




标尺的转向本身不保证“丰收”
——它衡量的是潜力,而非结果
站在2025年12月末回望,若要为这一年的机器人学术界勾勒一个粗略的进展坐标系,那么CoRL、RSS、ICRA、IROS这几大顶会的举办时序与主题,应该可以称得上是其中最显眼的维度。
ICRA、IROS,体量最大、覆盖最全面的机器人顶会,几乎覆盖所有方向的关键进展;
RSS 更偏向方法论和长期价值,往往能提前几年预告技术趋势;
CoRL 则站在“学习驱动机器人”的最前沿,攻坚感知 - 决策 - 动作统一建模,推进端到端学习。
而其获奖论文,则成为标记技术脉络的重要坐标。
因此,本篇文章将一起回顾2025各大机器人顶会的获奖论文。当然,本次盘点并非为了简单罗列一份获奖清单——
毕竟,在当下,任何脱离具体上下文的技术颂扬都意义有限。
奖项的确是顶会给出的一把 “筛选标尺”,但我们更想讨论的,是这把尺子究竟在丈量什么。
关注公众号【深蓝具身智能】,后台回复【2025顶会论文】获取完整论文包

最佳会议论文:Marginalizing and Conditioning Gaussians onto Linear Approximations of Smooth Manifolds with Applications in Robotics
-
发文团队:多伦多大学
-
文章概览:
该项研究讨论的是一个在机器人状态估计中经常出现、但很少被认真对待的问题:
当系统状态受到约束时,我们还在用原来的高斯分布处理不确定性,这其实并不完全合理。
比如,当机器人的状态被限制在某个几何结构上时,原本在空间中“到处扩散”的不确定性,理应被压缩到这个结构内部。
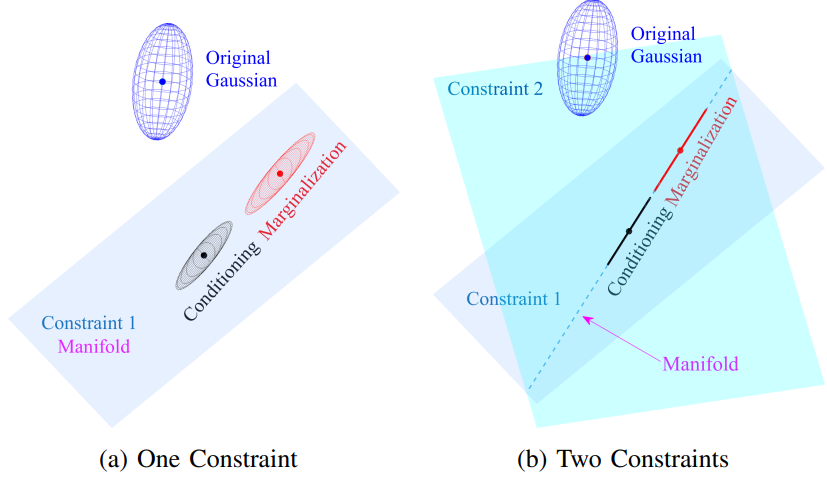
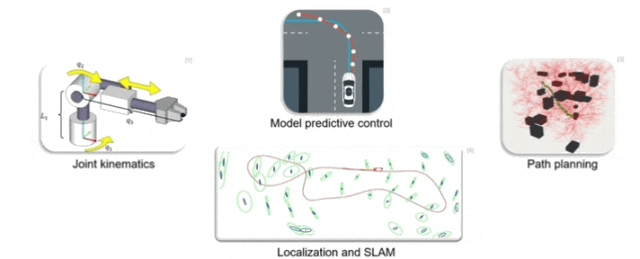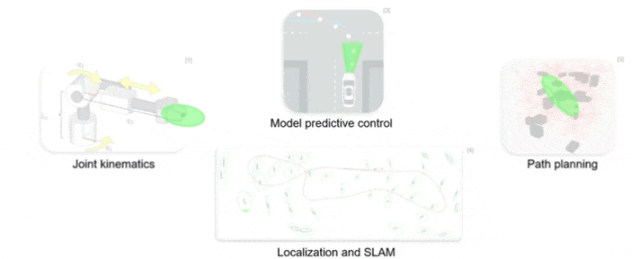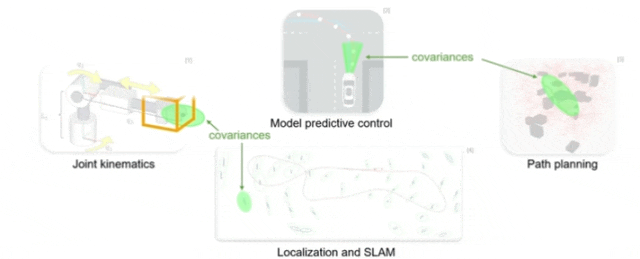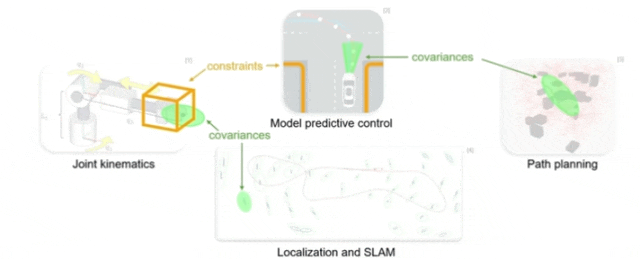
▲当一个高斯分布受到约束时,如何把它“压”到对应的几何结构上去。可以把边缘化理解为:只保留满足约束的那一部分,把多余的自由度直接去掉;而条件化则更像是:在满足约束的前提下,对分布重新做一次归一化
因此,研究从这个直觉出发,推导出了在存在线性约束时,对高斯分布进行处理的一套解析公式,并进一步通过线性近似,把这套方法推广到了更一般的非线性约束场景。
这样一来,在实际机器人系统中,即便状态空间是弯曲的、受约束的,也可以更合理地估计不确定性。
文章地址:https://arxiv.org/pdf/2409.09871
最佳会议论文:MAC-VO: Metrics-aware Covariance for Learning-based Stereo Visual Odometry
-
发文团队:卡内基梅隆大学
-
文章概览:
学习型视觉里程计在真实环境中常见的一个短板:
虽然深度学习方法已经能学会匹配特征点,但系统往往并不知道“哪些匹配是可靠的、哪些其实很危险”。
MAC-VO 的核心思路是让系统显式学会“不确定性”。
因此训练了一个模型,用来预测每个特征点匹配到底“靠不靠谱”,并把这种不确定性直接用在两个关键环节上:
一是挑选哪些特征点值得保留,二是在位姿图优化中。
让可靠的特征点“说话更有分量”,不可靠的影响被自动减弱。相比以往只用简单权重、却并不知道真实几何误差大小的方法,这种做法更贴近真实物理世界。

