




3D表征的“半生”
——复盘:50年技术发展史
机器人如何理解三维世界?
它需要的是毫米级的精确坐标,还是带有语义的物体概念?它应该构建一个可测量的空间地图,还是一个能推理和规划的认知模型?
这并非一个单纯的技术选择题,而是贯穿机器人感知领域50年的根本张力。上海交通大学等团队的最新综述,系统梳理了这段演进历史:
从只能判断 “有无障碍” 的 2D 网格;
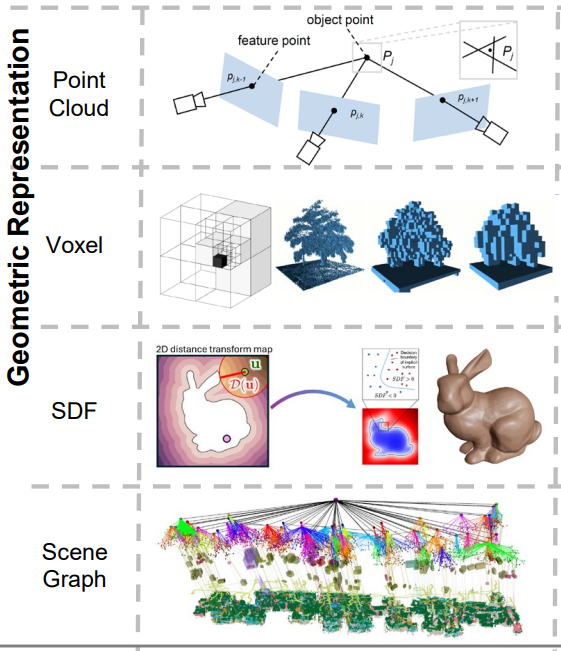
到用点云、体素、SDF 勾勒轮廓的初代 3D 表征
再到能 “脑补” 遮挡物、渲染照片级画面的 NeRF、3DGS;
最后到能听懂语言、零样本决策的 3D 基础模型。
每一种表征的进化,都是一次对“机器人应如何看世界”的重新定义。然而,技术的迭代并未终结一个核心争论:
究竟什么才是机器人真正需要内置的“世界观”?
站在这个十字路口,我们需要的不仅是对历史的回顾,更是对前路的冷静审视。
这篇文章将完整梳理这场贯穿半个世纪的“视觉进化”背后,那些未被充分讨论的权衡、代价与真正关键的技术抉择。

追本溯源,3D 场景表征不是凭空发明的,每一代技术都是为了解决当时机器人的 “痛点”,所以理解当下技术,得先知道过去的机器人到底 “缺什么”。
上世纪 70~90 年代,机器人普遍使用的是 2D 栅格地图(grid map)
在一个平面上划分成无数小格子,每个格子只有两种状态 —— 能走 or 不能走。
就像扫地机器人一样,“撞一下再记住”——
缺乏细节、没有语义,只能描述“此处有墙”。
▲图2|用于机器人导航及路径规划的传统2D栅格地图。
如图所示,地图将机器人周围的环境按照一定分辨率离散为一个个小的栅格,每个格子只有两种状态(注:后续研究中栅格的状态信息也逐渐丰富,但我们在此只介绍最基础的类型),即“占据”与“未占据”。其中占据即表明该栅格区域存在障碍,无法通行。
此类地图一般由机器人的SLAM系统得到,能够十分直观的反映机器人周围的环境状态,因此在相当长的时间里作为机器人理解三维空间的底层表征。
进入2000年左右,激光雷达和深度相机逐渐普及,第一代真正意义上的3D表征出现了
以下方法共同构成了早期 3D 场景表征的核心框架:
-
Point Cloud(点云):通过离散的三维点集合直接刻画物体或场景表面,是传感器数据的直接映射;
-
Voxel(体素):将三维空间离散为规则的小立方体网格,通过网格单元存储密度、特征等信息,实现结构化的场景建模;
-
Mesh(网格):利用三角面片拼接形成连续的物体表面,能精准还原几何形态;
-
SDF(带符号距离场):采用隐式数学函数描述空间,通过输出点到物体表面的距离及内外符号,实现光滑且连续的几何表征。
在很长一段时间里,这套体系支撑了几乎所有的机器人任务——SLAM、导航、避障、自动驾驶、机械臂。
但随着机器人任务越来越接近真实世界,“几何正确”已经不够了。
例如,一个家庭机器人面对厨房,会遇到一连串只有人类才能理解的问题:
“锅盖在哪一层?”
