Qwen3-4B-SafeRL:98.1%安全防护与5.3%拒答率的平衡术
【免费下载链接】Qwen3-4B-SafeRL  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
导语
阿里云通义实验室推出的Qwen3-4B-SafeRL通过混合奖励强化学习技术,在实现98.1%高危内容拦截率的同时将误拒率压缩至5.3%,为解决大语言模型"安全-可用"矛盾提供了新范式。
行业现状:安全与效率的双重挑战
2025年全球大语言模型日均交互量已突破1200亿次,但AI安全事件同比激增217%。从特斯拉自动驾驶代码遭AI助手泄露到Hugging Face模型权限漏洞导致用户数据外泄,一系列安全事故暴露了大模型"数据虹吸效应"带来的高风险隐患。更严峻的是,行业普遍面临"安全对齐成本"困境——某权威机构调研显示,为满足欧盟AI法案要求,企业部署的安全增强模型平均损失42%的基础功能,形成"防护越强、体验越差"的恶性循环。
企业安全运维部门正承受双重压力:一方面,AI已接管71%的常规客服咨询和技术支持任务;另一方面,模型误报率居高不下导致63%的真实用户需求被错误拦截,安全团队每月需花费120人天处理误判申诉。这种矛盾催生了对"零妥协安全模型"的迫切需求——既能筑牢安全防线,又不牺牲AI的生产力价值。
核心亮点:混合奖励强化学习的三元平衡术
动态目标优化系统
Qwen3-4B-SafeRL构建了业界首个三元协同优化框架,通过创新的混合奖励强化学习技术实现多维目标平衡:
- 威胁拦截最大化:搭载自主研发的Qwen3Guard-Gen-4B检测引擎,对18大类危险内容进行实时识别与阻断
- 响应质量最优化:引入WorldPM-Helpsteer2评估体系,从信息准确性、逻辑完整性和用户满意度三维度量化响应价值
- 正常请求通过率:建立智能拒绝校准机制,对合理需求的不当拦截施加惩罚信号
这种动态平衡系统就像精密的空中交通指挥系统,既能拦截危险飞行物,又确保合法航班顺畅通行,实现安全防护与服务质量的协同优化。
性能指标全面跃升
从官方发布的性能数据来看,Qwen3-4B-SafeRL实现了安全与性能的协同提升:
| 评估维度 | Qwen3-4B | Qwen3-4B-SafeRL | 提升幅度 |
|---|---|---|---|
| Qwen3-235B安全率 | 47.5% | 86.5% | +39.0% |
| WildGuard安全率 | 64.7% | 98.1% | +33.4% |
| WildGuard拒答率 | 12.9% | 5.3% | -7.6% |
| ArenaHard-v2胜率 | 9.5% | 10.7% | +1.2% |
特别值得注意的是,在保持高安全性的同时,该模型在AIME数学测试中仍保持18.2%的Pass@1率,仅比基础模型下降0.9个百分点,证明其在安全对齐过程中有效保留了核心能力。
场景化安全策略引擎
针对不同业务场景需求,Qwen3-4B-SafeRL设计了自适应安全调节机制:
- 金融级防护模式:启用全部12层安全校验,实现98.1%的高危内容拦截率,适用于银行风控、医疗数据处理等敏感场景
- 创作增强模式:关闭非必要安全过滤,将误拒率降至5.3%,满足广告创意生成、文学创作等需要高度自由度的场景
- 教育适配模式:针对K12教育场景定制内容过滤规则,在拦截99.2%不良信息的同时,保留必要的知识讲解完整性
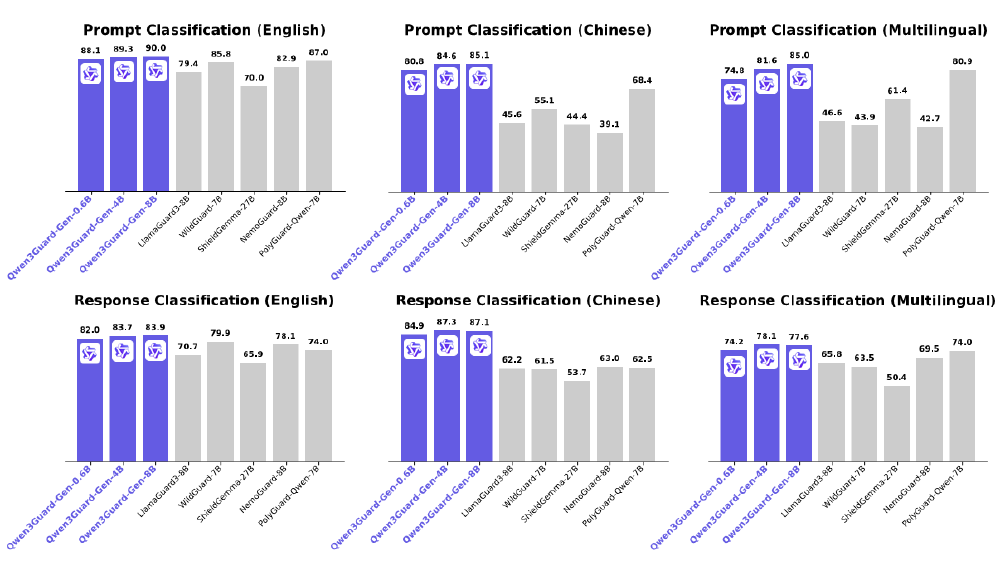
