



当前的机器人系统面临着一个根本性问题:它们只是"反应式"的黑盒,接收指令后直接输出动作,缺乏中间的推理过程。这种设计在复杂环境中暴露出致命缺陷——无法解释决策逻辑,难以适应新环境,更无法处理需要空间理解的精细操作任务。传统的Vision-Language-Action (VLA)模型直接将感知输入映射到控制输出,跳过了人类行动前的关键步骤——空间推理和路径规划。
今天,AI2(艾伦人工智能研究所)发布的MolmoAct模型,通过引入"空间推理"能力,正在重新定义机器人的思维方式。如图1所示,MolmoAct开创性地提出了一种能够在空间中进行推理的开放行动推理模型,该模型能够自回归地预测三个结构化推理链:用于感知和重建3D环境的深度感知令牌、用于表示其在场景中规划轨迹的视觉推理轨迹令牌,以及用于生成相应机器人控制命令的动作令牌。
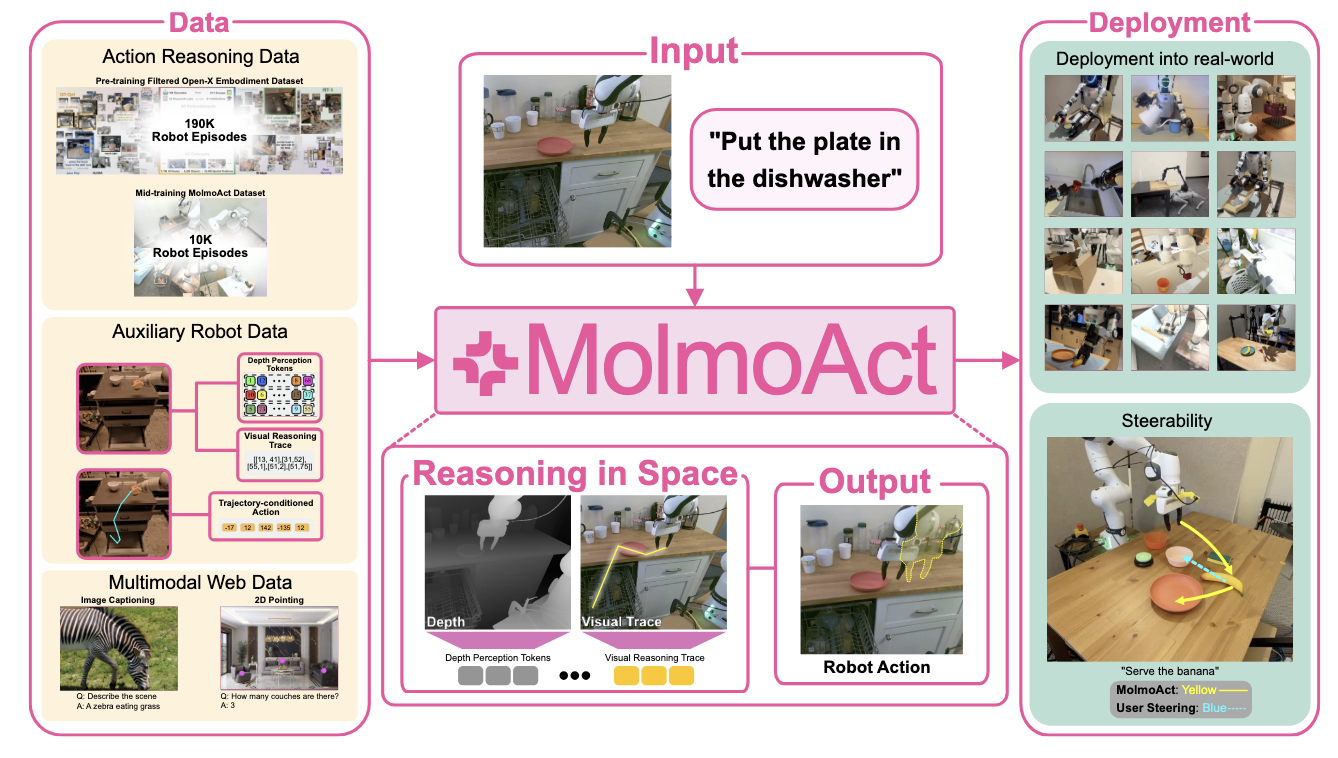
▲图 1 | 概述。MolmoAct 是一个开放式动作推理模型,给定用户的语言指令后,它能在空间中进行推理,并自回归地预测三种结构化推理链:用于感知和重建 3D 环境的深度感知令牌(Depth Perception Tokens)、用于表示其在场景中规划轨迹的视觉推理轨迹令牌(Visual Reasoning Trace Tokens),以及用于生成相应机器人控制指令的动作令牌(Action Tokens)。每个可解释的推理链都能独立解码 —— 生成场景的深度图、图像平面上的 2D 轨迹叠加层以及物理世界中的执行动作,在每个阶段都提供明确的、基于空间的推理。

