



在科技浪潮的推动下,人形机器人正逐步从实验室走向现实场景。然而,要使机器人能够像人类一样流畅地完成搬箱子、坐下、躺下等日常动作,甚至实现个性化步态(如恐龙行走),仍面临三大核心挑战:在复杂场景下泛化能力弱、机器人动作不能做到和人类一样自然,以及在动态环境下感知不准确。近日,由上海AI实验室与香港科技大学的团队提出了PhysHSI系统,在攻克这些痛点问题上取得了长足的进步,为人形机器人在真实世界中实现通用化、自然化的场景交互提供了强有力的支撑。
项目地址:https://why618188.github.io/physhsi/

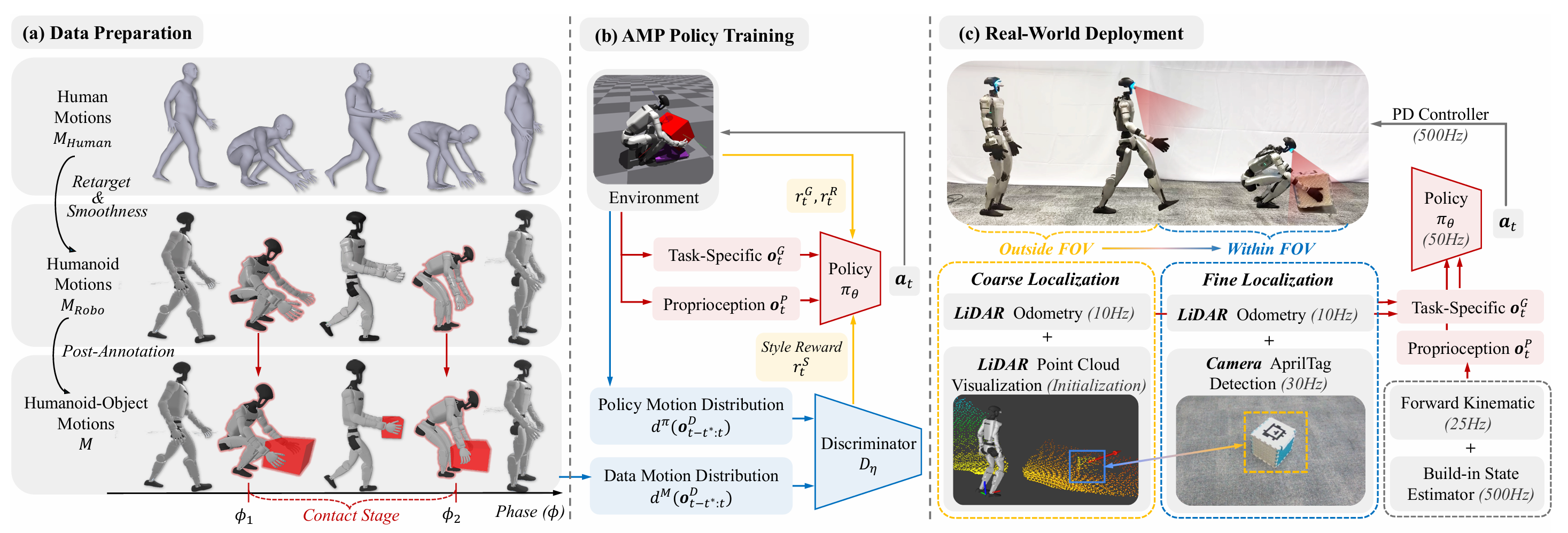
如图所示是PhysHSI的概览,它主要包括:仿真训练(数据准备-AMP策略训练),真实部署:

1. 数据准备
团队从AMASS(人体运动数据集)、SAMP(场景交互数据集)中提取基础运动数据,经过两步处理生成训练所需的交互数据集:
● 运动重定向:将数据集中的SMPL 人体运动模型重定向到Unitree G1机器人模型上,并用平滑滤波器消除重定向后的动作抖动;
● 物体标注:手动标注物体关键接触帧(比如箱子的“拾取瞬间”或“放置瞬间”),通过规则推断物体轨迹,确保数据具备物理合理性。
2. AMP策略
在PhysHSI系统中,人形机器人-场景交互(HSI)问题被建模为强化学习任务,核心是通过对抗运动先验(Adversarial Motion Prior, AMP)框架实现HSI策略学习。该框架以“让机器人运动既满足任务需求,又贴合人类自然运动特性”为目标,包含两大核心组件:负责生成动作的动作策略,以及用于区分“策略生成动作”与“参考动作数据集动作”的判别器,具体设计如下:
(1) 观测空间设计
机器人的观测信息分为本体观测与任务观测两类,且均融入前5步历史时序数据(提升对动态过程的感知能力),同时为判别器单独设计观测输入:
本体观测(108维):涵盖机器人自身运动状态,具体包括3维基座角速度、3维基座重力方向(用于姿态感知)、29维关节位置、29维关节速度,以及15维末端执行器(含左手、右手、左脚、右脚、头部)的3D位置等;
任务观测:随具体HSI任务动态调整(以搬箱子任务为例,包含箱子的3维尺寸、9 维位姿(6维姿态+3维位置)、3维目标放置位置),用于感知任务目标与环境交互对象状态;
判别器观测:以“区分运动来源”为目的,输入包含策略生成的关节动作序列与参考数据集中的关节动作序列,为风格奖励计算提供基础。
(2) 动作空间设计
动作策略的输出直接对接硬件执行逻辑:策略通过强化学习训练后,输出29个关节的目标位置,再由机器人内置的PD控制器解析目标位置,驱动关节运动,确保动作从“策略生成”到“硬件执行”的稳定落地。
(3) 奖励函数设计
● 总奖励采用“任务导向+运动约束+风格对齐”的多维度加权设计,公式表达为:总奖励=任务奖励+正则化奖励+风格奖励,各分项作用与计算逻辑如下:
■ 任务奖励:以“完成高层任务目标”为导向(比如搬箱子任务中“将箱子精准放置到指定位置”),通过设计位置误差、姿态误差等量化指标,鼓励策略生成符合任务需求的动作;
■ 正则化奖励:作为运动约束项,通过惩罚“过大的关节力矩”与“过快的关节速度”,避免机器人因动作过激导致硬件损耗或运动失稳,保障执行安全性;
■ 风格奖励:基于判别器建模实现,核心目标是让策略生成的运动贴近参考数据集中的人类自然运动特性。其计算依赖判别器的风格损失,公式为:判别器风格损失 = t步参考数据集动作对数似然损失 - t步策略生成动作对数似然损失 + 梯度惩罚项,其中,“梯度惩罚项”用于稳定对抗训练过程,避免判别器因数据分布偏移出现梯度消失或梯度爆炸问题;而风格奖励通过反向传播该损失,引导策略生成 “判别器难以区分与参考数据” 的运动,最终实现运动风格与人形自然性的对齐。
3. 微调策略
系统采用的微调优化策略如下:
● 混合参考状态初始化(RSI):在许多人形机器人-场景交互(HSI)任务中,若所有训练episode都从默认初始姿态开始,机器人很难探索到关键的动作过渡状态,而混合 RSI允许从参考数据集中随机采样运动状态作为episode初始状态,并加载对应标注的物体状态。这样一来,机器人能更快接触到多样化的运动起始点,探索到不同的动作序列和解决任务的方式,从而提升在训练过程中的探索效率,避免因初始状态单一而陷入局部最优解。
● 非对称演员-评论家:在真实世界中,由于智能体只能接收部分观测信息,并且系统要求训练过程中对一些任务观测进行掩码处理,所以采用非对称演员-评论家框架进行微调训练。
● 运动约束:引入动态调整风格奖励权重、L2C2正则平滑动作,减低训练过程中机器人抖动现象

完成仿真训练后,将PhysHSI部署到真实机器人上,需要解决环境连续定位和sim-to-real的差距问题:

1. 粗到精定位(解决环境连续定位问题)
● 初始化:目标物开始处于相机视野外,通过激光雷达重建的场景,人工在上面标定物体位置
● 粗定位:采用FAST-LIO进行自身位置估计,结合手动初始化的物体大致位置,引导机器人向目标移动;
● 精定位:当机器人靠近物体(约2.4m内),激活Intel RealSense D455相机的AprilTag检测,精准获取物体位姿;
● 动静态区分:区分静态物体(如椅子,床)与动态物体(如箱子),静态物体姿态固定,即使跟踪过程中从视野中丢失,也能通过全局地图确定其位置;动态物体在抓取过程中有效,抓取后离开视野,该物体将会被屏蔽。
2. 域随机化(解决sim-to-real差距问题)
域随机化方法的关键策略:
● 对物体位姿和前向运动学(FK)观测结果添加随机偏移、高斯噪声以及延迟;
● 复制动态物体在抓取阶段的掩码,当物体处于相机视野之外、目标距离超出范围,或者相机角度与垂直方向偏差过大时,就对该物体进行掩码遮挡,从而屏蔽该物体;
3. 硬件配置
机器人平台:Unitree G1
传感器:内置Livox Mid-360激光雷达,头部外接Intel RealSense D455深度相机
计算平台:Jetson Orin NX
特性:无需依赖外部设备(如动捕系统、外接计算机),支持便携的室内外部署


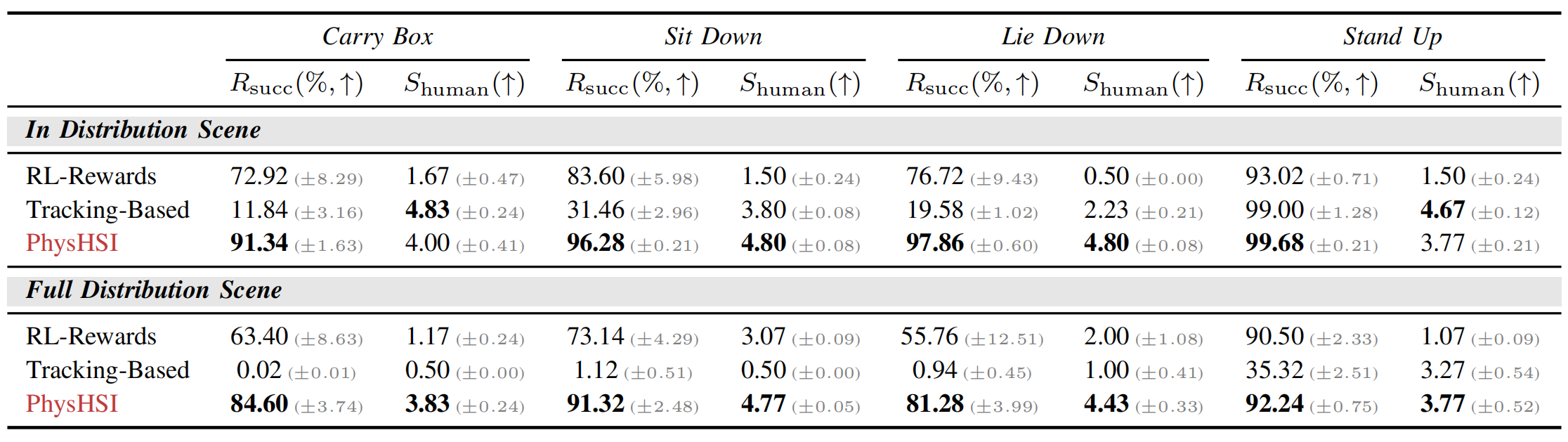
▲说明:仿真环境中基准比较
● 结论
在分布内场景(场景参数与训练数据分布一致)和全分布场景(场景参数随机化,更贴近真实复杂环境)中,相比于传统强化学习(RL-Rewards,依赖手动设计奖励)和轨迹跟踪方法(Tracking-Based,依赖轨迹模仿),PhysHSI均能同时实现更高的"任务成功率"和"自然拟人运动",可见PhysHSI在真实世界适配性上更具优势。