“椅子挡住了冰箱门吗?”
“桌子下面是不是藏着一只猫?”
这些问题不是几何关系能完全描述的,它需要 “理解”。
而机器人的下一次飞跃,就从这里开始。
近10年,3D 表征变得比以往更重要
过去十年,人工智能在视觉、语言、推理上的突破,让机器人第一次有机会接近“通用智能”。
但当我们尝试让这些能力落地到实体机器人身上时,一个现实问题横在面前:
语言模型很强,但机器人不生活在文本里,而是在真实的三维世界里。
机器人要完成任何任务 —— 找到杯子、绕过桌子、穿过门、搬起箱子 —— 都必须依赖一个能够支持:几何、语义、推理的世界表示方式。
这件事情看似分散,本质上却完全依赖同一个底层——
机器人如何表示三维世界?
可以这么理解:3D 场景表征是机器人能力的“共同基础”。
基础越强,上层能力越强;基础越弱,越难实现真正的具身智能。
因此,从技术系统到产业应用,大家都在问同一个问题:
有没有一种更统一、更强大的 3D 表征,可以给机器人提供类似“认知地图”的能力?
——答案,藏在最近三年最火的三项技术中。
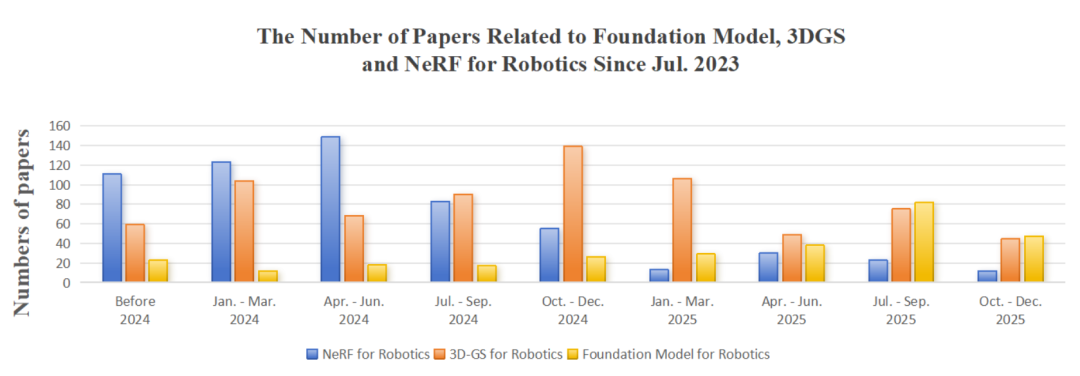
▲图3|三维表征研究热度变化。
从 NeRF 到 3DGS,再到大模型。

点云:一切三维技术的起点
点云之所以几十年不过时,是因为它有三个优点:
-
足够准确、足够稳定、适合 SLAM/自动驾驶。
但问题也明显:
-
太稀疏、缺少连续表面、看不懂“这是桌子还是箱子”。
点云就像机器人世界的“素描”:真实,但信息有限。
NeRF:让机器人第一次拥有“连续的世界”
NeRF(Neural Radiance Field)最大的“改变”不是画得好,而是:
它让机器人第一次可以“想象”一个连续、真实的三维世界。
它的优势是:
-
