



前言
为推动无人机从简单的飞行平台进化为能在复杂动态环境中自主作业的智能体,学术界正致力于攻克高速安全、团队协作与物理交互等核心难题。作为机器人学的顶级会议,Robotics: Science and Systems (RSS) 汇聚了最新的突破性成果。本次盘点的六篇论文正体现了当前研究的核心趋势:将AI与控制理论深度融合,加速算法从仿真到现实的落地,并开拓多智能体协同与空中物理操作的新疆界,为我们揭示了无人机技术的未来图景。
1. Demonstrating ViSafe: Vision-enabled Safety for High-speed Detect and Avoid
发表会议: Robotics: Science and Systems
机构: Carnegie Mellon University
作者:Parv Kapoor, Ian Higgins, Nikhil Keetha, Jay Patrikar, Brady Moon, Zelin Ye, Yao He, Ivan Cisneros, Yaoyu Hu, Changliu Liu, Eunsuk Kang, Sebastian Scherer
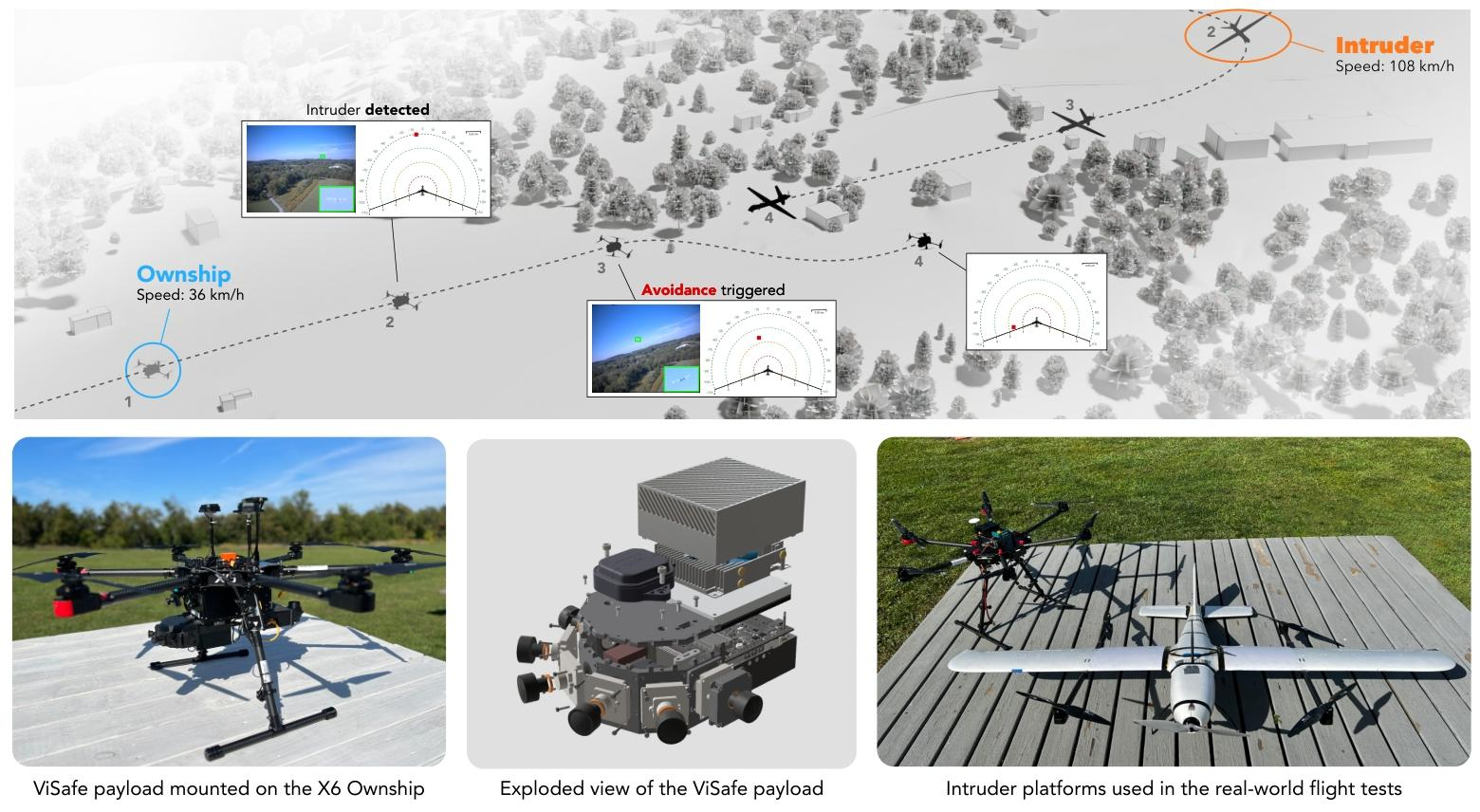
推荐理由: 论文首次展示了一套名为ViSafe的纯视觉、全栈式空中冲突避免系统,该系统专为资源受限的无人机设计,并在高达144公里/小时的相对接近速度下成功完成了真实世界的高速避碰测试。 ViSafe通过将先进的边缘AI感知与基于控制屏障函数(CBF)的可验证安全控制理论深度融合,为解决高密度空域下的“看见与规避”难题树立了新的标杆。
论文内容:作者提出了名为ViSafe的纯视觉空中冲突避免系统,旨在为小型无人机(sUAS)赋予“看见与规避”的能力。 该系统的核心是一个集成了多摄像头感知的机载硬件平台,能在边缘端实时运行深度学习模型,完成对入侵飞行器的探测、跟踪、以及最终的规避决策。 算法层面,ViSafe扩展了其前序工作AirTrack,实现了多视图融合跟踪,并通过创新的控制屏障函数(CBF)来设计规避控制器。 这种方法不依赖雷达、应答机等多源传感器,也无需外部通信或全局信息,仅依靠视觉输入来保证安全间隔。 为了全面验证系统性能,研究团队搭建了高保真的“数字孪生”仿真环境,进行了覆盖多种冲突场景、天气和光照条件的大规模硬件在环测试。 最终,通过在两个真实场地进行的大量飞行实验,包括与固定翼无人机以144公里/小时的接近速度进行的对头飞行测试,证明了ViSafe系统在高速、动态环境下保证飞行安全的有效性和鲁棒性。