现有的VLA模型存在结构性缺陷,它们缺乏对空间关系的深度理解。正如斯坦福心理学教授Barbara Tversky所言:"思维是具身的、空间的,存在于你的头脑之外。"这种缺失导致机器人在面对需要精确空间理解的任务时表现糟糕。比如"把杯子放到架子上"这样的指令,机器人无法理解杯子与架子的空间关系,无法规划合理的运动轨迹,只能依靠大量数据的统计学习来"碰运气"。
传统方法的核心问题在于缺乏结构化的推理机制。虽然语言和视觉任务受益于丰富的松散标记的网络规模数据,但机器人技术需要细粒度的具身交互——这些数据成本高昂、模糊且难以扩展。MolmoAct认识到,机器人学习的突破不仅需要更多数据,更需要结构化的学习方式。

MolmoAct创造性地提出了Action Reasoning Models (ARMs)概念,将机器人决策重构为三个递进的推理阶段,如图2所示的训练过程:
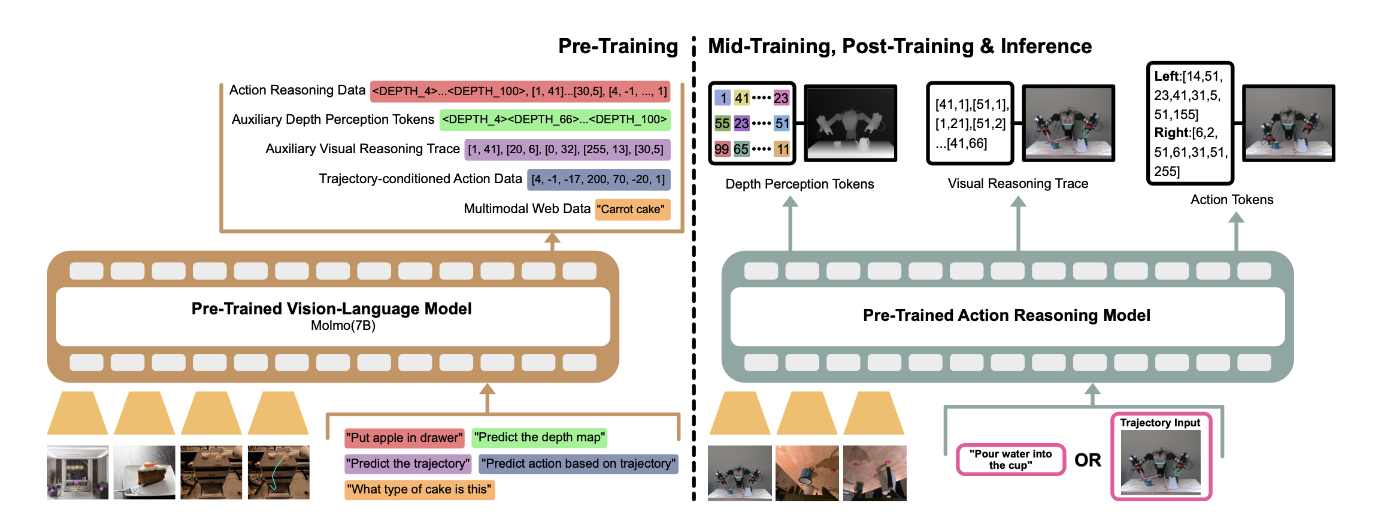
▲图 2 | MolmoAct 的训练过程。模型训练过程包括两个阶段:预训练(左侧)和后训练、中期训练与推理(右侧)。在预训练阶段,视觉 - 语言主干网络(Molmo)在多模态和机器人推理数据上进行训练,目标多样,包括离散化机器人控制、2D 指向、轨迹绘制、开放词汇问答以及感知令牌预测。在后训练阶段,动作推理模型接收多视角相机图像以及自然语言指令或视觉轨迹输入,生成用于执行的感知令牌、视觉推理轨迹令牌和动作令牌。深度感知:构建3D世界模型
MolmoAct首先生成深度感知令牌,这些特殊令牌的数学定义为:
其中。目标深度字符串定义为:
