




今天接下来给大家介绍Transformer!(按照技术维度介绍的话会涉及到一堆理论跟技术术语,反正我看的是晕乎乎的,巴拉巴拉一堆,也不知道说的是啥),咱们换个思路,从直观比喻到技术实现,带你全面理解Transformer。(本文重点讲自注意力机制)
引言:为什么Transformer如此重要?
作为改变AI格局的核心技术——Transformer。它是ChatGPT、Midjourney等众多AI大模型背后的"大脑",理解它对于把握当今AI发展脉络至关重要。
一、RNN的困境:低效的"电话接力"
在Transformer诞生之前,自然语言处理主要依赖RNN(循环神经网络)及其变体LSTM。让我们通过一个生动比喻来理解RNN的工作方式:
场景:你需要将句子"我爱吃苹果"传达给房间里的所有人
RNN的做法:像电话接力游戏一样,你只能悄悄告诉第一个人A,A再告诉B,B再告诉C...信息必须顺序传递
这种方式的四大弊端:
-
效率低下:句子越长,传递次数越多,速度越慢
-
信息失真:传到最后一个人时,句首信息已经模糊(梯度消失问题)
-
位置偏见:末尾词汇获得过多关注,重要程度失衡
-
视野局限:只能看到上文,无法预知下文
这些痛点催生了Transformer的革命性思想。
二、Transformer的革命:高效的"圆桌会议"
Transformer彻底改变了游戏规则,用"圆桌会议"取代了"电话接力":
工作方式:将句子中的所有词同时摆上桌面,每个词都可以直接与所有其他词交流
核心创新:通过自注意力机制,让模型能够同时考虑输入序列中的所有位置,动态捕捉全局信息
本质概括:Transformer是基于自注意力机制的并行处理模型,实现信息的高效全局交互
三、Transformer工作原理详解
第一步:会议准备——词向量与位置编码
在"开会"前需要两项准备工作:
词向量(Input Embedding)- (前面讲过,想了解的可点击)飞机
-
将单词转换为数字向量,如同给每个词分配"数字身份证"
-
通过训练不断优化,使语义相近的词在向量空间中也接近
位置编码(Positional Encoding)
-
解决并行处理导致的顺序信息丢失问题
-
给每个词添加"座位号",确保模型理解词汇顺序
第二步:会议核心——自注意力机制三步走
以理解"苹果"在上下文中的含义为例:
1. 准备发言稿(生成Q、K、V)
-
Query:我想要什么信息?(如"苹果"想问:"我在这里指什么?")
-
Key:我能提供什么线索?(如"吃"的Key是"动作")
-
Value:我的真实信息内容
2. 互动投票(计算注意力分数)
-
"苹果"用自己的Query匹配每个词的Key,计算亲密度得分
-
与语义相关的词(如"吃")得分较高
3. 汇总信息(加权求和)
-
根据得分权重对所有Value进行加权求和
-
生成包含上下文信息的"苹果"新表示
第三步:增强理解——多头注意力机制
单一视角可能不够全面,Transformer同时召开多场专题会议:
-
一个头关注语法关系(主谓宾结构)
-
一个头关注语义关系(同义、反义等)
-
另一个头关注实体信息(人名、地名等)
最后整合各场会议结果,获得更全面的理解。
第四步:深度加工——前馈神经网络
会议结束后,每个词获得的新信息还会经过前馈神经网络进行深度加工,学习更复杂的非线性关系,进一步增强表示能力。
四、Transformer的完整架构:编码器与解码器的协作
把无数个这样的“注意力会议”组织起来,就构成了Transformer的宏伟蓝图。它主要由编码器(Encoder) 和解码器(Decoder) 两大部门组成。(附上架构图)
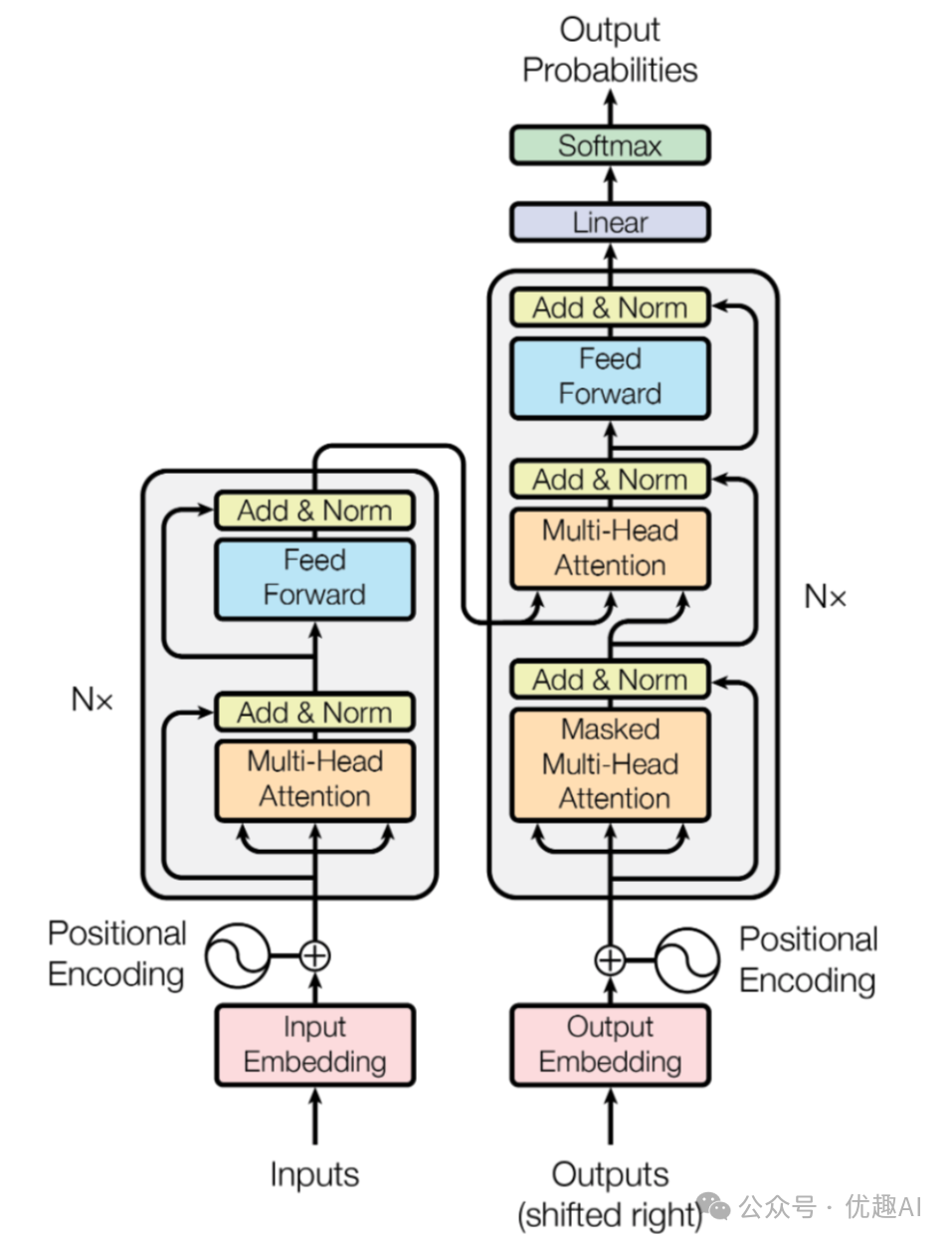
左边Encoder,右边Decoder
-
编码器(理解部门):负责深度阅读输入序列(如一句中文)。它由N个相同的层堆叠而成,每层都包含:
-
多头自注意力机制:开会讨论,理解内部关系
-
前馈神经网络:深度加工信息
-
残差连接和层归一化:稳定训练过程,避免梯度消失
-
-
解码器(生成部门):负责根据编码器的理解,生成目标序列(如一句英文)。它的结构类似编码器,但有三个关键区别:
-
掩码自注意力:在生成当前词时,只能看到已生成的词(上文),不知道未来的词,防止作弊