2.How to Coordinate UAVs and UGVs for Efficient Mission Planning? Optimizing Energy-Constrained Cooperative Routing with a DRL Framework
发表会议: Robotics: Science and Systems
机构: University of Illinois Chicago
作者: Md Safwan Mondal, Subramanian Ramasamy, Pranav Bhounsule
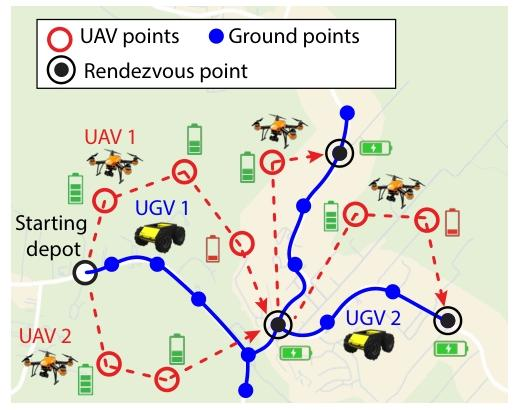
推荐理由: 该研究提出了一种创新的、基于深度强化学习(DRL)的框架,用于解决多无人机(UAV)与多无人地面车辆(UGV)的协同路径规划问题。该框架首次高效地解决了大规模、异构智能体团队在能源受限和动态任务环境下的协同难题,实现了方案质量高(任务完成时间短)、扩展性强(适应不同团队规模和问题复杂度)和适应性好(能在线应对任务和团队的动态变化)三大核心优势。
论文内容:作者提出了一种用于多UAV-UGV团队能源受限协同路径规划的深度强化学习(DRL)框架,目标是在最短的时间内完成对所有指定任务点的访问。该框架的核心是采用一个编码器-解码器结构的Transformer网络来学习最优的路径规划策略。其中,编码器负责将任务点的位置信息转换成高维度的特征嵌入,以捕捉任务之间的空间关系 。在决策层面,解码器内创新性地引入了“分批次智能体切换”策略 。该策略允许UAV智能体完成从一次充电到下一次充电之间的完整任务序列后,再切换到另一个智能体,从而实现了高效且有序的团队协作。随后,解码器会根据当前选定的活动智能体的状态(如位置、剩余燃料等)和环境信息,决定下一步是访问任务点还是执行充电对接 。为了证明框架的有效性,作者将其与多种传统的启发式方法以及一个DRL基线模型进行了全面的计算实验对比。结果显示,该框架在不同规模的问题和团队配置下,无论是在求解质量(任务总耗时)还是计算效率上都展现出显著的优越性。此外,通过泛化能力测试和动态场景的案例研究,进一步证明了该框架无需重新训练即可适应更复杂的任务、变化的团队配置以及动态出现的任务点,展现了其作为在线规划工具的强大鲁棒性和实际应用潜力 。