其中M=100。这些令牌通过预训练的VQVAE编码器提取,将RGB图像转换为包含几何结构和位置信息的深度表示。与传统VLA模型使用文本令牌描述空间信息不同,深度感知令牌直接编码距离、位置和几何关系,为后续的空间推理提供精确的3D基础。
空间规划:绘制执行轨迹
基于深度感知令牌,MolmoAct预测一系列图像空间中的路径点,形成视觉推理轨迹。轨迹的数学表示为:
其中1≤L≤5,坐标值归一化到图像维度:
。这些轨迹在图像上以可视化路径呈现,直观展示机器人的规划意图。关键在于,这种中级表示独立于具体的机器人硬件配置,具有良好的跨平台适应性。
精确执行:生成控制指令
最后,MolmoAct基于规划轨迹生成具体的机器人动作指令。整个推理过程遵循严格的概率分解:
其中表示深度令牌,
表示视觉轨迹,
表示动作序列。这种分解确保每个阶段都基于前一阶段的输出进行条件推理。
核心技术创新解析
动作令牌化的几何优化
传统方法使用无关的语言令牌表示动作区间,忽略了动作空间的序数结构。MolmoAct采用单调映射,将256个离散动作区间:分配给相邻的BPE符号,保留了相邻动作区间的相似性,提供了更平滑的优化起点。这种相似性保持的初始化显著减少了训练时间——相比GR00T N1的50,000 GPU小时,MolmoAct仅需9,216 GPU小时,实现了超过5倍的效率提升。
可视化控制的精确性
相比语言指令的固有模糊性,视觉轨迹提供了精确且无歧义的控制方式。测试时,用户可在摄像头图像上绘制视觉轨迹,将轨迹叠加到RGB图像上:,模型自回归生成下一步动作令牌:
这种方法避免了对大量文本-动作语料库的依赖,实现更安全、更可控的人机交互体验。

MolmoAct的训练策略体现了对效率的极致追求。如图3所示的数据混合分布,整个训练分为三个精心设计的阶段:
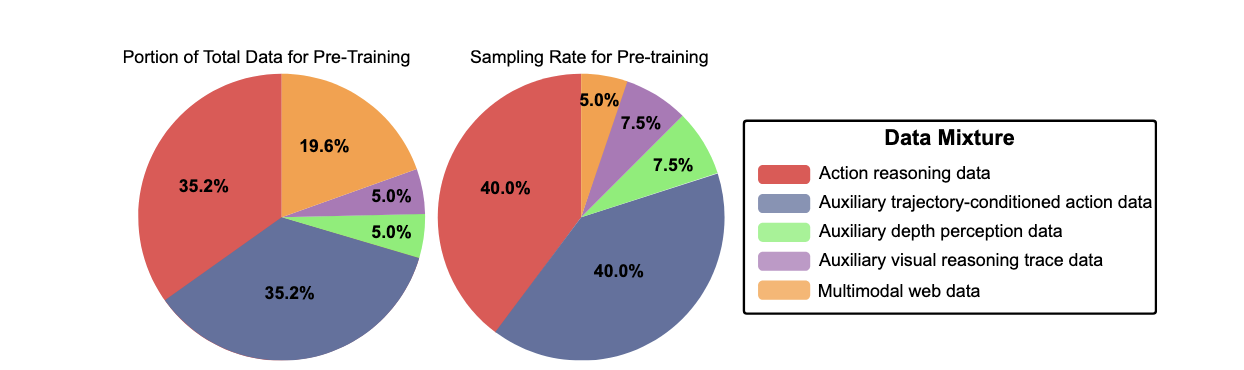
▲图 3 | 整体预训练混合数据中的数据分布(左侧)和用于 MolmoAct 预训练的采样子集数据分布(右侧)。混合数据主要包含动作推理数据(38.7%)、轨迹条件数据(38.7%)和多模态网络数据(21.5%),以及少量辅助深度数据和轨迹数据(各 0.5%)。采样子集增加了辅助数据的比例(深度和线条各 7.5%),同时将多模态网络数据减少至 5%。
预训练阶段使用26.3M样本在256个H100 GPU上训练,总计9,728 GPU小时。相比之下,NVIDIA的GR00T N1使用600M样本和1,024个GPU,而Physical Intelligence的π0使用900M样本。MolmoAct用不到3%的数据量达到了相当甚至更好的性能。
中期训练阶段专门针对家庭操作场景,使用自建的MolmoAct数据集进行优化。如图4所示,这10,689条高质量轨迹覆盖了从客厅整理到厨房操作的93种不同任务,为模型提供了丰富的家庭环境先验知识。图6b的消融实验显示,中期训练平均带来5.5%的性能提升。
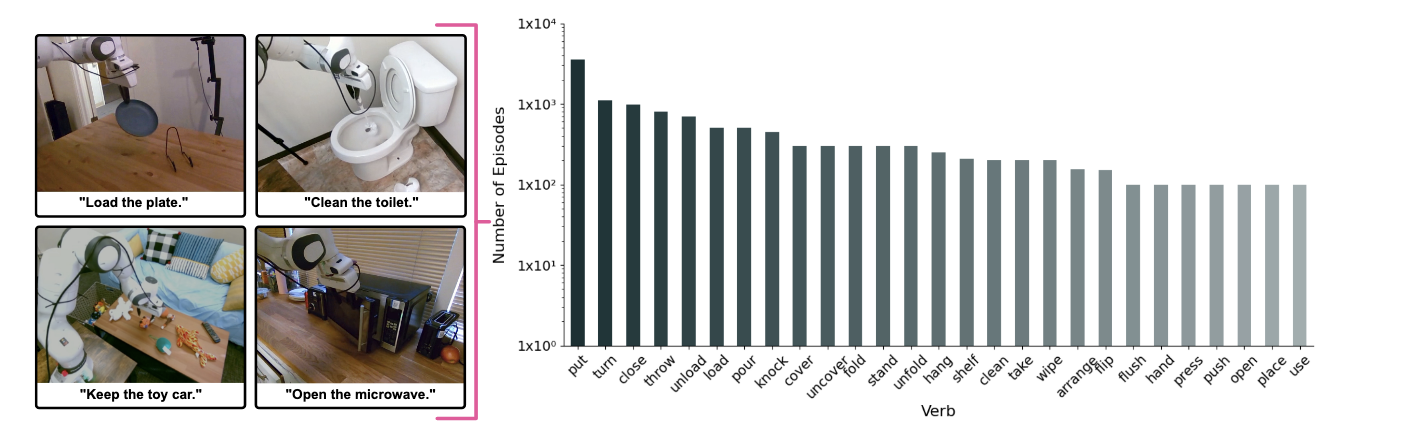
▲图 4 | MolmoAct 数据集中的示例和动词分布。左侧:与自然语言指令配对的机器人操作任务样本,涵盖多种家庭活动,如关闭笔记本电脑、放置盘子、清洁马桶和打开微波炉。右侧:数据集中顶级动词的对数尺度分布,呈现长尾模式,其中 “put(放置)”“turn(转动)” 和 “close(关闭)” 是最频繁的动作。
