






目录
1.程序功能描述
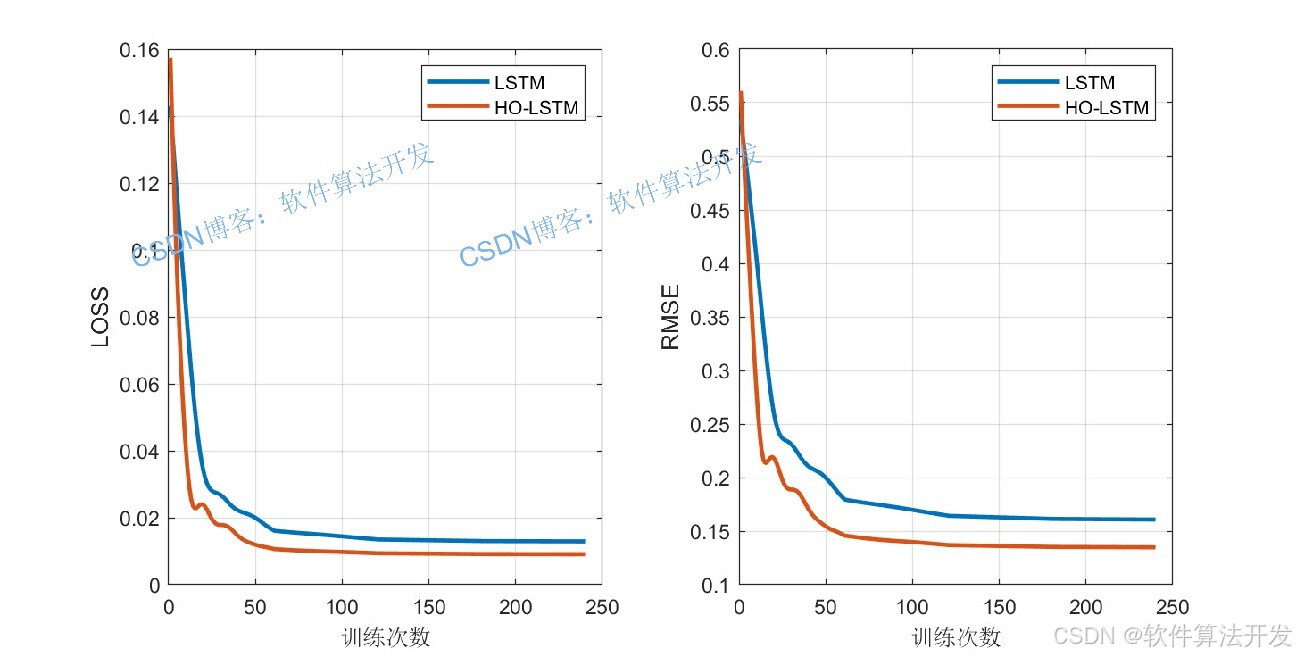
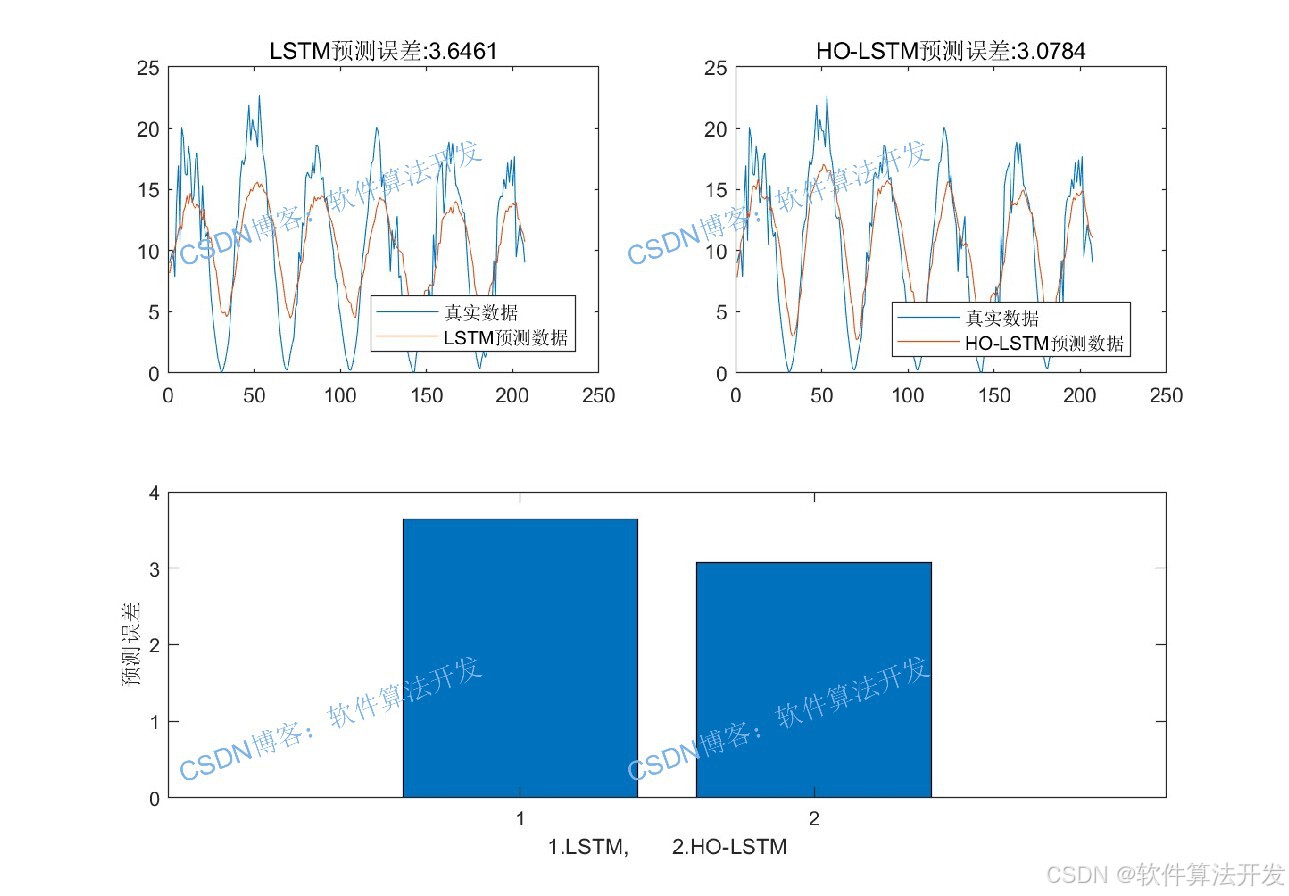
河马优化算法(Hippopotamus Optimization Algorithm, HO)是2022年提出的一种新型启发式优化算法,模拟河马在自然界中的生存行为(如水域选择、领地划分、觅食策略),具有收敛速度快、全局搜索能力强、不易陷入局部最优的特点。将HO算法与LSTM结合,构建HO-LSTM模型,核心思路是:以LSTM的预测误差最小化为目标函数,通过HO算法自适应优化LSTM的网络层数量,同时协同优化学习率、隐藏层神经元数等关键参数,最终得到性能最优的时间序列预测模型。HO-LSTM算法的核心优势在于:
避免人工调参的主观性:传统LSTM层数量需依赖经验试错,HO算法可自动搜索最优层数;
平衡模型复杂度与泛化能力:通过优化层,在拟合复杂特征与抑制过拟合间找到最优解;
提升预测精度:结合HO的全局优化能力与LSTM的时序特征捕捉能力,降低预测误差。
2.测试软件版本以及运行结果展示
MATLAB2022A/MATLAB2024B版本运行
3.部分程序
% 定义全局变量,用于存储训练和测试数据及相关参数