3.Influence of Static and Dynamic Downwash Interactions on Multi-Quadrotor Systems
发表会议: Robotics: Science and Systems
机构: Brown University
作者: Anoop Kiran, Nora Ayanian, and Kenneth Breuer
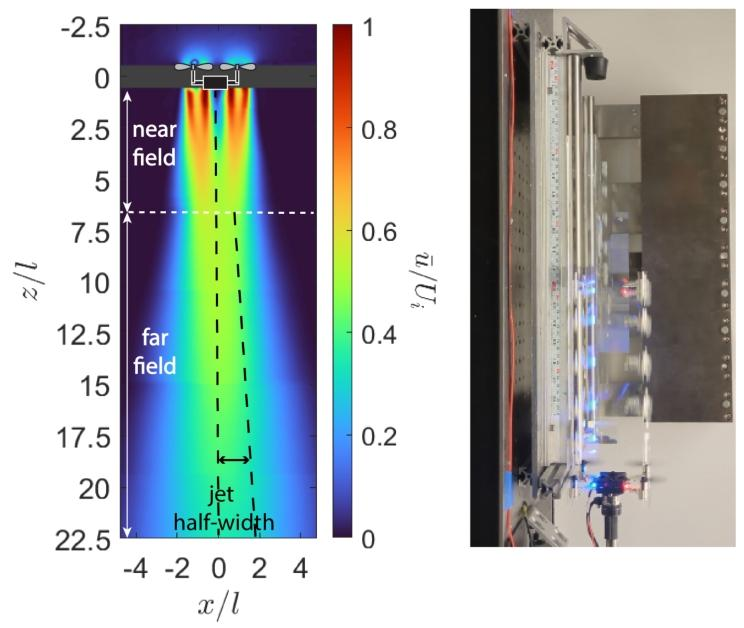
推荐理由: 本文通过全面的数据驱动分析,系统地量化和剖析了四旋翼无人机近距离飞行时的下洗流空气动力学效应,改变了以往仅通过保守策略(如设置巨大避障区)来规避下洗流影响的传统范式。研究不仅为理解密集体型下的不稳定力矩和性能衰减提供了坚实的经验基础,还验证了即使在小型无人机较低雷诺数工况下,其远场下洗流也可用经典湍流射流理论进行精确建模。这一系列开创性的工作为开发能够主动利用下洗流效应、优化飞行编队、并提升多机系统鲁棒性的新型物理感知控制策略铺平了道路。
论文内容:针对多四旋翼无人机在密集编队中因下洗流干扰而导致性能下降和失稳的重大挑战,作者进行了一项综合性的数据驱动研究,旨在深入表征、分析和理解该效应。研究采用了一套精密的实验装置,通过改变两架Crazyflie无人机的相对水平和垂直间距,使用六轴力/力矩传感器精确测量了静态分离下无人机间相互作用的力和力矩。同时,研究利用粒子图像测速技术(PIV)对单个及成对无人机下方的下洗流速度场进行了高分辨率的量化测绘。研究发现,在垂直堆叠配置下,下方无人机的推力会因上方的下洗流而显著降低,损失可达其悬停推力的35%,而水平偏移则会产生巨大的失稳俯仰力矩。一项核心发现是,单个无人机下方的独立旋翼射流会在特定距离外合并成一股统一的湍流射流,并且其远场行为与经典湍流射流理论的标度律高度吻合,即便在无人机运行的较低雷诺数下也是如此,这为建立簡洁的代数模型提供了理论依据。此外,论文还通过一个定制的动态测试平台研究了无人机在相互接近和远离过程中的动态力,揭示了分离速率对相互作用力的显著影响。这项工作最终形成了一个宝贵的开源空气动力学数据集,为未来开发能够在复杂下洗流区域内稳定飞行的先进多机控制器奠定了基础。