▲与依赖大量多帧联合优化的方法不同,MAC-VO 只基于相邻两帧之间的位姿图进行优化,并逐步构建地图。关键在于,系统会根据学习到的匹配不确定性,为每个三维特征点建立更符合实际误差的协方差模型,从而在优化过程中自动区分“可靠信息”和“噪声信息”
文章地址:https://arxiv.org/pdf/2409.09479
速览 ICRA 顶会 10 大赛道获奖论文 + 4 篇最佳学生论文
1. 机器学习赛道(Machine Learning Track)Robo-DM: Data Management for Large Robot Datasets
2. 野外与服务机器人赛道(Field and Service Robotics Track)PolyTouch: A Robust Multi-Modal Tactile Sensor for Contact-Rich Manipulation Using Tactile-Diffusion Policies
3. 人机交互赛道(Human-Robot Interaction Track)Human-Agent Joint Learning for Efficient Robot Manipulation Skill Acquisition
4. 机械设计赛道(Mechanical Design Track)Individual and Collective Behaviors in Soft Robot Worms Inspired by Living Worm Blobs
5. 控制赛道(Control Track)No Plan but Everything under Control: Robustly Solving Sequential Tasks with Dynamically Composed Gradient Descent
6. 感知赛道(Perception Track)MAC-VO: Metrics-Aware Covariance for Learning-Based Stereo Visual Odometry
7. 抓取赛道(Grasping Track)D(R, O) Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping
8. 自动化赛道(Automation Track)Physics-Aware Robotic Palletization with Online Masking Inference
9. 医疗赛道(Medical Robotics Track)In-Vivo Tendon-Driven Rodent Ankle Exoskeleton System for Sensorimotor Rehabilitation
10. 多机器人协作赛道(Multi-Robot Systems Track)Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding
最佳学生论文(Best Student Paper Awards)
1. Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding
2. ShadowTac: Dense Measurement of Shear and Normal Deformation of a Tactile Membrane from Colored Shadows
3. Point and Go: Intuitive Reference Frame Reallocation in Mode Switching for Assistive Robotics
4. TinySense: A Lighter Weight and More Power-Efficient Avionics System for Flying Insect-Scale Robots
▲篇幅受限,不展开技术细节,关注公众号【深蓝具身智能】,后台回复【2025顶会盘点】领取完整论文包
最佳论文:Learning a Unified Policy for Position and Force Control in Legged Loco-Manipulation
-
发文团队:北京通用人工智能研究院BIGAI
-
文章概览:
腿式机器人在真实环境中进行操作时一个非常现实的问题:
一旦涉及推、按、顶、撑等接触行为,机器人不仅要知道“动到哪儿”,还必须同时控制“用多大力”。
因此,研究提出了一种统一的控制策略,让机器人在没有力传感器的情况下,同时学会位置控制和力控制。

