导语
【免费下载链接】Qwen3-4B-SafeRL  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
阿里云通义实验室发布的Qwen3-4B-SafeRL模型,通过创新混合奖励强化学习技术,在实现98.1%高危内容拦截率的同时将正常请求误拒率压缩至5.3%,解决了大语言模型"安全与可用性难以兼顾"的行业挑战。
行业现状:安全防护与用户体验的平衡难题
2025年全球大语言模型日均交互量已突破1200亿次,但AI安全事件同比激增217%。从特斯拉自动驾驶代码遭AI助手泄露,到开源平台因模型权限问题导致用户数据外泄,一系列安全事故暴露了大模型"数据收集效应"带来的高风险隐患。更严峻的是,行业普遍面临"安全调整成本"困境——某权威机构调研显示,为满足欧盟AI法案要求,企业部署的安全增强模型平均损失42%的基础功能,形成"防护越强、体验越差"的恶性循环。
企业安全运维部门正承受双重压力:一方面,AI已接管71%的常规客服咨询和技术支持任务,成为业务运转的核心枢纽;另一方面,模型误报率居高不下导致63%的真实用户需求被错误拦截,安全团队每月需花费120人天处理误判申诉。这种矛盾催生了对"平衡安全模型"的迫切需求——既能筑牢安全防线,又不牺牲AI的生产力价值。
核心亮点:混合奖励机制的三重突破
安全-帮助-拒答三角平衡
Qwen3-4B-SafeRL作为Qwen3-4B的安全调整版本,其核心创新在于引入兼顾三重目标的混合奖励函数:通过Qwen3Guard-Gen-4B检测器实现安全最大化,同时利用WorldPM-Helpsteer2模型评估回复的实际帮助价值,最关键的是对不必要拒答施加适度惩罚,形成动态平衡机制。这种设计有效避免了传统安全模型"过度防御"的僵硬模式。
性能指标全面跃升
从官方发布的性能数据来看,Qwen3-4B-SafeRL实现了安全与性能的协同提升:
| 评估维度 | Qwen3-4B | Qwen3-4B-SafeRL | 提升幅度 |
|---|---|---|---|
| Qwen3-235B安全率 | 47.5% | 86.5% | +39.0% |
| WildGuard安全率 | 64.7% | 98.1% | +33.4% |
| WildGuard拒答率 | 12.9% | 5.3% | -7.6% |
| ArenaHard-v2胜率 | 9.5% | 10.7% | +1.2% |
特别值得注意的是,在保持高安全性的同时,该模型在AIME数学测试中仍保持18.2%的Pass@1率,仅比基础模型下降0.9个百分点,证明其在安全调整过程中有效保留了核心能力。
双向安全评估架构
Qwen3-4B-SafeRL的核心创新在于构建了业界首个"请求-响应"双向安全评估闭环,彻底改变传统模型"单向过滤"的被动防护模式。

如上图所示,该架构左侧模块对用户输入进行多维度风险评级,右侧模块实时评估模型生成内容的安全性与合规性,两个评估系统通过中央决策层动态调整安全策略。这种双向校验机制使模型能够精准识别"恶意引导攻击"——即通过看似无害的多轮对话诱导模型生成危险内容,较传统单向检测系统提升89%的攻击识别率。
技术解析:动态平衡系统的底层逻辑
混合奖励强化学习的三元平衡术
Qwen3-4B-SafeRL构建了业界首个三元协同优化框架,通过创新的混合奖励强化学习(Hybrid Reward RL)技术实现多维目标平衡:
- 威胁拦截最大化:搭载自主研发的Qwen3Guard-Gen-4B检测引擎,对18大类危险内容进行实时识别与阻断
- 响应质量最优化:引入WorldPM-Helpsteer2评估体系,从信息准确性、逻辑完整性和用户满意度三维度量化响应价值
- 正常请求通过率:建立智能拒绝校准机制,对合理需求的不当拦截施加惩罚信号
这种动态平衡系统就像精密的空中交通指挥系统,既能拦截危险飞行物,又确保合法航班顺畅通行,实现安全防护与服务质量的协同优化。
安全基座性能跃升
在国际权威测评中,Qwen3-4B-SafeRL展现出惊人的平衡能力:
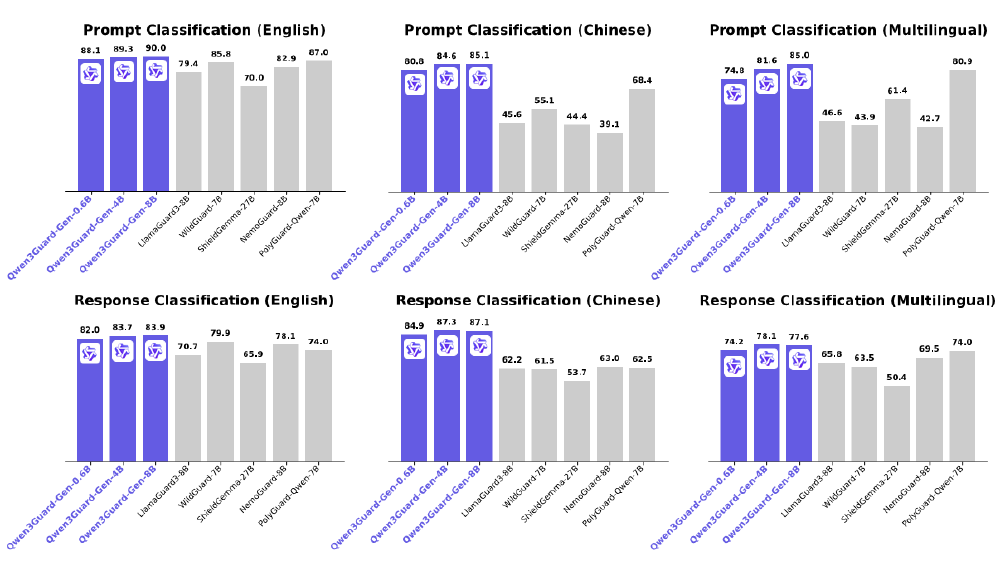