4.Leveling the Playing Field: Carefully Comparing Classical and Learned Controllers for Quadrotor Trajectory Tracking
发表会议: Robotics: Science and Systems
机构: University of Pennsylvania
作者: Jake Welde, Pratik Kunapuli, Dinesh Jayaraman, Vijay Kumar
推荐理由: 本文提出了一套严谨、公平的实验基准协议,旨在解决当前研究中学习控制器(强化学习RL)与经典控制器(几何控制GC)性能比较时存在的普遍偏见。通过首次系统性地消除在任务目标定义、训练数据和前馈信息方面的“不对称性”,该工作颠覆了“学习方法普遍优于经典方法”的普遍认知,为不同类别控制器之间进行可靠、有效的性能比较树立了新的标准。
论文内容:作者指出,以往研究在比较强化学习(RL)与几何控制(GC)在无人机轨迹跟踪等任务上的性能时,常因实验设置不公而得出偏向于学习方法的结论。为解决此问题,论文设计并实施了一套“公平竞争”的实验方法论。该方法论的核心是纠正三个关键的不对称性:1) 任务与优化对称:确保两种控制器都针对完全相同的任务目标函数和轨迹数据进行优化或调参。2) 数据访问对称:保证两种控制器在优化过程中能接触到相同分布的任务数据,避免因训练/调参数据与测试任务不符而导致经典控制器性能不佳。3) 前馈信息对称:给予两种控制器同等的未来轨迹信息访问权限,这对GC的性能至关重要,但在以往的基准测试中常被忽略或以次优方式实现。在搭建了该公平的仿真对比平台后,实验结果表明,经过最佳优化的GC与RL控制器之间的性能差距远小于先前文献所报告的。具体而言,GC在稳态误差上表现更优,而RL在瞬态响应(即处理大幅度初始扰动的能力)上更胜一筹。最后,通过一个模拟接球实验,论文展示了在需要极高敏捷性的瞬态任务中,RL的优势确实能够转化为更高的任务成功率。
5.Flying Hand: End-Effector-Centric Framework for Versatile Aerial Manipulation Teleoperation and Policy Learning