核心做法是,在仿真中系统性地施加不同的外力和控制指令,让策略通过历史状态去“推断”当前受到的力,并通过调整位置和速度来进行补偿。
这种统一策略支持多种操作模式,包括精确的位置跟踪、主动施加外力、跟随目标力以及更自然的顺应式接触。这样,机器人并不是被动地执行轨迹,而是能够根据接触情况做出更柔顺、更稳定的反应。

▲图1|统一的力-位置控制策略示意图。该策略使腿式机器人能够在多种操作场景中灵活切换,例如跟踪目标位置、主动施加外力以及进行柔顺接触(上)。在模仿学习的数据采集阶段,该策略内部学到的力估计能力可以生成“感知到接触”的示范数据,即便没有外部力传感器,也能提升后续模型在接触密集任务中的表现(中)。在四足机器人和人形机器人上的实验结果,验证了该策略在不同平台上的适应性与稳定性(下)
文章地址:https://arxiv.org/pdf/2505.20829
最佳论文:Fabrica: Dual-Arm Assembly of General Multi-Part Objects via Integrated Planning and Learning
-
发文团队:麻省理工学院
-
文章概览:
该项研究聚焦的是机器人操作中公认最难的一类任务之一:多零件装配。
问题不只是“怎么抓”,而是要在很长的时间跨度内,完成一系列顺序相关、接触密集、几何约束复杂的操作,同时还要能适配不同形状、不同结构的物体。
Fabrica 提出了一套真正“从规划到执行”的双臂装配系统:
在全局层面,系统会自动规划装配顺序、双臂分工、抓取方式以及运动路径,甚至能根据任务自动生成用于固定和支撑的临时夹具,从而保证长序列装配过程的稳定性。
通过将高层规划与低层学习紧密结合,Fabrica 展示了一个无需人工示范、无需任务特定知识、却能够完成通用多零件装配的完整系统。

▲Fabrica 双臂装配系统整体示意图。系统首先通过离线规划解决装配顺序、抓取方式和双臂运动等长时间尺度的问题,为复杂装配任务打好整体框架;在执行阶段,再利用规划结果作为引导,学习能够适应不同物体形状、装配路径和抓取姿态的装配动作,从而在真实环境中稳定完成多零件装配
文章地址:https://arxiv.org/pdf/2506.05168
最佳学生论文:Visual Imitation Enables Contextual Humanoid Control
-
发文团队:加州大学伯克利分校
-
文章概览:
如果人可以通过“看别人怎么做”学会上楼、坐下、起身,那机器人为什么不行?
该项研究围绕这一看似简单、却长期困扰人形机器人的问题,进行展开:
与其设计复杂的传感器和规则,不如直接把人类日常动作的视频作为学习来源。
为此,研究提出了 VIDEOMIMIC,一套从真实视频出发、再回到真实机器人的学习流程。
系统从普通单目视频中同时重建人的运动和周围环境,再将这些信息转化为仿真中的训练数据,最终学得一个能够在真实人形机器人上运行的全身控制策略。
此外,这个策略不仅模仿动作本身,还会结合环境上下文,例如台阶高度、地形变化或座椅位置,从而做出合适的动作调整。

▲图1|VIDEOMIMIC 的整体流程示意图。系统从普通单目视频中学习人类在真实环境中的动作,并通过仿真训练,将这些技能迁移到人形机器人上。最终,机器人能够在一个统一的控制策略下,根据环境情况完成上楼、跨地形、坐下等具有上下文感知的全身动作
文章地址:https://arxiv.org/pdf/2505.03729
延伸阅读:仅占投稿5% | 推荐入选 CoRL 2025 Oral 的17 篇硬核成果,看机器人学习新趋势!