global T_train; % 训练目标数据(原始尺度)
global T_test; % 测试目标数据(原始尺度)
global Pxtrain; % 训练输入数据
global Txtrain; % 训练目标数据(归一化后)
global Pxtest; % 测试输入数据
global Txtest; % 测试目标数据(归一化后)
global Norm_I; % 输入数据归一化参数(用于反归一化)
global Norm_O; % 输出数据归一化参数(用于反归一化)
global indim; % 输入数据维度
global outdim; % 输出数据维度
% 加载数据文件data.mat,该文件包含原始数据集
load data.mat
% 调用数据处理函数,对原始数据进行预处理
% 包括划分训练集和测试集、数据归一化等操作
[T_train,T_test,Pxtrain,Txtrain,Pxtest,Txtest,Norm_I,Norm_O,indim,outdim]=func_process(dat);
% 定义优化算法的参数范围
low = 10; % 搜索空间下界(优化参数最小值)
high = 50; % 搜索空间上界(优化参数最大值)
dim = 1; % 优化维度(待优化参数的数量)
Tmax = 20; % 最大迭代次数
Npop = 20; % 种群大小(每次迭代的个体数量)
1174.算法理论概述
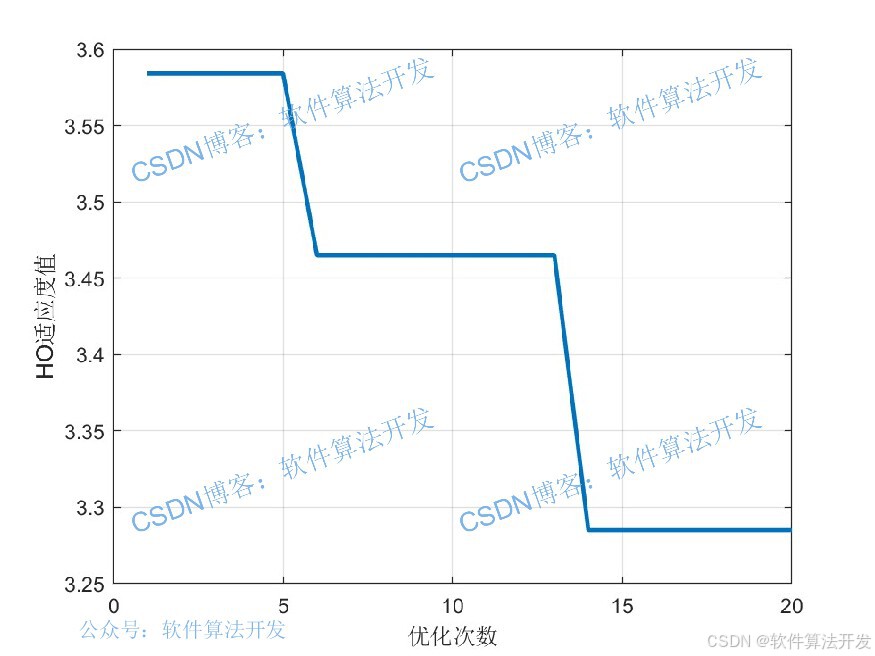
HO算法模拟河马的三大核心行为:
水域选择(全局搜索):河马倾向于选择水源充足、食物丰富的区域,对应算法中通过随机生成候选解探索搜索空间;
领地划分(局部开发):河马会划分领地,在领地内精细觅食,对应算法中基于最优解邻域搜索,提升局部收敛精度;
应激反应(跳出局部最优):当领地受到威胁时,河马会迁移至新区域,对应算法中通过随机扰动避免陷入局部最优。
对每个初始个体Li(0) ,构建对应的LSTM模型,训练后计算其在验证集上的预测误差,将误差作为适应度函数值(适应度越大,对应Li 越优):
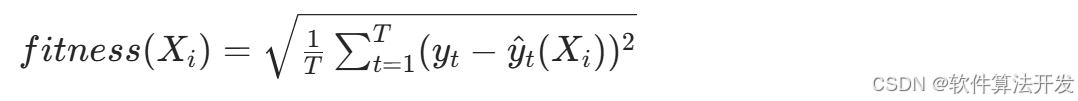
基于HO优化得到的最优参数Xbest∗,构建并训练最终的LSTM模型。
5.完整程序
VVV
关注后手机上输入程序码:117



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











