



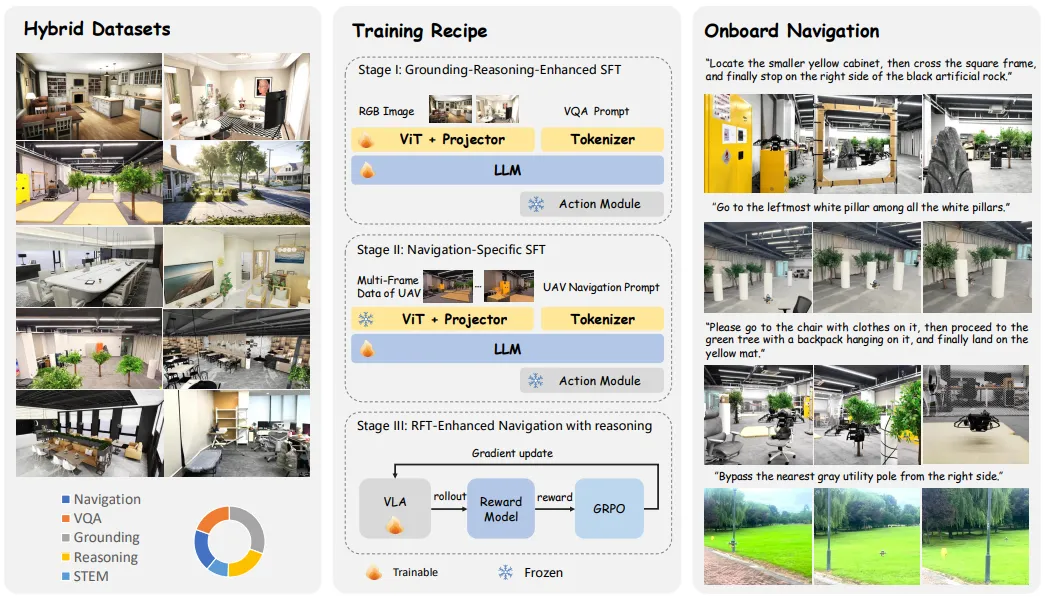
「 告别“看得见躲不开”
解决机载大模型反应迟钝难题」
在复杂环境里飞无人机,最怕的不是“看不见”,而是“看见了也来不及反应”。
狭窄通道、树枝电线、光照突变,再加上一句人类式指令,比如“绕过去再靠近目标”,对机载系统来说就是一场连环考。
很多视觉语言动作模型在实验室里很聪明,一上机就会遇到四个现实拦路虎:训练数据视角不对、只看单帧缺少时序推理、生成式动作带随机性可能撞墙、算力又被机载平台卡得死死的。
来自浙大和微分智飞的VLA-AN 给出了一个明确的新思路:别只追“更大更强”,而是把数据、训练方式、动作安全和机载加速一起做成一套闭环,让无人机能在复杂环境里更稳、更快地根据飞手的自然语言指令执行飞行任务。


VLA-AN 的出发点有点像“把纸上谈兵变成野外生存”。
作者先承认一个事实:很多 VLA 方法的训练数据分布和无人机第一人称高速视角差得很远,于是他们先补上“看世界的方式”。报告里把数据集作为核心组件之一,强调其包含大量轨迹与多模态样本,并结合合成与真实数据来覆盖复杂环境中的视觉变化与运动状态。
接着,他们把整套系统拆成四块再扣回一个目标:让模型既能理解指令,又能在机载算力下稳定输出可执行动作。
从结构上看,系统用视觉编码器把图像变成特征,经投影对齐到语言模型,再由动作模块生成包含 3D 航点、偏航等在内的动作表达,还配了任务重规划与完成判断的逻辑。也就是说,它不是只做“回答”,而是在做“持续导航”。

