单纯使用上面的方法会出现错误,(这也是 Steven D’Aprano在回帖中提到的bug):
在对类的cls函数进行装饰后,会使得类的构造函数变成返回的装饰函数,其类型为
<class 'function'>(使用type()获得),该类型不属于type类型(即<class 'type'>),于是在使用print(isinstance(a, TitularChildClass))会报错:
TypeError: isinstance() arg 2 must be a type, a tuple of types, or a union
为了解决这个问题,我们需要进一步对代码进行封装,这里我们想到的方案是:由于问题是由返回的函数不是<class 'type'>引起的,于是我们猜想是否可以使用class来代替function,从而是返回的对象具有<class 'type'>类型呢?
于是我们采用了如下的解决方案:
def functional_checker(cls):
@functools.wraps(cls, updated=()) # 使用updated=()停止更新
class DecoratedClass(cls):
def __init__(self):
super(DecoratedClass, self).__init__()
# do some operations
...
return DecoratedClass
@functional_checker
class TitularChildClass:
def __init__(self):
...
Note1:@wraps(..., updated=())停用更新,防止调用DecoratedClass.__dict__的update()函数,因为Class.__dict__是一个只读属性;
Note2:在查阅资料时,我们看到也有使用functools.update_wrapper()来实现类似的功能,不过实际上@functools.wraps()在内部也是调用的functools.update_wrapper():

所以这里我们就直接使用高级函数wraps()来实现这个功能;
Note3:此功能也可以直接构造对__init__()的装饰器来实现,这里可使用instance = args[0]来取得实例的self引用,在调用初始化函数之后,再使用instance来进行后续的检查代码;
14 IDE
14.1 PyCharm
请参考博文《PyCharm Cookbook by Eric》
14.2 VSCode
请参考博文《【Python】VSCode&Python Cookbook by Eric》
15 简单交互设计
进度条
请参考博文《《南溪的python灵隐笔记》——tqdm的学习笔记》
16 解释器选项
-O:解释器优化模式
优化模式可以通过解释器选项-O或环境变量PYTHONOPTIMIZE开启,它会在编译时移除不必要的语句,如assert语句等。这种优化对Python本身的运行效率有所提升,但对PyTorch程序则影响不大。
sys.flags.optimize:判断当前解释器是否处于优化模式。
17 代码调试
18.1 开启解释器的调试模型:-O
- 在默认情况下,Python解释器会以非优化模式启动,此时
__debug__的值为True。 - 当启动解释器时使用
-O或PYTHONOPTIMIZE环境变量开启优化模式时,__debug__的值就会被设置为False。
18.2 中止程序:quit()
在python里中止程序,可以使用:
quit()
exit()
两个函数的作用是完全一样的;
18.2 简化错误信息:import pretty_errors
可以使用pretty_errors库来简化错误信息;
18.3 输出表达式的值:f{x=}
使用f{x=}输出值的效果如下:

18.4 获取函数被调用位置文件名 & 被调用代码行
# 获取被调用位置所在文件名
sys._getframe().f_back.f_code.co_filename
# 调用者所在行号
ln = sys._getframe().f_back.f_lineno
# 被调用位置信息
sys._getframe().f_back.f_code.co_filename + ": " + str(sys._getframe().f_back.f_lineno)
18 代码简化
使用comprehension一行代码实现list元素简单映射
我们可以使用推导式在一行代码中完成list元素的简单映射,例如:
r =(x**2 for x in [1,2,3,4,5,6,7,8,9])
list(r)
map也可以一行实现元素映射,不过没有comprehension快
map也可以在一行代码中实现对列表中的元素进行简单的映射,
例如:

不过其运算速度没有comprehension快,测试结果截图如下:

comprehension中最后一个list会使用全局变量
我们可以看看下面的例子:

这里推导式的最后一个list变量lst,在调用的时候使用的是全局变量list(可能内部是以字典的形式调用的),而前面所有的mutable对象则是evaluated immediately,即赋值当前了lst的引用;
[Note]:关于以上内容请参考《PEP 289 – Generator Expressions | “outermost for-expression is evaluated immediately”》;
而在调用时,由于lst = [1,2]将lst替换成了新的列表[1,2],所以之前的引用则成为匿名变量lst_0,但是其内容仍然存在(即之前的[1,2,3]);
不要使用comprehension来合并for-loop和if-statement
for x in [x for x in range(a) if x % 2 == 0]:
pass
将for-loop和if-statement合并可以将代码减少到一行,但是会降低代码的运行速度;
测试代码: [comprehension_for+if.ipynb]
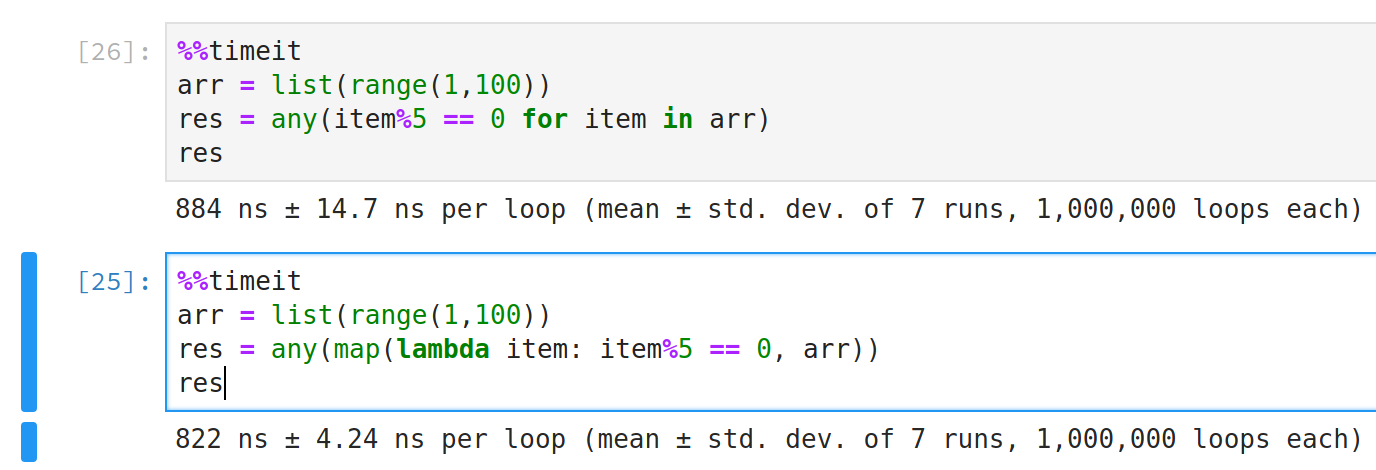
使用any()和all()实现列表的快速判断
示例代码:
arr = list(range(1,100))
res = any(map(lambda item: item%5 == 0, arr))
Map方式比for形式速度快,如图所示:
19 安装package
请参见我们的博文《Conda & Pip Cookbook by Eric》
常用的python包
cython: Cython
opencv-python: cv2
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
20 Package组织结构
在包中使用__init__.py来声明当前包需要引入的内容,具体来说,可以使用__all__指定需要引入的文件,例如:__all__=["file_a","file_b"],其中file_a.py和file_b.py位于当前当前包所在的目录中;
21 命令行参数解析:argparse
parser = argparse.ArgumentParser(description='Describe_scripts_function')
# 设置的参数默认是必填项
...
args = parser.parse_args()
return args
22 终端显示
推荐使用rich库进行终端信息的显示;
18.1 打印信息同时显示代码行号——“带有行号的print”
可以使用console.log()打印信息并在右侧显示信号所在代码位置(行号):
from rich.console import Console
console = Console()
console.print(table)
console.log("information")
15.2 显示表格:rich.table
我们可以使用rich.table形成表格内容并显示输出;
关于rich.table的使用请参考《Beautiful Terminal Styling in Python With Rich | Table》;
23 统计运行时间:Timer
实现Timer类来统计代码块的运行时间,(实现方法可以参考[ailzhang/blog_code/tile/utils.py/Timer])
20.1 使用time.perf_counter()获得精确时间戳
start = time.perf_counter()
time.sleep(1)
end = time.perf_counter()
print(end-start)
24 性能分析
关于对python代码进行性能分析,请参考博文《python代码优化:运行时间分析》
21.1 Pytest-benchmark
可以用来测试单个函数的执行时间;
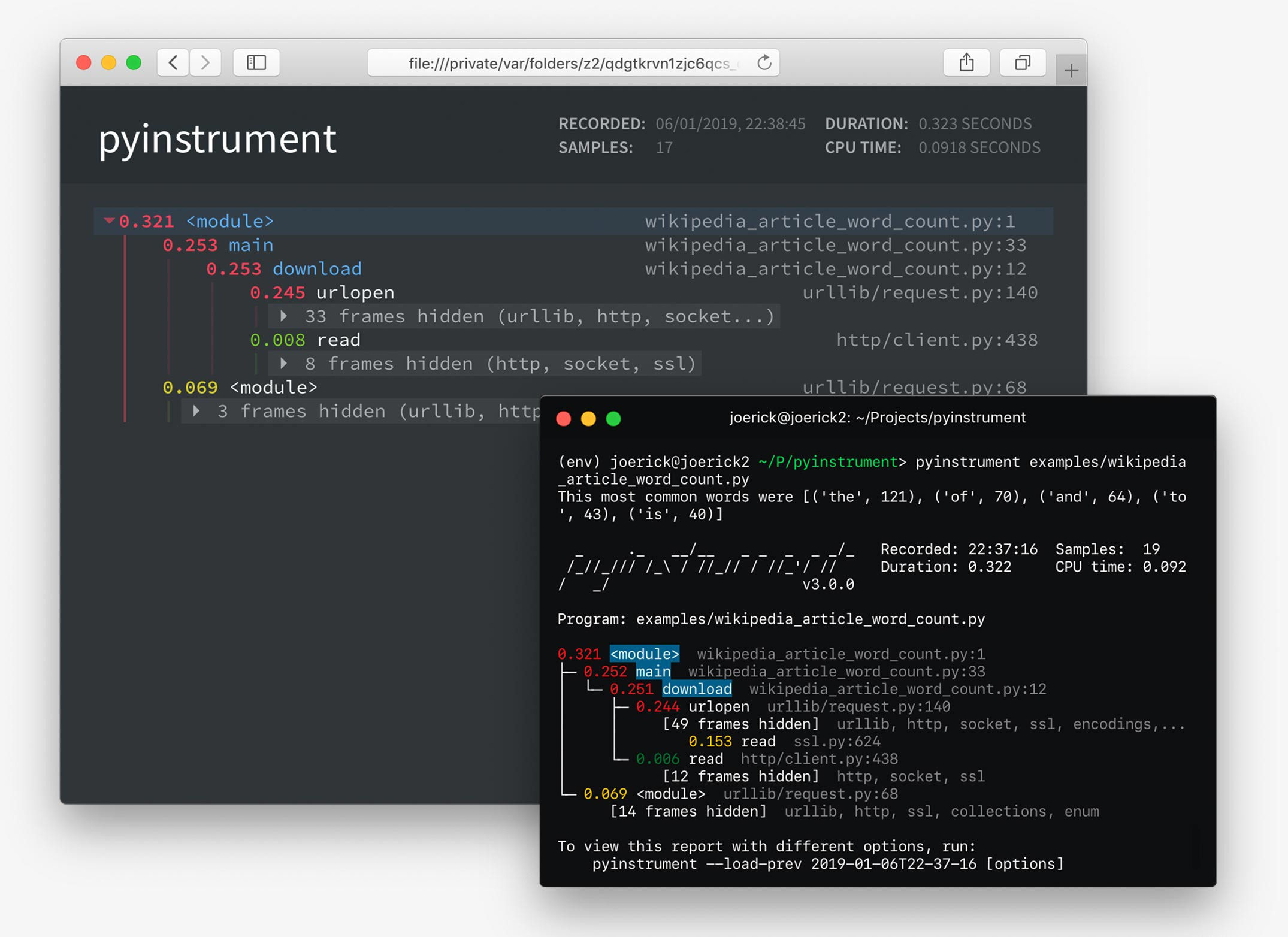
21.2 Pyinstrument
Pyinstrument分析的效果如图所示,
25 代码可视化执行:[PythonTutor]
可以使用[PythonTutor]来可视化代码的执行,如图所示,