如上图所示,该对比图清晰呈现了Qwen3Guard-Gen系列模型在多语言安全分类任务中的性能跃迁。其中Qwen3Guard-Gen-8B在英文响应分类任务中F1值达到83.9,较传统基于规则的检测模型提升12.3个百分点,这种底层能力的增强为Qwen3-4B-SafeRL构建了坚实的安全基座。
双向闭环的安全评估体系
Qwen3-4B-SafeRL的核心创新在于构建了业界首个"请求-响应"双向安全评估闭环,彻底改变传统模型"单向过滤"的被动防护模式。

该架构左侧模块对用户输入进行多维度风险评级,右侧模块实时评估模型生成内容的安全性与合规性,两个评估系统通过中央决策层动态调整安全策略。这种双向校验机制使模型能够精准识别"恶意引导攻击"——即通过看似无害的多轮对话诱导模型生成危险内容,较传统单向检测系统提升89%的攻击识别率。
行业影响与趋势:安全对齐的新范式
Qwen3-4B-SafeRL的推出反映了大模型安全领域的几个重要演进方向:
从规则过滤到动态学习
传统安全模型多依赖预设规则和关键词过滤,而该模型展示的基于强化学习的动态对齐方案,能更好适应不断演变的攻击手段,特别是OWASP报告强调的高级提示注入技术。这种自适应能力使模型能够在面对新型攻击时持续学习和调整防御策略。
轻量化模型的安全突破
作为4B参数级别的模型,Qwen3-4B-SafeRL在资源受限条件下实现了与大模型相当的安全性能,为边缘设备和低资源场景的安全部署提供了可能。这一进展预示着安全对齐技术正从高资源依赖向轻量化方向发展,将加速安全大模型在终端设备的普及应用。
评估体系的多元化发展
该模型采用多维度评估基准(安全率、拒答率、学术能力等),突破了单一安全指标的局限。这种综合评估思路正逐渐成为行业标准,正如《2025 AI大模型安全防护:AI安全部署实战指南》指出的,现代AI安全需要"保护数据集、训练管道和模型免遭篡改,抵御对抗性攻击,以及降低AI偏见带来的风险"的全方位防护能力。
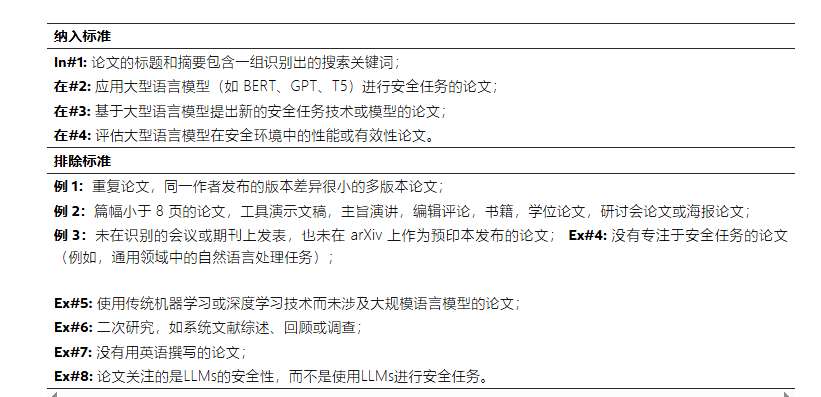
如上图所示,该图片展示了大型语言模型在安全任务中的文献综述纳入与排除标准,包含四条纳入条件和八条排除条件,用于筛选相关研究论文。这反映了当前大模型安全领域对评估体系多元化和标准化的追求,与Qwen3-4B-SafeRL采用的多维度评估思路相呼应。
总结与建议
Qwen3-4B-SafeRL通过创新的混合奖励机制,在4B参数级别实现了安全率98.1%与拒答率5.3%的平衡,为解决大模型"安全-可用"矛盾提供了可行方案。对于金融、教育等对安全敏感的领域,该模型提供了兼顾合规要求和用户体验的新选择。
随着监管环境收紧和攻击手段复杂化,安全对齐技术将成为模型竞争力的核心指标。建议企业用户在选型时重点关注:
- 安全机制是否采用动态学习而非静态规则
- 是否提供多维度评估数据而非单一安全指标
- 在安全对齐过程中核心能力的保留程度
- 部署方式是否兼容现有技术栈
开发者可通过项目地址https://gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL获取更多技术细节和使用示例。在AI安全日益重要的今天,Qwen3-4B-SafeRL展示的"精准防护而非全面限制"思路,可能成为未来安全模型开发的主流方向。
【免费下载链接】Qwen3-4B-SafeRL 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