最佳论文:FEAST: A Flexible Mealtime-Assistance System Tackling In-the-Wild Personalization
-
发文团队:康奈尔大学
-
文章概览:
该项研究聚焦机器人应用场景:居家进食辅助。
相比实验室里的单一任务,真实家庭环境中的进食行为高度多样化,不仅包括吃饭、喝水、擦嘴,还会受到环境、交流状态和个人偏好的强烈影响,这使得“通用方案”几乎行不通。
研究提出的 FEAST 系统,并不是从算法性能出发,而是从真实照护需求出发设计的。通过与社区研究者和多位被照护者的长期交流,论文总结了三个在真实环境中进行个性化部署的核心原则:可适应性、透明性和安全性。
围绕这三个原则,系统在硬件、交互方式和控制逻辑上都进行了模块化设计,使其能够根据不同用户的能力和偏好进行灵活调整。
完整内容解读:RSS2025最佳论文!康奈尔大学新突破:首个 | 个性化 | 实时 | 喂食机器人系统
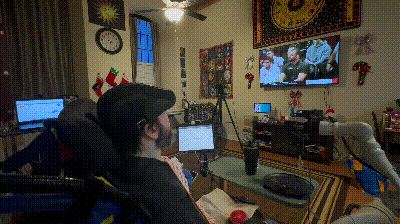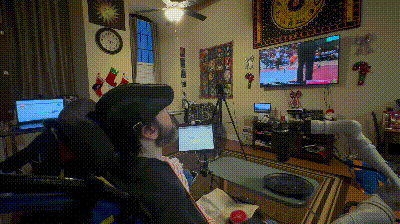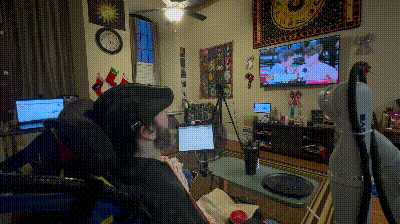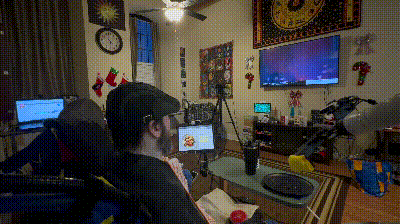
▲FEAST 进食辅助系统的整体设计与真实使用场景。系统基于对多位被照护者需求的调研而设计,强调在真实家庭环境中的适应性、安全性和可理解性。通过居家实验可以看到,FEAST 能够根据不同使用者的需求进行个性化调整,在多种真实用餐场景中稳定提供辅助
文章地址:https://arxiv.org/pdf/2506.14968
最佳学生论文:Solving Multi-Agent Safe Optimal Control with Distributed Epigraph Form MARL
-
发文团队:麻省理工学院
-
文章概览:
该项研究聚焦多智能体协同任务:既要协作完成任务,又必须始终保证安全。
但是协同过程中始终面临:策略震荡、约束失效,甚至学到“偶尔违规但平均没问题”的危险行为,而这在真实机器人上是不可接受的。

基于这一痛点,研究明确提出了一种更符合真实应用的安全定义:安全不是“平均违规很小”,而是“零违规”。
在这一前提下,重新审视了多智能体强化学习中的约束优化形式,提出了 Def-MARL,一种集中训练、分布执行的安全多智能体强化学习算法。
每个机器人在执行时只依赖本地信息,但在训练阶段通过共享结构,保证整体策略在满足安全约束的同时仍然能够高效协作。
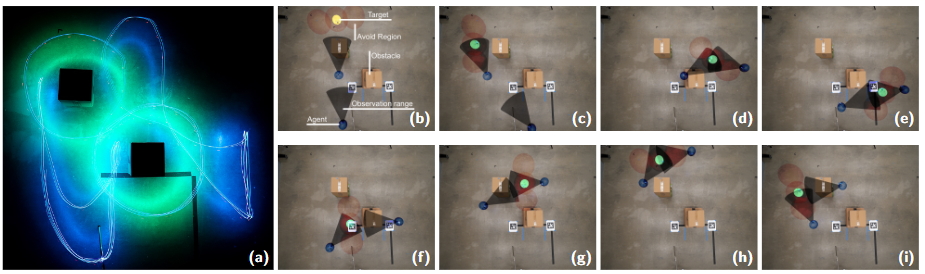
▲图1|Def-MARL 在多无人机协同任务中的效果示意。两台无人机需要在保证安全的前提下协作跟踪一个运动目标。通过 Def-MARL 学到的策略,无人机能够自动分工,在目标位于各自负责区域时进行跟踪,同时始终保持对目标的视觉覆盖。(a) 为无人机和目标的运动轨迹示意;(b)-(i) 展示了策略执行过程中无人机的协同行为
文章地址:https://arxiv.org/pdf/2504.15425
最佳系统论文:Demonstrating MuJoCo Playground
-
发文团队:加州大学伯克利分校、谷歌DeepMind
-
文章概览:
搭环境、跑仿真、训策略、再部署到真实机器人——这条链路往往配置复杂、调试成本高、复现门槛大。
该项研究中的 MuJoCo Playground 目标非常直接,就是把这整套流程变得足够轻量和统一。
团队基于 MJX 构建了一个完全开源的机器人学习框架,通过高度集成的物理引擎、渲染系统和训练环境,让研究者只需简单安装,就可以在单张 GPU 上快速训练策略,并直接迁移到真实机器人上运行。
框架支持多种常见机器人平台,包括四足、人形、灵巧手和机械臂,并同时支持基于状态和基于图像的策略输入。
这项工作为具身智能社区提供了一个更易上手、也更易扩展的实验基础。

