



导读
如何让机器人不仅学会完成任务,更具备跨环境的泛化能力,一直是强化学习(RL)难以跨越的障碍。本文展示了一种令人振奋的进展:通过大规模多任务RL训练,研究者让在Minecraft中学习到的视觉-动作智能体,具备了零样本泛化能力,能够在从未见过的3D世界甚至现实场景中展现出强大的空间推理与交互表现。为此,作者构建了统一的目标空间(cross-view目标表示),并基于Minecraft环境自动合成了超过十万个交互任务,解决了传统RL任务设计繁琐的问题。
此外,文中提出的分布式训练框架有效提升了训练效率,使得Transformer策略在长序列任务中依然表现稳定。结果显示:RL训练将智能体的交互成功率提升了4倍,并在多个平台上实现了出色的零样本迁移,展示了RL作为视觉-动作智能体后训练手段的巨大潜力。
论文出处:arXiv2025
论文标题:Scalable Multi-Task Reinforcement Learning for Generalizable SpatialIntelligence in Visuomotor Agents
论文作者:Shaofei Cai, Zhancun Mu, Haiwen Xia, Bowei Zhang, Anji Liu, Yitao Liang

强化学习(Reinforcement Learning, RL)在解决复杂任务,特别是序列决策问题方面展现出巨大潜力。传统上,RL 在多任务策略训练中通常依赖于精心设计的奖励函数,从零开始引导智能体学习特定的任务知识。然而,这种方式广泛面临“灾难性遗忘”与多任务干扰等问题,严重限制了 RL 在复杂多任务环境中的泛化能力。
近年来,随着大语言模型(LLMs)的快速发展,RL 的应用范式出现了根本性转变。它不再仅仅是一个任务学习工具,而逐渐演变为强化 LLM 核心能力(如逻辑推理和指令理解)的关键手段。这一变化背后的两个关键要素是:(1)LLMs 通过大规模预训练获取的通用知识;(2)“下一个token预测”机制统一了 LLM 的任务表示空间,使其能够连贯地处理多种语言任务。
尽管 RL 在语言建模领域取得了显著成功,但这一成就尚未在视觉-动作智能体中得到充分体现。主要挑战在于 RL 模型容易过拟合特定任务或环境,难以获得具备泛化能力的策略。本文为此问题提供了初步的答案:通过 RL 微调训练的视觉-动作智能体,可实现空间推理能力的跨环境零样本泛化,适用于其他 3D 环境甚至真实场景。
为了实现这一目标,作者首先提出构建统一且高效的多任务目标空间。他们认为,一个理想的目标空间应具备四个关键特性:开放性、明确性、可扩展性和课程化(即逐步学习复杂技能的能力)。在综合分析现有主流任务表示方式后,作者最终选择使用 cross-view 目标表示方法作为统一任务空间——即通过选取从某一新视角可观察到目标物体的位置,并生成该物体的精准分割掩码,以此作为任务目标。
为支持大规模 RL 训练,研究者进一步选择在 Minecraft 环境中进行策略训练。得益于其高度可定制性,Minecraft 可通过对世界种子、地形、视角与目标物体的随机采样,自动生成数以万计的任务实例。这种自动化机制有效突破了手动设计任务的瓶颈,使大规模多任务训练成为可能。为解决训练中的工程挑战,作者还构建了一个高效的分布式 RL 框架,提升了长序列 Transformer 策略的训练稳定性。
最终,作者在 Minecraft 中进行了超过 10 万个任务的强化训练,智能体在交互任务中的成功率提升了 4 倍,并在 DMLab、Unreal Engine 以及现实世界环境中展示出强大的跨视角空间推理泛化能力。这一发现强有力地验证了:RL 不仅适用于策略训练,更能作为后训练机制,显著增强视觉-动作策略的通用能力。