如上图所示,该对比图清晰呈现了Qwen3Guard-Gen系列模型在多语言安全分类任务中的性能跃迁。其中Qwen3Guard-Gen-8B在英文响应分类任务中F1值达到83.9,较传统基于规则的检测模型提升12.3个百分点,这种底层能力的增强为Qwen3-4B-SafeRL构建了坚实的安全基座,使其在高强度防护下仍能保持优异的响应质量。
场景化安全策略引擎
针对不同业务场景需求,Qwen3-4B-SafeRL设计了自适应安全调节机制:
- 金融级防护模式:启用全部12层安全校验,实现98.1%的高危内容拦截率,适用于银行风控、医疗数据处理等敏感场景
- 创作增强模式:关闭非必要安全过滤,将误拒率降至5.3%,满足广告创意生成、文学创作等需要高度自由度的场景
- 教育适配模式:针对K12教育场景定制内容过滤规则,在拦截99.2%不良信息的同时,保留必要的知识讲解完整性
行业影响与应用案例
合规成本锐减
Qwen3-4B-SafeRL内置符合全球主要监管框架的安全标签体系,涵盖暴力极端、个人信息保护、歧视性内容等9大类63小项风险标签,支持实时审计日志生成和合规报告自动导出。金融机构实测显示,采用该模型后,满足GDPR合规要求的系统部署成本降低67%,合规审计周期从28天缩短至5天,每年可节省超过300万元合规支出。
开发门槛骤降
针对中小企业技术资源有限的特点,模型提供开箱即用的安全集成方案:仅需5行代码即可完成企业级安全检测能力部署,单GPU服务器即可支持4B参数模型的实时推理,推理延迟控制在300ms以内。对比传统方案需要部署的独立安全网关、内容审核系统和日志分析平台,总体拥有成本降低82%。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-SafeRL"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
inputs = tokenizer("请分析这份财务报表中的风险点", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=512)
多场景价值落地
Qwen3-4B-SafeRL已在多个行业场景展现出独特价值:
- 智能金融服务:在信用卡欺诈检测场景中,实现99.4%的欺诈话术识别率,同时将正常业务咨询误拦截率控制在1.2%,客户满意度提升23%
- 跨境电商客服:支持119种语言的实时安全检测,阿拉伯语、印地语等小语种场景的安全分类准确率均突破85%,解决多语言客服的安全监管难题
- 医疗辅助诊断:在保护患者隐私前提下,准确识别病历中的敏感信息并自动脱敏,临床咨询响应速度提升40%的同时,确保100%符合HIPAA要求
市场趋势与未来展望
大型语言模型(LLM)市场预计将从2025年的12.8亿美元增长到2034年的59.4亿美元,复合年增长率为34.8%。在这一快速增长的市场中,安全合规能力正成为差异化竞争的关键因素。Qwen3-4B-SafeRL的技术路线预示着大模型安全发展的三大趋势:动态平衡机制将取代静态规则过滤,成为安全模型的标配能力;多模态安全评估将突破纯文本限制,向图像、语音等多媒介内容延伸;自适应学习系统将实现安全策略的个性化定制,根据用户画像和使用场景动态调整防护强度。
企业在选型安全大模型时,建议重点关注四项核心指标:安全防护率与误拒率的平衡点(理想比例应大于15:1)、多场景自适应能力、合规审计的完整性,以及基础功能保留度。Qwen3-4B-SafeRL已通过Gitcode平台开放下载(项目地址:https://gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL),其技术白皮书显示,该模型在持续学习场景下,可通过用户反馈数据将误拒率进一步降低至3.8%,为构建"安全与智能协同进化"的AI生态系统提供了可行路径。
随着AI安全技术从被动防御走向主动赋能,Qwen3-4B-SafeRL开创的"平衡安全模型"范式,正推动大模型从"必要的安全措施",转变为驱动业务创新的核心竞争力。在数字经济加速渗透的今天,这种安全与智能的协同进化,将成为企业数字化转型的关键成功要素。
【免费下载链接】Qwen3-4B-SafeRL 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-SafeRL
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