发表会议:Robotics: Science and Systems
机构: Carnegie Mellon University;Pennsylvania State University
作者: Guanqi He, Xiaofeng Guo, Luyi Tang, Yuanhang Zhang, Mohammadreza Mousaei, Jiahe Xu, Junyi Geng, Sebastian Scherer, Guanya Shi
推荐理由: 论文提出了一个统一的、以末端执行器为中心的(end-effector-centric)空中操作框架,首次成功地将高层决策(遥操作或模仿学习策略)与底层的无人机-机械臂全身控制进行解耦。该方法不仅大幅提升了空中作业的通用性和精准度,更开创性地将直观的遥操作和前沿的模仿学习策略引入空中机器人领域。
论文内容:针对现有空中操作机器人通常为特定任务设计,缺乏通用性的问题,作者提出了一个名为“飞行之手”(Flying Hand)的统一框架。该框架由三部分构成:一个硬件平台(包含一台全驱六旋翼无人机和一个四自由度机械臂),一个以末端执行器为中心的底层全身模型预测控制器(MPC),以及一个高层策略模块 。其核心思想是通过一个末端执行器中心接口,将复杂的底层控制与上层任务决策分离 。底层控制器采用MPC来协同优化无人机和机械臂的运动,以精确追踪末端执行器的目标轨迹 ,并通过L1自适应控制来实时补偿模型不确定性和外部扰动,从而保证了高精度的追踪性能。在高层,该框架支持两种策略输入:一是直观的遥操作界面,允许操作员像控制自己 свободно移动的手一样直接控制末端执行器的位姿 ;二是一个基于模仿学习的自主策略,通过学习人类操作员的演示数据来训练机器人自主完成任务,这也是模仿学习首次被成功应用于空中操作领域。大量的真实世界实验,如空中写字、穿针、拧阀门和换灯泡等 ,验证了该框架的卓越性能、遥操作的便捷性以及学习策略的有效性 。
6.RAPID: Robust and Agile Planner Using Inverse Reinforcement Learning for Vision-Based Drone Navigation
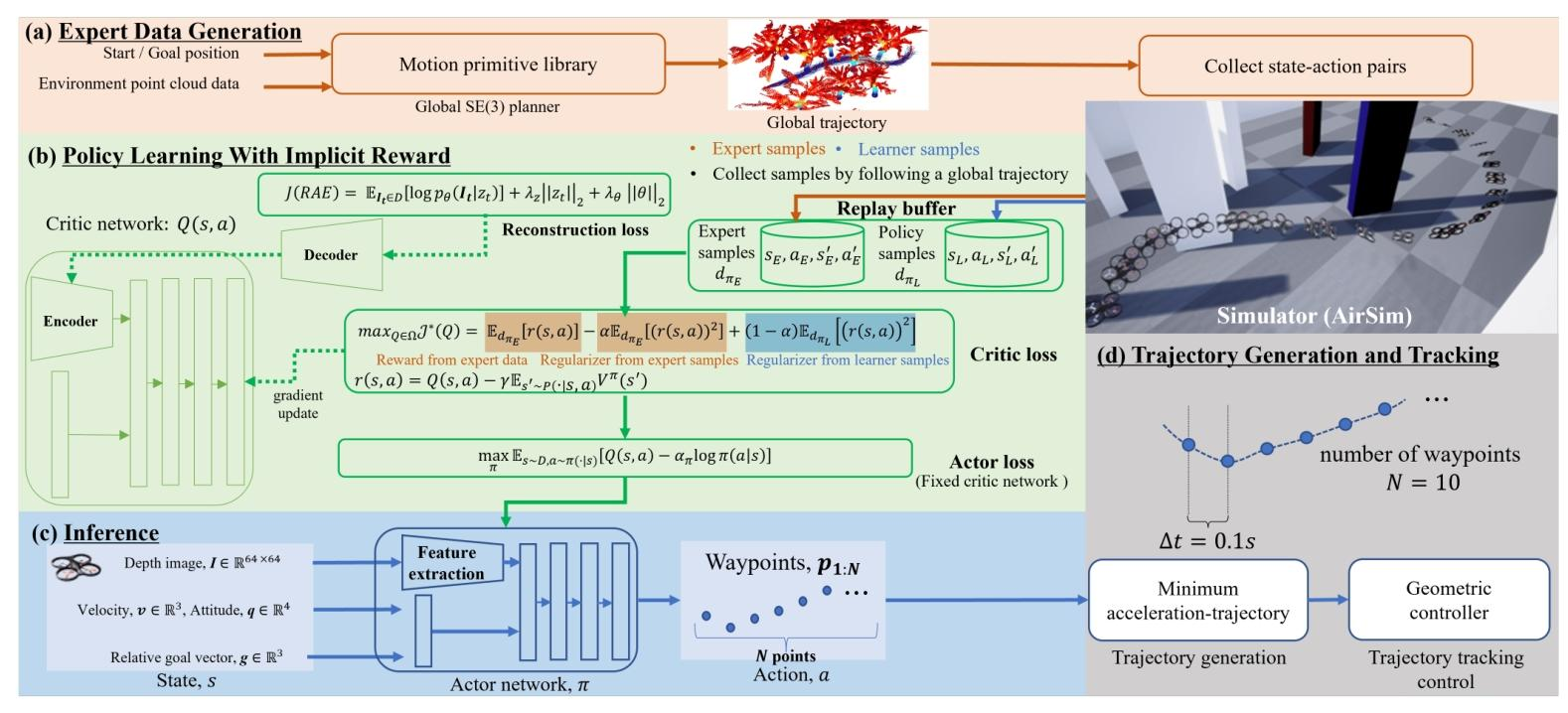
发表会议: Robotics: Science and Systems
