




哈,提示词工程这个相对来说比较简单,不像上一篇文章难懂,本文快速过一下!
“这个AI根本不好用,给出的回答都是泛泛而谈!”
“为什么同一个问题,别人能获得高质量答案,而我只能得到平庸的结果?”
如果你曾有过这样的困惑,问题可能不在于AI的能力,而在于你与它对话的方式。今天,我们就来揭开提示词工程的神秘面纱,掌握与AI高效沟通的秘诀。
为什么需要学习提示词工程?
想象一下,你向一位助手交代任务:“帮我写个PPT”和“帮我写一篇主题是春季健身注意事项的PPT,风格轻松有趣,面向20-35岁的上班族”——哪个指令能得到更符合预期的结果?
AI也是如此。提示词(Prompt)就是你与AI沟通的指令,质量直接决定回答的质量。
核心四步法:让AI听懂你的话
1. 明确角色:你是谁?
在提问前,先为AI设定一个专业角色。
普通提问:
“告诉我如何学习英语”
角色设定提问:
“假设你是一位有10年教学经验的英语教授,为一名有一定基础但缺乏系统性的中文母语者设计一个6个月的英语提升计划”
看,角色设定让AI的回答更具专业性和针对性。
2. 定义任务:你要什么?
清晰、具体地描述你的需求,避免模糊表述。
模糊任务:
“帮我写销售文案”
明确任务:
“为一款智能手环撰写朋友圈广告文案,突出其心率监测和睡眠分析功能,目标用户是关注健康的年轻人,字数在150字以内”
3. 补充细节:在什么情况下?
提供背景信息、约束条件和具体要求。
缺乏细节:
“总结这篇文章”
丰富细节:
“用三个 bullet points 总结这篇关于人工智能的文章,每点不超过20字,面向完全不懂技术的小白读者”
4. 指定输出:要什么形式?
明确告诉AI你期望的回答格式。
不指定格式:
“给我一些项目创意”
指定格式:
“列出5个Python初学者可以在一周内完成的小项目创意,每个包括:项目名称、难度等级(1-5星)、所需技能和预期收获”
接下来,老规矩,上实战
import requests
import json
import time
import pandas as pd
# ==================== 全局配置 ====================
# 请根据你的聚合平台信息修改以下配置
BASE_URL = "https://api.ufunai.cn/v1" # 替换为你的平台地址
API_KEY = "sk-xxxxx" # 替换为你的API密钥
MODEL_NAME = "gpt-4-turbo" # 指定要测试的模型名称
# =================================================
def test_prompts(prompts, max_tokens=500, temperature=0.7):
"""
测试不同提示词在指定模型上的效果
参数:
prompts: 提示词列表
max_tokens: 最大生成长度
temperature: 温度参数
"""
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
results = []
print(f"开始测试 {len(prompts)} 个提示词在模型 '{MODEL_NAME}' 上的效果")
print("=" * 60)
for i, prompt in enumerate(prompts, 1):
print(f"\n测试 {i}/{len(prompts)}: {prompt}")
print("-" * 40)
payload = {
"model": MODEL_NAME,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": max_tokens,
"temperature": temperature
}
try:
start_time = time.time()
response = requests.post(
f"{BASE_URL}/chat/completions",
headers=headers,
json=payload,
timeout=60
)
response_time = time.time() - start_time
if response.status_code == 200:
result = response.json()
content = result['choices'][0]['message']['content']
usage = result.get('usage', {})
print(f"生成结果: {content[:200]}...")
print(f"响应时间: {response_time:.2f}秒")
print(f"Token使用: {usage.get('total_tokens', 'N/A')}")
results.append({
"提示词": prompt,
"生成内容": content,
"响应时间(秒)": response_time,
"总token数": usage.get('total_tokens', 0),
"提示token数": usage.get('prompt_tokens', 0),
"生成token数": usage.get('completion_tokens', 0)
})
else:
print(f"请求失败: HTTP {response.status_code} - {response.text}")
results.append({
"提示词": prompt,
"生成内容": f"错误: HTTP {response.status_code}",
"响应时间(秒)": response_time,
"总token数": 0,
"提示token数": 0,
"生成token数": 0
})
except Exception as e:
print(f"请求异常: {str(e)}")
results.append({
"提示词": prompt,
"生成内容": f"异常: {str(e)}",
"响应时间(秒)": 0,
"总token数": 0,
"提示token数": 0,
"生成token数": 0
})
# 添加延迟避免API限制
time.sleep(1)
return results
def save_results(results, filename=None):
"""保存结果到文件"""
if filename is None:
timestamp = time.strftime("%Y%m%d-%H%M%S")
filename = f"prompt_test_{MODEL_NAME}_{timestamp}.xlsx"
df = pd.DataFrame(results)
df.to_excel(filename, index=False)
print(f"\n结果已保存到: {filename}")
return filename
def main():
"""主函数"""
# 检查配置
if BASE_URL == "https://your-aggregator-platform.com/api/v1" or API_KEY == "your-api-key-here":
print("请先修改代码开头的全局配置 (BASE_URL 和 API_KEY)")
return
# 定义要测试的提示词
prompts = [
# 基础提示词
"写一篇关于人工智能的文章",
# 具体指令
"请以科普作者的身份,用通俗易懂的语言写一篇关于人工智能发展现状的文章",
# 角色扮演
"假设你是一位科技杂志主编,为普通读者撰写一篇关于人工智能的专题报道",
# 结构化要求
"""写一篇关于人工智能的文章,要求:
1. 开头引人入胜
2. 主题:对比分析传统编程与人工智能编程的异同点
3. 中间分析三个主要应用领域
4. 结尾给出未来展望
""",
]
# 执行测试
results = test_prompts(prompts)
# 保存结果
filename = save_results(results)
# 简单总结
print("\n" + "=" * 60)
print("测试总结:")
print("=" * 60)
success_count = sum(1 for r in results if not r["生成内容"].startswith(("错误:", "异常:")))
avg_time = sum(r["响应时间(秒)"] for r in results) / len(results)
avg_tokens = sum(r["总token数"] for r in results) / len(results)
print(f"测试提示词数量: {len(prompts)}")
print(f"成功生成数量: {success_count}")
print(f"平均响应时间: {avg_time:.2f}秒")
print(f"平均Token使用: {avg_tokens:.0f}")
# 显示每个提示词的生成内容长度
print("\n各提示词生成内容长度:")
for i, result in enumerate(results, 1):
status = "✓" if not result["生成内容"].startswith(("错误:", "异常:")) else "✗"
print(f"{i}. {status} 长度:{len(result['生成内容']):4d} - {result['提示词']}...")
