




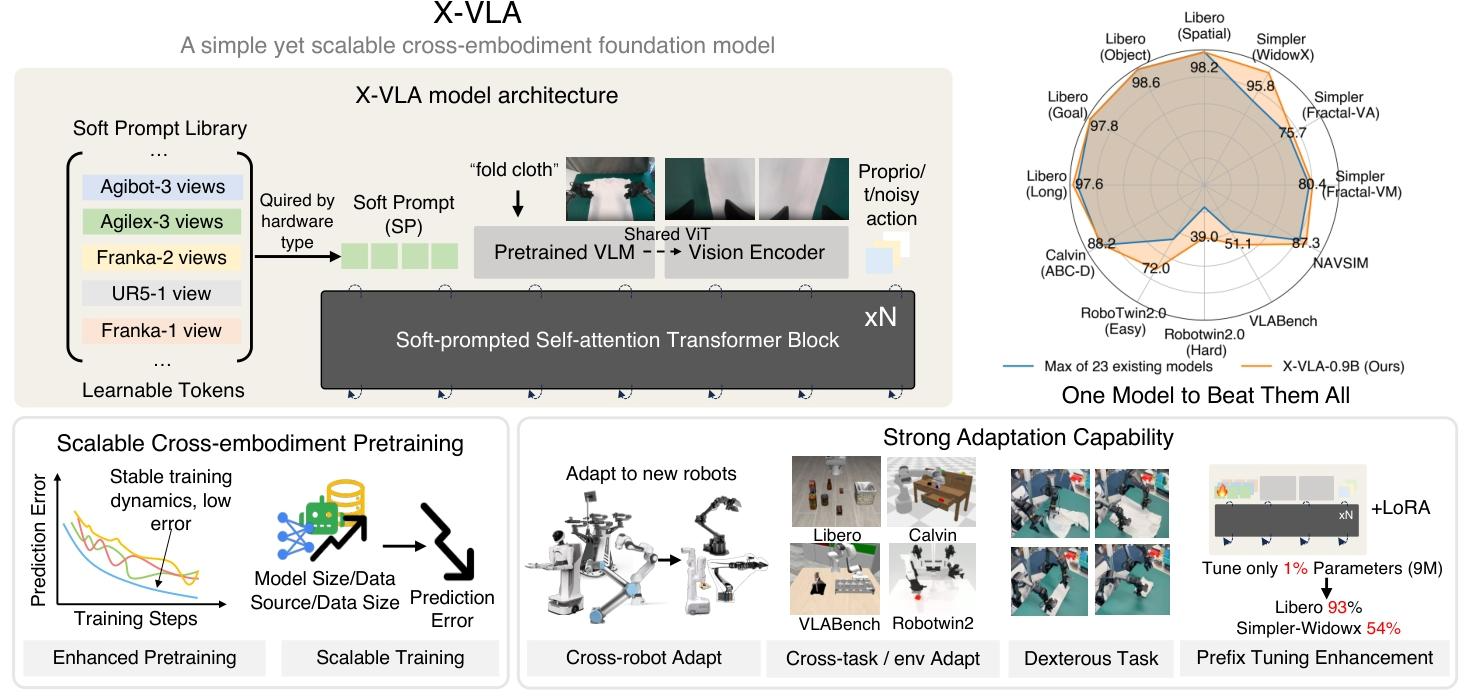
这是清华大学 AIR 与上海 AI Lab 最新发布的 X-VLA 模型——全球首个实现「120 分钟无辅助自主叠衣」的全开源具身智能模型,在 IROS 2025 AGIBOT World Challenge 国际具身智能竞赛中荣获冠军。
长期以来,构建具身通用大模型一直受限于三个核心问题:硬件差异大,数据采集标准不一,跨场景泛化能力差。
而X-VLA的突破性意义在于采用纯 Transformer 框架,通过可学习的 Soft-Prompt 嵌入让模型“理解”不同机器人和环境的差异。这让它成为首个真正能在统一模型中完成跨平台、跨任务、跨环境学习的 VLA 系统,为通用机器人智能开辟了新的路径。

异构软提示学习
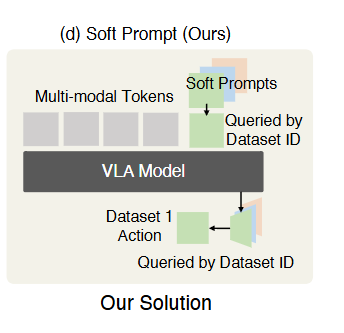
▲图2 | soft prompts方法:通过数据集 ID 查询软提示库和动作输出库,将软提示注入多模态令牌,实现跨实体适配。
为了解决不同机器人硬件差异导致的策略迁移困难的问题,传统方法通常为设置单独的动作输出头或添加人工语言描述来适配,这样大大提高模型迁移部署的成本。而 X-VLA 则以可学习的 Soft-Prompt 向量在统一 Transformer 架构中自动编码硬件特征,实现跨机器人自适应。具体工作流程如下:
-
为每个 “实体 + 环境” 组合(如 “Franka + 顶部相机”“AGIBOT + 头部 / 手腕相机”)分配独立的可学习软提示向量,将 “实体 - 环境差异” 编码为模型可理解的特征;
-
