 WoW世界模型让AI学会物理推理
WoW世界模型让AI学会物理推理




导读
AI能生成世界,但不一定懂世界。从OpenAI的Sora到各种视频生成大模型,它们能造出惊艳的视觉画面,却常常犯物理错误——球能穿地、杯子不掉落。为什么?为它们只是“在看”,而人类是在“做中学”。来自北京大学与港科大的团队提出了 WoW(World-Omniscient World Model),一个真正“通过行动学习”的世界模型:它在200万段机器人交互轨迹中,自己“动手做实验”,逐步学会了物理规律、因果推理与动作执行,让AI第一次具备了世界的因果感知力。
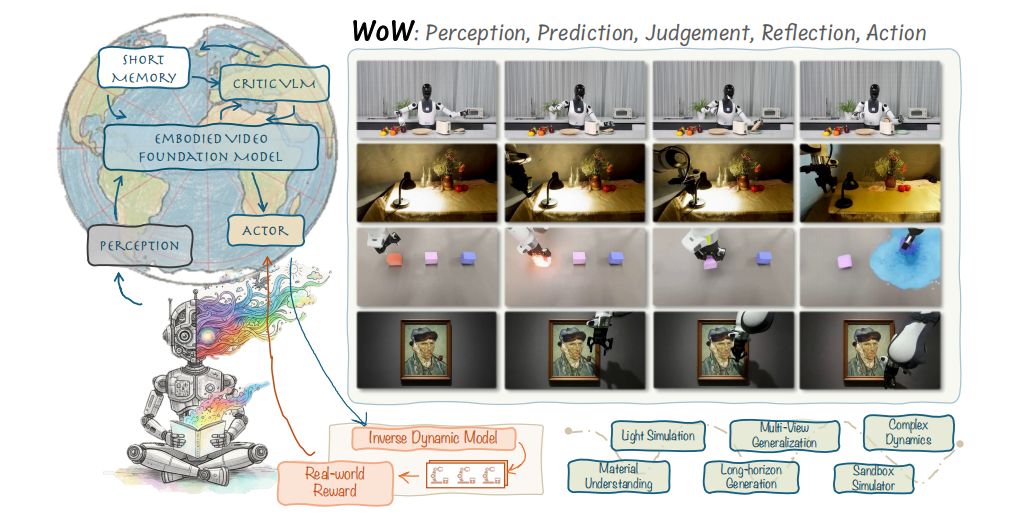
图1|WoW 是一个融合了感知、预测、判断、反思与行动五个环节的具身世界模型。它从真实的机器人交互数据中学习,能在已知与未知场景中生成高质量、物理一致的机器人视频,最终让想象中的动作真正落地于现实执行
论文出处:arXiv2025
论文标题:WOW: TOWARDS A WORLD-OMNISCIENT WORLDMODEL THROUGH EMBODIED INTERACTION
论文作者:Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi,Kevin Zhang等

团队将WoW设计成一个五阶段的具身认知循环:
感知 → 预测 → 判断 → 反思 → 行动。
在传统视频模型中,AI只是被动地预测“下一个画面”;而WoW主动“想象未来”,再用语言模型审视这份想象是否符合物理规律,最后将修正后的结果转化为真实机器人的动作。整个系统建立在一个名为 SOPHIA(Self-Optimizing Predictive Hallucination Improving Agent)的自我优化框架上。SOPHIA融合了扩散Transformer(DiT)的生成能力与视觉语言模型(VLM)的推理能力,让AI能在语言指导下,反复“生成-批评-改进”,形成一个真正闭环的世界模拟系统。💡如果说Sora是在“看世界”,那么WoW是在“体验世界”。