-
编码器-解码器注意力:这里的Query来自解码器,Key和Value来自编码器输出,确保生成时关注输入的相关部分
-
同样包含前馈网络和残差连接
-
五、代码实战:自注意力机制完整演示
让我们用一个真实的例子来演示自注意力机制。假设我们要分析句子:"猫吃鱼"。
import math
import torch
import torch.nn.functional as F
def complete_self_attention_explanation():
# 1. 定义输入数据
print("\n1. 定义词向量(3维:[动物性, 动作性, 食物性])")
cat = torch.tensor([0.9, 0.1, 0.0]) # 猫:高动物性
eat = torch.tensor([0.1, 0.9, 0.0]) # 吃:高动作性
fish = torch.tensor([0.3, 0.1, 0.8]) # 鱼:高食物性
words = ['猫', '吃', '鱼']
X = torch.stack([cat, eat, fish])
for i, word in enumerate(words):
vec = X[i].tolist()
print(f" '{word}': {vec}")
# 2. 生成Q, K, V
print("\n2. 生成Q, K, V矩阵")
print(" 简化演示:Q = K = V = 输入词向量")
Q = K = V = X
print(f" Q矩阵形状: {Q.shape}, 内容:")
print(f" {Q}")
# 3. 计算注意力分数(点积)
print("\n3. 计算注意力分数(点积相似度)")
print(" 公式: 分数(i,j) = Q[i] · K[j]")
# 详细展示一个点积计算
print(f"\n 点积计算示例 - '猫'和'吃'的相似度:")
print(f" 猫向量: {cat.tolist()}")
print(f" 吃向量: {eat.tolist()}")
dot_example = torch.dot(cat, eat)
calculation = " + ".join([f"({cat[i]:.1f}×{eat[i]:.1f})" for i in range(3)])
print(f" 点积 = {calculation} = {dot_example:.3f}")
print(f" 这个值表示'猫'和'吃'的语义相似度")
# 计算完整分数矩阵
raw_scores = torch.matmul(Q, K.t())
print(f"\n 完整的原始分数矩阵:")
print(f" {raw_scores}")
# 4. 缩放处理
print("\n4. 缩放分数(防止梯度消失)")
d_k = Q.size(-1) # 向量维度
scale_factor = math.sqrt(d_k)
scaled_scores = raw_scores / scale_factor
print(f" 除以 √{d_k} = {scale_factor:.3f}")
print(f" 缩放后矩阵:")
print(f" {scaled_scores}")
# 5. Softmax计算(详细过程)
print("\n5. Softmax计算(转换为注意力权重)")
print(" 公式: softmax(z_i) = exp(z_i) / Σ(exp(z_j))")
print(" 目的: 将分数转换为概率分布,权重和为1")
attn_weights = F.softmax(scaled_scores, dim=-1)
# 详细演示第一行的Softmax计算
print(f"\n '{words[0]}'行的详细Softmax计算:")
row_scores = scaled_scores[0]
print(f" 原始分数: {row_scores.tolist()}")
exp_scores = torch.exp(row_scores)
sum_exp = torch.sum(exp_scores)
print(f" 指数计算:")
for i, score in enumerate(row_scores):