训练时通过数据集 ID 调用对应软提示,引导模型在早期特征融合阶段就 “感知” 当前的实体 - 环境属性,从而动态调整视觉 - 语言 - 动作的映射关系,避免分布偏移导致的泛化性能下降。
例如,当模型从 “Franka(顶部相机,实验室)” 迁移到 “AGIBOT(手腕相机,家庭环境)” 时,软提示会自动注入 AGIBOT 的硬件特征和家庭环境的视觉分布信息,帮助模型快速适配新领域的感知 - 控制逻辑。
多模态编码
除了软提示之外,X-VLA还为复杂的多模态输入构建一个精简的编码管道。
1、与直接将全部视角与指令送入 VLM 不同,X-VLA 采用双流编码:固定视角与语言指令由预训练 VLM 处理,手腕等辅助视角由共享视觉主干编码,从而兼顾高层语义理解与低层操作精度。
2、由于本体感觉状态与动作生成令牌
均为具有相关物理语义的紧凑向量,X-VLA 在流匹配过程中将它们与时间信息
拼接,并通过轻量线性层投影至高维特征空间,让模型既“知道自己在哪”,又“理解动作何时发生”,保证控制的连贯与稳定。
数据增强机制
X-VLA对人工演示数据进行了结构化再加工。通过 时间下采样 + 动作抽象 + 统一表示,它将原本嘈杂的低级轨迹转化为可泛化的高层意图信号,从而在不增加采集成本的情况下,显著提升了预训练的语义对齐与稳定性。
异质混合数据集
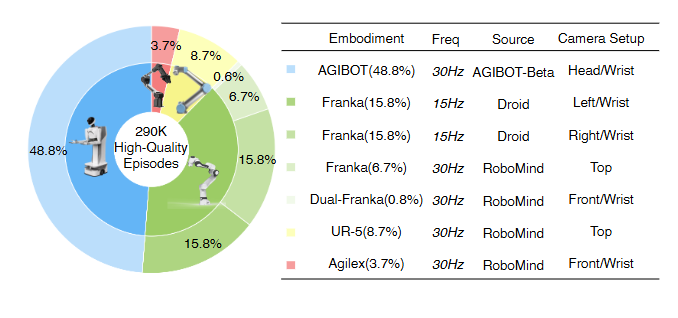
▲图3 | 数据集分布情况
模型在异质混合数据集上进行大规模预训练,总计约 290 K 条机器人操作演示,来自多个公开或实验室数据源。数据分布如图3所示,共有 7 套硬件系统、5 类机械臂(单臂与双臂),采样频率 15–30 Hz,数据统一转换为末端执行器 (EEF) 位姿 + 6D 旋转 + 抓取状态 的标准动作表示。

