







📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
一、引言:大模型重塑Web UI自动化测试格局
Web UI自动化测试是保障软件质量的关键环节,然而传统Selenium脚本开发面临编写成本高、维护难度大、学习曲线陡峭等挑战。随着大语言模型(LLM)技术的成熟,2025年上半年,这一领域正经历革命性变革。
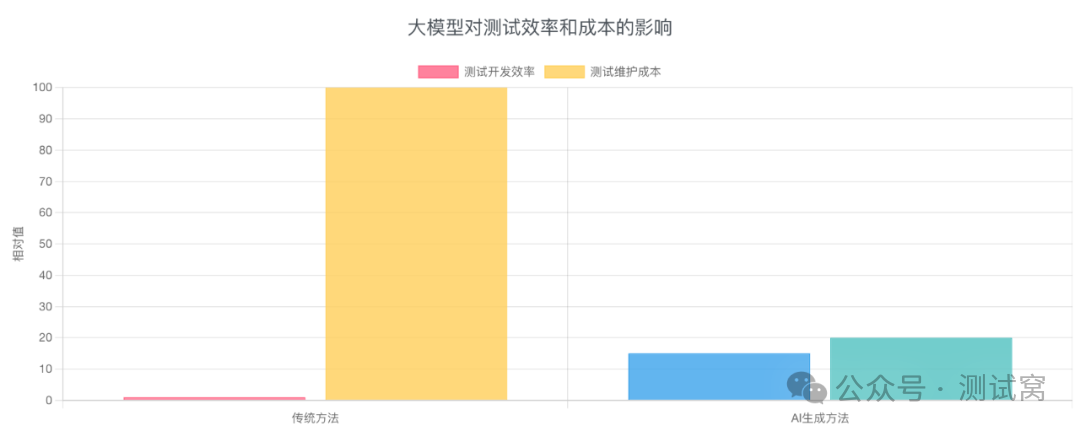
使用LLM生成Selenium脚本可将测试开发效率提升10-20倍,同时将维护成本降低70-80%。这种变革对测试工程师和教育工作者具有重大意义:测试团队能够将更多精力投入到测试设计而非代码编写上;教育工作者可以利用这些工具简化教学,使学生更专注于测试逻辑而非工具细节。
二、学术研究前沿:大模型生成测试脚本的技术突破
2.1 基于迭代混合程序分析的测试生成
2025年3月,Panta技术的提出代表了大模型在测试生成领域的重要突破。这项由Sijia Gu等人开发的技术通过模拟人类开发者分析代码和构建测试用例的迭代过程,显著提高了测试覆盖率。
Panta创新性地将静态控制流分析和动态代码覆盖分析相结合,系统地引导LLM识别未覆盖的执行路径并生成更好的测试用例。实验评估表明,在开源项目中具有高圈复杂度的类上,Panta比最先进的方法实现了26%更高的行覆盖率和23%更高的分支覆盖率。
2.2 自动化提示优化的测试用例生成
Prompt Alchemist是2025年初提出的一种针对测试用例生成的自动化提示优化技术,由Shuzheng Gao等人开发。该技术认识到LLM的性能高度依赖于提示的质量,而不同的LLM可能最适合不同的提示。
Prompt Alchemist的创新点在于:
-
它不是简单地组合和变异现有提示,而是基于适当的指导进行优化,避免了提示缺乏多样性和生成测试用例中重复错误的问题
-
它引入了领域上下文知识,增强了LLM在特定任务中的性能
2.3 基于LLM的测试生成与修复协同进化
TestART是2024年8月提出的一种新颖的单元测试生成方法,通过测试生成和修复的协同进化显著提升了LLM生成测试的质量。该方法首次利用基于模板的修复策略有效修复LLM生成测试用例中的错误,同时提取成功测试用例的覆盖信息作为覆盖率引导测试反馈。
在比较实验中,TestART在通过率上提高了18%,在三种数据集上的覆盖率提高了20%,并且仅用一半数量的测试用例就达到了比EvoSuite更好的覆盖率。
2.4 基于属性检索的测试生成增强
LLM-based Unit Test Generation via Property Retrieval是2024年10月提出的一种创新机制,它扩展了基于LLM的检索增强生成(RAG)技术,超越了基本的向量、文本相似性和基于图的方法。该方法考虑了任务特定的上下文,并引入了定制的属性检索机制。
在测试生成过程中,该方法将测试生成过程分为"Given"、"When"和"Thens"段落。当为目标方法生成测试时,它不仅检索被测代码的一般上下文,还考虑其他方法的现有测试等任务特定上下文,从而在目标方法和其他方法之间形成属性关系。
2.5 大模型在测试脚本生成中的挑战与局限
尽管LLM在测试脚本生成方面取得了显著进展,但仍存在一些重要挑战。2024年12月发表的研究指出,当前LLM-based测试生成工具在检测bug方面存在局限性。该研究使用真实的人为编写的错误代码作为输入,评估了这些工具如何未能检测到bug,甚至通过在生成的测试套件中验证bug并拒绝揭示bug的测试,使情况变得更糟。
研究表明,这些工具的测试预言设计为通过,这可能导致它们无法真正实现软件测试的预期目标。