SOPHIA自我优化循环
WoW不靠一次生成,而是通过三步循环来进化想象:
Predict(预测) → Critic(审视) → Refine(改写)。
语言模型像一个“物理评论员”,对生成视频打分并反馈问题,下一轮扩散模型再据此改进提示词,生成更符合物理规律的结果。这一机制让模型从“视觉幻想”变为“物理推理”。
Solver-Critic双智能体架构
WoW内部存在一对协作智能体:
● Refiner Agent(生成者) 不断产出候选视频;
● Dynamic Critic Model(评估者) 检查物理一致性、动作连贯性、任务完成度。
两者形成“证明者-验证者(Prover-Verifier)”式闭环,使得模型能在不可微的物理空间中实现自我纠错。
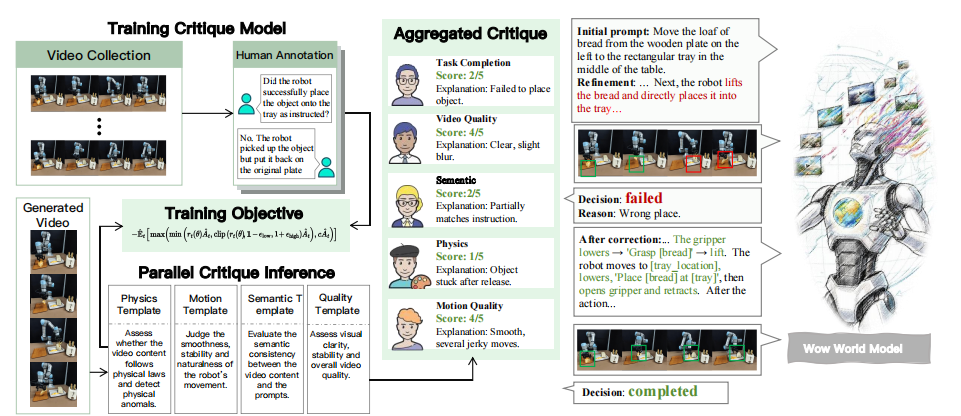
图2|左侧展示了 动态评论模型团队(Dynamic Critic Model Team),它通过真实与合成视频的标注训练,学会判断生成画面的物理合理性。右侧展示 Refiner Agent(优化智能体),根据评论模型的反馈不断改写提示词、重新生成视频,形成一个“生成—批评—改进”的闭环优化过程,让模型越看越准,越生成越真实
Flow-Mask Inverse Dynamics Model(FM-IDM):
为了让“想象”真正落地,团队设计了一个像素级动作反推模块。它通过光流估计与遮罩分支,将连续两帧预测视频转化为机器人末端执行器的7维动作。这使得WoW不仅能“想象未来”,还能“动手去实现”。
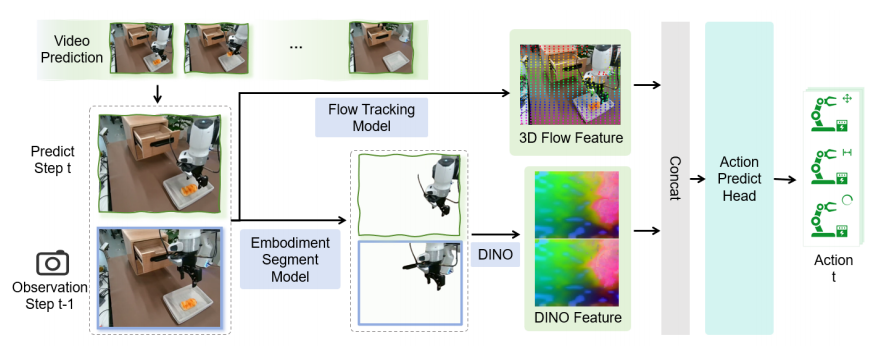
图3|给定连续两帧预测视频,FM-IDM(Flow-Mask Inverse Dynamics Model)能够计算出机器人末端执行器的动作变化量(ΔAction),从视觉“想象”中反推出真实可执行的运动指令,让模型真正实现从视频到行动的闭环
WoWBench:为物理直觉量身打造的评测体系
团队还创建了 WoWBench,一个专测“物理一致性与因果推理”的新基准。 它从四个维度评估模型能力——感知、预测、规划与泛化,共20个子任务、606条机器人轨迹,并结合人类与AI双重评分,让“想象力”第一次有了可量化的科学标准
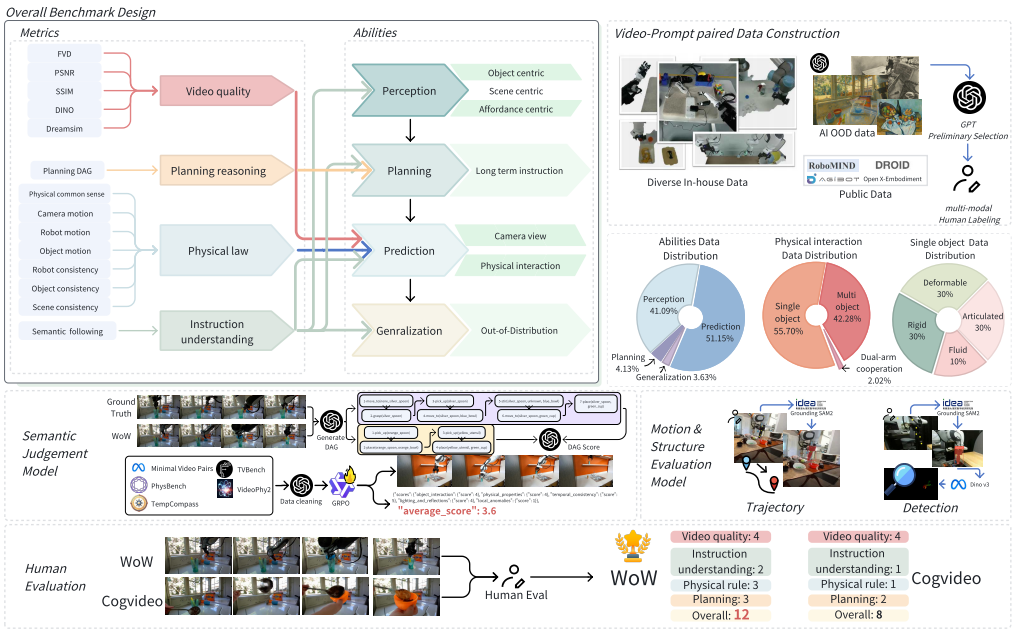
图4|WoWBench 围绕五个核心组成部分构建:(左上)多维评测体系,从视频质量、规划推理、物理规律、指令理解四个角度评价生成结果;(中上)对应具身世界模型的四大核心能力——感知、规划、预测与泛化;(右上)依托多源数据构建流程,融合自采、开源与AI生成数据,并结合 GPT 预筛选 + 人类标注 的混合机制,形成高质量的视频–指令对(图中三张饼图展示了数据分布统计);(中部)采用双评测机制:专家模型评估运动与一致性,GPT或精调VLM评估指令理解与任务规划;(底部)还邀请了12位领域专家进行人工评审,确保模型表现与人类认知一致