print(f" exp({score:.4f}) = {exp_scores[i]:.4f}")
print(f" 指数和 = {sum_exp:.4f}")
print(f" Softmax结果:")
for i, (exp_val, score) in enumerate(zip(exp_scores, row_scores)):
softmax_val = exp_val / sum_exp
print(f" {exp_val:.4f} / {sum_exp:.4f} = {softmax_val:.4f}")
print(f"\n 最终注意力权重矩阵:")
print(f" {attn_weights}")
# 6. 加权求和(最关键的步骤)
print("\n6. 加权求和得到新词表示")
print(" 公式: 新向量[i] = Σ(注意力权重[i,j] × V[j])")
print(" 意义: 每个词的新表示是所有词信息的加权融合")
new_representation = torch.matmul(attn_weights, V)
# 详细演示第一个词(猫)的加权求和计算
print(f"\n '{words[0]}'的详细加权求和计算:")
cat_weights = attn_weights[0] # 猫的注意力权重
print(f" 猫的注意力权重: {cat_weights.tolist()}")
print(f" 值向量矩阵V:")
print(f" {V}")
# 手动计算每个维度
manual_result = torch.zeros(3)
for dim in range(3):
print(f"\n 第{dim + 1}维度计算:")
dim_sum = 0
for j in range(3):
weight = cat_weights[j]
value = V[j, dim]
contribution = weight * value
dim_sum += contribution
print(f" {weight:.3f} × {value:.1f} (来自'{words[j]}') = {contribution:.3f}")
manual_result[dim] = dim_sum
print(f" 维度{dim + 1}总和 = {dim_sum:.3f}")
print(f"\n 手动计算结果: {manual_result.tolist()}")
# 验证矩阵乘法结果
matrix_result = torch.matmul(attn_weights[0:1], V)
print(f" 矩阵乘法结果: {matrix_result[0].tolist()}")
print(f" 结果是否一致: {torch.allclose(manual_result, matrix_result[0])}")
# 显示所有词的新旧向量对比
print(f"\n7. 新旧向量对比(信息融合效果):")
for i, word in enumerate(words):
old_vec = X[i].tolist()
new_vec = new_representation[i].tolist()
print(f" '{word}':")
print(f" 旧向量: {[f'{x:.3f}' for x in old_vec]}")
print(f" 新向量: {[f'{x:.3f}' for x in new_vec]}")
# 分析变化
changes = []
for dim in range(3):
change = new_vec[dim] - old_vec[dim]
if abs(change) > 0.01:
change_type = "增加" if change > 0 else "减少"
dim_name = ["动物性", "动作性", "食物性"][dim]
changes.append(f"{dim_name}{change_type}{abs(change):.3f}")
if changes:
print(f" 主要变化: {', '.join(changes)}")