三、产业应用进展:大模型在Web UI测试中的落地实践
AI驱动的Selenium测试自动化平台
2025年,多家企业推出了基于AI的Selenium测试自动化平台,这些平台利用大模型技术显著简化了Web UI测试脚本的生成过程。核心功能包括测试用例自动生成、自适应测试维护和多浏览器/跨平台支持。
自我修复的Selenium测试框架
Healenium(https://www.healenium.io/)是2025年推出的一种创新的AI驱动的UI测试自动化框架,特别针对解决Selenium测试脚本维护难题。该框架能够自动检测损坏的定位器并进行自我修复,无需手动更新。当UI发生变化导致定位器失败时,Healenium不会让测试失败,而是动态查找并修复定位器,减少手动维护工作。
基于大模型的Web UI测试脚本生成工具
2025年上半年,多家公司推出了专门针对Web UI测试脚本生成的大模型工具,这些工具能够直接生成可执行的Selenium脚本。如AI Test Case Generator、FREE AI-Powered Selenium Code Generator和AutonomIQ等工具,都能将自然语言描述的测试用例转换为可执行的Selenium脚本。
基于Gemini的自动化测试脚本生成
Google的Gemini AI模型在2025年得到了显著改进,多家公司已经开发了基于Gemini的自动化测试脚本生成工具。这些工具能够从Excel文件加载测试用例,调用Gemini的API为每个测试用例生成Selenium脚本,生成的脚本可以直接在Selenium环境中执行。
四、大模型对Web UI测试脚本生成的变革性影响
4.1 测试脚本生成方式的根本转变
大模型正在从根本上改变Web UI测试脚本的生成方式,从传统的手工编写或基于录制的方法转向AI驱动的自动化生成。这种转变体现在以下几个方面:
-
从代码导向到意图导向:传统的Selenium脚本编写需要测试人员具备较强的编程能力,而大模型允许测试人员以自然语言描述测试意图
-
从线性思维到智能推断:大模型能够理解测试用例的上下文和意图,自动推断出必要的操作步骤
-
从静态脚本到动态适应:AI生成的测试脚本具有更好的适应性,能够自动应对UI的微小变化
4.2 测试效率与质量的提升
大模型在Web UI测试脚本生成中的应用已经带来了测试效率和质量的显著提升:
-
测试开发效率提升:使用AI生成Selenium脚本,测试开发速度提高了10-20倍
-
测试维护成本降低:AI生成的测试脚本具有更好的稳定性和自我修复能力,使维护工作量减少了70-80%
-
测试覆盖率提高:研究表明,AI驱动的测试生成能够达到90%或更高的测试覆盖率,而传统方法通常只能达到30%左右
-
测试准确性提升:大模型能够生成更全面、更符合用户实际使用场景的测试用例
4.3 测试团队结构与技能要求的变化
大模型的引入正在改变测试团队的结构和技能要求:
-
角色转变:测试工程师的角色正在从脚本编写者转变为测试设计者和质量分析师
-
技能升级:测试人员需要掌握新的技能,如提示工程、测试设计思维和结果分析
-
团队协作:大模型使得非技术人员能够参与到测试自动化过程中,促进了跨职能团队的协作
五、工具推荐与实践指南
5.1 学术研究工具推荐
Panta
一种基于迭代混合程序分析的测试生成技术,能够显著提高测试覆盖率。虽然最初是为单元测试设计的,但其思想和方法对于Web UI测试脚本生成具有重要参考价值。
Prompt Alchemist
这一技术可以帮助测试人员为不同的LLM模型定制最优提示,从而生成更准确的测试脚本。对于教育工作者来说,这是一个很好的教学工具。
TestART
这种测试生成和修复的协同进化技术可以帮助提高AI生成测试脚本的质量和可靠性,特别适合于复杂Web应用的UI测试。