可以从任意角度生成真实画面;可以补全机器人看不见的地方;表示的是“连续空间”,不是离散点。
这对具身智能来说非常关键——
虽然NeRF 没让机器人拥有 “意识”,但让它第一次能像人一样,在 “脑子里” 构建出一个完整、连贯且可推演的环境模型。
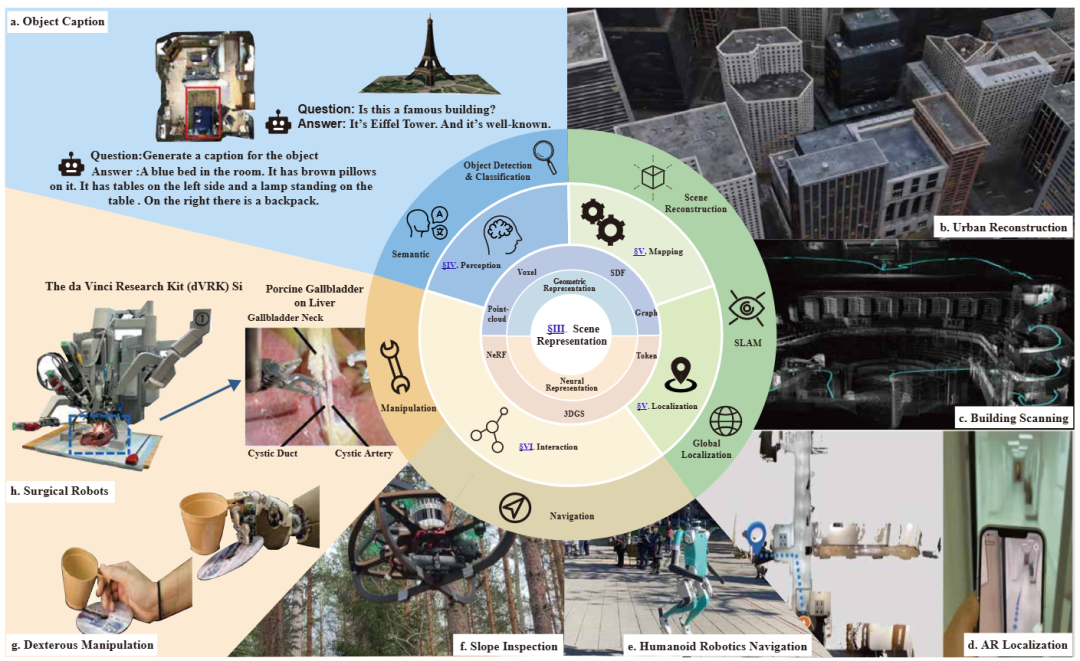
▲图4|三维场景表征如何支撑机器人的核心能力。这张图展示了三维场景表征在机器人系统中的位置:它是感知、建图、定位以及操作等能力的共同基础。从“看见世界”到“在世界中行动”,机器人所有核心能力都建立在这一底层表示之上
但 NeRF 的问题也很现实:
训练太慢、推理太慢、算力需求大、工程落地难。
于是,它开启了第二次场景表征革命。
3D Gaussian Splatting:速度时代的答案
如果说 NeRF 带来“连续世界”,那么 3DGS 带来的就是——
连续世界的实时化。
3DGS 把场景拆成数量巨大的透明“小气泡”(高斯球体),通过一种新型渲染方式让画面飞快呈现:
-
渲染快(能达到 1080p 30fps)、精度高、适合移动机器人进行实时建图
你也可以把它理解为:NeRF 的画质 + 点云的速度 = 3DGS
也因此,在近两年的机器人研究中,3DGS 是热度最高的新技术之一。
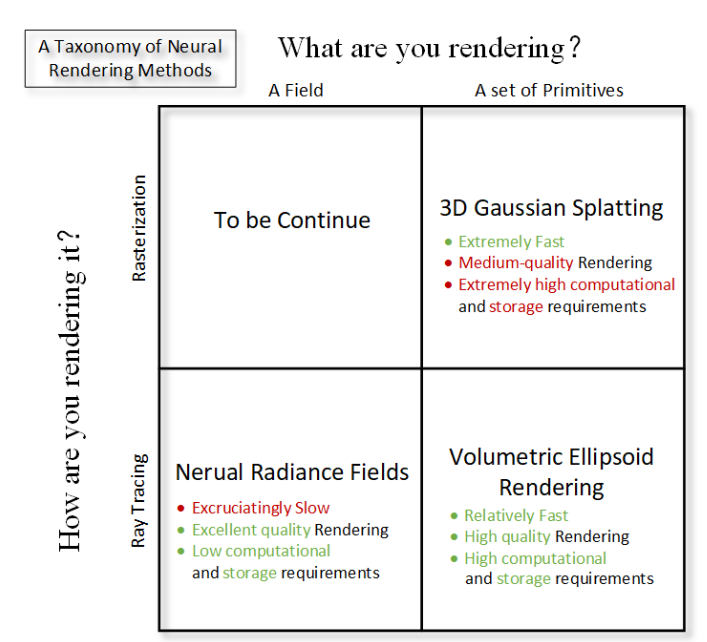
▲图5|神经三维表征的技术谱系与未来方向:这张图总结了神经三维重建的三大代表路线:NeRF、3D 高斯表示以及基于椭球体的体积渲染。它们共同构成了当前三维表征研究的主要分支,也代表了未来可能融合发展的方向
基础模型:下一代机器人的“三维大脑雏形”
这一部分可以说是整个具身智能领域最令人期待的方向。
为什么这么说?