if __name__ == "__main__":
main()
输出结果:
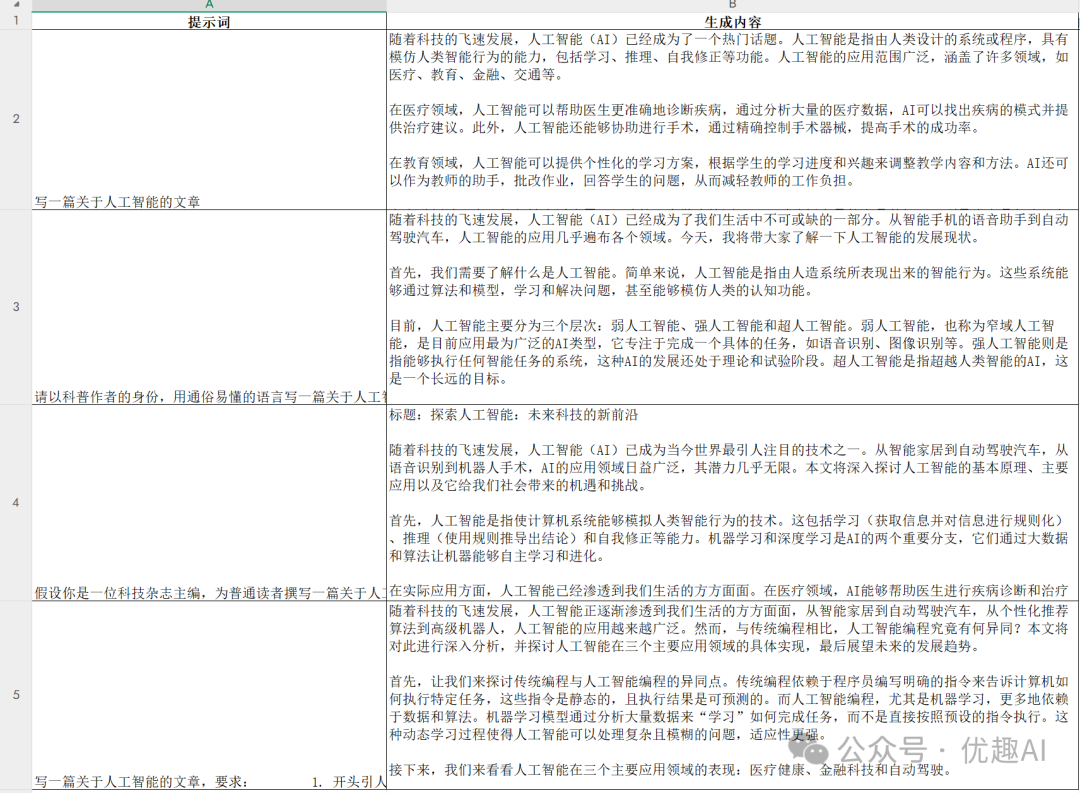
同样是让AI写文章,但四个提示词得到的结果截然不同:
-
第一个:泛泛而谈的科普文
-
第二个:生动有趣的科普文
-
第三个:专业深度的报道
-
第四个:结构清晰的专题分析
结论: 只要需求提得好,AI没有啥干不了!
进阶技巧:成为提示词魔法师
技巧1:分步思考
对于复杂问题,让AI一步步推理:“首先分析这个问题的主要难点,然后提出解决思路,最后给出具体方案”
技巧2:示例引导
提供输入输出示例:“参照这个格式:输入‘会议安排’,输出‘您好,请提供会议时间、参与人员和主题,我将为您安排’”
技巧3:反向验证
“如果我想要相反的结果,你会怎么做?”这有助于检验AI理解的深度。
常见陷阱与避免方法
-
假设AI有背景知识:总是提供必要的上下文
-
一次性要求太多:复杂任务拆分成多个步骤
-
使用模糊词汇:用“300字左右”代替“短一点”
-
忽略迭代优化:第一次不满意,继续细化你的提示词
结语
提示词工程不是一朝一夕就能精通的魔法,而是一项可通过练习不断提升的技能。每次与AI对话,都是锻炼这一能力的机会。
记住,优质的输入决定优质的输出。掌握了与AI高效沟通的艺术,你就拥有了驾驭智能时代的超级能力。
现在,就尝试用今天学到的方法,去命令AI为你创造些惊喜吧!
是不是很简单!!
源代码如需获取,请关注公众号,发送消息ufunai-prompt获取,扫一扫即可获取!
创作不易,码字更不易,如果觉得这篇文章对你有帮助,记得点个关注、在看或收藏,给作者一点鼓励吧~


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