return attn_weights, new_representation
attn_weights, new_repr = complete_self_attention_explanation()
代码执行输出:
1. 定义词向量(3维:[动物性, 动作性, 食物性])
'猫': [0.8999999761581421, 0.10000000149011612, 0.0]
'吃': [0.10000000149011612, 0.8999999761581421, 0.0]
'鱼': [0.30000001192092896, 0.10000000149011612, 0.800000011920929]
2. 生成Q, K, V矩阵
简化演示:Q = K = V = 输入词向量
Q矩阵形状: torch.Size([3, 3]), 内容:
tensor([[0.9000, 0.1000, 0.0000],
[0.1000, 0.9000, 0.0000],
[0.3000, 0.1000, 0.8000]])
3. 计算注意力分数(点积相似度)
公式: 分数(i,j) = Q[i] · K[j]
点积计算示例 - '猫'和'吃'的相似度:
猫向量: [0.8999999761581421, 0.10000000149011612, 0.0]
吃向量: [0.10000000149011612, 0.8999999761581421, 0.0]
点积 = (0.9×0.1) + (0.1×0.9) + (0.0×0.0) = 0.180
这个值表示'猫'和'吃'的语义相似度
完整的原始分数矩阵:
tensor([[0.8200, 0.1800, 0.2800],
[0.1800, 0.8200, 0.1200],
[0.2800, 0.1200, 0.7400]])
4. 缩放分数(防止梯度消失)
除以 √3 = 1.732
缩放后矩阵:
tensor([[0.4734, 0.1039, 0.1617],
[0.1039, 0.4734, 0.0693],
[0.1617, 0.0693, 0.4272]])
5. Softmax计算(转换为注意力权重)
公式: softmax(z_i) = exp(z_i) / Σ(exp(z_j))
目的: 将分数转换为概率分布,权重和为1
'猫'行的详细Softmax计算:
原始分数: [0.4734271764755249, 0.10392304509878159, 0.16165807843208313]
指数计算:
exp(0.4734) = 1.6055
exp(0.1039) = 1.1095
exp(0.1617) = 1.1755
指数和 = 3.8905
Softmax结果:
1.6055 / 3.8905 = 0.4127
1.1095 / 3.8905 = 0.2852
1.1755 / 3.8905 = 0.3021
最终注意力权重矩阵:
tensor([[0.4127, 0.2852, 0.3021],
[0.2930, 0.4240, 0.2830],
[0.3110, 0.2835, 0.4055]])
6. 加权求和得到新词表示
公式: 新向量[i] = Σ(注意力权重[i,j] × V[j])
意义: 每个词的新表示是所有词信息的加权融合
'猫'的详细加权求和计算:
猫的注意力权重: [0.412672758102417, 0.28518861532211304, 0.3021385967731476]
值向量矩阵V:
tensor([[0.9000, 0.1000, 0.0000],
[0.1000, 0.9000, 0.0000],
[0.3000, 0.1000, 0.8000]])
第1维度计算:
0.413 × 0.9 (来自'猫') = 0.371
0.285 × 0.1 (来自'吃') = 0.029
0.302 × 0.3 (来自'鱼') = 0.091
维度1总和 = 0.491
第2维度计算:
0.413 × 0.1 (来自'猫') = 0.041
0.285 × 0.9 (来自'吃') = 0.257
0.302 × 0.1 (来自'鱼') = 0.030
维度2总和 = 0.328
第3维度计算:
0.413 × 0.0 (来自'猫') = 0.000
0.285 × 0.0 (来自'吃') = 0.000
0.302 × 0.8 (来自'鱼') = 0.242
维度3总和 = 0.242
手动计算结果: [0.4905659258365631, 0.3281508982181549, 0.24171088635921478]
矩阵乘法结果: [0.4905659258365631, 0.3281508982181549, 0.24171088635921478]
结果是否一致: True
7. 新旧向量对比(信息融合效果):
'猫':
旧向量: ['0.900', '0.100', '0.000']
新向量: ['0.491', '0.328', '0.242']
主要变化: 动物性减少0.409, 动作性增加0.228, 食物性增加0.242
'吃':
旧向量: ['0.100', '0.900', '0.000']
新向量: ['0.391', '0.439', '0.226']
主要变化: 动物性增加0.291, 动作性减少0.461, 食物性增加0.226
'鱼':
旧向量: ['0.300', '0.100', '0.800']
新向量: ['0.430', '0.327', '0.324']
主要变化: 动物性增加0.130, 动作性增加0.227, 食物性减少0.476六、新旧向量变化的深层解读
1. 动物性减少0.409:从类别识别到角色理解
原始状态:猫的动物性特征显著(0.9),这反映了其作为动物的本质属性。
语境化转变:在"猫吃鱼"的具体语境中,模型认识到猫不仅仅是动物类别的一员,更是动作的执行者。这种特征权重的重新分配体现了模型从静态分类向动态角色理解的进化。
认知升级:类似于人类理解语言时的思维过程——我们不会将"猫"简单归类为动物,而是根据上下文理解其具体角色和功能。
2. 动作性增加0.228:从静态概念到动态参与者
语义丰富化:通过关注"吃"这个动作性极强的词,猫的表示中融入了动态特征。这种转变使得模型能够理解词在句子中的功能性角色,而不仅仅是其词典定义。
关系建模:动作性的增加反映了模型对主谓关系的捕捉,展现出对语法结构和语义关系的深层理解能力。
3. 食物性增加0.242:从孤立词义到关系网络
关联学习:尽管猫本身不是食物,但与食物性强的"鱼"建立关联后,猫的表示中包含了这种关系信息。这体现了模型学习词间关系的强大能力。
语义网络构建:这种变化表明模型不再将词视为孤立实体,而是将其置于复杂的语义网络中,每个词的 meaning 都受到其关联词的影响。
七、自注意力机制核心技术框架
六步核心流程
-
词向量表示:将离散符号转换为连续向量空间中的表示
-
QKV生成:创建查询、键、值三个投影,实现多视角分析
-
点积计算:定量衡量词与词之间的语义相似度
-
缩放处理:确保数值稳定性,优化训练过程
-
Softmax转换:将相似度分数转化为概率分布的注意力权重
-
加权求和:生成融合上下文信息的词表示
三大技术优势
-
并行计算架构:打破序列处理的瓶颈,大幅提升计算效率
-
全局信息整合:每个位置都能直接访问序列中的所有信息
-
长距离依赖建模:有效解决传统RNN中的梯度消失问题
八、总结与展望
Transformer的成功源于自注意力机制的创新,它使模型能够:
-
理解复杂的语言结构和长距离依赖关系
-
在各种NLP任务中实现突破性表现
-
为多模态学习和通用AI奠定基础
自注意力机制证明:真正的智能不在于复杂规则,而在于建立元素间动态关系的能力。这一洞见不仅推动了自然语言处理的发展,更为我们理解智能的本质提供了重要启示。
理解Transformer,不仅让我们掌握当今最先进的AI技术,更让我们看到AI未来发展的无限可能。这种基于全局关联的思维方式正在推动AI从狭隘的任务专用型向通用的情境理解型系统演进,为真正意义上的机器理解语言开辟了道路。
本文完!!
源代码如需获取,请关注公众号,发送消息ufunai-transformer获取,扫一扫即可获取!
创作不易,码字更不易,如果觉得这篇文章对你有帮助,记得点个关注、在看或收藏,给作者一点鼓励吧~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