因为它把三维世界变成一种“可推理的语言”。
前面我们提到的传统表征:
点云 = 点
NeRF = 网络参数
3DGS = 高斯球体
而基础模型把三维场景编码成 token(类似自然语言)
这意味着机器人可以:
-
用语言询问三维世界、在大模型中进行空间推理、用文本引导三维任务(如“从桌子下面绕过去”);
-
实现真正的零样本导航、灵样本操作。
这是人类第一次尝试为机器人构建一种统一的、可泛化的三维认知格式。
但挑战同样巨大:
-
模型规模太大、训练数据昂贵、几何精度仍不如传统方法。
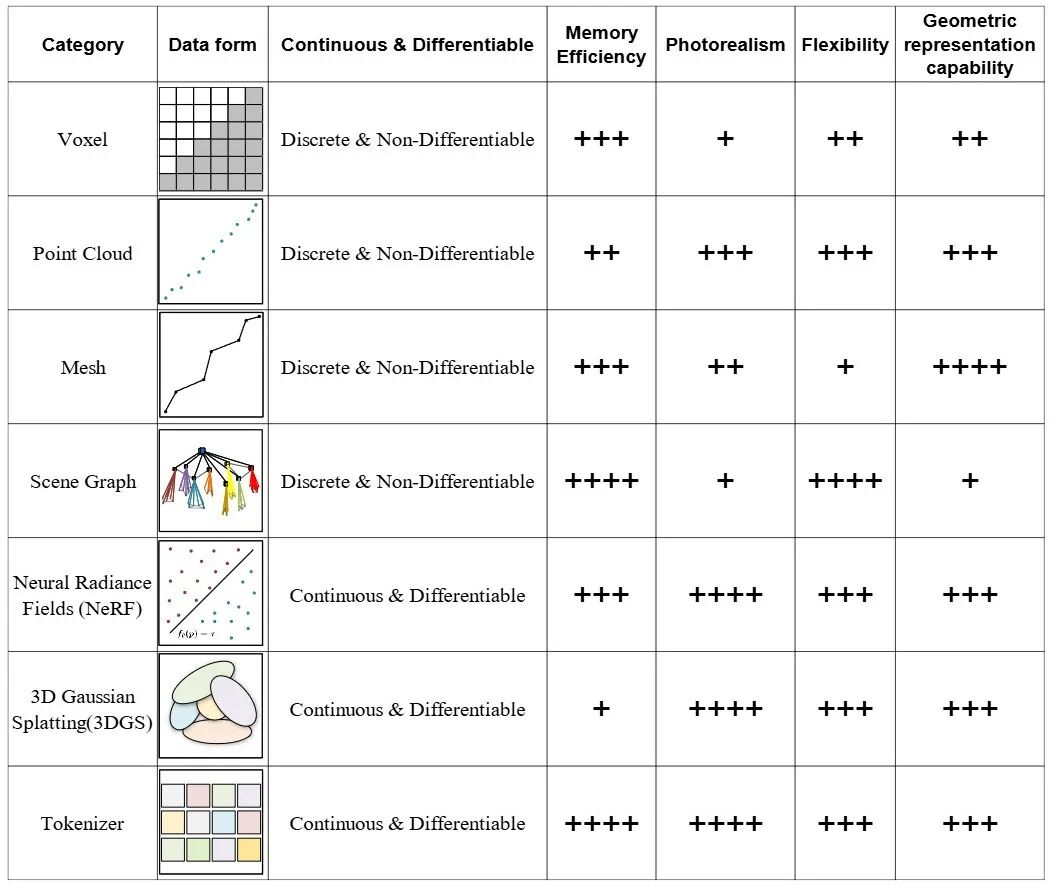
▲图6|不同三维表示技术的特点对比。图中从多个维度比较了主流三维表征方式,包括数据形式、是否连续、占用内存、真实感、灵活性以及能否精确表达几何结构。不同方法各有优缺点,这也是为什么今天的机器人往往需要多种表征“混合使用”

近年来有个明显趋势:语言模型的理解能力持续升级,机器人的动作控制愈发稳定,能应对的任务也越来越复杂。
但真正让机器人从 “机械执行指令” 跨越到 “自主决策行动” 的,核心是新三维表征体系的突破——
它第一次让机器人打通了 “视觉 - 语言 - 动作” 的完整链条,这正是具身智能的核心,也是当前 Vision-Language-Action(VLA)领域研究的核心灵感来源。
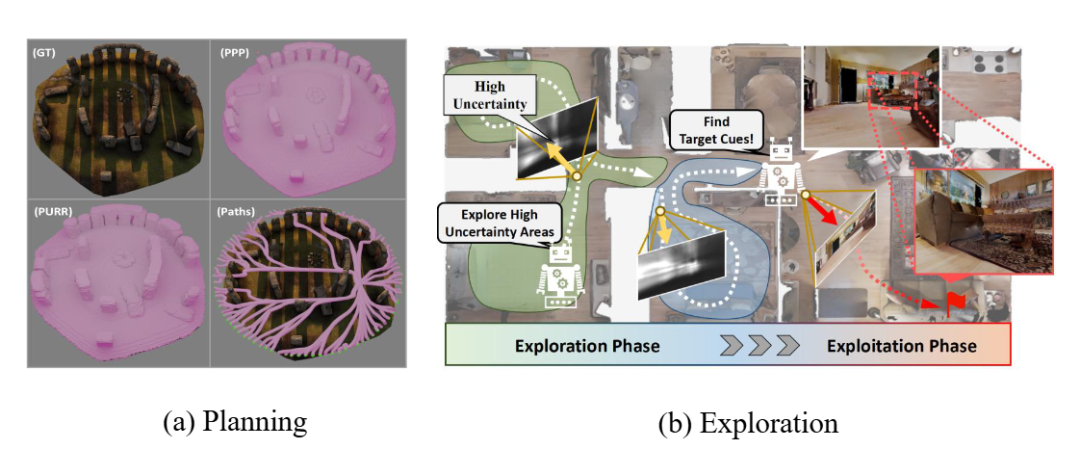
▲图7|基于神经三维表征的机器人导航示例:这张图展示了如何利用神经三维表征完成机器人导航任务。通过在连续、可补全的三维世界中规划路径,机器人能够更自然地理解环境结构,从而执行更复杂、更多约束的导航操作

回顾过去五十年:
机器人从 2D 网格走向点云、从点云走向 NeRF;从 NeRF 走向 3DGS;今天又迈向基础模型。
过去的机器人是“记录世界”:看到什么,存什么;
现在的机器人开始“理解世界”:能补全、能推理、能联想;
未来的机器人会“表达世界”:把场景变成语言,把语言变成行动,把行动变成智能。
对于具身智能而言,3D 场景表征不是什么“一个模块”,而是整个系统能力的底座……
Ref
论文标题:What Is The Best 3D Scene Representation forRobotics? From Geometric to Foundation Models
论文地址:Tianchen Deng, Yue Pan, Shenghai Yuan, Dong Li, Chen Wang, Mingrui Li, Long Chen, Lihua Xie, Danwei Wang, Jingchuan Wang, Javier Civera, Hesheng Wang, Weidong Chen
论文链接:https://arxiv.org/pdf/2512.03422v1

















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