一、通用任务空间设计
传统多任务强化学习中,任务通常以简单 ID 表示,缺乏语义结构,不利于策略泛化。为实现“以少训多”、适配新环境的能力,作者提出构建一个具备以下四个关键特性的通用任务空间:
● 开放性:可容纳无限种任务类型;
● 明确性:任务目标清晰可感知;
● 可扩展性:支持大规模任务合成与评估;
● 课程性:任务难度可平滑调整,利于技能积累。
经过对比分析,自然语言和实例图像都存在一定缺陷(如语言空间模糊、图像空间缺乏空间上下文),最终作者选择了跨视角目标指定(Cross-View Goal Specification, CVGS)作为任务空间核心方式。
CVGS 的方式是:给定一个来自第三视角的图像及其目标分割掩膜,要求智能体从当前第一视角出发完成该目标交互。这种表示天然融合了视觉与目标语义,并具备跨视角推理能力,是推动策略泛化的关键。
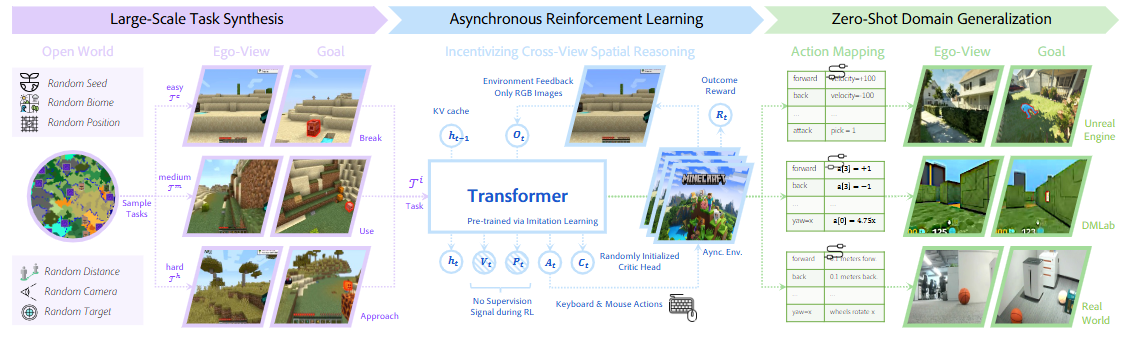
图1|本文方法在一个开放世界环境中,随机采样地形、目标物体、相机视角与交互距离,从而合成大规模、混合难度的跨视角交互任务。基础策略通过构建的分布式强化学习框架进行微调,并可通过简单的动作空间映射部署到未见过的 3D 世界中
二、系统流程与训练策略
为了实现上述任务空间下的策略学习,作者构建了一个完整训练流程,包含任务定义、模仿学习预训练、大规模任务生成、强化学习微调以及高效分布式训练框架。
1. 任务定义
每个任务由四部分构成:初始观察图像、目标视角图像、目标掩膜、交互事件(如拾取、打碎等)。策略模型接收历史观察序列与任务描述,输出下一步动作决策,核心挑战在于理解自身与目标之间的空间关系。
2. 模仿学习预训练(IL)
通过采样大量轨迹,构建目标可见性、几何中心、掩膜等辅助信息,引导模型学习目标识别与动作决策的关联。这样预训练后的策略具备基本的目标感知和操作能力,为后续强化学习打下基础。
3. 大规模任务自动生成
在 Minecraft 环境中,作者设计了一种可控的任务生成机制:
● 随机设置目标位置和视角;
● 调整目标视角覆盖目标物体;
● 使用 Segment Anything Model(SAM)生成像素级分割掩膜;
● 根据距离等因素自动设定任务难度和奖励信号。
通过这一机制,团队生成了超过 10 万个多样化任务实例,构建了一个规模空前的训练数据集。
4. 强化学习微调(RL)
在预训练基础上,策略通过强化学习进行优化。为了保持训练稳定性,加入了对预训练策略的 KL 正则化约束。此外,虽然训练只监督动作输出,但模型在空间感知能力上也有所保留,体现了任务间知识迁移的效果。

图2|RL主要算法框架
5. 高效分布式训练框架
考虑到 Minecraft 仿真复杂、长序列依赖强,作者设计了一套高效的分布式 RL 框架:
● 异步数据采集:多个 rollout worker 并发运行;
● 优化通信:数据存储在共享 NAS,训练器仅读取索引;
● 长序列支持:采用片段化缓存管理,支持 Transformer 长依赖建模。
最终系统可同时运行 72 个环境实例,采样速度达 1000FPS,有效支撑大规模训练。