26 异常处理
关于 try-except-else-finally语句的详细用法,请参考《Python3 错误和异常 | 菜鸟教程》
try:
x = 10/0
except ZeroDivisionError:
print("Catch the ZeroDivisionError")
except Exception as e:
raise e # 对于当前代码域无法处理的情况,继续向上抛出异常
try-except-else-finally语句流程图

(图来自《菜鸟教程》)
这里的 except-else 形成了一种分支结构;
except语句可以捕获多个异常
try:
# Risky operation
except (TypeError, ValueError) as e:
# Handle both exceptions
层次化异常触发
Note:
此技巧来自于博文《20个改善编码的Python异常处理技巧,让你的代码更高效》。
# Demo for Python exception handling with 'from' keyword
def function_that_raises_ioerror():
# This function simulates an operation that could fail, e.g., file operation
raise IOError("File not found error")
def higher_level_operation():
try:
function_that_raises_ioerror()
except IOError as e:
# While handling the IOError, we realize a more general error should be raised for higher-level logic
# We use the 'from' keyword to chain the exceptions, providing context about the original error
raise RuntimeError("Higher-level operation failed due to an IO error") from e
# Running the higher-level operation to see the effect of exception chaining
higher_level_operation()
# 可以查看异常错误提示的信息
常见异常
KeyboardInterrupt:按键中断
27 数值计算
28 获取系统信息
28.1 获取系统环境变量
可以使用os.environ来获得系统环境变量的字典;
28 清理内存
del variable
gc.collect() # 释放内存
29 资源管理
atexit:程序退出时执行资源释放
30 自动化运维
阻塞式执行:subprocess.run([command])
非阻塞执行:subprocess.Popen([command])
command = "main.exe"
subprocess.Popen([command])
30.1 Os.system
import os
os.system("main.exe")
30.2 Subprocess.run
ChatGPT4: 当使用
subprocess.run(),最佳实践是将命令和参数分开为列表中的元素。这种方法使得命令的解析更加明确和准确,特别是当命令或参数包含空格、特殊字符或需要特殊处理时。
31 文件读写
32 时间信息处理
使用pendulum来进行处理时间信息,可以使用conda install pendulum来进行安装;
获取当前时间
now = pendulum.now()
新建local时间
dt = pendulum.local(2021, 12, 6)
33 网络连接
请参考博文《计算机网络基础知识笔记》
34 绘制图表
关于使用python绘制数据展示的图表,请参考《Python绘制图表的学习笔记》

















 1869
1869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