性能领先
WoW 在 WoWBench 四大指标中全面领先,在“物理法则一致性”上达到 80.16%,在“指令理解”上更高达 96.53%,远超 Cosmos-Predict、CogVideoX 等强势基线。
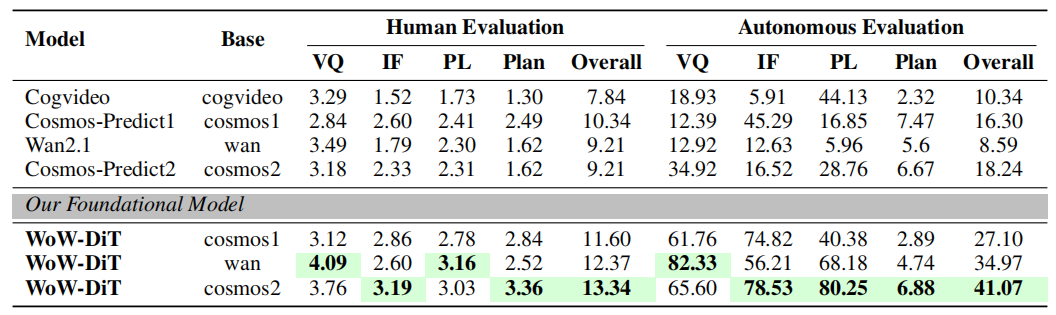
图5|基础视频生成模型对比分析图,该图展示了 WoW-DiT 与多种主流视频生成模型在文本到视频(Text-to-Video)任务中的性能对比。所有指标均为“数值越高越好”,表格中加粗高亮的部分代表最佳成绩。可以看到,WoW-DiT 在多个关键维度上全面超越现有 SOTA 模型
数据与规模领先
从 3万 到 200万 条交互轨迹,WoW 的性能几乎呈幂律增长——证明真实交互数据比纯视觉数据更能塑造“世界理解力”。14B 参数版本在复杂物理任务上表现最稳健,即便是7B模型,也能在效率与效果间取得理想平衡。
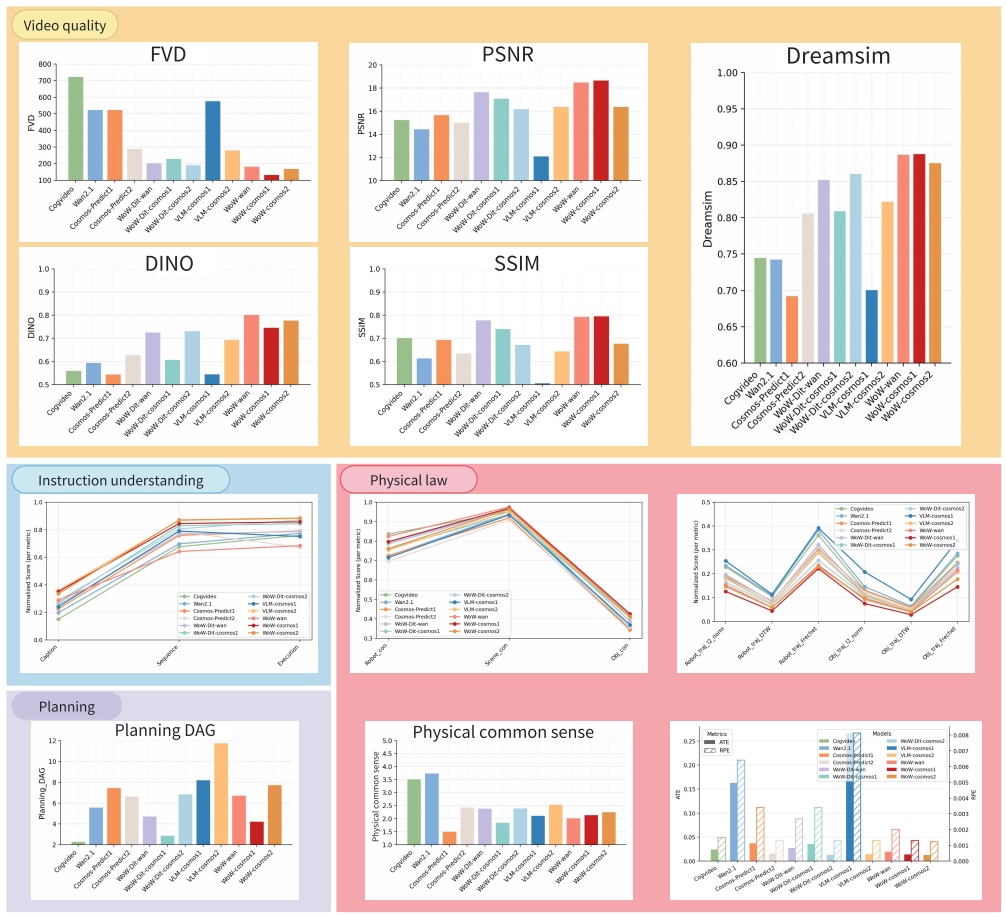
图6|WoWBench 各模型多维细粒度性能对比图,这张图展示了不同模型在 WoWBench 各项指标下的详细表现。不同颜色的方块代表四个核心维度——感知、预测、规划与泛化,每个模块中都给出了直观的图表,对比各模型在不同评测指标下的得分差异
现实验证:从视频到真实机器人
在真实机器人实验中,WoW-驱动的 FM-IDM 在 中等难度任务成功率达到75.2%,在简单任务上更高达 94.5%,远超传统逆动力学基线。当部署到实际机械臂上,WoW 生成的动作几乎可直接执行——它能识别碰撞、避免错误抓取,实现“从像素到动作”的完整闭环。