实验设置与环境定义
所有实验统一采用基于像素的视觉输入(224×224),控制空间涵盖全方位移动、相机视角调整以及物体交互等操作,具备较强的跨环境适应性。训练任务主要在 Minecraft 中构建,任务类型包括接近(Approach)、打击(Break)、交互(Interact)和狩猎(Hunt),难度通过起始距离进行分级。
Minecraft 中的 RL 训练发现
1. RL 带来显著性能跃升
在 10 万个自动生成的任务上进行 RL 后训练后,平均成功率从 7% 提升至 28%,为 pretrain 水平的 4 倍。尤其是在高难度任务(如射箭打猎)中,从不到 1% 飙升至 28%。这表明 RL 能激活 pretrain 未能挖掘出的稀有能力。
2. KL 正则约束保障训练稳定
实验显示,加入与预训练策略的 KL 距离约束(即“w/ KL”)能显著提升学习曲线稳定性,避免无 KL 时出现的收敛崩溃现象。也验证了预训练策略是 RL 成功的前提,直接训练常常失败。
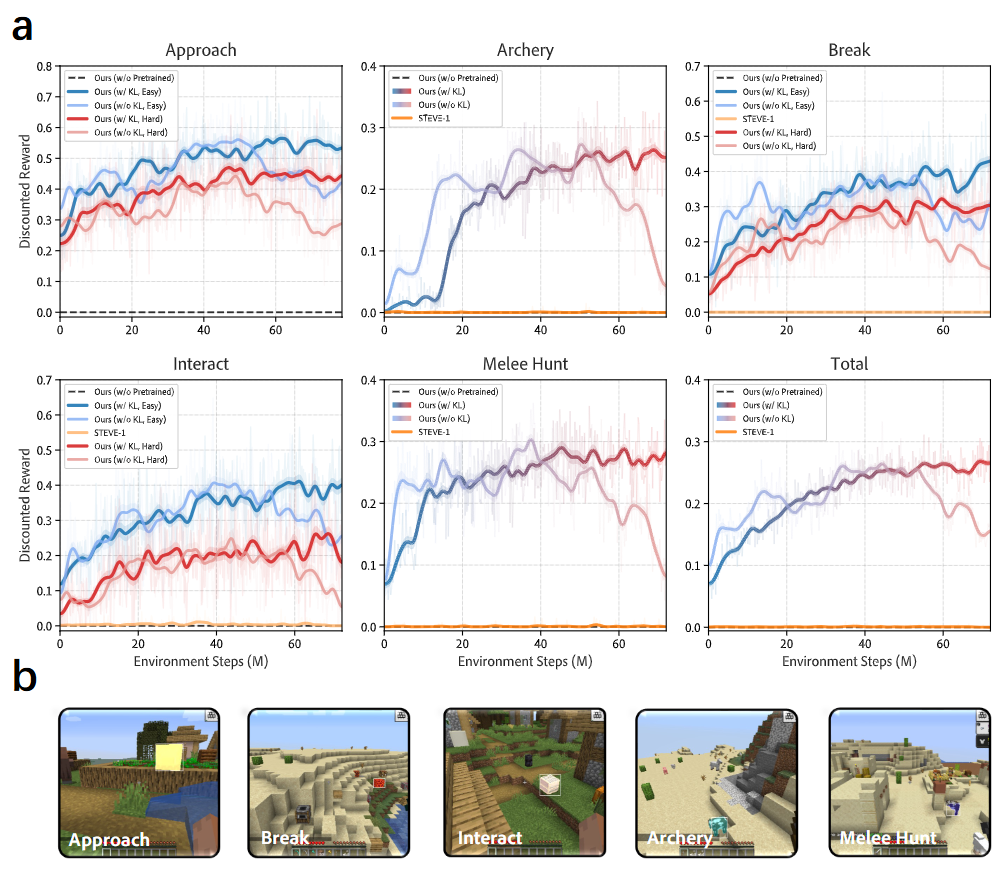
图3|(a) Minecraft 环境中五种技能的 RL 训练曲线,展示了所有技能在 RL 过程中同步提升的趋势。同时也揭示了:若缺乏 KL 散度约束,策略在后期训练阶段会发生性能崩溃。(b) 展示每种技能训练时的目标视角示例,涵盖多种摄像头角度(如眼平视角、俯视角)。其中,“射箭”任务涉及与敌对生物的远程交互,而“近战狩猎”则要求进行近距离战斗。
3. 自然语言策略适应性差
以自然语言作为任务输入的 STEVE-1,在 RL 阶段基本毫无提升,表明语言本身难以提供精确的空间引导,尤其在目标不可见时显得力不从心。而本文方法可借助三视角目标输入进行空间推理,引导探索。
4. 混合难度课程策略效果更优
相比传统的“从易到难”进阶方式,作者采用混合难度训练策略(同时训练 Easy/Medium/Hard 任务),结果表明其收敛更快、泛化更强。即便高难任务只占 1/3 采样频率,也明显优于仅训练高难任务的 baseline。
5. 空间推理能力具有鲁棒性