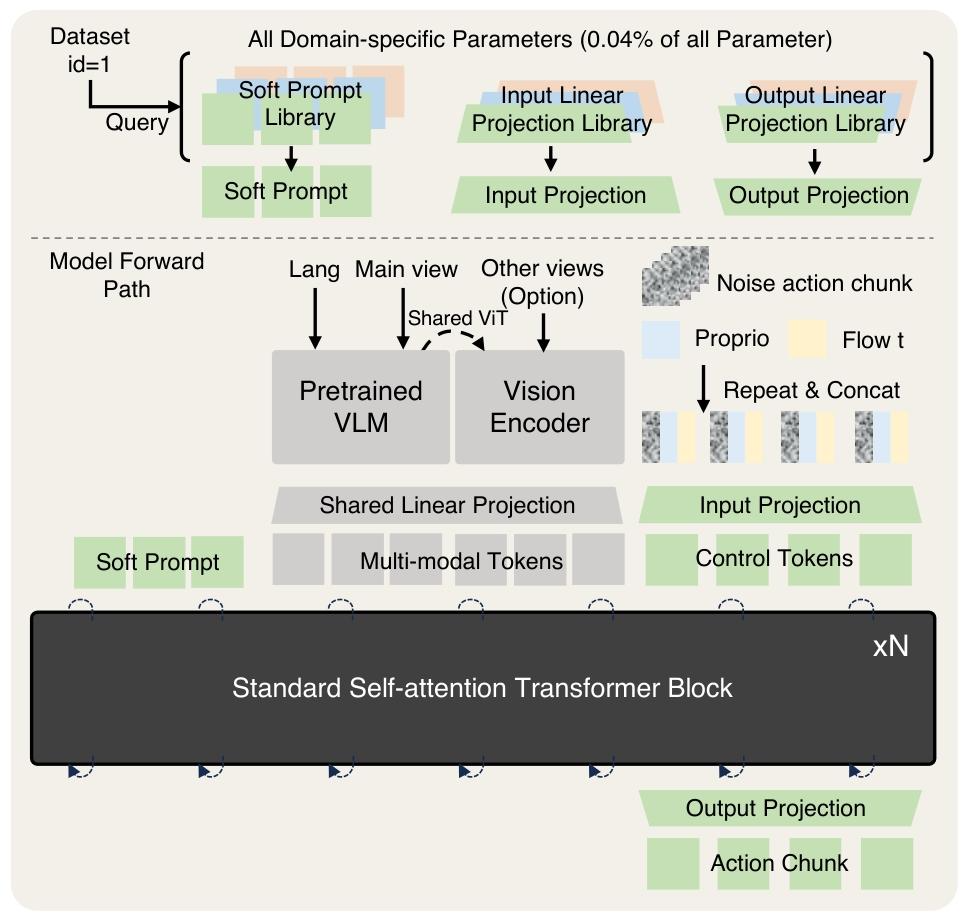
▲图4 | 模型架构图
这张图展示了X-VLA 模型的完整架构,核心是通过领域特定参数库(软提示、输入 / 输出投影) 处理跨实体异质性,结合多模态编码与标准 Transformer 模块实现视觉 - 语言 - 动作的端到端学习。
特定数据库
X-VLA 通过软提示(Soft Prompts )及输入 / 输出投影库建模跨实体差异。软提示为每个数据源存储可学习嵌入,输入与输出投影层分别实现模态对齐与动作空间映射。 这些组件仅占模型数据 0.04%,表明X-VLA可实现“小参数高适配”的跨机器人迁移。
模型架构
多模态输入包括语言、图像、本体状态与动作噪声。主视角与语言由预训练 VLM 处理,手腕等辅助视角经共享视觉主干编码;本体状态(Proprio),时间嵌入(Flow t),带噪声的动作片段(Noise action chunk)拼接后经线性映射至高维空间,实现早期模态融合,再由多层 Transformer 编码器学习视觉–语言–动作的统一表征。经 Transformer 编码后,通过Output Projection(输出投影) 将特征映射到具体动作空间,生成动作片段(Action Chunk),直接用于机器人控制。

X-VLA实验致力于解决下面三个问题
1. 缩放实验:X-VLA 的性能是否会随 “模型变大、数据更多样、数据量更大” 而稳定提升?
2. 适配性能:X-VLA能否适用于具有不同特征的新领域(机械臂/场景)?
3. 可解释性:软提示是否捕捉到了能够反映混合数据源异质性的有意义表征?