机构: Ulsan National Institute of Science and Technology
作者:Minwoo Kim, Geunsik Bae, Jinwoo Lee, Woojae Shin, Changseung Kim, Myong-Yol Choi, Heejung Shin, Hyondong Oh
推荐理由: 该论文首次成功地将逆向强化学习(IRL)框架应用于无人机的高速视觉导航任务,有效解决了传统学习方法中模仿学习的复合误差和强化学习的奖励设计难题 。该方法在纯仿真环境中训练,却能直接部署于真实世界的复杂场景并实现卓越性能,成功跨越了仿真到现实的鸿沟,在真实飞行中达到了平均7m/s,最高8.8m/s的惊人速度 。
论文内容:作者提出了一个名为RAPID的学习型规划器,旨在解决无人机在杂乱环境中进行高速敏捷飞行的挑战 。传统方法存在高延迟问题,而现有的学习方法如行为克隆(BC)和强化学习(RL)分别受限于复合误差和奖励函数设计难的问题。为克服这些限制,RAPID采用了一种基于逆向强化学习(IRL)的框架,通过专家数据集和智能体的自主探索数据,学习一个隐式的奖励函数和鲁棒的飞行策略 。为了高效处理高维度的视觉输入,该方法集成了一个辅助自编码器损失函数以提升学习效率;同时,通过对高速飞行场景中吸收状态(如碰撞或到达终点)的特殊处理,增强了学习的稳定性与避障性能 。此外,为缩小仿真与现实的差距,该模型在训练中便考虑了真实控制器的跟踪误差,并使用模拟真实传感器噪声的深度图像。最终,仅在仿真中训练出的模型被成功验证于现实世界的森林和城市等多种环境中,证明了其强大的泛化能力和实用性 。
结语
综合来看,这六篇来自RSS的论文共同描绘了无人机技术向更高自主性、智能性和实用性迈进的清晰路径。无论是ViSafe和RAPID在高速视觉导航上取得的惊人突破,还是“飞行之手”在空中精细操作上展现的卓越通用性,亦或是对多机协同与底层空气动力学的深刻洞察,都标志着无人机正在从孤立的飞行器转变为能与环境、与人、与其他机器人进行复杂交互的智能系统。这些研究不仅解决了关键的技术瓶颈,更通过严谨的科学方法论,为构建一个真正由智能空中机器人赋能的未来奠定了坚实的基础。

















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