数据先把“视角与动态”补齐
作者把“数据分布不匹配”列为首要问题,并用大规模轨迹与多模态样本去对冲这个落差。
他们强调数据来源包含合成与真实两类,目标是让模型在遮挡、远近变化、复杂背景等情况下仍能学到可迁移的导航线索。
在消融实验里,作者也专门对“不同数据类型”进行对比,分别在 seen/unseen 场景下观察性能变化,用结果支撑“数据覆盖面”对泛化的重要性。
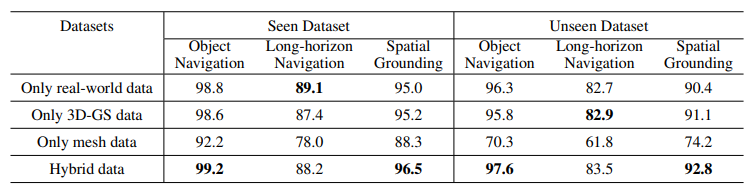
图1|不同导航训练数据的消融实验:比较使用不同训练导航数据集时,模型在评测任务上的成功率变化。它对应论文前面强调的“数据域差距”问题,用来说明数据选择/组成会如何影响 seen/unseen 等场景下的泛化能力
三阶段训练,把“会理解”训练成“会执行”
作者把训练分成三段,并把它作为核心贡献之一。直观理解是:先打好基础能力,再强化导航相关的决策与稳定输出,最后把系统拉到更贴近部署的状态。
这件事的价值在于,它把“语言理解”与“动作可落地”之间那段最容易掉链子的距离缩短了。
从训练阶段的消融实验来看,用阶段性对比展示每一段训练对最终成功率的增益。
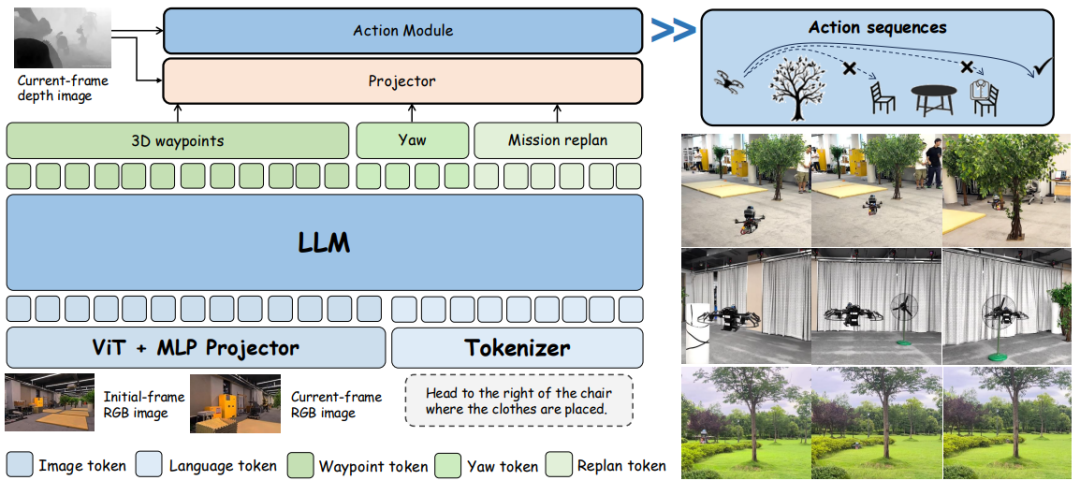
图2|VLA-AN 的模型架构面向“边飞边想”的导航推理任务:它既能处理单帧图像,也能处理多帧图像输入。整体由四块组成:Vision Transformer(视觉Transformer)负责把图像编码成视觉特征;MLP projector(多层感知机投影器)把视觉特征映射到与大语言模型对齐的隐空间;LLM(大语言模型)负责理解文本指令并进行推理;最后由 projector + action module(动作生成模块)对“想要执行的指令”做一致性检查,并生成可执行的动作序列
鲁棒动作模块,专门盯住“别撞”这件小事
作者明确指出扩散(Diffusion)、流匹配(Flow Matching)这类生成式动作会引入随机噪声,在狭窄空间更容易出碰撞风险。VLA-AN 没有把安全寄托在“采样运气”上,而是加入一个低时延的动作修正机制。
具体做法是利用深度信息检测潜在相交,并提取局部障碍来形成即时的“排斥式”修正,从而把轨迹往安全方向推回去。
这让系统在复杂环境里更像“能及时收手的驾驶员”,而不是一味的执行飞行动作,等危险到了眼前再依靠“反应”避障。