后训练阶段通过LoRA参数高效微调,仅需30-50个演示就能快速适应新任务。这种轻量级适应策略使得MolmoAct能够在资源受限的环境中快速部署。

仿真基准测试的突破性表现
在SimplerEnv基准上,MolmoAct-7B达到70.5%的零样本准确率,如表1所示,超越了Physical Intelligence的π0和NVIDIA的GR00T N1等闭源模型。更重要的是,在分布外变体聚合测试中,MolmoAct的性能下降微乎其微(72.1% vs 70.5%),展现了出色的鲁棒性。
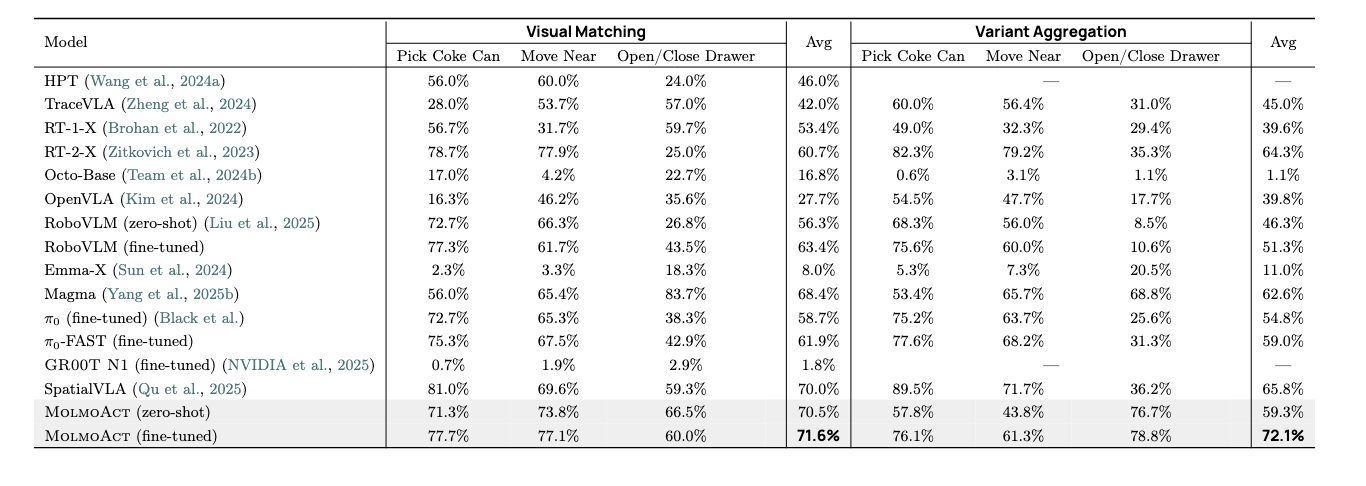
▲表 1 | Google 机器人任务上不同策略的 SimplerEnv 评估。零样本和微调结果分别表示在 OXE 数据集上预训练的模型和在 RT - 1 数据集(Brohan 等人,2022)上微调的模型性能。
在LIBERO基准的86.6%平均成功率中,如表2所示,MolmoAct在长期任务上比ThinkAct提升6.3%,这个差距在需要多步推理的复杂任务中尤为显著。特别值得注意的是,MolmoAct在LIBERO-Long任务上达到77.2%的成功率,远超其他基线方法。
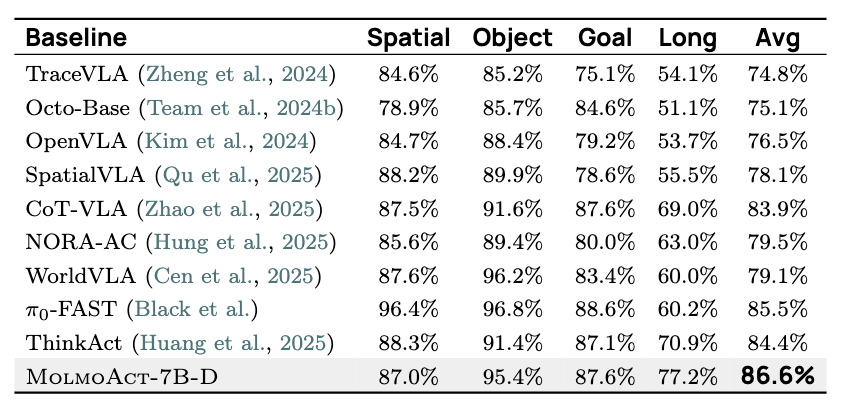
▲表 2 | LIBERO 基准在四个任务类别(空间类、物体类、目标类和长 horizon 类)上的成功率及平均性能。MolmoAct 实现了 86.6% 的最高整体平均成功率,优于所有基线模型,在所有类别中表现强劲,尤其在长 horizon 任务中。真实世界部署的实用价值