图7|机器人动作类型泛化能力展示图;这张图展示了 WoW 模型在多种机器人操作任务中的泛化能力。从“推、拉、抓取、堆叠”等基础动作,到“按按钮、解锁、系绳”等复杂操作,模型都能理解语义并生成连贯、物理合理的动作序列
泛化力
不论是 UR5、Franka、AgileX 双臂机器人,还是油画风、素描风的虚拟环境,WoW 都能准确执行任务。它甚至能理解反事实描述,比如“石头做的夹克”举不起物体,显示出对物理常识的真正掌握。

图8|跨机体泛化能力案例展示,这组案例展示了 WoW 世界模型在不同机器人平台上的泛化表现。无论是 UR5、Franka、AgileX 双臂机器人,还是灵巧手与仿真环境,模型都能在零微调的情况下准确理解指令并完成任务,体现出对不同机器人结构与动力学的强大适应能力

WoW 的意义不止是“更聪明的视频模型”,它标志着生成式AI开始真正理解世界的因果逻辑。
通过语言-感知-行动的闭环,AI 不再只在屏幕里想象,而能在现实世界中学会试错、形成直觉。未来,像 WoW 这样的具身世界模型,或许会成为通用智能的“物理大脑”——让机器人不再依赖规则,而是凭经验去推理、去创造。

















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