在仿真任务对比中,作者把 VLA-AN 和 OpenVLA、π0、Groot N1.5 放到同一张图里,覆盖 8 类任务类型,用成功率做对比。
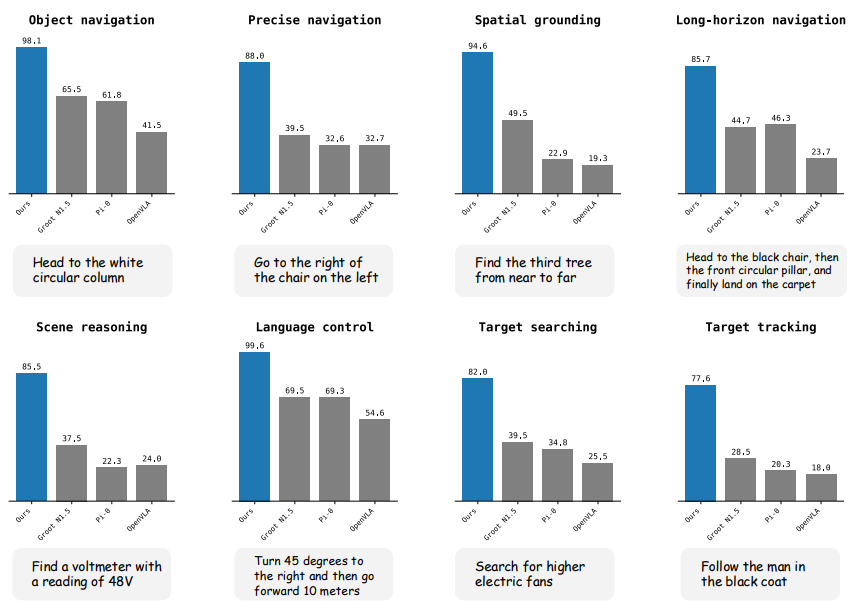
图3|多类导航任务的基准对比结果:图中用柱状图给出了不同方法在各类任务上的成功率,对比对象包括 OpenVLA、π0、Groot N1.5,以及作者的方法 VLA-AN。这里的重点是看“同一批任务上谁更稳”,以及 VLA-AN 在不同任务类型上的整体趋势与优势分布
整体趋势是:VLA-AN 在多类任务上表现更稳,并在单任务上报告了最高 98.1% 的成功率,同时也给出了平均成功率超过 90% 的描述。

图4|仿真环境中的语言+视觉导航测试:展示无人机在模拟场景里如何结合图像观测与自然语言指令完成导航任务。更像是“过程回放图”,用于直观看到模型在不同障碍、路径与目标条件下的执行效果
VLA_AN更“像系统论文”的部分在于:它不只给成功率,还把部署代价摊开讲。下图给出 Orin NX 上不同规模模型(含 AWQ 量化)的推理速度与计算量指标,直接回答“机载能不能跑”。

图5|不同模型在机载平台上的推理效率对比。它主要想说明:在算力受限的机载条件下,VLA-AN 通过模型规模选择与量化/加速等手段,把推理速度压到可实时运行的范围
真实平台与任务展示如下图所示,无人机能够在真实的复杂环境中执行人类给出的不同自然语言指令,并快速高效的自主完成任务。

图6|真实场景中的语言+视觉导航实验:展示无人机在真实环境里根据自然语言指令执行导航的过程与结果。与仿真图不同,这里更强调复杂光照、真实障碍与不可控因素下的表现,用来验证系统“从仿真到现实”的可用性

VLA-AN 这份报告传递的信号很清晰:
真正能落地的 VLA,不只是把模型做大,而是把“数据、训练、动作安全、机载加速”拧成一股绳。它把语言理解放进持续导航过程里,又把避碰这种工程刚需变成模块化能力,同时还用 Orin NX 的指标把部署问题摆到台面上。
论文标题:VLA-AN: An Efficient and OnboardVision-Language-Action Framework for Aerial Navigation in Complex Environments
论文作者:Yuze Wu, Mo Zhu, Xingxing Li, Yuheng Du, Yuxin Fan,Wenjun Li, Xin Zhou, Fei Gao
论文链接:https://arxiv.org/pdf/2512.15258

















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