真实世界实验展现了MolmoAct的强大适应能力。如图5所示,在单臂任务中超越π0-FAST 10%,在双臂协作任务中提升幅度更是达到22.7%。这种性能差距反映了空间推理在处理复杂操作任务时的根本优势。
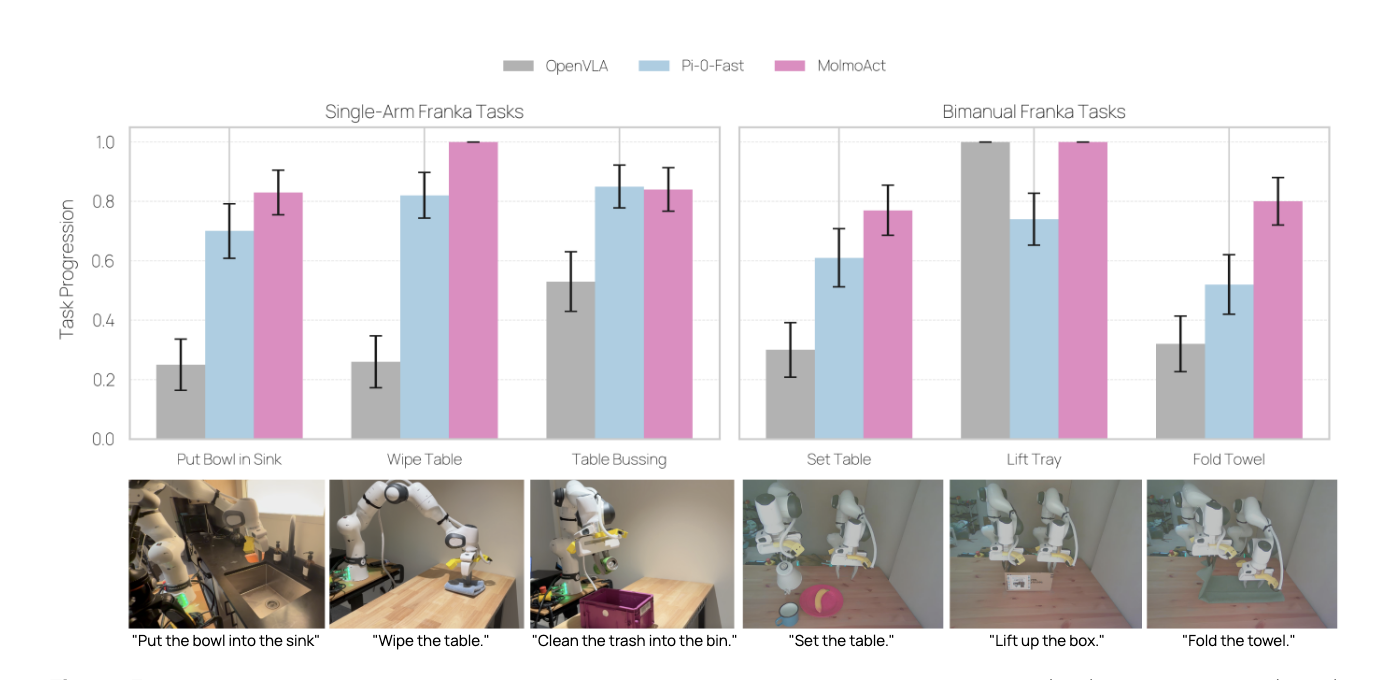
▲图 5 | OpenVLA、π0 - FAST 和 MolmoAct 在单臂(左侧)和双臂(右侧)Franka 任务上的真实世界评估。条形图显示每个任务在 25 次试验中的平均任务进展及标准误差。MolmoAct 始终优于基线模型,尤其在擦桌子(Wipe Table)和清理餐桌(Table Bussing)等单臂任务上表现突出,在叠毛巾(Fold Towel)和摆桌子(Set Table)等双臂任务上也保持着强劲性能。 bottom 行展示了示例任务设置及相应的自然语言指令。
在分布外泛化测试中,图6a显示MolmoAct在语言变化、空间变化、干扰物和新颖物体等各个维度上都显著超越基线方法,平均提升23.3%。这种全面的优势证明了空间推理架构的鲁棒性。
可控性的量化验证
在交互式控制实验中,如图9所示,当用户通过绘制轨迹来纠正机器人的初始规划时,任务成功率从常规语言指令的42%提升至75%。这个33%的改进幅度证明了视觉轨迹控制的实用价值。更重要的是,图 7展示的轨迹生成评估中,MolmoAct在Elo评分上显著超越了Gemini-2.5-Flash、GPT-4o等强基线模型。
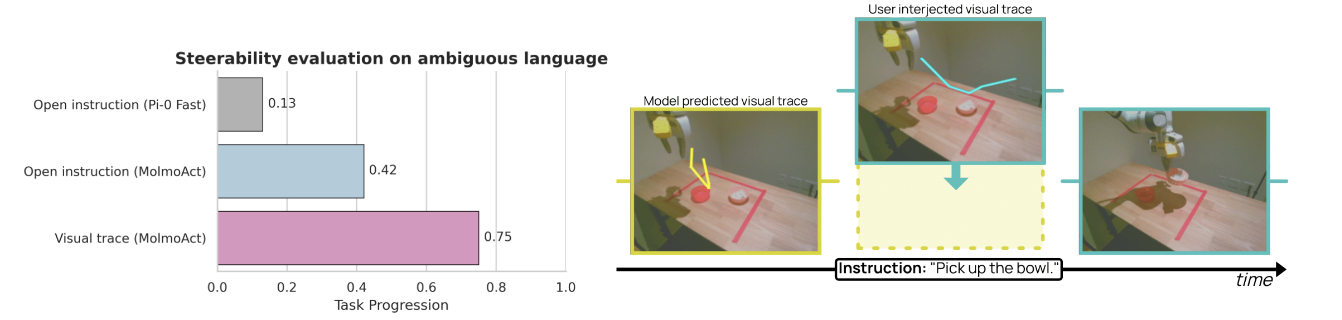