▲图1|MuJoCo Playground 支持的多种机器人和任务环境示意。这些在仿真中训练得到的策略,能够直接迁移到真实机器人上运行,包括人形机器人、四足机器人、灵巧手和机械臂等多种平台
文章地址:https://arxiv.org/pdf/2502.08844
最佳系统论文:Building Rome with Convex Optimization
-
发文团队:哈佛大学
-
文章概览:
该方案首次实现无需初始化、可证全局最优的大规模 BA 求解,为 3D 重建提供高效可靠的新范式。
Bundle Adjustment(光束平差,BA) 虽然是结构光恢复和 SfM 系统的核心步骤,但它本质上是一个高度非凸的优化问题,通常非常依赖初始化,规模一大就容易慢、容易崩,甚至直接失败。
能不能把这一步变得又稳、又快、还不怕初始化?
为此,研究提出了一种新的“缩放式”Bundle Adjustment 表达方式,借助学习到的深度信息,直接把二维特征点提升到三维空间中进行优化。在这个基础上,作者设计了一种非常紧致的凸优化松弛,使得原本困难的非凸问题可以被转化为一个具有全局最优保证的优化问题。换句话说,系统不再需要“小心翼翼”地选初值,也能可靠地收敛到正确解。

▲图1|基于凸优化的三维重建流程示意图。通过将传统容易陷入局部最优的 Bundle Adjustment 转化为更稳定的优化形式,系统可以在不依赖初始化的情况下,实现更快、更可扩展的三维重建
文章地址:https://arxiv.org/pdf/2502.04640
延伸阅读:顶会突破!推荐RSS 2025 的8篇力作:聚焦VLA 革新、机器人操纵两大重点领域创新!

此前我们盘点过官方评选出的8篇 Award Finalist Papers,因此不再作具体展开,大家可以点击下方链接查看详细内容。

顶会盘点 | IROS 2025 八大 Finalist:窥见全球机器人研究顶尖实力!
▲点击查看详细内容。关注公众号【深蓝具身智能】,后台回复【2025顶会盘点】领取本文完整论文包

回顾2025年这些来自ICRA、IROS、RSS和CoRL的获奖论文,可以明显感觉到这把“标尺”发生了变化:
“纯粹”的指标领先已不足以定义顶尖工作。
它依然在丈量方法的严谨性与边界的突破性,这毋庸置疑。但更看重的是,一个漂亮的解决方案是否包含了对真实世界 “噪音” 与 “摩擦” 的深刻理解,并为此预留了进化的接口 ——
可能是适配多场景的模块化设计,可能是降低部署门槛的轻量化算法,也可能是兼容真实数据分布的学习框架……
当然,标尺的转向本身不保证“丰收”,它衡量的是潜力,而非结果。
这些被顶会所共同标注的重点方向,能否引领我们穿越当前的技术高原,取决于未来数年里,有多少紧随其后的工作愿意投身于那漫长、琐碎而至关重要的 “接口” 工程之中 ——
路标已然更新,而征途依旧漫长。
Ref:
1. 2025ICRA官网链接:
https://2025.ieee-icra.org/program/awards-and-finalists/
2. 2025CoRL官网链接:
https://www.corl.org/program/awards
3. 2025RSS 官网链接:
https://roboticsconference.org/2025/program/awards/
4. 2025IROS官网链接:
https://ras.papercept.net/conferences/conferences/IROS25/program/IROS25_ContentListWeb_1.html#tuat1
信息来源各顶会官网,如有不全面之处欢迎指正

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