尽管 RL 阶段未对目标可见性与位置预测分支提供监督,这两项辅助能力仍基本保持原有效果,表明策略具备较强的内生空间理解能力,并未在 RL 过程中被削弱。
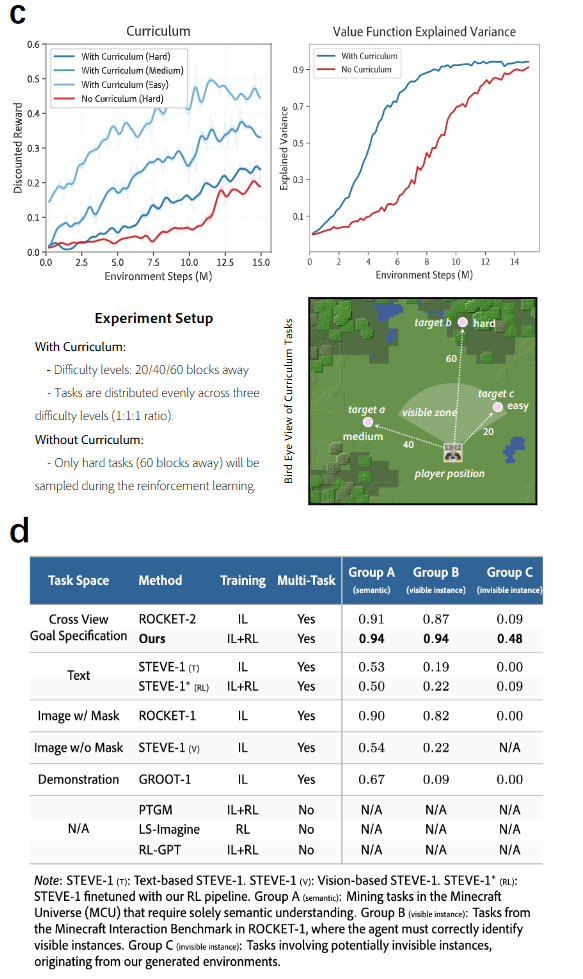
图4|(c) 比较了基于课程学习(混合难度)与非课程训练(仅高难任务)的训练效果。左图中的“折扣奖励”表明课程学习能带来更高的训练效率与更快的奖励累积,右图的“值函数解释方差”则表明课程训练可加速值函数的学习过程。(d) Minecraft 中当前主流目标条件策略的结果表(以成功率计)。我们的智能体是首个在该复杂环境中实现多任务强化学习成功的模型,同时也列举了多个具有代表性的单任务 RL 模型作参考。
与现有方法的对比
如图4(d)所示,作者在 Minecraft 中构造了三类任务组(语义理解、可见目标交互、不可见目标交互)来评估泛化能力:
● 多数基线(如 ROCKET、PTGM、RL-GPT)在前两类任务中表现尚可;
● 但在最具挑战性的“不可见目标”任务中,只有本文方法达成 48% 成功率,远超其他方法。
这一结果表明其具备跨视角、跨任务的强泛化能力。
跨环境泛化评估
为进一步验证能力迁移效果,作者将 RL 后训练策略迁移至三个新环境:
● DMLab 与 Unreal Engine;
● 真实场景下的全向轮移动机器人。
结果表明:
● 预训练策略在新环境中表现一般;
● RL 后训练策略则能适应更大视角差异,如从俯视图导航至目标;
● 在真实场景下的“找球”任务中,成功率提升达 41%。
但也发现:在真实世界中存在撞击障碍物、远距离接近失败等问题,提示仍需通过增加训练环境多样性来弥合现实差距。

图5|真实场景迁移实验结果图示

本研究验证了强化学习在提升视觉-运动智能体的跨视角空间推理与交互能力方面具有显著效果。实验表明,这种增强的能力能够很好地泛化至各种 3D 环境中,包括真实世界。此外,我们还从 RL 后训练过程中获得了诸多有价值的观察与启发。未来的工作将进一步探索适用于多种动作空间的 3D 世界统一强化学习训练方法。


















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