▲图 6 | 开放式指令和视觉轨迹的可控性评估。左侧:不同控制模式的成功率显示,带有视觉轨迹控制的 MolmoAct 达到最高成功率(0.75),优于其开放式指令变体和 π0 - FAST。右侧:“拿起碗” 任务的示例:模型预测轨迹(黄色)通过用户提供的控制轨迹(青色)进行调整,最终完成任务修正。
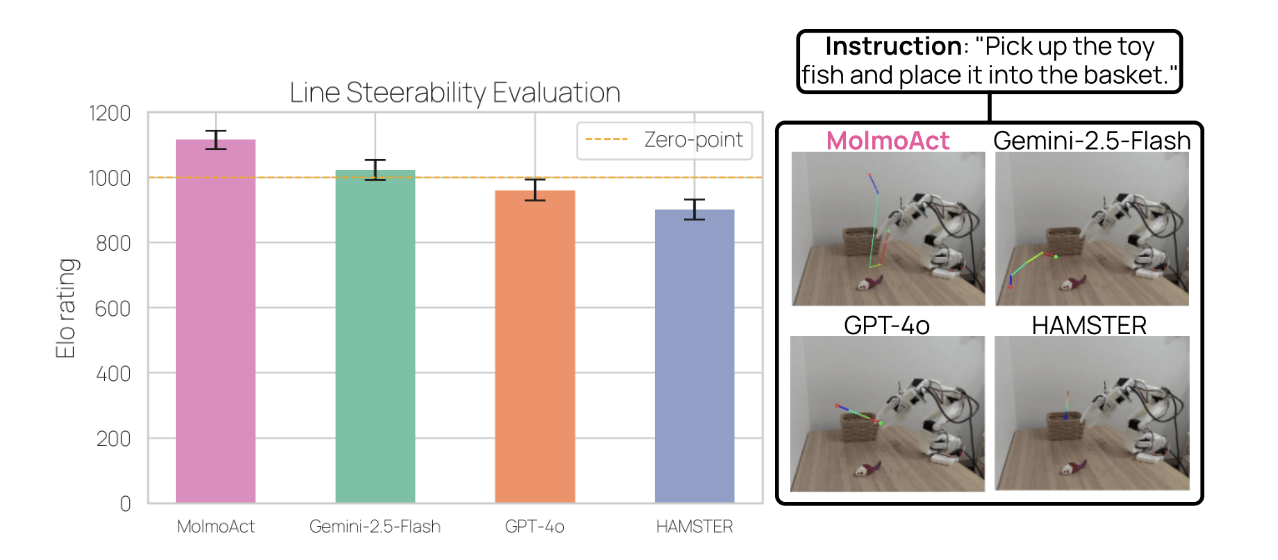
▲图 7 | 跨模型的线路可控性评估。左侧:Elo 评级显示 MolmoAct 性能最高,超过 Gemini - 2.5 - Flash、GPT - 4o 和 HAMSTER,误差线表示 95% 置信区间(CI)。右侧:示例定性结果显示在机器人相机视图上叠加的预测视觉轨迹。

范式转变:从反应到推理
MolmoAct的最大贡献在于将机器人控制从"刺激-反应"模式转变为"感知-推理-执行"模式。这种转变不仅提升了性能,更重要的是提供了可解释性和可控性,这对机器人在安全关键应用中的部署至关重要。
空间表示的创新突破
深度感知令牌和视觉推理轨迹为机器人提供了新的空间表示方法。这种表示既保持了空间信息的几何精确性,又具备了语言模型处理的可操作性,架起了连接3D物理世界与符号推理的桥梁。
数学基础的严谨性体现在其概率分解框架中。通过将复杂的感知-规划-执行过程分解为条件概率的乘积,MolmoAct确保了每个推理阶段的数学可解释性。
开源生态的示范效应
MolmoAct的完全开源策略为学术界和工业界提供了宝贵的研究基础。特别是MolmoAct数据集的发布,为机器人学习社区提供了首个大规模的家庭操作数据集,其价值将在未来的研究中持续体现。

尽管MolmoAct取得了显著进展,但仍存在改进空间。当前的视觉轨迹主要是2D表示,对于复杂的3D操作任务可能不够充分。深度感知令牌固定为100个的长度限制也可能在处理复杂场景时造成信息瓶颈。