5.2 产业应用工具推荐
testRigor
一个领先的生成式AI测试自动化工具,允许用户使用简单的英语构建测试自动化。它能够将高级指令(如"购买Kindle")转换为具体的Selenium步骤。testRigor已经被70,000多家公司采用。
AI Test Case Generator
一个专门为Jira和Azure设计的工具,使用AI和LLM将用户故事直接转换为可执行的测试用例。对于使用敏捷开发方法的团队来说,这是一个理想的选择。
AutonomIQ
该工具的脚本生成功能由自然语言引擎提供支持,能够理解英语描述的测试意图并生成相应的Selenium脚本。它的独特之处在于能够在几分钟内创建Selenium脚本,大大加快了测试自动化过程。
5.3 实施路径与最佳实践
基于2025年上半年的研究和应用进展,以下是实施大模型驱动的Web UI测试脚本生成的建议路径和最佳实践:
- 渐进式实施
从部分关键功能开始试点,逐步扩展到整个应用
- 混合模式
采用人工审查与AI生成相结合的混合模式,确保测试质量
- 提示工程培训
投资于测试团队的提示工程培训,这是有效使用AI生成测试脚本的关键技能
- 版本控制
对AI生成的测试脚本实施严格的版本控制,确保可追溯性和可审计性
- 持续监控
建立对AI生成测试脚本的持续监控机制,收集执行数据,评估测试覆盖率和缺陷检测率
六、未来趋势与挑战
6.1 多模态测试脚本生成的发展
未来,多模态测试脚本生成将成为重要发展方向。当前的LLM主要基于文本输入生成测试脚本,而未来的AI测试工具将能够利用更丰富的输入模态,如视觉输入、视频输入和语音输入。
6.2 测试脚本生成的效率优化
未来的研究将更加关注测试脚本生成的效率优化,包括模型轻量化、增量生成、并行生成和上下文感知等技术。
6.3 测试脚本质量与可靠性的提升
尽管大模型在测试脚本生成方面取得了显著进展,但质量和可靠性仍是主要挑战。未来的发展将集中在测试预言改进、形式化验证、人类反馈循环和多AI协作等方面。
6.4 大模型测试生成面临的挑战与应对
大模型在Web UI测试脚本生成中仍面临多项挑战,包括理解准确性、脆弱性、可解释性、安全风险和过度生成等问题。应对这些挑战需要采用更精确的提示工程、更健壮的定位策略、可解释AI技术和智能去重技术等。
七、结论与展望
7.1 大模型在Web UI测试脚本生成中的价值总结
基于2025年上半年的研究和应用进展,大模型在Web UI测试脚本生成中展现出巨大价值:
-
效率提升:AI驱动的测试生成使测试开发速度提高了10-20倍
-
成本降低:测试维护工作量减少了70-80%
-
质量提升:AI生成的测试脚本能够覆盖更广泛的场景
-
可访问性增强:自然语言界面使非技术人员也能参与测试自动化
7.2 未来发展的关键方向
展望未来,大模型驱动的Web UI测试脚本生成将朝着以下方向发展:
-
更智能的上下文理解:AI将能够更好地理解整个应用上下文和用户旅程
-
自主测试执行:AI不仅生成测试脚本,还将能够自主执行测试、分析结果并生成报告
-
预测性测试:基于历史数据和应用变更模式,AI将能够预测可能的缺陷区域
-
全栈测试生成:从UI测试扩展到API测试、数据库测试和性能测试
-
人机共生:AI与人类测试人员将形成更紧密的协作关系
大模型驱动的Web UI测试脚本生成正在引发软件测试领域的深刻变革。对于测试工程师和教育工作者而言,现在是拥抱这一变革的最佳时机。通过学习和应用最新的AI测试技术,测试团队可以显著提高测试效率和质量,教育工作者可以培养适应未来的测试人才。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