缩放实验
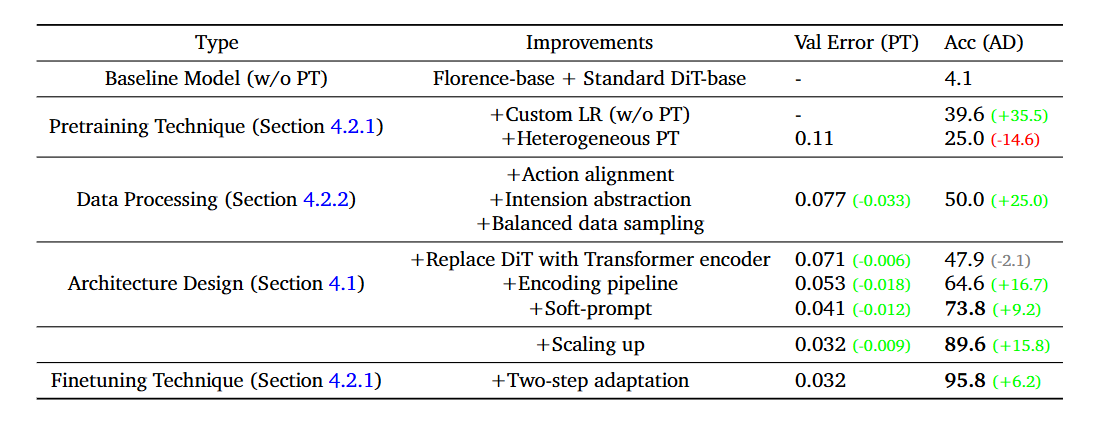
▲表1 | 随着预训练期间验证误差(Val Error)的减小,适应成功率逐步提高,这表明两者之间存在很强的相关性。因此,在本文中,我们使用验证误差作为预训练性能的替代指标。
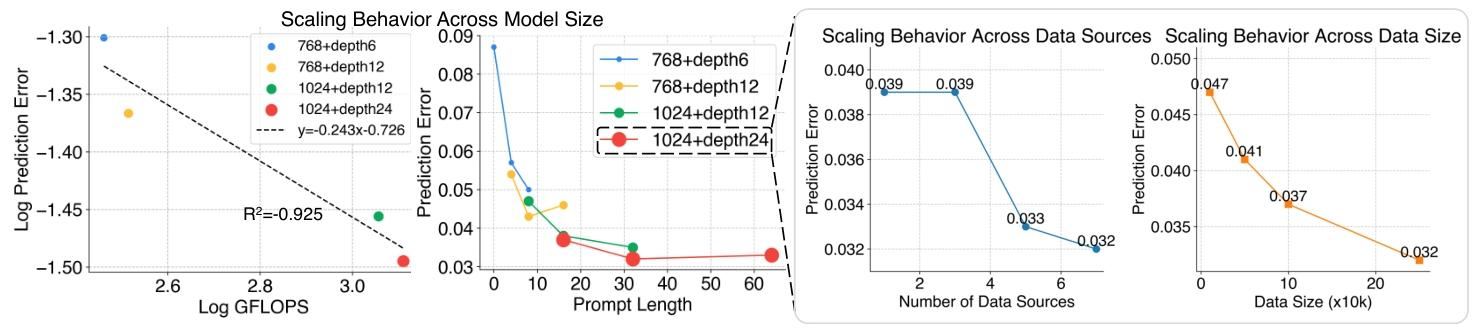
▲图5 | 随着计算量、数据多样性和数据量的增加,X-VLA能够降低验证预测误差,提升适配性能。
如表1所示,随着预训练期间验证误差(Val Error)的减小,适应成功率逐步提高,这表明两者之间存在很强的相关性。因此,在论文中,作者使用验证误差作为预训练性能的替代指标。
图5实验图表分别从模型容量、提示长度、数据源多样性、数据量四个维度,直观展示了 X-VLA 模型的缩放行为,核心结论是模型性能随 “模型变大、数据源更多、数据量更大” 稳定提升,且无饱和迹象,证明了 X-VLA 的可扩展性。
适配实验
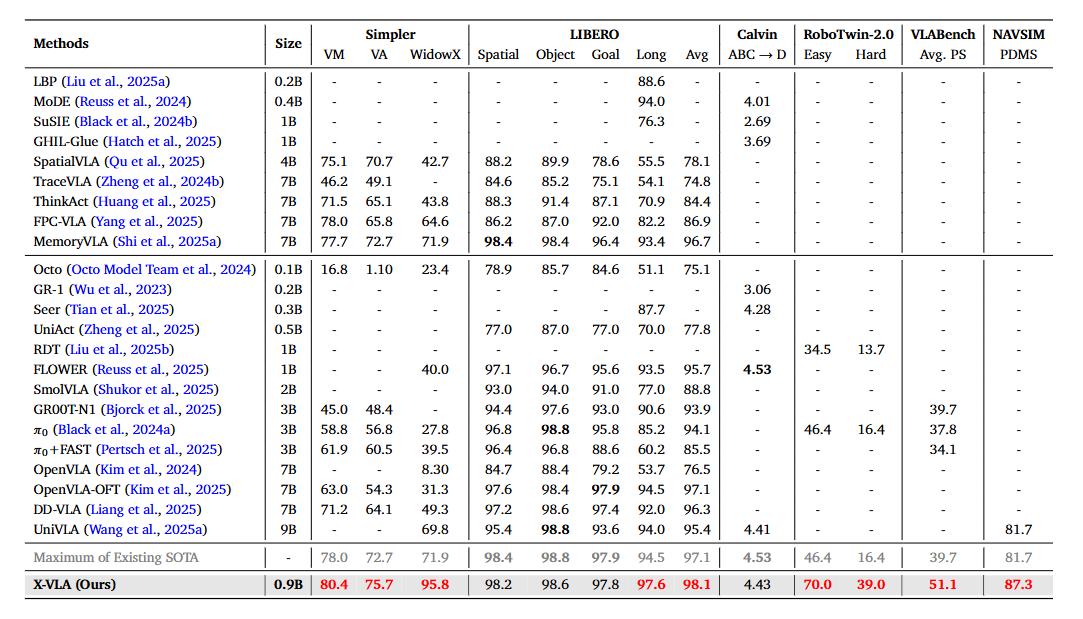
▲表2 | 专用模型与通用模型在模拟基准测试中的比较
在 Libero、Simpler 等 6 个仿真环境,以及 WidowX、AgileX、AIRBOT 三台真实机器人上,X-VLA 都交出了满分答卷——从单臂到双臂,从精细操作到长时序任务,它几乎全面刷新了当前最强成绩,达到sota水平。
解释性分析
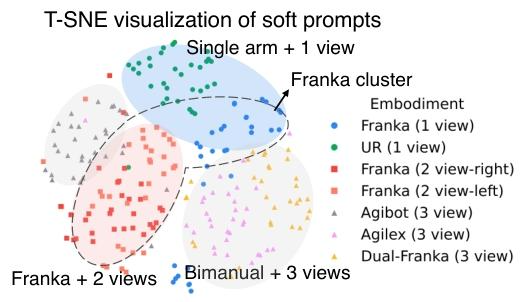
▲图6 | 7个数据源上软提示的T-SNE可视化。
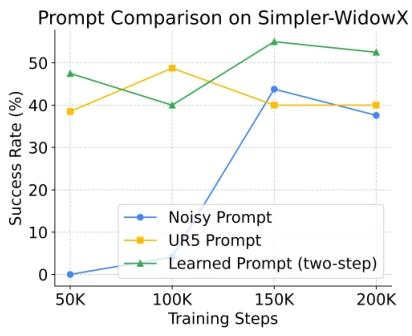
▲图7 | 不同提示词在PEFT上的对比
图 6 说明了经过学习的软提示收敛更快,最终达到更高的成功率,而随机提示则导致适配速度更慢且性能下降。
图 7 soft prompts T-SNE 可视化显示,Franka 左右视角的软提示(红色与灰色)并未分成独立簇,而是自然聚合在一起。这表明软提示并非简单区分数据源,而是能识别并抽取跨实体的共性特征,有效避免对视角等无关差异的过度拟合。

X-VLA 以 Soft-Prompt + 纯 Transformer 架构 为核心,重新定义了机器人学习范式。纯 Transformer 设计为模型的持续扩展与通用化奠定了基础,而 Soft-Prompt 的成功应用,则为利用多源异构数据构建具身通用大模型 提供了全新思路。更重要的是,论文还指出一条值得探索的新方向——融入明确的与具身无关的抽象概念(例如,通用运动学描述符、基于物理的先验知识),可进一步减少模型对特定任务和硬件适配的依赖,让通用机器人智能迈向真正的“理解与推理”阶段。
论文题目:X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
论文作者:Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, Xianyuan Zhan
论文地址:https://arxiv.org/abs/2510.10274 项目地址:https://thu-air-dream.github.io/X-VLA/
Github地址:https://github.com/2toinf/X-VLA

















 74
74

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