计算复杂度的权衡:三阶段架构虽然提高了可解释性,但也增加了推理时间。如论文附录中的分析所示,模型在控制推理频率和数据收集时使用的控制频率之间存在不匹配,这可能源于服务器到机器人通信延迟和预测更多推理令牌所需的额外时间。
深度表示的精度限制:论文指出,固定的100个令牌表示深度可能对细粒度操作任务不够充分。增加深度感知令牌的数量可以增强空间推理并提高此类任务的性能。
未来的发展方向包括:扩展到更高维度的轨迹表示、提升实时推理效率、增强对动态环境的适应能力。同时,如何将空间推理能力扩展到移动操作、多机器人协作等更复杂场景,也是值得探索的重要方向。
MolmoAct标志着机器人学习从"数据驱动"向"推理驱动"的重要转变。通过在空间中进行推理,机器人不再是简单的模式匹配器,而是真正具备了理解和规划能力的智能体。这种结构化推理范式为构建能够将感知转化为有目的行动的基础模型提供了全新的蓝图。
资源链接
● 论文地址: arXiv:2508.07917
● 项目主页: allenai.org/blog/molmoact
● 模型下载: HuggingFace (MolmoAct-7B-D, MolmoAct-7B-O)
● 数据集: MolmoAct-Dataset, MolmoAct-Pretraining-Datasets, MolmoAct-Midtraining-Datasets

















 2293
2293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