● 消融实验
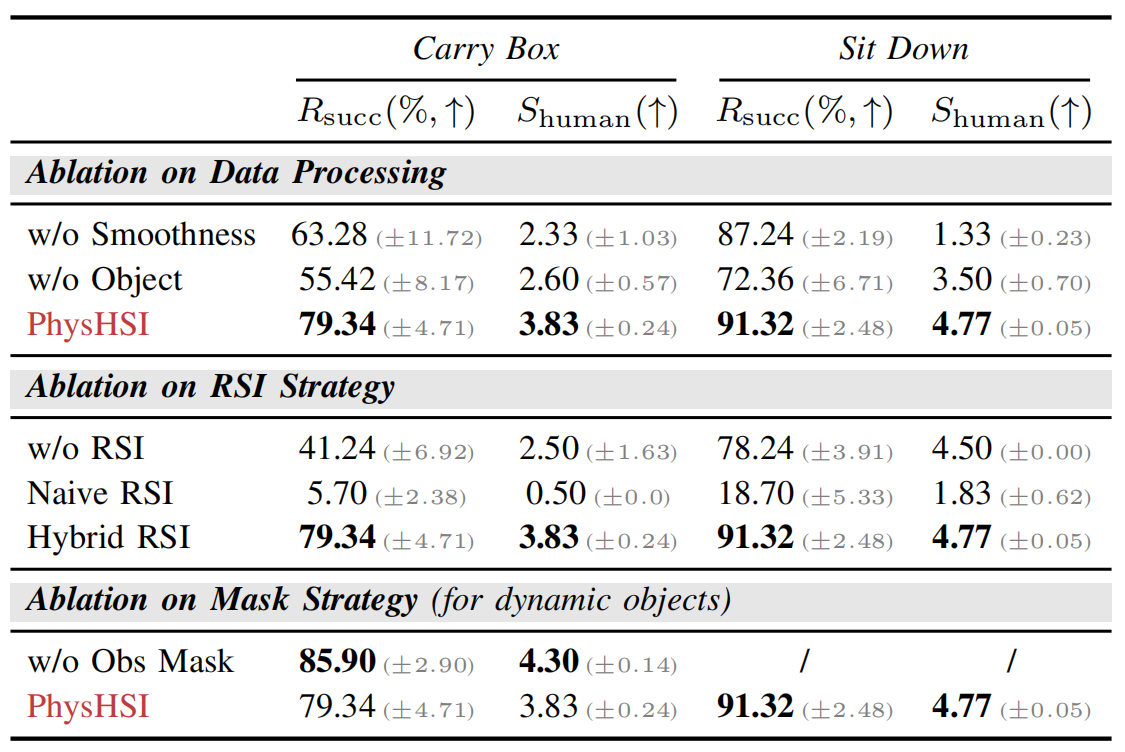
▲说明:各策略的消融实验
○ 结论
PhysHSI的数据处理、混合RSI策略、动态物体掩码三大模块,是其在"任务成功率”"与"运动拟人度"上表现优异的关键保障。
● 任务性能分析

▲说明:各真实任务实验结果


▲说明:躺下

▲说明: 坐下

▲说明: 起立+高抬腿+恐龙步
● 结论
综上,在真实场景中,这几类任务均展现出较好的综合性能,不同任务在成功率、精度、执行时间和作用范围上各有特点,整体验证了系统在真实场景下的有效性与实用性。

尽管表现出色,但PhysHSI仍有改进空间:
● 硬件限制:Unitree G1的橡胶手限制了可搬运物体的体积尺寸和重量;
● 数据依赖:物体标注仍需手动,难以快速扩展到新任务;
● 感知自动化:粗定位需手动初始化物体位置,未来需实现自主目标探索。

PhysHSI的核心价值在于,它构建了“数据-训练-部署”全流程解决方案,对真实世界人形机器人-场景交互(HSI)任务进行探索,为后续在实际应用中开发更先进的物体交互与场景交互能力奠定了基础。

















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









